Best AI tools for< Computer Vision Engineer >
Infographic
46 - AI tool Sites
ImageBind
ImageBind by Meta AI is a groundbreaking AI tool that revolutionizes the field of computer vision by introducing a new way to 'link' AI across multiple senses. It is the first AI model capable of binding data from six different modalities simultaneously, including images, video, audio, text, depth, thermal, and inertial measurement units (IMUs). By recognizing relationships between these modalities, ImageBind enables machines to analyze various forms of information together, advancing AI capabilities significantly.
Raman Labs
Raman Labs is an AI tool that offers dedicated modules for computer vision-based tasks. It allows users to integrate machine learning functionality into their existing applications with just 2 lines of code, ensuring real-time performance even with high-resolution data on consumer-grade CPUs. The tool provides a clean and minimalistic API for easy integration, robust to large scale and resolution variations, versatile to run on various platforms, and adaptive to scale with the computing power of the system.

Segment Anything by Meta AI
Segment Anything by Meta AI is an advanced AI model that specializes in image segmentation, allowing users to easily 'cut out' any object in an image with a single click. The model, named SAM, offers zero-shot generalization to unfamiliar objects and images without the need for additional training. SAM's promptable design enables a wide range of segmentation tasks through input prompts, making it a versatile tool for various applications.
Gradient Insight
Gradient Insight is a data science consulting and AI solutions provider. They offer a range of services including generative AI development, machine learning, computer vision, robotics and automation, AI strategy and roadmap, and data analytics. Their team of expert data scientists helps businesses to de-risk their investment in AI and to overcome barriers to engineering innovation. Gradient Insight has worked with clients such as Opitas, a fintech company, and the UK MOD. They offer a smooth and efficient process from consultation to delivery, and ongoing support and improvement.
Datagen
Datagen is a platform that provides synthetic data for computer vision. Synthetic data is artificially generated data that can be used to train machine learning models. Datagen's data is generated using a variety of techniques, including 3D modeling, computer graphics, and machine learning. The company's data is used by a variety of industries, including automotive, security, smart office, fitness, cosmetics, and facial applications.

QuarkIQL
QuarkIQL is a generative testing tool for computer vision APIs. It allows users to create custom test images and requests with just a few clicks. QuarkIQL also provides a log of your queries so you can run more experiments without starting from square one.
NVIDIA Toronto AI Lab
The NVIDIA Toronto AI Lab is a research laboratory focused on advancing the state-of-the-art in artificial intelligence. The lab's researchers are working on a wide range of AI topics, including deep learning, machine learning, computer vision, natural language processing, and robotics.
syntheticAIdata
syntheticAIdata is a platform that provides synthetic data for training vision AI models. Synthetic data is generated artificially, and it can be used to augment existing real-world datasets or to create new datasets from scratch. syntheticAIdata's platform is easy to use, and it can be integrated with leading cloud platforms. The company's mission is to make synthetic data accessible to everyone, and to help businesses overcome the challenges of acquiring high-quality data for training their vision AI models.
Datature
Datature is an all-in-one platform for building and deploying computer vision models. It provides tools for data management, annotation, training, and deployment, making it easy to develop and implement computer vision solutions. Datature is used by a variety of industries, including healthcare, retail, manufacturing, and agriculture.
Robovision
Robovision is a central platform to manage vision intelligence inside smart machines. Successfully introduce AI in dynamic environments without the need for AI experts.
Synthesis AI
Synthesis AI is a synthetic data platform that enables more capable and ethical computer vision AI. It provides on-demand labeled images and videos, photorealistic images, and 3D generative AI to help developers build better models faster. Synthesis AI's products include Synthesis Humans, which allows users to create detailed images and videos of digital humans with rich annotations; Synthesis Scenarios, which enables users to craft complex multi-human simulations across a variety of environments; and a range of applications for industries such as ID verification, automotive, avatar creation, virtual fashion, AI fitness, teleconferencing, visual effects, and security.
AIGeneratedCourses
AIGeneratedCourses is a collection of AI-generated courses created by Chat2Course.com. These courses are designed to help you learn about a variety of AI-related topics, including machine learning, deep learning, and natural language processing. The courses are easy to follow and are perfect for beginners who want to learn more about AI.
AI Jobs
AI Jobs is a curated list of the best AI jobs for developers, designers and marketers. It provides a platform for companies to post their AI-related job openings and for job seekers to find their dream AI job. The website also includes a blog with articles on the latest AI trends and technologies.
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.

Viso Suite
Viso Suite is a no-code computer vision platform that enables users to build, deploy, and scale computer vision applications. It provides a comprehensive set of tools for data collection, annotation, model training, application development, and deployment. Viso Suite is trusted by leading Fortune Global companies and has been used to develop a wide range of computer vision applications, including object detection, image classification, facial recognition, and anomaly detection.
