
vLLM
Easy, fast, and cheap LLM serving for everyone

vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Features
Advantages
Disadvantages
Frequently Asked Questions
Alternative AI tools for vLLM
Similar sites
vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.

Unify
Unify is an AI tool that offers a unified platform for accessing and comparing various Language Models (LLMs) from different providers. It allows users to combine models for faster, cheaper, and better responses, optimizing for quality, speed, and cost-efficiency. Unify simplifies the complex task of selecting the best LLM by providing transparent benchmarks, personalized routing, and performance optimization tools.

Mixpeek
Mixpeek is a multimodal intelligence platform that helps users extract important data from videos, images, audio, and documents. It enables users to focus on insights rather than data preparation by identifying concepts, activities, and objects from various sources. Mixpeek offers features such as real-time synchronization, extraction and embedding, fine-tuning and scaling of models, and seamless integration with various data sources. The platform is designed to be easy to use, scalable, and secure, making it suitable for a wide range of applications.
OpenLIT
OpenLIT is an AI application designed as an Observability tool for GenAI and LLM applications. It empowers model understanding and data visualization through an interactive Learning Interpretability Tool. With OpenTelemetry-native support, it seamlessly integrates into projects, offering features like fine-tuning performance, real-time data streaming, low latency processing, and visualizing data insights. The tool simplifies monitoring with easy installation and light/dark mode options, connecting to popular observability platforms for data export. Committed to OpenTelemetry community standards, OpenLIT provides valuable insights to enhance application performance and reliability.
Metaflow
Metaflow is an open-source framework for building and managing real-life ML, AI, and data science projects. It makes it easy to use any Python libraries for models and business logic, deploy workflows to production with a single command, track and store variables inside the flow automatically for easy experiment tracking and debugging, and create robust workflows in plain Python. Metaflow is used by hundreds of companies, including Netflix, 23andMe, and Realtor.com.
Ragie
