
booster
Booster - open accelerator for LLM models. Better inference and debugging for AI hackers
Stars: 133

Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.
README:
![]()
Booster, according to Merriam-Webster dictionary:
- an auxiliary device for increasing force, power, pressure, or effectiveness
- the first stage of a multistage rocket providing thrust for the launching and the initial part of the flight
Large Model Booster aims to be an simple and mighty LLM inference accelerator both for those who needs to scale GPTs within production environment or just experiment with models on its own.
- Built with performance and scaling in mind thanks Golang and C++
- No more problems with Python dependencies
- CPU-only inference if needed: any Intel or AMD x64, ARM64 and Apple Silicon
- GPUs supported as well: Nvidia CUDA, Apple Metal, even OpenCL cards
- Split really big models between a number of GPU (warp LLaMA 70B with 2x RTX 3090)
- Great performance on CPU only machines, fast as hell inference on monsters with beefy GPUs
- Both regular FP16/FP32 models and their quantised versions are supported - 4-bit really rocks!
- Popular LLM architectures already there: LLaMA, Mistral, Gemma, etc...
- Special bonus: SOTA Janus Sampling for code generation and non English languages
Within first month of llama.go development I was literally shocked of how original ggml.cpp project made it very clear - there are no limits for talented people on bringing mind-blowing features and moving to AI future.
So I've decided to start a new project where best-in-class C++ / CUDA core will be embedded into mighty Golang server ready for robust and performant inference at large scale within real production environments.
- [x] Rebrand project again :) Collider => Booster
- [x] Complete LLaMA v3 and v3.1 support
- [x] OpenAI API Chat Completion compatible endpoints
- [x] Ollama compatible endpoints
- [x] Interactive mode for chatting from command line
- [x] Update Janus Sampling for LLaMA-3
- [ ] ... and finally V3 release!
- [ ] Broader integration with Ollama ecosystem
- [ ] Smarter context expanding when reaching its limits
- [ ] Embedded web UI with no external dependencies
- [ ] Native Windows binaries
- [ ] Prebuilt binaries for all platforms
- [ ] Support LLaVA multi-modal models inference
- [ ] Better code test coverage
- [ ] Perplexity computation useful for benchmarking
Booster was (and still) developed on Mac with Apple Silicon M1 processor, so it's really easy peasy:
make macFollow step 1 and step 2, then just make!
Ubuntu Step 1: Install C++ and Golang compilers, as well some developer libraries
sudo apt update -y && sudo apt upgrade -y && \
apt install -y git git-lfs make build-essential && \
wget https://golang.org/dl/go1.21.5.linux-amd64.tar.gz && \
tar -xf go1.21.5.linux-amd64.tar.gz -C /usr/local && \
rm go1.21.5.linux-amd64.tar.gz && \
echo 'export PATH="${PATH}:/usr/local/go/bin"' >> ~/.bashrc && source ~/.bashrc
Ubuntu Step 2: Install Nvidia drivers and CUDA Toolkit 12.2 with NVCC
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin && \
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600 && \
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/3bf863cc.pub && \
sudo add-apt-repository "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/ /" && \
sudo apt update -y && \
sudo apt install -y cuda-toolkit-12-2
Now you are ready to rock!
make cudaYou shold go through steps below:
- Build the server from sources [ Mac inference as example ]
make clean && make mac- Download the model, like [ Hermes 2 Pro ] based on [ LLaMA-v3-8B ] quantized to GGUF Q4KM format:
wget https://huggingface.co/NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF/resolve/main/Hermes-2-Pro-Llama-3-8B-Q4_K_M.gguf- Create configuration file and place it to the same directory [ see config.sample.yaml ]
id: mac
host: localhost
port: 8080
log: booster.log
deadline: 180
pods:
gpu:
model: hermes
prompt: chat
sampling: janus
threads: 1
gpus: [ 100 ]
batch: 512
models:
hermes:
name: Hermes2 Pro 8B
path: ~/models/Hermes-2-Pro-Llama-3-8B-Q4_K_M.gguf
context: 8K
predict: 1K
prompts:
chat:
locale: en_US
prompt: "Today is {DATE}. You are virtual assistant. Please answer the question."
system: "<|im_start|>system\n{PROMPT}<|im_end|>"
user: "\n<|im_start|>user\n{USER}<|im_end|>"
assistant: "\n<|im_start|>assistant\n{ASSISTANT}<|im_end|>"
samplings:
janus:
janus: 1
depth: 200
scale: 0.97
hi: 0.99
lo: 0.96- When all is done, start the server with debug enabled to be sure it working
Launch Booster in interactive mode to just chatting with the model:
./boosterLaunch Booster as server to handle all API endpoints and show debug info:
./booster --server --debug- Now use Booster with Ollama / OpenAI API or POST JSON to native Async API
http://localhost:8080/jobs
{
"id": "5fb8ebd0-e0c9-4759-8f7d-35590f6c9fc6",
"prompt": "Who are you?"
}- See results with native HTTP GET to native Async API
http://localhost:8080/jobs/5fb8ebd0-e0c9-4759-8f7d-35590f6c9fc6
{
{
"id": "5fb8ebd0-e0c9-4759-8f7d-35590f6c9f77",
"output": "I'm a virtual assistant.",
"prompt": "Who are you?",
"status": "finished"
}
}- See instructions within
booster.servicefile on how to create daemond service out of this API server.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for booster
Similar Open Source Tools
booster
Booster is a powerful inference accelerator designed for scaling large language models within production environments or for experimental purposes. It is built with performance and scaling in mind, supporting various CPUs and GPUs, including Nvidia CUDA, Apple Metal, and OpenCL cards. The tool can split large models across multiple GPUs, offering fast inference on machines with beefy GPUs. It supports both regular FP16/FP32 models and quantised versions, along with popular LLM architectures. Additionally, Booster features proprietary Janus Sampling for code generation and non-English languages.
Devon
Devon is an open-source pair programmer tool designed to facilitate collaborative coding sessions. It provides features such as multi-file editing, codebase exploration, test writing, bug fixing, and architecture exploration. The tool supports Anthropic, OpenAI, and Groq APIs, with plans to add more models in the future. Devon is community-driven, with ongoing development goals including multi-model support, plugin system for tool builders, self-hostable Electron app, and setting SOTA on SWE-bench Lite. Users can contribute to the project by developing core functionality, conducting research on agent performance, providing feedback, and testing the tool.