V7
V7 is an AI data engine for computer vision and generative AI. It provides a multimodal automation tool that helps users label data 10x faster, power AI products via API, build AI + human workflows, and reach 99% AI accuracy. V7's platform includes features such as automated annotation, DICOM annotation, dataset management, model management, image annotation, video annotation, document processing, and labeling services.

Deep Learning
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The online version of the book is now complete and will remain available online for free. The deep learning textbook can now be ordered on Amazon. For up to date announcements, join our mailing list.
Innovatiana
Innovatiana is a data labeling outsourcing company that provides high-quality training data for AI models. They specialize in computer vision, data moderation, document processing, natural language processing, and data collection. Innovatiana is committed to ethical and sustainable practices, and they pay their data labelers fair wages and provide them with good working conditions. They also use a variety of quality control measures to ensure that their data is accurate and reliable.
Tech Xplore
Tech Xplore is a leading source of science and technology news, covering the latest breakthroughs in research and innovation across a wide range of disciplines, including artificial intelligence, robotics, computer science, and more. The website provides in-depth articles, interviews with experts, and up-to-date information on the latest developments in the field of AI and its applications.

CVF Open Access
The Computer Vision Foundation (CVF) is a non-profit organization dedicated to advancing the field of computer vision. CVF organizes several conferences and workshops each year, including the International Conference on Computer Vision (ICCV), the Conference on Computer Vision and Pattern Recognition (CVPR), and the Winter Conference on Applications of Computer Vision (WACV). CVF also publishes the International Journal of Computer Vision (IJCV) and the Computer Vision and Image Understanding (CVIU) journal. The CVF Open Access website provides access to the full text of all CVF-sponsored conference papers. These papers are available for free download in PDF format. The CVF Open Access website also includes links to the arXiv versions of the papers, where available.

Visual Computing & Artificial Intelligence Lab at TUM
The Visual Computing & Artificial Intelligence Lab at TUM is a group of research enthusiasts advancing cutting-edge research at the intersection of computer vision, computer graphics, and artificial intelligence. Our research mission is to obtain highly-realistic digital replica of the real world, which include representations of detailed 3D geometries, surface textures, and material definitions of both static and dynamic scene environments. In our research, we heavily build on advances in modern machine learning, and develop novel methods that enable us to learn strong priors to fuel 3D reconstruction techniques. Ultimately, we aim to obtain holographic representations that are visually indistinguishable from the real world, ideally captured from a simple webcam or mobile phone. We believe this is a critical component in facilitating immersive augmented and virtual reality applications, and will have a substantial positive impact in modern digital societies.
Amazon Science
Amazon Science is a research and development organization within Amazon that focuses on developing new technologies and products in the fields of artificial intelligence, machine learning, and computer science. The organization is home to a team of world-renowned scientists and engineers who are working on a wide range of projects, including developing new algorithms for machine learning, building new computer vision systems, and creating new natural language processing tools. Amazon Science is also responsible for developing new products and services that use these technologies, such as the Amazon Echo and the Amazon Fire TV.
Undressing AI
Undressing AI is a website that provides information about artificial intelligence (AI) and its potential impact on society. The site includes articles, videos, and other resources on topics such as the history of AI, the different types of AI, and the ethical implications of AI.

Enric Corona
Enric Corona is a Research Scientist at Google Research, working on 3D Humans and Generative AI. His research is in areas of computer vision and machine learning, including modelling and reconstruction of 3D human bodies and hands.
OpenCV
OpenCV is the world's largest computer vision library. It's open source, contains over 2500 algorithms and is operated by the non-profit Open Source Vision Foundation.

OpenCV.ai
OpenCV.ai is a leading provider of computer vision software and services. The company's team of experts has extensive experience in developing optimized large-scale computer vision solutions. OpenCV.ai's expertise is helping businesses grow in a variety of industries, including medicine, manufacturing, and retail. The company's solutions are used by startups and Fortune 500 companies alike.
CVAT
CVAT is an open-source data annotation platform that helps teams of any size annotate data for machine learning. It is used by companies big and small in a variety of industries, including healthcare, retail, and automotive. CVAT is known for its intuitive user interface, advanced features, and support for a wide range of data formats. It is also highly extensible, allowing users to add their own custom features and integrations.
RunPod
RunPod is a cloud platform specifically designed for AI development and deployment. It offers a range of features to streamline the process of developing, training, and scaling AI models, including a library of pre-built templates, efficient training pipelines, and scalable deployment options. RunPod also provides access to a wide selection of GPUs, allowing users to choose the optimal hardware for their specific AI workloads.

Big Vision
Big Vision provides consulting services in AI, computer vision, and deep learning. They help businesses build specific AI-driven solutions, create intelligent processes, and establish best practices to reduce human effort and enable faster decision-making. Their enterprise-grade solutions are currently serving millions of requests every month, especially in critical production environments.
