
llava-docker
Docker image for LLaVA: Large Language and Vision Assistant
Stars: 59

This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
README:


- Ubuntu 22.04 LTS
- CUDA 11.8
- Python 3.10.12
- LLaVA v1.2.0 (LLaVA 1.6)
- Torch 2.1.2
- xformers 0.0.23.post1
- Jupyter Lab
- runpodctl
- OhMyRunPod
- RunPod File Uploader
- croc
- rclone
- speedtest-cli
- screen
- tmux
- llava-v1.6-mistral-7b model
This image is designed to work on RunPod. You can use my custom RunPod template to launch it on RunPod.
[!NOTE] You will need to edit the
docker-bake.hclfile and updateUSERNAME, andRELEASE. You can obviously edit the other values too, but these are the most important ones.
# Clone the repo
git clone https://github.com/ashleykleynhans/llava-docker.git
# Log in to Docker Hub
docker login
# Build the image, tag the image, and push the image to Docker Hub
cd llava-docker
docker buildx bake -f docker-bake.hcl --pushdocker run -d \
--gpus all \
-v /workspace \
-p 3000:3001 \
-p 8888:8888 \
-p 2999:2999 \
-e VENV_PATH="/workspace/venvs/llava" \
ashleykza/llava:latestYou can obviously substitute the image name and tag with your own.
[!IMPORTANT] If you select a 13B or larger model, CUDA will result in OOM errors with a GPU that has less than 48GB of VRAM, so A6000 or higher is recommended for 13B.
You can add an environment called MODEL to your Docker container to
specify the model that should be downloaded. If the MODEL environment
variable is not set, the model will default to liuhaotian/llava-v1.6-mistral-7b.
| Model | Environment Variable Value | Version | LLM | Default |
|---|---|---|---|---|
| llava-v1.6-vicuna-7b | liuhaotian/llava-v1.6-vicuna-7b | LLaVA-1.6 | Vicuna-7B | no |
| llava-v1.6-vicuna-13b | liuhaotian/llava-v1.6-vicuna-13b | LLaVA-1.6 | Vicuna-13B | no |
| llava-v1.6-mistral-7b | liuhaotian/llava-v1.6-mistral-7b | LLaVA-1.6 | Mistral-7B | yes |
| llava-v1.6-34b | liuhaotian/llava-v1.6-34b | LLaVA-1.6 | Hermes-Yi-34B | no |
| Model | Environment Variable Value | Version | Size | Default |
|---|---|---|---|---|
| llava-v1.5-7b | liuhaotian/llava-v1.5-7b | LLaVA-1.5 | 7B | no |
| llava-v1.5-13b | liuhaotian/llava-v1.5-13b | LLaVA-1.5 | 13B | no |
| BakLLaVA-1 | SkunkworksAI/BakLLaVA-1 | LLaVA-1.5 | 7B | no |
| Connect Port | Internal Port | Description |
|---|---|---|
| 3000 | 3001 | LLaVA |
| 8888 | 8888 | Jupyter Lab |
| 2999 | 2999 | RunPod File Uploader |
| Variable | Description | Default |
|---|---|---|
| VENV_PATH | Set the path for the Python venv for the app | /workspace/venvs/llava |
| JUPYTER_LAB_PASSWORD | Set a password for Jupyter lab | not set - no password |
| DISABLE_AUTOLAUNCH | Disable LLaVA from launching automatically | enabled |
| MODEL | The path of the Huggingface model | liuhaotian/llava-v1.6-mistral-7b |
LLaVA creates log files, and you can tail the log files instead of killing the services to view the logs.
| Application | Log file |
|---|---|
| Controller | /workspace/logs/controller.log |
| Webserver | /workspace/logs/webserver.log |
| Model Worker | /workspace/logs/model-worker.log |
For example:
tail -f /workspace/logs/webserver.logIf you are running the RunPod template, edit your pod and add HTTP port 5000.
If you are running locally, add a port mapping for port 5000.