Ragie is a fully managed RAG-as-a-Service platform designed for developers. It offers easy-to-use APIs and SDKs to help developers get started quickly, with advanced features like LLM re-ranking, summary index, entity extraction, flexible filtering, and hybrid semantic and keyword search. Ragie allows users to connect directly to popular data sources like Google Drive, Notion, Confluence, and more, ensuring accurate and reliable information delivery. The platform is led by Craft Ventures and offers seamless data connectivity through connectors. Ragie simplifies the process of data ingestion, chunking, indexing, and retrieval, making it a valuable tool for AI applications.
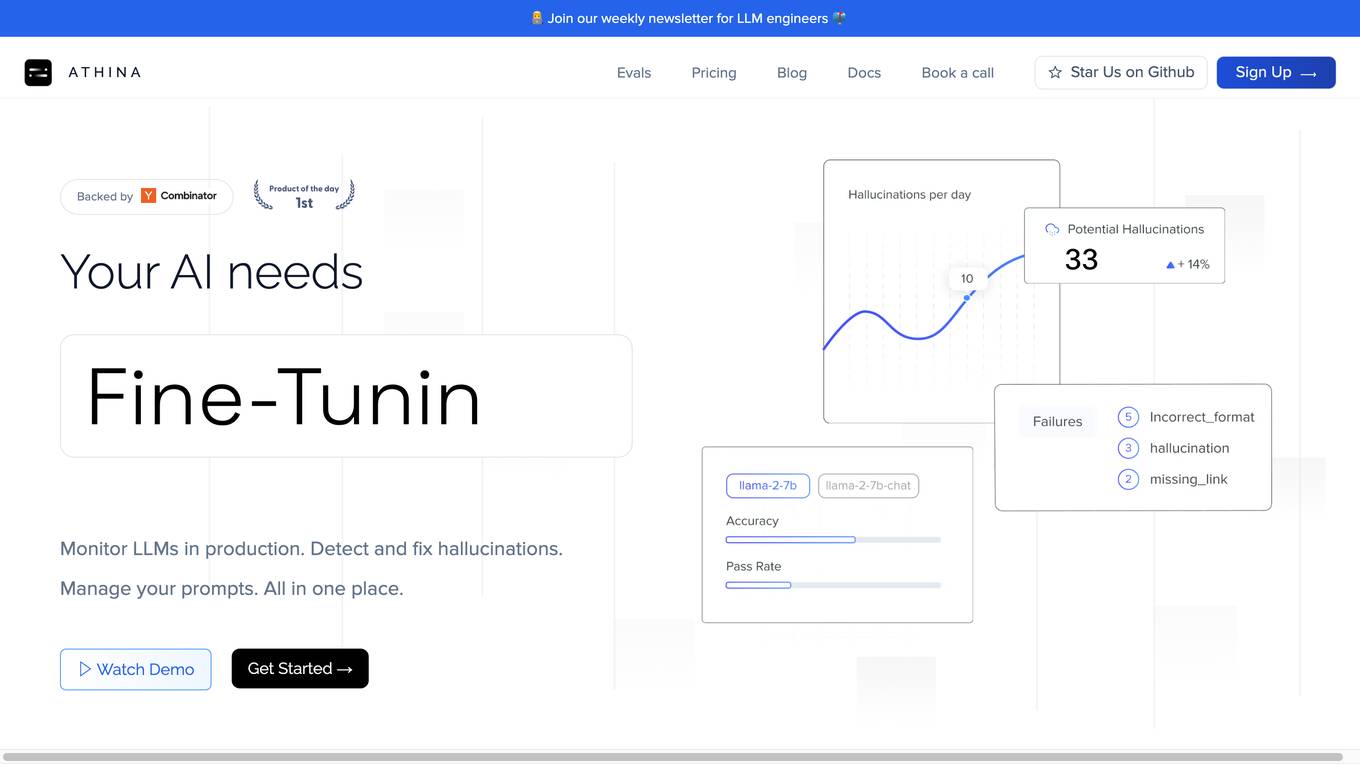
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
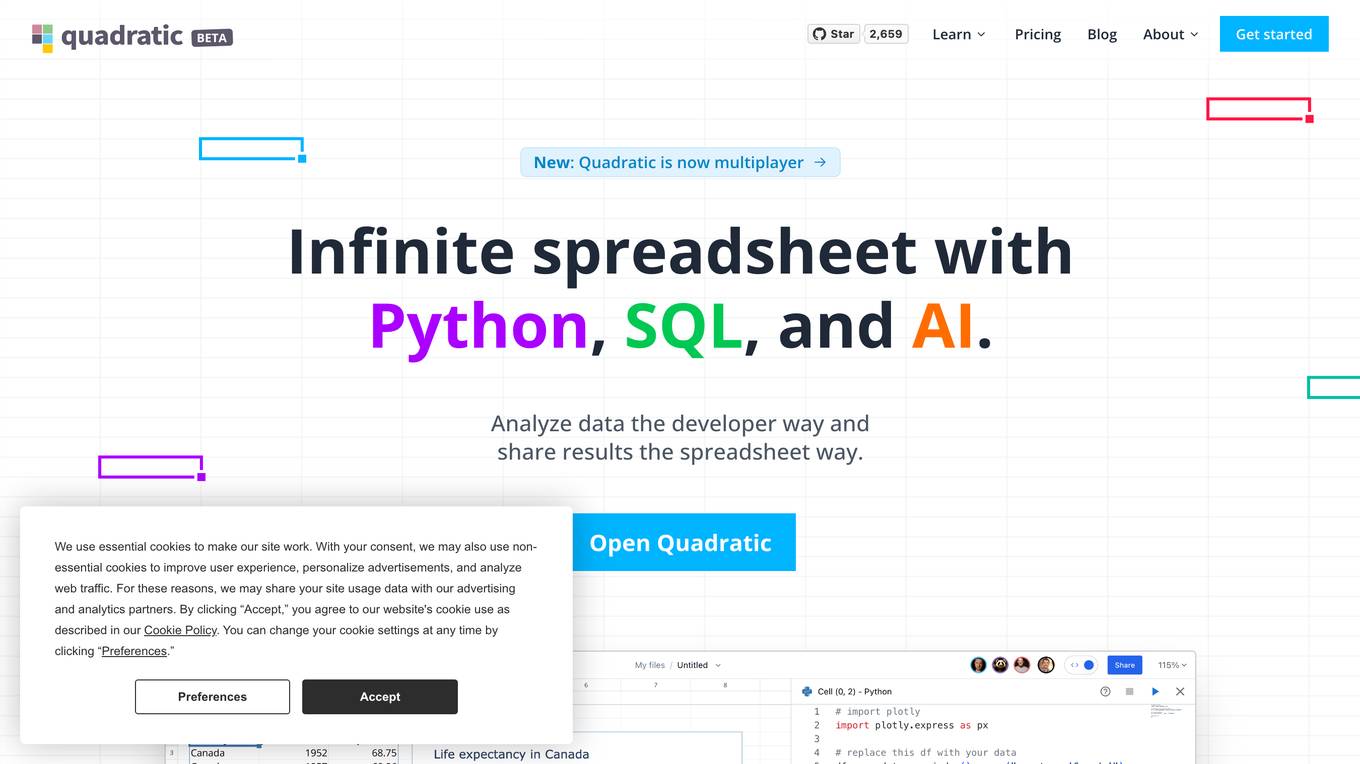
Quadratic
Quadratic is an infinite spreadsheet with Python, SQL, and AI. It combines the familiarity of a spreadsheet with the power of code, allowing users to analyze data, write code, and create visualizations in a single environment. With built-in Python library support, users can bring open source tools directly to their spreadsheets. Quadratic also features real-time collaboration, allowing multiple users to work on the same spreadsheet simultaneously. Additionally, Quadratic is built for speed and performance, utilizing Web Assembly and WebGL to deliver a smooth and responsive experience.
Pinecone
Pinecone is a vector database designed to help power AI applications for various companies. It offers a serverless platform that enables users to build knowledgeable AI applications quickly and cost-effectively. With Pinecone, users can perform low-latency vector searches for tasks such as search, recommendation, detection, and more. The platform is scalable, secure, and cloud-native, making it suitable for a wide range of AI projects.
Massed Compute
Massed Compute is an AI tool that provides cloud GPU services for VFX rendering, machine learning, high-performance computing, scientific simulations, and data analytics & visualization. The platform offers flexible and affordable plans, cutting-edge technology infrastructure, and timely creative problem-solving. As an NVIDIA Preferred Partner, Massed Compute ensures reliable and future-proof Tier III Data Center servers for various computing needs. Users can launch AI instances, scale machine learning projects, and access high-performance GPUs on-demand.
Tecton