Orbbec
Orbbec is a leading provider of 3D vision technology, offering a wide range of 3D cameras and sensors for various applications. With a focus on AI, optics, and advanced algorithms, Orbbec empowers developers and enterprises to create immersive experiences, precise measurements, and advanced visualizations. Their products include stereo vision cameras, ToF cameras, structured light cameras, camera computers, and lidar sensors, catering to industries such as manufacturing, healthcare, robotics, fitness, logistics, and retail.
Tangram Vision
Tangram Vision is a company that provides sensor calibration tools and infrastructure for robotics and autonomous vehicles. Their products include MetriCal, a high-speed bundle adjustment software for precise sensor calibration, and AutoCal, an on-device, real-time calibration health check and adjustment tool. Tangram Vision also offers a high-resolution depth sensor called HiFi, which combines high-resolution depth data with high-powered AI capabilities. The company's mission is to accelerate the development and deployment of autonomous systems by providing the tools and infrastructure needed to ensure the accuracy and reliability of sensors.
OpenCV
OpenCV is a library of programming functions mainly aimed at real-time computer vision. Originally developed by Intel, it was later supported by Willow Garage and is now maintained by Itseez. OpenCV is cross-platform and free for use under the open-source BSD license.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.
Clarifai
Clarifai is a full-stack AI platform that provides developers and ML engineers with the fastest, production-grade deep learning platform. It offers a wide range of features, including data preparation, model building, model operationalization, and AI workflows. Clarifai is used by a variety of companies, including Fortune 500 companies and startups, to build AI applications in a variety of industries, including retail, manufacturing, and healthcare.
Kovil.AI
Kovil.AI is an AI-powered platform that connects businesses with top AI talents from India's largest network. The platform offers a vetting process to match businesses with hand-picked Indian developers, covering a wide range of expertise in AI, machine learning, data science, and more. Kovil.AI aims to empower ambitious businesses by providing access to specialized, high-caliber AI professionals, accelerating the hiring process, and reducing costs. The platform also offers managed services and products, ensuring flexibility, adaptability, and a competitive advantage for businesses seeking top talent.
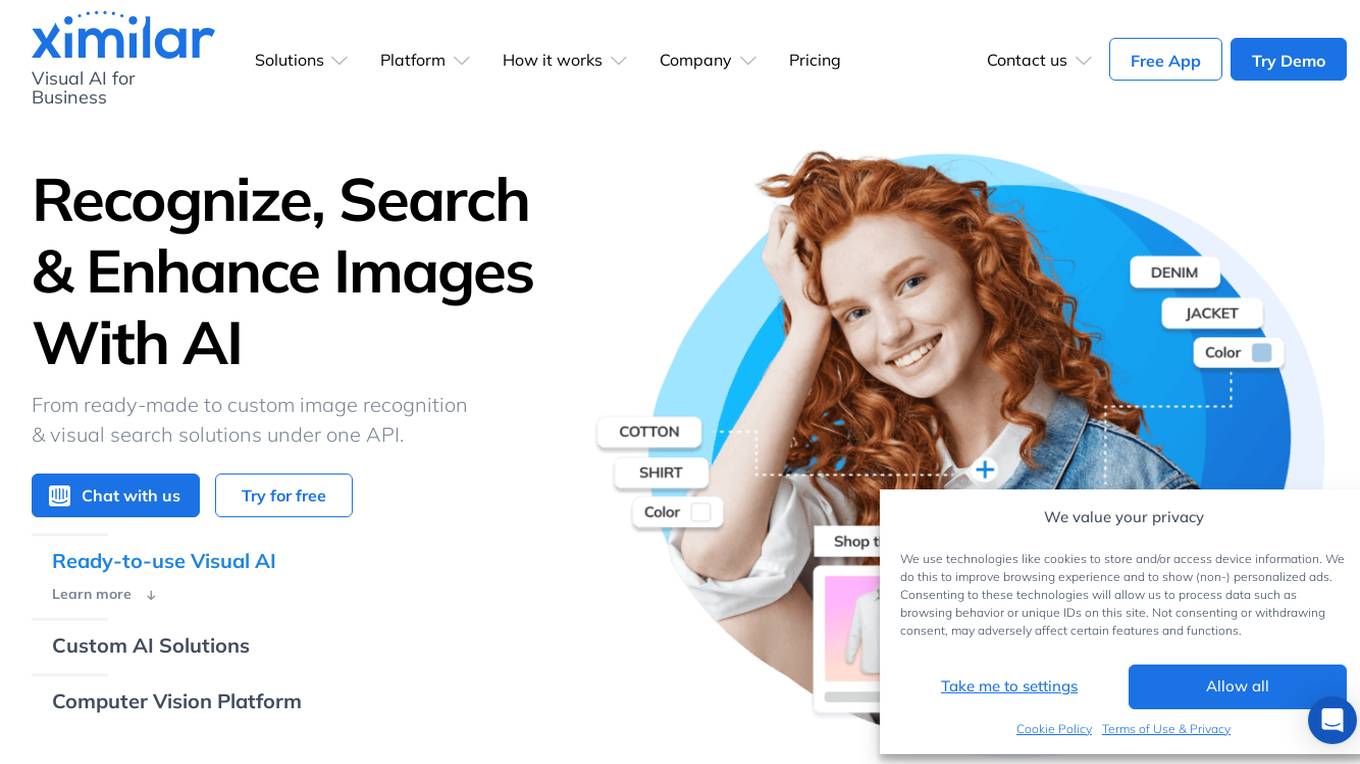
Ximilar Visual AI for Business
Ximilar Visual AI for Business is an AI tool that offers a comprehensive platform for image recognition and visual search solutions. It provides features such as image classification, regression, object detection, AI model combination, image annotation, and more. Users can easily build custom machine learning models without coding, access ready-to-use visual AI demos, and benefit from features like image upscaling, background removal, and color extraction. The platform caters to various industries including fashion, home decor, stock photos, collectibles, med & biotech, manufacturing, and real estate.