# Stop model worker and controller to free up VRAM
fuser -k 10000/tcp 40000/tcp
# Install dependencies
source /workspace/venvs/llava/bin/activate
pip3 install flask protobuf
cd /workspace/LLaVA
export HF_HOME="/workspace"
python -m llava.serve.api -H 0.0.0.0 -p 5000You can use the test script to test your API.
- Matthew Berman for giving me a demo on LLaVA, as well as his amazing YouTube videos.
Pull requests and issues on GitHub are welcome. Bug fixes and new features are encouraged.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llava-docker
Similar Open Source Tools
llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
TinyLLM
TinyLLM is a project that helps build a small locally hosted language model with a web interface using consumer-grade hardware. It supports multiple language models, builds a local OpenAI API web service, and serves a Chatbot web interface with customizable prompts. The project requires specific hardware and software configurations for optimal performance. Users can run a local language model using inference servers like vLLM, llama-cpp-python, and Ollama. The Chatbot feature allows users to interact with the language model through a web-based interface, supporting features like summarizing websites, displaying news headlines, stock prices, weather conditions, and using vector databases for queries.

vscode-unify-chat-provider
The 'vscode-unify-chat-provider' repository is a tool that integrates multiple LLM API providers into VS Code's GitHub Copilot Chat using the Language Model API. It offers free tier access to mainstream models, perfect compatibility with major LLM API formats, deep adaptation to API features, best performance with built-in parameters, out-of-the-box configuration, import/export support, great UX, and one-click use of various models. The tool simplifies model setup, migration, and configuration for users, providing a seamless experience within VS Code for utilizing different language models.
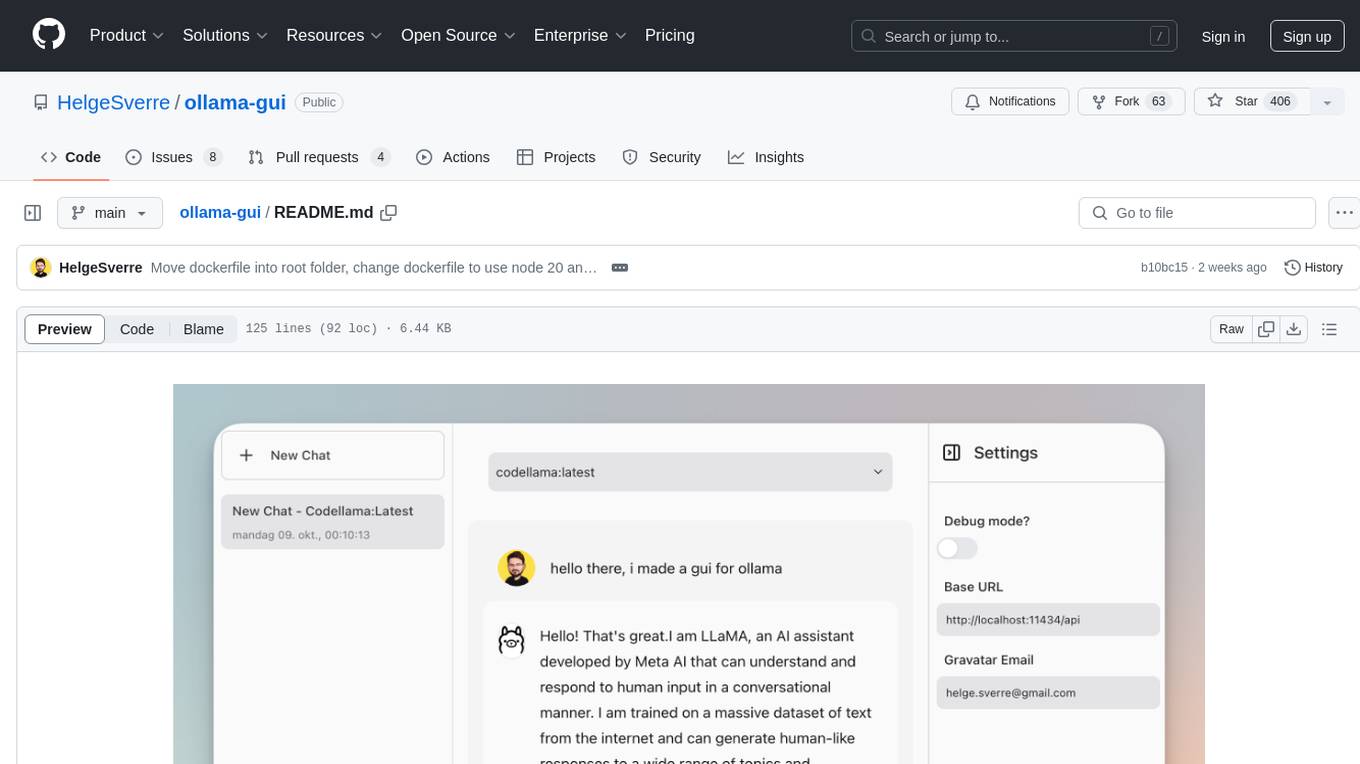
ollama-gui
Ollama GUI is a web interface for ollama.ai, a tool that enables running Large Language Models (LLMs) on your local machine. It provides a user-friendly platform for chatting with LLMs and accessing various models for text generation. Users can easily interact with different models, manage chat history, and explore available models through the web interface. The tool is built with Vue.js, Vite, and Tailwind CSS, offering a modern and responsive design for seamless user experience.
manim-generator