refact-lsp
Refact Agent is a small executable written in Rust as part of the Refact Agent project. It lives inside your IDE to keep AST and VecDB indexes up to date, supporting connection graphs between definitions and usages in popular programming languages. It functions as an LSP server, offering code completion, chat functionality, and integration with various tools like browsers, databases, and debuggers. Users can interact with it through a Text UI in the command line.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.
open-chatgpt
Open-ChatGPT is an open-source library that enables users to train a hyper-personalized ChatGPT-like AI model using their own data with minimal computational resources. It provides an end-to-end training framework for ChatGPT-like models, supporting distributed training and offloading for extremely large models. The project implements RLHF (Reinforcement Learning with Human Feedback) powered by transformer library and DeepSpeed, allowing users to create high-quality ChatGPT-style models. Open-ChatGPT is designed to be user-friendly and efficient, aiming to empower users to develop their own conversational AI models easily.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.

ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
rag-chat
The `@upstash/rag-chat` package simplifies the development of retrieval-augmented generation (RAG) chat applications by providing Next.js compatibility with streaming support, built-in vector store, optional Redis compatibility for fast chat history management, rate limiting, and disableRag option. Users can easily set up the environment variables and initialize RAGChat to interact with AI models, manage knowledge base, chat history, and enable debugging features. Advanced configuration options allow customization of RAGChat instance with built-in rate limiting, observability via Helicone, and integration with Next.js route handlers and Vercel AI SDK. The package supports OpenAI models, Upstash-hosted models, and custom providers like TogetherAi and Replicate.