Tecton is an AI data platform that helps build smarter AI applications by simplifying feature engineering, generating training data, serving real-time data, and enhancing AI models with context-rich prompts. It automates data pipelines, improves model accuracy, and lowers production costs, enabling faster deployment of AI models. Tecton abstracts away data complexity, provides a developer-friendly experience, and allows users to create features from any source. Trusted by top engineering teams, Tecton streamlines ML delivery processes, improves customer interactions, and automates release processes through CI/CD pipelines.
Pinecone
Pinecone is a vector database designed to build knowledgeable AI applications. It offers a serverless platform with high capacity and low cost, enabling users to perform low-latency vector search for various AI tasks. Pinecone is easy to start and scale, allowing users to create an account, upload vector embeddings, and retrieve relevant data quickly. The platform combines vector search with metadata filters and keyword boosting for better application performance. Pinecone is secure, reliable, and cloud-native, making it suitable for powering mission-critical AI applications.
PyAI
PyAI is an advanced AI tool designed for developers and data scientists to streamline their workflow and enhance productivity. It offers a wide range of AI capabilities, including machine learning algorithms, natural language processing, computer vision, and more. With PyAI, users can easily build, train, and deploy AI models for various applications, such as predictive analytics, image recognition, and text classification. The tool provides a user-friendly interface and comprehensive documentation to support users at every stage of their AI projects.
Kiln
Kiln is an AI tool designed for fine-tuning LLM models, generating synthetic data, and facilitating collaboration on datasets. It offers intuitive desktop apps, zero-code fine-tuning for various models, interactive visual tools for data generation, Git-based version control for datasets, and the ability to generate various prompts from data. Kiln supports a wide range of models and providers, provides an open-source library and API, prioritizes privacy, and allows structured data tasks in JSON format. The tool is free to use and focuses on rapid AI prototyping and dataset collaboration.
CVAT
CVAT is an open-source data annotation platform that helps teams of any size annotate data for machine learning. It is used by companies big and small in a variety of industries, including healthcare, retail, and automotive. CVAT is known for its intuitive user interface, advanced features, and support for a wide range of data formats. It is also highly extensible, allowing users to add their own custom features and integrations.
For similar tasks