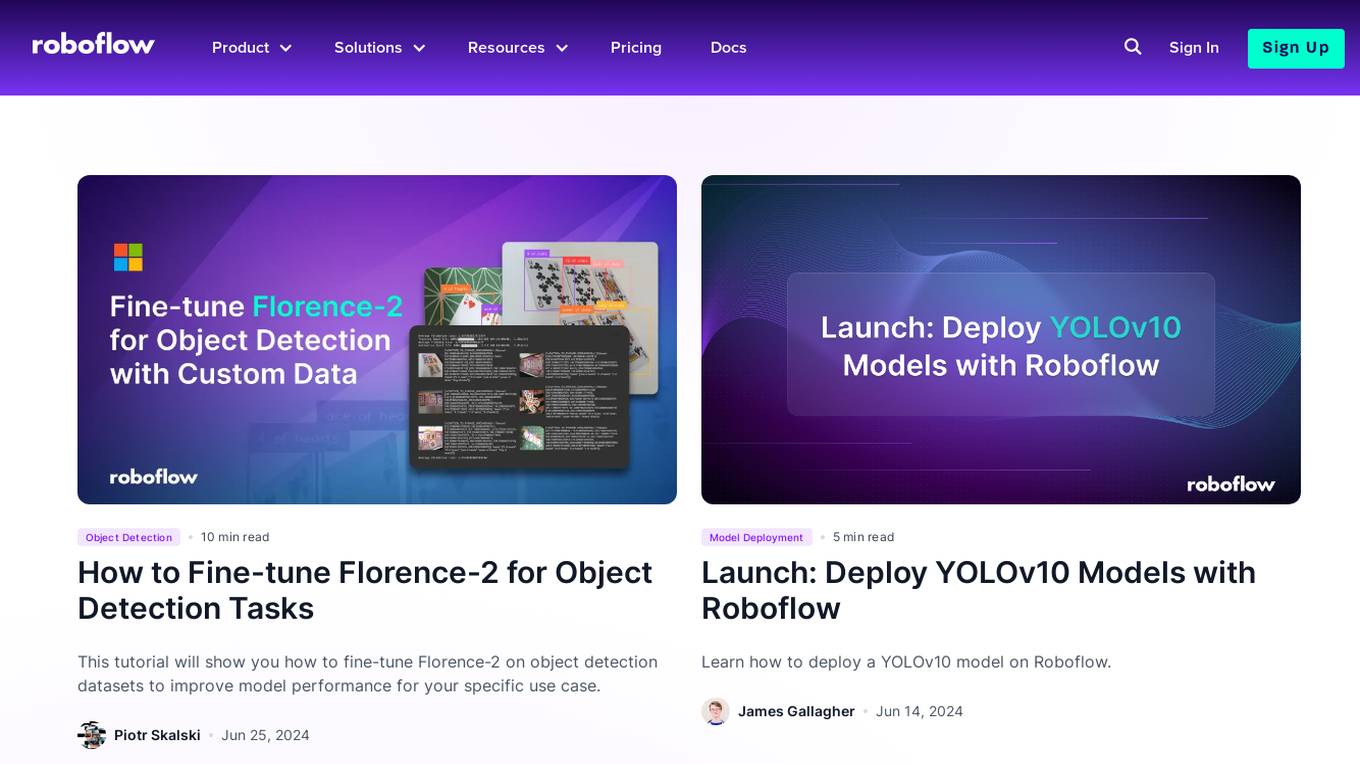
Roboflow
Roboflow is an AI tool designed for computer vision tasks, offering a platform that allows users to annotate, train, deploy, and perform inference on models. It provides integrations, ecosystem support, and features like notebooks, autodistillation, and supervision. Roboflow caters to various industries such as aerospace, agriculture, healthcare, finance, and more, with a focus on simplifying the development and deployment of computer vision models.