The 'manim-generator' repository focuses on automatic video generation using an agentic LLM flow combined with the manim python library. It experiments with automated Manim video creation by delegating code drafting and validation to specific roles, reducing render failures, and improving visual consistency through iterative feedback and vision inputs. The project also includes 'Manim Bench' for comparing AI models on full Manim video generation.
llumen
Llumen is a self-hosted interface optimized for modest hardware like Raspberry Pi, old laptops, and minimal VPS. It offers privacy without complexity, providing essential features with minimal resource demands. Users can enjoy sub-second cold starts, real-time token streaming, various chat modes, rich media support, and a universal API for OpenAI-compatible providers. The tool has a small footprint with a binary size of around 17MB and RAM usage under 128MB. Llumen aims to simplify the setup process and offer a user-friendly experience for individuals seeking a privacy-focused solution.
star-vector
StarVector is a multimodal vision-language model for Scalable Vector Graphics (SVG) generation. It can be used to perform image2SVG and text2SVG generation. StarVector works directly in the SVG code space, leveraging visual understanding to apply accurate SVG primitives. It achieves state-of-the-art performance in producing compact and semantically rich SVGs. The tool provides Hugging Face model checkpoints for image2SVG vectorization, with models like StarVector-8B and StarVector-1B. It also offers datasets like SVG-Stack, SVG-Fonts, SVG-Icons, SVG-Emoji, and SVG-Diagrams for evaluation. StarVector can be trained using Deepspeed or FSDP for tasks like Image2SVG and Text2SVG generation. The tool provides a demo with options for HuggingFace generation or VLLM backend for faster generation speed.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.
aikit
AIKit is a one-stop shop to quickly get started to host, deploy, build and fine-tune large language models (LLMs). AIKit offers two main capabilities: Inference: AIKit uses LocalAI, which supports a wide range of inference capabilities and formats. LocalAI provides a drop-in replacement REST API that is OpenAI API compatible, so you can use any OpenAI API compatible client, such as Kubectl AI, Chatbot-UI and many more, to send requests to open-source LLMs! Fine Tuning: AIKit offers an extensible fine tuning interface. It supports Unsloth for fast, memory efficient, and easy fine-tuning experience.