Rationale
Rationale is a cutting-edge decision-making AI tool that leverages the power of the latest GPT technology and in-context learning. It is designed to assist users in making informed decisions by providing valuable insights and recommendations based on the data provided. With its advanced algorithms and machine learning capabilities, Rationale aims to streamline the decision-making process and enhance overall efficiency.

Talpa.ai
Talpa.ai is an AI-powered platform that offers advanced solutions for data analytics and automation. The platform leverages cutting-edge artificial intelligence technologies to provide businesses with valuable insights and streamline their operations. Talpa.ai helps organizations make data-driven decisions, optimize processes, and enhance overall efficiency. With its user-friendly interface and powerful features, Talpa.ai is a reliable partner for businesses looking to harness the power of AI for growth and success.
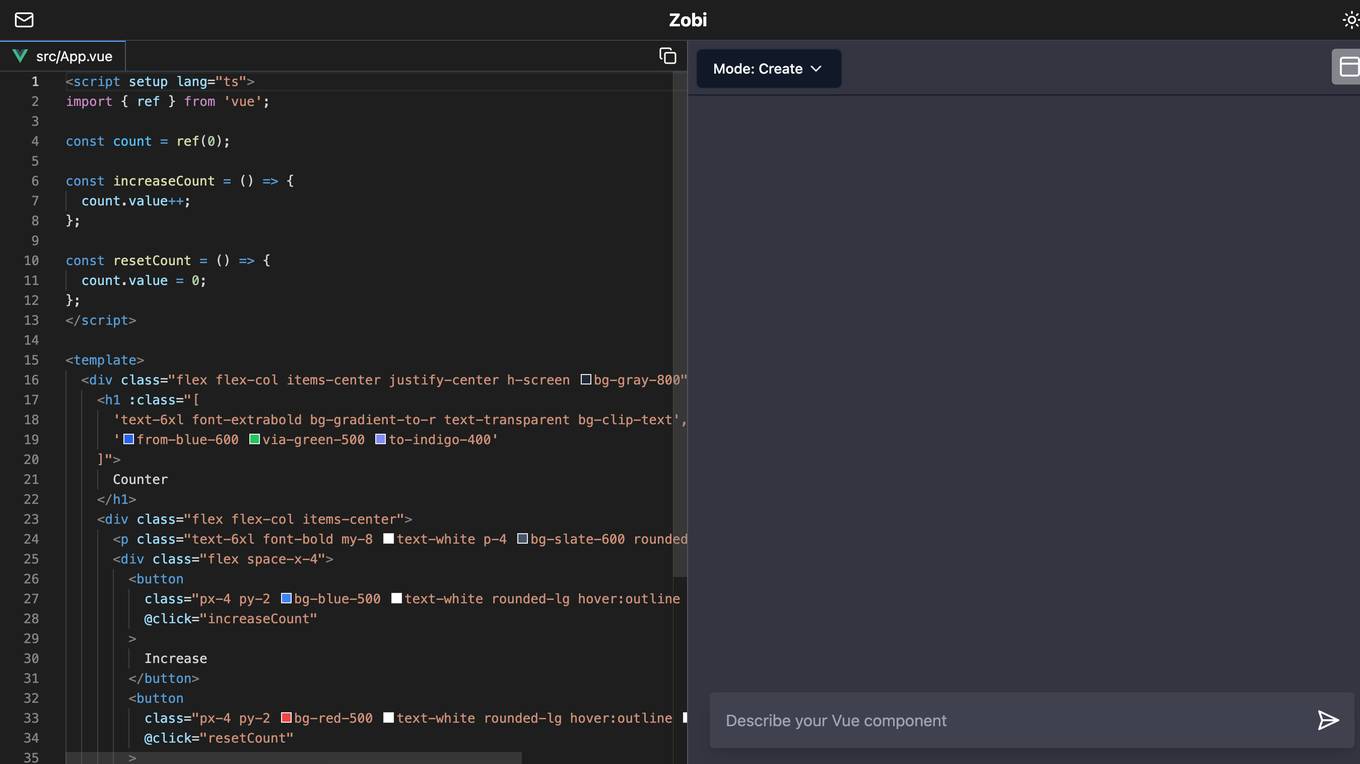
Zobi
The website Zobi is a web application that allows users to create a counter mode. Users can increment and reset the count using the provided functions. The interface is designed with a modern and user-friendly layout, making it easy for users to interact with the application.