ThirdEye Data
ThirdEye Data is a data and AI services & solutions provider that enables enterprises to improve operational efficiencies, increase production accuracies, and make informed business decisions by leveraging the latest Data & AI technologies. They offer services in data engineering, data science, generative AI, computer vision, NLP, and more. ThirdEye Data develops bespoke AI applications using the latest data science technologies to address real-world industry challenges and assists enterprises in leveraging generative AI models to develop custom applications. They also provide AI consulting services to explore potential opportunities for AI implementation. The company has a strong focus on customer success and has received positive reviews and awards for their expertise in AI, ML, and big data solutions.
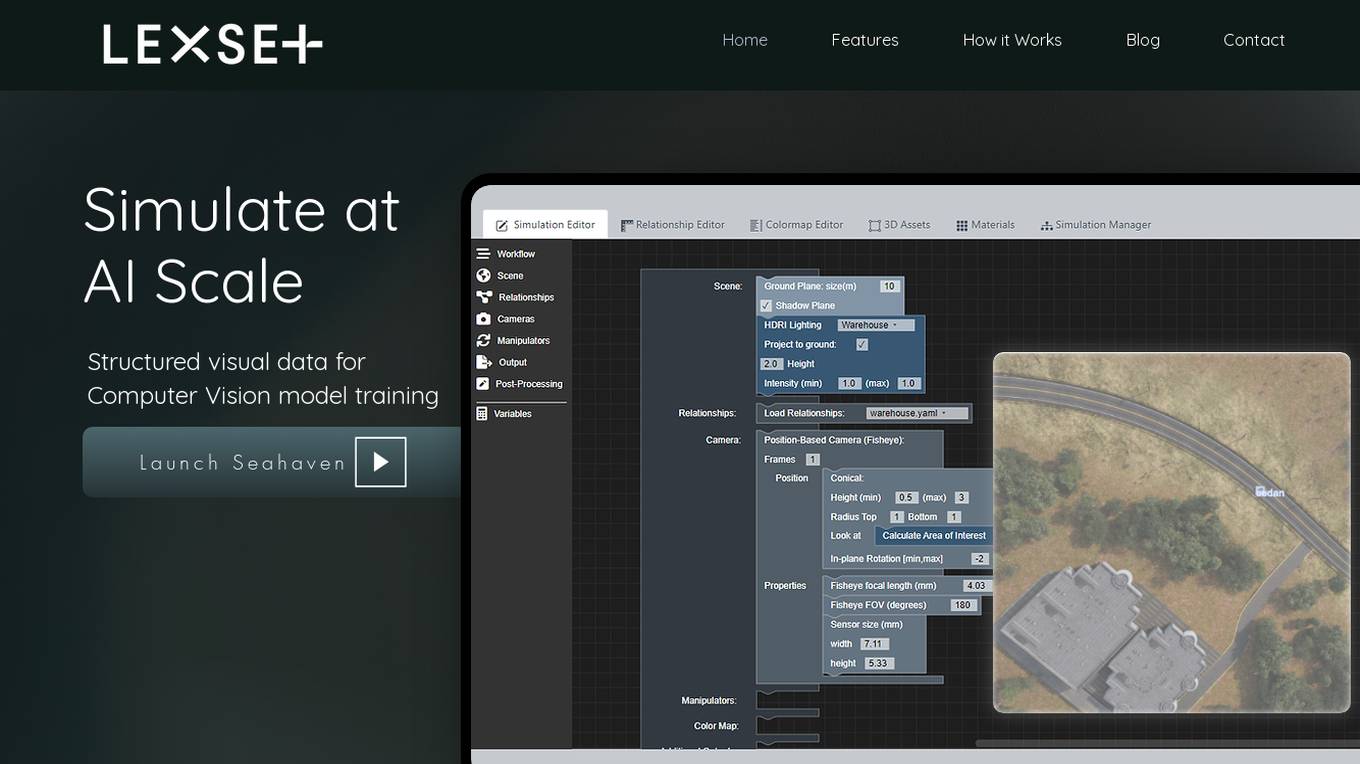
Lexset
Lexset is an AI tool that provides synthetic data generation services for computer vision model training. It offers a no-code interface to create unlimited data with advanced camera controls and lighting options. Users can simulate AI-scale environments, composite objects into images, and create custom 3D scenarios. Lexset also provides access to GPU nodes, dedicated support, and feature development assistance. The tool aims to improve object detection accuracy and optimize generalization on high-quality synthetic data.