lmnr
Laminar is an all-in-one open-source platform designed for engineering AI products. It allows users to trace, evaluate, label, and analyze LLM data efficiently. The platform offers features such as automatic tracing of common AI frameworks and SDKs, local and online evaluations, simple UI for data labeling, dataset management, and scalability with gRPC communication. Laminar is built with a modern open-source stack including RabbitMQ, Postgres, Clickhouse, and Qdrant for semantic similarity search. It provides fast and beautiful dashboards for traces, evaluations, and labels, making it a comprehensive tool for AI product development.
AiR
AiR is an AI tool built entirely in Rust that delivers blazing speed and efficiency. It features accurate translation and seamless text rewriting to supercharge productivity. AiR is designed to assist non-native speakers by automatically fixing errors and polishing language to sound like a native speaker. The tool is under heavy development with more features on the horizon.

ichigo
Ichigo is a local real-time voice AI tool that uses an early fusion technique to extend a text-based LLM to have native 'listening' ability. It is an open research experiment with improved multiturn capabilities and the ability to refuse processing inaudible queries. The tool is designed for open data, open weight, on-device Siri-like functionality, inspired by Meta's Chameleon paper. Ichigo offers a web UI demo and Gradio web UI for users to interact with the tool. It has achieved enhanced MMLU scores, stronger context handling, advanced noise management, and improved multi-turn capabilities for a robust user experience.
gpt-computer-assistant
GPT Computer Assistant (GCA) is an open-source framework designed to build vertical AI agents that can automate tasks on Windows, macOS, and Ubuntu systems. It leverages the Model Context Protocol (MCP) and its own modules to mimic human-like actions and achieve advanced capabilities. With GCA, users can empower themselves to accomplish more in less time by automating tasks like updating dependencies, analyzing databases, and configuring cloud security settings.
clearml-serving
ClearML Serving is a command line utility for model deployment and orchestration, enabling model deployment including serving and preprocessing code to a Kubernetes cluster or custom container based solution. It supports machine learning models like Scikit Learn, XGBoost, LightGBM, and deep learning models like TensorFlow, PyTorch, ONNX. It provides a customizable RestAPI for serving, online model deployment, scalable solutions, multi-model per container, automatic deployment, canary A/B deployment, model monitoring, usage metric reporting, metric dashboard, and model performance metrics. ClearML Serving is modular, scalable, flexible, customizable, and open source.

evalchemy
Evalchemy is a unified and easy-to-use toolkit for evaluating language models, focusing on post-trained models. It integrates multiple existing benchmarks such as RepoBench, AlpacaEval, and ZeroEval. Key features include unified installation, parallel evaluation, simplified usage, and results management. Users can run various benchmarks with a consistent command-line interface and track results locally or integrate with a database for systematic tracking and leaderboard submission.
For similar tasks

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.
LafTools
LafTools is a privacy-first, self-hosted, fully open source toolbox designed for programmers. It offers a wide range of tools, including code generation, translation, encryption, compression, data analysis, and more. LafTools is highly integrated with a productive UI and supports full GPT-alike functionality. It is available as Docker images and portable edition, with desktop edition support planned for the future.
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.
auto-dev
AutoDev is an AI-powered coding wizard that supports multiple languages, including Java, Kotlin, JavaScript/TypeScript, Rust, Python, Golang, C/C++/OC, and more. It offers a range of features, including auto development mode, copilot mode, chat with AI, customization options, SDLC support, custom AI agent integration, and language features such as language support, extensions, and a DevIns language for AI agent development. AutoDev is designed to assist developers with tasks such as auto code generation, bug detection, code explanation, exception tracing, commit message generation, code review content generation, smart refactoring, Dockerfile generation, CI/CD config file generation, and custom shell/command generation. It also provides a built-in LLM fine-tune model and supports UnitEval for LLM result evaluation and UnitGen for code-LLM fine-tune data generation.