Unlearn.ai
Unlearn.ai is an AI-powered platform that streamlines clinical trials by leveraging digital twins of patients. The platform replaces traditional siloed workflows with a unified workspace for trial design, planning, and analysis. By utilizing digital twins, data, and AI, Unlearn.ai helps teams achieve alignment faster, test assumptions earlier, and move forward with confidence in clinical development.
Promptly
Promptly is a generative AI platform designed for enterprises to build custom AI agents, applications, and chatbots without any coding experience. The platform allows users to seamlessly integrate their own data and GPT-powered models, supporting a wide variety of data sources. With features like model chaining, developer-friendly tools, and collaborative app building, Promptly empowers teams to quickly prototype and scale AI applications for various use cases. The platform also offers seamless integrations with popular workflows and tools, ensuring limitless possibilities for AI-powered solutions.
BlockSurvey
BlockSurvey is an AI-powered survey assistant that offers a comprehensive platform for creating, analyzing, and optimizing surveys with advanced AI capabilities. It prioritizes user data privacy and security, providing end-to-end encryption and compliance with industry standards. The platform features AI survey creation, analysis, thematic analysis, sentiment analysis, adaptive questioning, and sample responses generation. It also offers features like data encoding, survey optimization, secure surveys, anonymous surveys, and customization options. BlockSurvey caters to various industries and functions, ensuring privacy-first surveys with zero knowledge and decentralized survey capabilities.
Baseboard
Baseboard is an AI tool designed to help users generate insights from their data quickly and efficiently. With Baseboard, users can create visually appealing charts and visualizations for their websites or publications with the assistance of an AI-powered designer. The tool aims to streamline the data visualization process and provide users with valuable insights to make informed decisions.
Gestualy
Gestualy is an AI tool designed to measure and improve customer satisfaction and mood quickly and easily through gestures. It eliminates the need for cumbersome satisfaction surveys by allowing interactions with customers or guests through gestures. The tool uses artificial intelligence to make intelligent decisions in businesses. Gestualy generates valuable statistical reports for businesses, including satisfaction levels, gender, mood, and age, all while ensuring data protection and privacy compliance. It offers touchless interaction, immediate feedback, anonymized reports, and various services such as gesture recognition, facial analysis, gamification, and alert systems.
Strategy-First AI
Strategy-First AI is an AI tool designed to help businesses elevate their brand using artificial intelligence technology. The tool focuses on implementing strategic AI solutions to enhance brand performance and competitiveness in the market. With a user-friendly interface and advanced AI algorithms, Strategy-First AI provides businesses with valuable insights and recommendations to optimize their branding strategies and achieve business goals.
iListingAI
iListingAI is the UK's leading inventory software designed to streamline property inspection reports using AI technology. The application offers a user-friendly interface that combines vision, voice, and video to generate professional and legally compliant inventories 10x faster. With features like AI analysis, instant report generation, voice-first workflow, and ghost mode comparison, iListingAI revolutionizes the property inspection process for independent clerks and agencies.
Microsoft Azure
Microsoft Azure is a cloud computing service that offers a wide range of products and solutions for businesses and developers. It provides services such as databases, analytics, compute, containers, hybrid cloud, AI, application development, and more. Azure aims to help organizations innovate, modernize, and scale their operations by leveraging the power of the cloud. With a focus on flexibility, performance, and security, Azure is designed to support a variety of workloads and use cases across different industries.

Wizu
Wizu is an AI-powered platform that offers conversational surveys to enhance customer feedback. It helps businesses collect meaningful feedback, analyze AI-powered insights, and take clear actions based on the data. The platform utilizes AI technology to drive engagement, deliver better response rates, and provide richer insights for businesses to make data-driven decisions.
Lexum.ai
Lexum.ai is an AI-powered legal research and summaries tool designed to assist legal professionals in conducting efficient and accurate legal research. The tool utilizes advanced artificial intelligence algorithms to analyze vast amounts of legal data and provide users with comprehensive summaries and insights. By leveraging cutting-edge technology, Lexum.ai aims to streamline the legal research process and enhance the productivity of legal practitioners.
TimeToTok
TimeToTok is an AI Copilot and Agent designed for TikTok's growth. It uses LLM technology, similar to GPT, to analyze massive TikTok data and provide AI-driven insights to help creators improve their content, engagement, and monetization. The platform offers personalized growth strategies, viral content ideas, video optimization suggestions, competitor tracking, and 24/7 support to enhance users' TikTok presence and achieve significant growth.

Chatsheet
Chatsheet is an AI tool that revolutionizes the way spreadsheets are used. It leverages artificial intelligence to automate data entry, analysis, and visualization tasks, making spreadsheet management more efficient and intuitive. With Chatsheet, users can easily create, edit, and analyze data in a collaborative and interactive environment. The tool offers advanced features such as predictive analytics, natural language processing, and smart data suggestions to streamline decision-making processes. Chatsheet is designed to simplify complex data handling tasks and empower users to make data-driven decisions with ease.

ChatCSV
ChatCSV is a personal data analyst tool that allows users to upload CSV files and ask questions in natural language. It generates common questions about the data, visualizes answers with charts, and maintains chat history. It is useful for industries like retail, finance, banking, marketing, and advertising to understand trends, customer behavior, and more.

Lime
Lime is an AI-powered data research assistant designed to help users with data research tasks. It offers advanced capabilities to streamline the process of gathering and analyzing data, making it easier for users to derive insights and make informed decisions. Lime is equipped with cutting-edge AI technology that enables it to handle complex data sets efficiently and provide valuable recommendations. Whether you are a business professional, researcher, or student, Lime can assist you in various data-related tasks, saving you time and effort.
AI SEO Page
AI SEO Page is an AI-powered platform that focuses on the integration of artificial intelligence (AI) technology with Search Engine Optimization (SEO) strategies. The website provides insights and resources on leveraging AI in various aspects of SEO, including content creation, link building, analytics, user experience, and local SEO. It offers guidance on implementing AI-driven solutions to enhance search engine rankings and improve online visibility.
Business Automated
Business Automated is an independent automation consultancy that offers custom automation solutions for businesses. The website provides a range of products and services related to automation, including tools like Airtable, Google Sheets, and ChatGPT. Users can access tutorials on YouTube and read more on Medium to learn about automation techniques. Business Automated also offers products like Sales CRM and Cold emails with GPT4 and Airtable, demonstrating its focus on streamlining business processes through AI technology.