FalkorDB
FalkorDB is the first queryable Property Graph database to use sparse matrices to represent the adjacency matrix in graphs and linear algebra to query the graph. Primary features: * Adopting the Property Graph Model * Nodes (vertices) and Relationships (edges) that may have attributes * Nodes can have multiple labels * Relationships have a relationship type * Graphs represented as sparse adjacency matrices * OpenCypher with proprietary extensions as a query language * Queries are translated into linear algebra expressions

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.

hcaptcha-challenger
hCaptcha Challenger is a tool designed to gracefully face hCaptcha challenges using a multimodal large language model. It does not rely on Tampermonkey scripts or third-party anti-captcha services, instead implementing interfaces for 'AI vs AI' scenarios. The tool supports various challenge types such as image labeling, drag and drop, and advanced tasks like self-supervised challenges and Agentic Workflow. Users can access documentation in multiple languages and leverage resources for tasks like model training, dataset annotation, and model upgrading. The tool aims to enhance user experience in handling hCaptcha challenges with innovative AI capabilities.
openkore
OpenKore is a custom client and intelligent automated assistant for Ragnarok Online. It is a free, open source, and cross-platform program (Linux, Windows, and MacOS are supported). To run OpenKore, you need to download and extract it or clone the repository using Git. Configure OpenKore according to the documentation and run openkore.pl to start. The tool provides a FAQ section for troubleshooting, guidelines for reporting issues, and information about botting status on official servers. OpenKore is developed by a global team, and contributions are welcome through pull requests. Various community resources are available for support and communication. Users are advised to comply with the GNU General Public License when using and distributing the software.
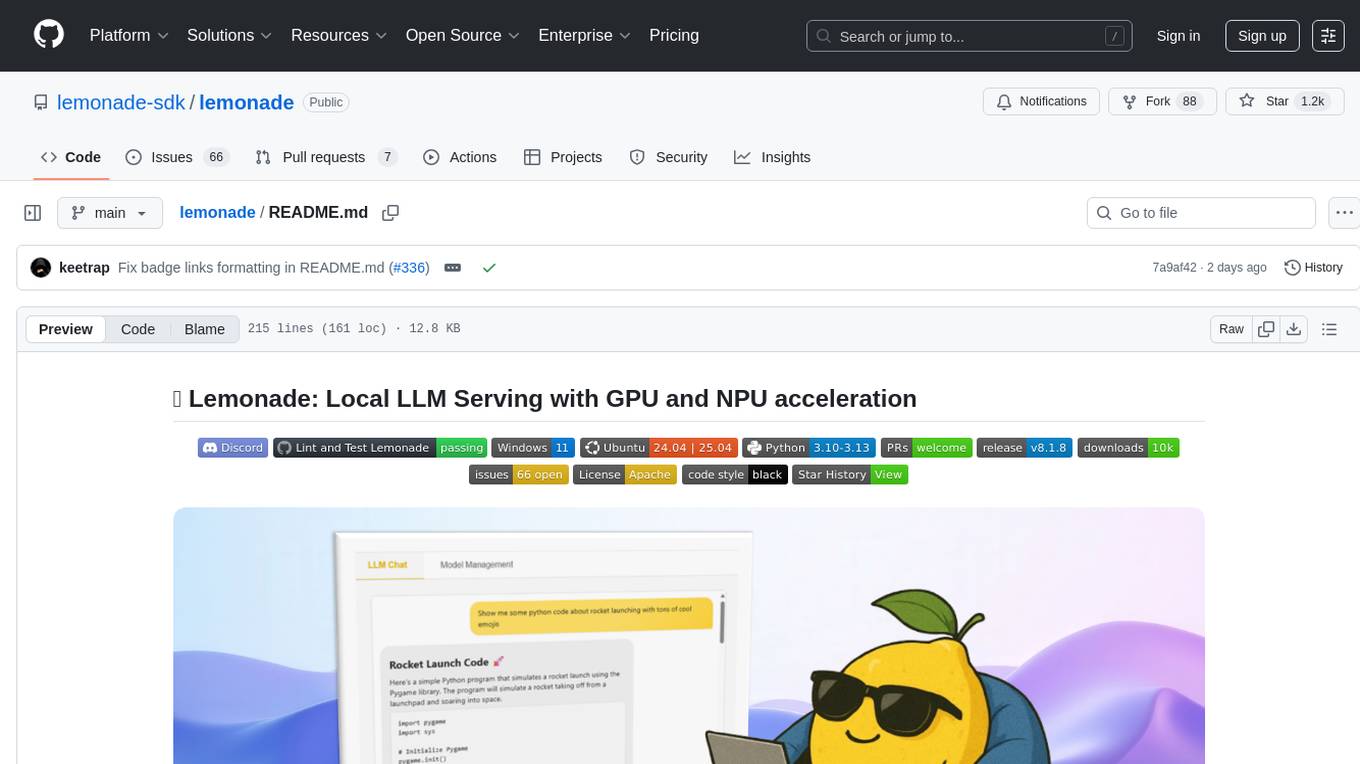
lemonade
Lemonade is a tool that helps users run local Large Language Models (LLMs) with high performance by configuring state-of-the-art inference engines for their Neural Processing Units (NPUs) and Graphics Processing Units (GPUs). It is used by startups, research teams, and large companies to run LLMs efficiently. Lemonade provides a high-level Python API for direct integration of LLMs into Python applications and a CLI for mixing and matching LLMs with various features like prompting templates, accuracy testing, performance benchmarking, and memory profiling. The tool supports both GGUF and ONNX models and allows importing custom models from Hugging Face using the Model Manager. Lemonade is designed to be easy to use and switch between different configurations at runtime, making it a versatile tool for running LLMs locally.
dora