LLM4SE
The collection is actively updated with the help of an internal literature search engine.
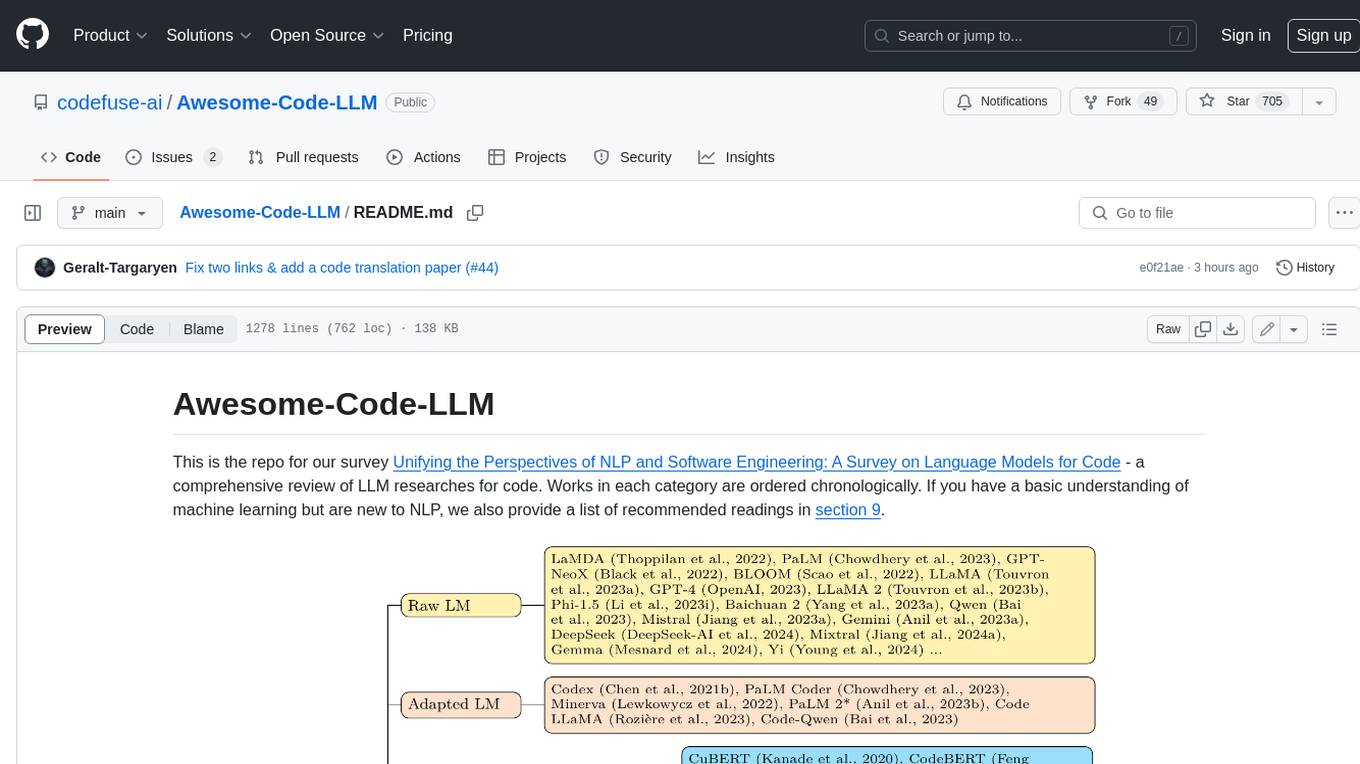
Awesome-Code-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, in lowercase letters: 'description' (detailed description of the repo, must be less than 400 words,Ensure that no line breaks and quotation marks.),'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,user may use those keyword to find the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in lowercase letters), 'answer' (in english languages)

crewAI
crewAI is a cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It provides a flexible and structured approach to AI collaboration, enabling users to define agents with specific roles, goals, and tools, and assign them tasks within a customizable process. crewAI supports integration with various LLMs, including OpenAI, and offers features such as autonomous task delegation, flexible task management, and output parsing. It is open-source and welcomes contributions, with a focus on improving the library based on usage data collected through anonymous telemetry.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.
tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.