Airwiz
Airwiz is an AI data analyst tool designed to revolutionize data analysis experiences for users of Airtable. It enables users to perform complex data analysis tasks without the need for coding skills. By simply asking questions, users can gain valuable insights and make informed decisions based on their data. Airwiz simplifies the data analysis process, making it accessible to a wider audience.
ASK BOSCO®
ASK BOSCO® is an AI reporting and forecasting tool designed for agencies and retailers. It helps in collecting and analyzing data to improve browsing experience, customize marketing strategies, and provide analytics for better decision-making. The platform offers features like AI reporting, competitor benchmarking, AI budget planning, and data integrations to streamline marketing efforts and maximize ROI. Trusted by leading brands, ASK BOSCO® provides accurate forecasting and insights to optimize media spend and plan budgets effectively.
Synthreo
Synthreo is a Multi-Tenant AI Automation Platform designed for Managed Service Providers (MSPs) to empower businesses by streamlining operations, reducing costs, and driving growth through intelligent AI agents. The platform offers cutting-edge AI solutions that automate routine tasks, enhance decision-making, and facilitate collaboration between human teams and digital labor. Synthreo's AI agents provide transformative advantages for businesses of all sizes, enabling operational efficiency and strategic growth.
Rapid Editor
Rapid Editor is an advanced mapping tool that revolutionizes map editing by integrating cutting-edge technology and authoritative geospatial open data. It empowers OpenStreetMap mappers of all levels to quickly make accurate and fresh edits to maps. The tool saves effort by tapping into open data and AI-predicted features to draw map geometry, provides AI-analyzed satellite imagery for a high-level overview of unmapped areas, and displays open map data and machine learning detections in an intuitive user interface. Rapid Editor is designed to help map the world efficiently and is supported by a strong community of humanitarian and community groups.
RestoGPT AI
RestoGPT AI is a Restaurant Marketing and Sales Platform designed to help local restaurants streamline their online ordering and delivery processes. It acts as an AI employee that manages the entire online business, from building a branded website to customer database management, order processing, delivery dispatch, menu maintenance, customer support, and data-driven marketing campaigns. The platform aims to increase customer retention, generate more direct orders, and improve overall efficiency in restaurant operations.