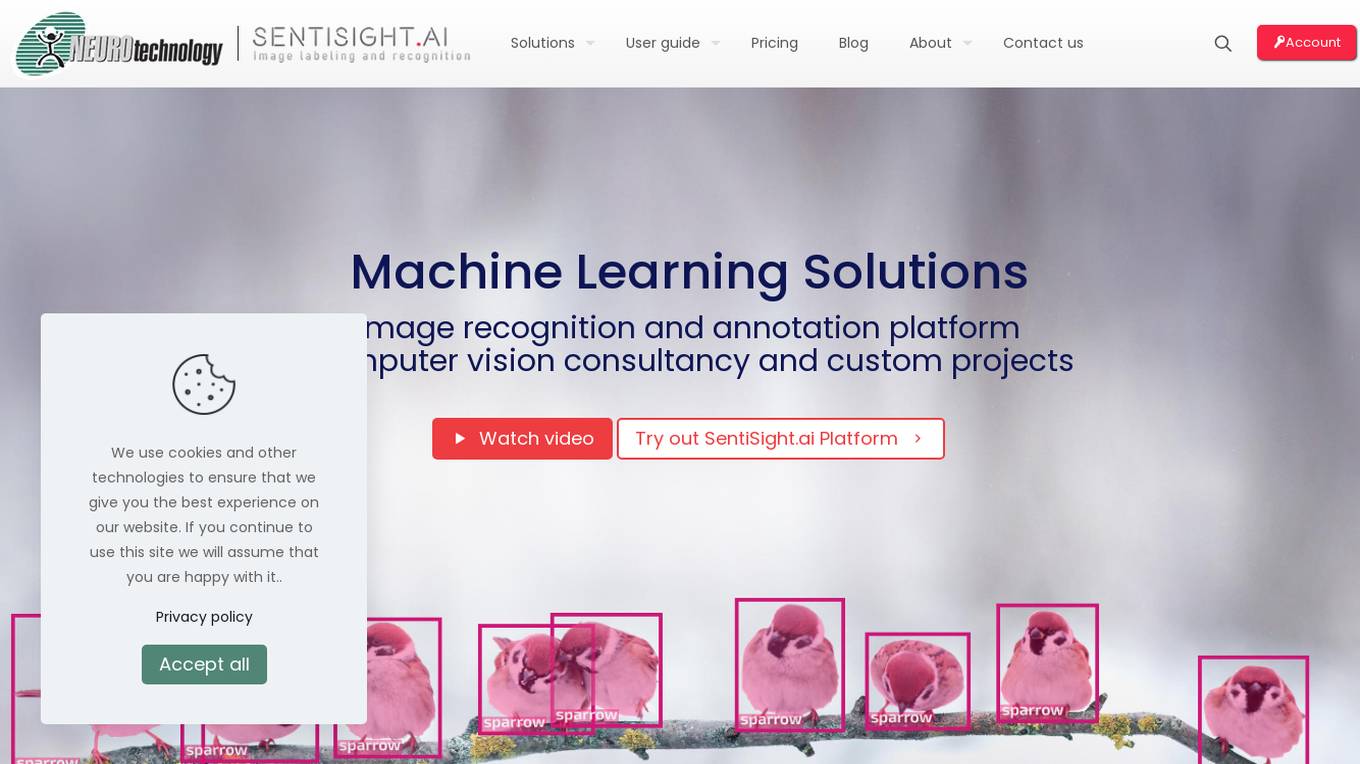
SentiSight.ai
SentiSight.ai is a machine learning platform for image recognition solutions, offering services such as object detection, image segmentation, image classification, image similarity search, image annotation, computer vision consulting, and intelligent automation consulting. Users can access pre-trained models, background removal, NSFW detection, text recognition, and image recognition API. The platform provides tools for image labeling, project management, and training tutorials for various image recognition models. SentiSight.ai aims to streamline the image annotation process, empower users to build and train their own models, and deploy them for online or offline use.
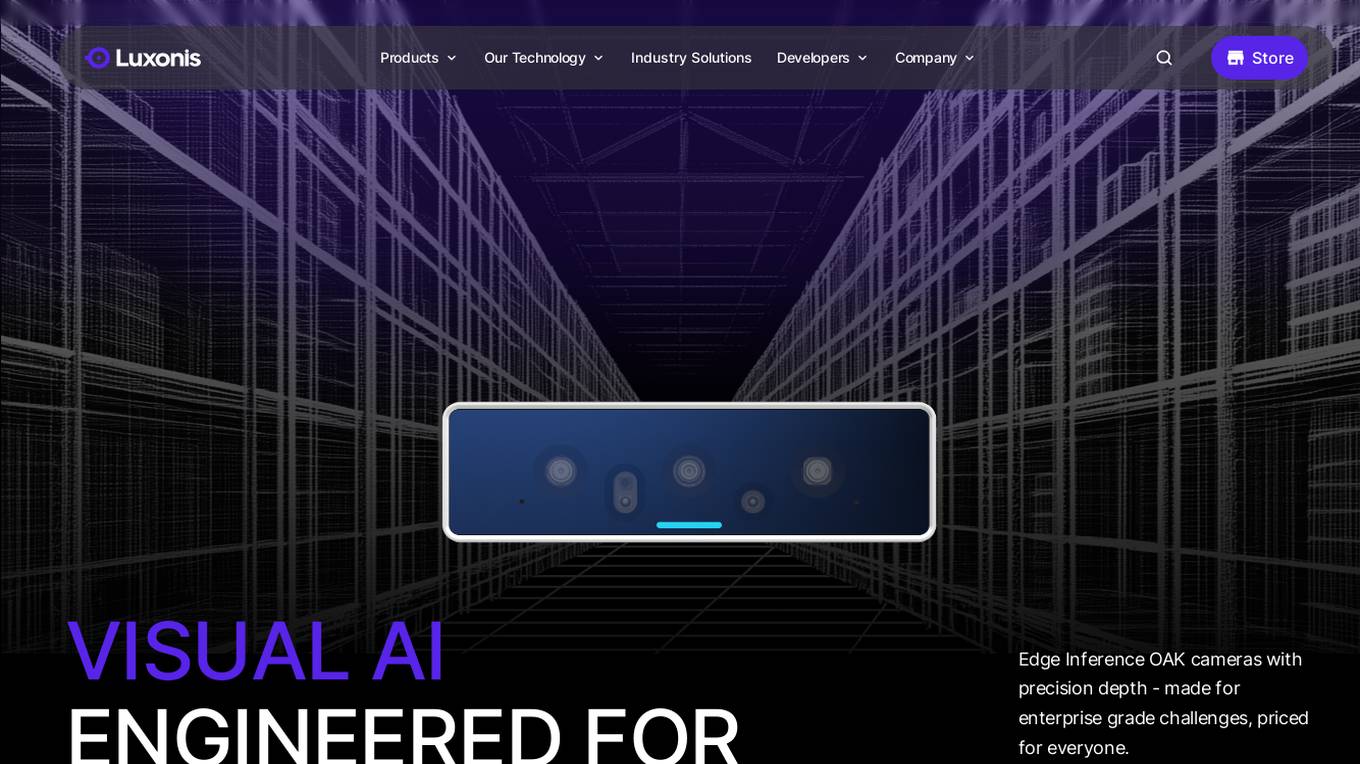
Luxonis
Luxonis is an AI application that offers Visual AI solutions engineered for precision edge inference. The application provides stereo depth cameras with unique features and quality, enabling users to perform advanced vision tasks on-device, reducing latency and bandwidth demands. With open-source DepthAI API, users can create and deploy custom vision solutions that scale with their needs. Luxonis also offers real-world training data for self-improving vision intelligence and operates flawlessly through vibrations, temperature shifts, and extended use. The application integrates advanced sensing capabilities with up to 48MP cameras, wide field of view, IMUs, microphones, ToF, thermal, IR illumination, and active stereo for unparalleled perception.
Hailo Community
Hailo Community is an AI tool designed for developers and enthusiasts working with Raspberry Pi and Hailo-8L AI Kit. The platform offers resources, benchmarks, and support for training custom models, optimizing AI tasks, and troubleshooting errors related to Hailo and Raspberry Pi integration.

INSAIT