Dataflow-oriented robotic application (dora-rs) is a framework that makes creation of robotic applications fast and simple. Building a robotic application can be summed up as bringing together hardwares, algorithms, and AI models, and make them communicate with each others. At dora-rs, we try to: make integration of hardware and software easy by supporting Python, C, C++, and also ROS2. make communication low latency by using zero-copy Arrow messages. dora-rs is still experimental and you might experience bugs, but we're working very hard to make it stable as possible.
For similar tasks

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.
LafTools
LafTools is a privacy-first, self-hosted, fully open source toolbox designed for programmers. It offers a wide range of tools, including code generation, translation, encryption, compression, data analysis, and more. LafTools is highly integrated with a productive UI and supports full GPT-alike functionality. It is available as Docker images and portable edition, with desktop edition support planned for the future.
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.
auto-dev
AutoDev is an AI-powered coding wizard that supports multiple languages, including Java, Kotlin, JavaScript/TypeScript, Rust, Python, Golang, C/C++/OC, and more. It offers a range of features, including auto development mode, copilot mode, chat with AI, customization options, SDLC support, custom AI agent integration, and language features such as language support, extensions, and a DevIns language for AI agent development. AutoDev is designed to assist developers with tasks such as auto code generation, bug detection, code explanation, exception tracing, commit message generation, code review content generation, smart refactoring, Dockerfile generation, CI/CD config file generation, and custom shell/command generation. It also provides a built-in LLM fine-tune model and supports UnitEval for LLM result evaluation and UnitGen for code-LLM fine-tune data generation.

LLM4SE
The collection is actively updated with the help of an internal literature search engine.
Awesome-Code-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, in lowercase letters: 'description' (detailed description of the repo, must be less than 400 words,Ensure that no line breaks and quotation marks.),'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,user may use those keyword to find the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in lowercase letters), 'answer' (in english languages)

crewAI
crewAI is a cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It provides a flexible and structured approach to AI collaboration, enabling users to define agents with specific roles, goals, and tools, and assign them tasks within a customizable process. crewAI supports integration with various LLMs, including OpenAI, and offers features such as autonomous task delegation, flexible task management, and output parsing. It is open-source and welcomes contributions, with a focus on improving the library based on usage data collected through anonymous telemetry.
llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.
llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.