For similar jobs
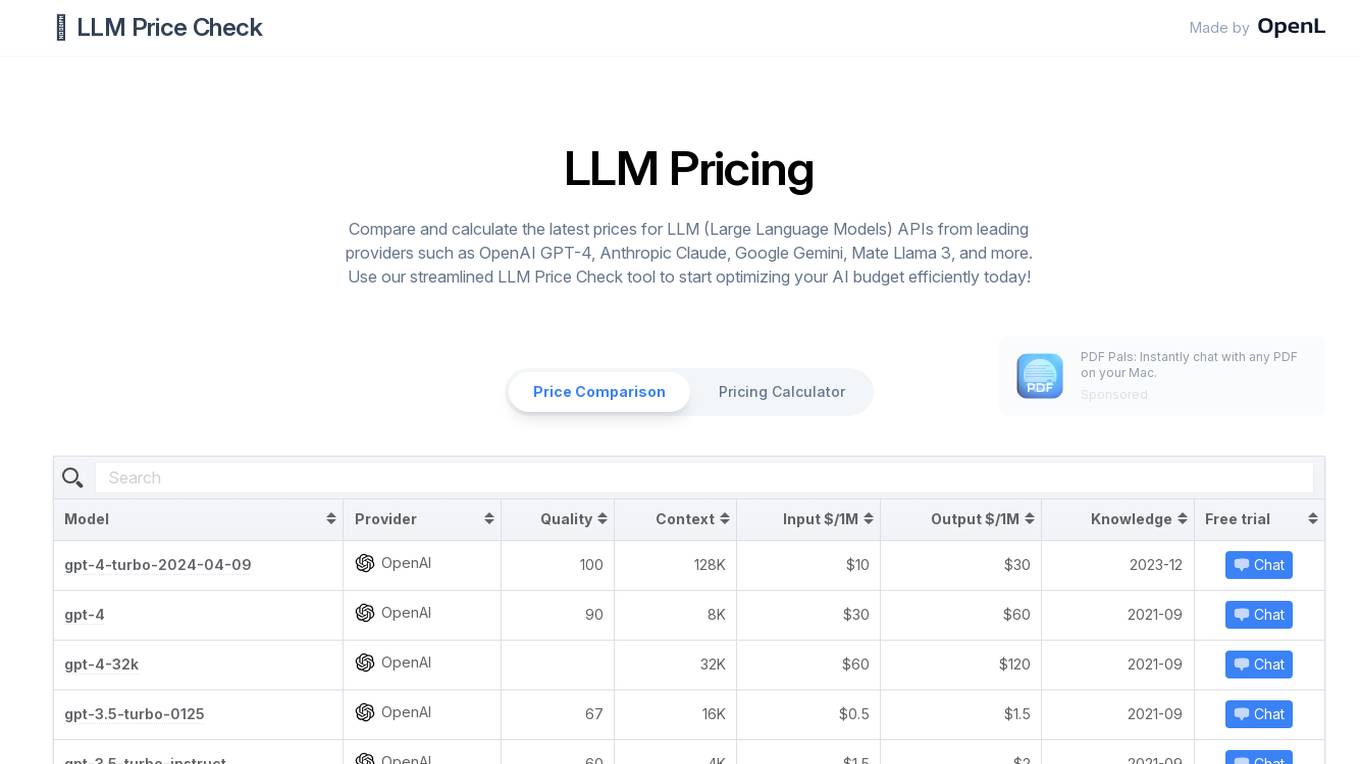
LLM Price Check
LLM Price Check is an AI tool designed to compare and calculate the latest prices for Large Language Models (LLM) APIs from leading providers such as OpenAI, Anthropic, Google, and more. Users can use the streamlined tool to optimize their AI budget efficiently by comparing pricing, sorting by various parameters, and searching for specific models. The tool provides a comprehensive overview of pricing information to help users make informed decisions when selecting an LLM API provider.
Radical Ventures
Radical Ventures is an AI-focused website that invests in people using artificial intelligence to shape the future of how we live, work, and play. The platform features founder stories of companies leveraging AI technology, AI research articles, and insights from AI pioneers. It aims to support and promote innovation in the field of artificial intelligence.
TWIML
TWIML is a platform that provides intelligent content focusing on Machine Learning and Artificial Intelligence technologies. It offers podcasts, articles, and resources to practitioners, innovators, and leaders, giving insights into the present and future of ML & AI. The platform covers a wide range of topics such as deep reinforcement learning, fusion energy production, data-centric AI, responsible AI, and machine learning platform strategies.
Practical Deep Learning for Coders
Practical Deep Learning for Coders is a free course designed for individuals with some coding experience who want to learn how to apply deep learning and machine learning to practical problems. The course covers topics such as building and training deep learning models for computer vision, natural language processing, tabular analysis, and collaborative filtering problems. It is based on a 5-star rated book and does not require any special hardware or software. The course is led by Jeremy Howard, a renowned expert in machine learning and the President and Chief Scientist of Kaggle.
Imbue
Imbue is a company focused on building AI systems that can reason and code, with the goal of rekindling the dream of the personal computer by creating practical AI agents that can accomplish larger goals and work safely in the real world. The company emphasizes innovation in AI technology and aims to push the boundaries of what AI can achieve in various fields.