INSAIT is an Institute for Computer Science, Artificial Intelligence, and Technology located in Sofia, Bulgaria. The institute focuses on cutting-edge research areas such as Computer Vision, Robotics, Quantum Computing, Machine Learning, and Regulatory AI Compliance. INSAIT is known for its collaboration with top universities and organizations, as well as its commitment to fostering a diverse and inclusive environment for students and researchers.
PROPHESEE
PROPHESEE is an AI-driven system developed by Metavision Technologies that leverages Event-Based Vision technology inspired by human vision and neuromorphic engineering. It enables machines to capture hyper-fast and fleeting scene dynamics, manage extreme lighting conditions, and operate with new levels of power efficiency. The system enhances machine intelligence, autonomy, speed, and safety, offering a new era in autonomy, automation, and mobility. PROPHESEE combines patented neuromorphic vision sensors and AI algorithms to create an unparalleled event-based vision system, dynamically driven by live scene events. It significantly improves artificial vision speed and efficiency, reducing energy consumption and computational power requirements.

GrokCV
GrokCV is an AI tool developed by GrokCV Group that focuses on infrared weak small target detection and remote sensing multi-modal visual perception. The tool provides a platform for researchers and enthusiasts to access and discuss cutting-edge research papers, codes, datasets, and interpretations in the field of computer vision and remote sensing.

Ultralytics YOLO
Ultralytics YOLO is an advanced real-time object detection and image segmentation model that leverages cutting-edge advancements in deep learning and computer vision. It offers unparalleled performance in terms of speed and accuracy, making it suitable for various applications and easily adaptable to different hardware platforms. The comprehensive Ultralytics Docs provide resources to help users understand and utilize its features and capabilities, catering to both seasoned machine learning practitioners and newcomers to the field.