Decrypt
Decrypt is an AI-powered platform that provides news and information on topics such as AI, Bitcoin, culture, gaming, and crypto. The platform offers detailed insights into coin prices, market trends, and top news stories related to the cryptocurrency world. Decrypt combines AI-generated content with human curation to deliver up-to-date and relevant information to its users.
EnterpriseAI
EnterpriseAI is an advanced computing platform that focuses on the intersection of high-performance computing (HPC) and artificial intelligence (AI). The platform provides in-depth coverage of the latest developments, trends, and innovations in the AI-enabled computing landscape. EnterpriseAI offers insights into various sectors such as financial services, government, healthcare, life sciences, energy, manufacturing, retail, and academia. The platform covers a wide range of topics including AI applications, security, data storage, networking, and edge/IoT technologies.

KINOMOTO.MAG
KINOMOTO.MAG is a platform that delves into the fusion of culture and technology, exploring how they influence the art world. The website showcases the latest advancements in AI technology and its impact on artistic expression. Through insightful articles and features, Kinomoto.Mag aims to bridge the gap between traditional art forms and cutting-edge AI innovations.
AI Parabellum
AI Parabellum is a specialized AI Tools Directory that aims to unite creators, innovators, and AI enthusiasts. It serves as a platform to discover and showcase the most advanced AI tools in the industry. The website provides a comprehensive collection of AI tools across various categories, catering to individuals and businesses looking to leverage artificial intelligence for different purposes.
Labellerr
Labellerr is a data labeling software that helps AI teams prepare high-quality labels 99 times faster for Vision, NLP, and LLM models. The platform offers automated annotation, advanced analytics, and smart QA to process millions of images and thousands of hours of videos in just a few weeks. Labellerr's powerful analytics provides full control over output quality and project management, making it a valuable tool for AI labeling partners.
Papers With Code
Papers With Code is an AI tool that provides access to the latest research papers in the field of Machine Learning, along with corresponding code implementations. It offers a platform for researchers and enthusiasts to stay updated on state-of-the-art datasets, methods, and trends in the ML domain. Users can explore a wide range of topics such as language modeling, image generation, virtual try-on, and more through the collection of papers and code available on the website.
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
SiliconANGLE
SiliconANGLE is an AI tool that focuses on enterprise and emerging technologies. It provides insights, analysis, and news on various tech topics such as Cloud, AI, Security, Blockchain, Big Data, and more. The platform offers in-depth coverage of industry events, research reports, and exclusive interviews with tech experts.
THE DECODER
THE DECODER is an AI tool that provides news, insights, and updates on artificial intelligence across various domains such as business, research, and society. It covers the latest advancements in AI technologies, applications, and their impact on different industries. THE DECODER aims to keep its audience informed about the rapidly evolving field of artificial intelligence.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.
CCN
CCN is a website providing news, analysis, and guides related to cryptocurrencies, blockchain technology, and AI developments. The platform covers a wide range of topics including crypto investing, exchanges, gambling, technology advancements, and regulatory updates. With a focus on delivering accurate and up-to-date information, CCN aims to educate and inform its audience about the latest trends and developments in the crypto and AI industries.
vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.
Toloka AI
Toloka AI is a data labeling platform that empowers AI development by combining human insight with machine learning models. It offers adaptive AutoML, human-in-the-loop workflows, large language models, and automated data labeling. The platform supports various AI solutions with human input, such as e-commerce services, content moderation, computer vision, and NLP. Toloka AI aims to accelerate machine learning processes by providing high-quality human-labeled data and leveraging the power of the crowd.
Next AI Jobs
Next AI Jobs is an AI-powered platform that specializes in connecting professionals with job opportunities in the fields of Artificial Intelligence (AI), Machine Learning (ML), Natural Language Processing (NLP), and Data Science. The platform utilizes advanced algorithms to match candidates with relevant job listings, streamlining the recruitment process for both employers and job seekers. Next AI Jobs provides a user-friendly interface where users can create profiles, upload resumes, and apply for jobs with ease. With a focus on the rapidly growing AI industry, Next AI Jobs aims to bridge the gap between talented individuals and top-tier companies seeking AI expertise.

AI Investing Tools
AI Investing Tools is a curated directory of AI tools designed to help users automate their investing process. The platform offers a handpicked collection of AI investing tools that assist in making more money, developing trading strategies, automating investing, rebalancing portfolios, and analyzing markets. It aims to leverage AI technology to enhance trading efficiency, optimize portfolios, and eliminate emotional biases in investment decisions.
Geeky Gadgets
Geeky Gadgets is a technology news website that covers the latest updates on Apple, Android, deals, gadgets, technology hardware, gaming, and guides. The site features articles on various AI tools and applications, providing insights and reviews to help professionals navigate the world of artificial intelligence.

AICamp
AICamp is an AI application that offers live learning events, workshops, meetups, and seminars on various AI-related topics such as machine learning, data processing, generative AI, and more. It provides a platform for developers to share knowledge, practical experiences, and best practices in the field of AI and data science. AICamp aims to connect like-minded individuals globally and facilitate learning and networking opportunities in the AI community.
DMLR
DMLR (Data-centric Machine Learning Research) is an AI tool that focuses on advancing research in data-centric machine learning. It organizes workshops, research retreats, maintains a journal, and runs a working group to support infrastructure projects. The platform covers topics such as data collection, governance, bias, and drifts, as well as data-centric explainable AI and AI alignment. DMLR encourages submissions around the theme of AI for Science, using AI to tackle scientific challenges and accelerate discoveries.
DeepLearning.AI
DeepLearning.AI is an online platform offering a wide range of courses, discussions, and resources related to artificial intelligence. Users can engage in discussions, ask questions, and participate in various AI projects. The platform covers topics such as deep learning, machine learning, natural language processing, and more. DeepLearning.AI aims to provide a comprehensive learning experience for individuals interested in AI technologies.