185 - Open Source Tools

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
Awesome-AIGC-3D
Awesome-AIGC-3D is a curated list of awesome AIGC 3D papers, inspired by awesome-NeRF. It aims to provide a comprehensive overview of the state-of-the-art in AIGC 3D, including papers on text-to-3D generation, 3D scene generation, human avatar generation, and dynamic 3D generation. The repository also includes a list of benchmarks and datasets, talks, companies, and implementations related to AIGC 3D. The description is less than 400 words and provides a concise overview of the repository's content and purpose.
holoscan-sdk
The Holoscan SDK is part of NVIDIA Holoscan, the AI sensor processing platform that combines hardware systems for low-latency sensor and network connectivity, optimized libraries for data processing and AI, and core microservices to run streaming, imaging, and other applications, from embedded to edge to cloud. It can be used to build streaming AI pipelines for a variety of domains, including Medical Devices, High Performance Computing at the Edge, Industrial Inspection and more.
ai-deadlines
Countdown timers to keep track of a bunch of CV/NLP/ML/RO conference deadlines.
awesome-mobile-robotics
The 'awesome-mobile-robotics' repository is a curated list of important content related to Mobile Robotics and AI. It includes resources such as courses, books, datasets, software and libraries, podcasts, conferences, journals, companies and jobs, laboratories and research groups, and miscellaneous resources. The repository covers a wide range of topics in the field of Mobile Robotics and AI, providing valuable information for enthusiasts, researchers, and professionals in the domain.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline
CompressAI-Vision
CompressAI-Vision is a tool that helps you develop, test, and evaluate compression models with standardized tests in the context of compression methods optimized for machine tasks algorithms such as Neural-Network (NN)-based detectors. It currently focuses on two types of pipeline: Video compression for remote inference (`compressai-remote-inference`), which corresponds to the MPEG "Video Coding for Machines" (VCM) activity. Split inference (`compressai-split-inference`), which includes an evaluation framework for compressing intermediate features produced in the context of split models. The software supports all the pipelines considered in the related MPEG activity: "Feature Compression for Machines" (FCM).
kornia
Kornia is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.
Awesome-Quantization-Papers
This repo contains a comprehensive paper list of **Model Quantization** for efficient deep learning on AI conferences/journals/arXiv. As a highlight, we categorize the papers in terms of model structures and application scenarios, and label the quantization methods with keywords.
ai_all_resources
This repository is a compilation of excellent ML and DL tutorials created by various individuals and organizations. It covers a wide range of topics, including machine learning fundamentals, deep learning, computer vision, natural language processing, reinforcement learning, and more. The resources are organized into categories, making it easy to find the information you need. Whether you're a beginner or an experienced practitioner, you're sure to find something valuable in this repository.
habitat-lab
Habitat-Lab is a modular high-level library for end-to-end development in embodied AI. It is designed to train agents to perform a wide variety of embodied AI tasks in indoor environments, as well as develop agents that can interact with humans in performing these tasks.
carla
CARLA is an open-source simulator for autonomous driving research. It provides open-source code, protocols, and digital assets (urban layouts, buildings, vehicles) for developing, training, and validating autonomous driving systems. CARLA supports flexible specification of sensor suites and environmental conditions.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
nnstreamer
NNStreamer is a set of Gstreamer plugins that allow Gstreamer developers to adopt neural network models easily and efficiently and neural network developers to manage neural network pipelines and their filters easily and efficiently.
TornadoVM
TornadoVM is a plug-in to OpenJDK and GraalVM that allows programmers to automatically run Java programs on heterogeneous hardware. TornadoVM targets OpenCL, PTX and SPIR-V compatible devices which include multi-core CPUs, dedicated GPUs (Intel, NVIDIA, AMD), integrated GPUs (Intel HD Graphics and ARM Mali), and FPGAs (Intel and Xilinx).
habitat-sim
Habitat-Sim is a high-performance physics-enabled 3D simulator with support for 3D scans of indoor/outdoor spaces, CAD models of spaces and piecewise-rigid objects, configurable sensors, robots described via URDF, and rigid-body mechanics. It prioritizes simulation speed over the breadth of simulation capabilities, achieving several thousand frames per second (FPS) running single-threaded and over 10,000 FPS multi-process on a single GPU when rendering a scene from the Matterport3D dataset. Habitat-Sim simulates a Fetch robot interacting in ReplicaCAD scenes at over 8,000 steps per second (SPS), where each ‘step’ involves rendering 1 RGBD observation (128×128 pixels) and rigid-body dynamics for 1/30sec.
CVPR2024-Papers-with-Code-Demo
This repository contains a collection of papers and code for the CVPR 2024 conference. The papers cover a wide range of topics in computer vision, including object detection, image segmentation, image generation, and video analysis. The code provides implementations of the algorithms described in the papers, making it easy for researchers and practitioners to reproduce the results and build upon the work of others. The repository is maintained by a team of researchers at the University of California, Berkeley.
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.
gaussian-painters
This tool is a fork of the 3D Gaussian Splatting code. It allows users to create a dataset ready to be trained with the Gaussian Splatting code. The dataset can be used for various experiments, such as creating orthogonal images, steganography, and lenticular effects. The tool also includes a visualizer that allows users to visualize the "painting" process during the Gaussian Splatting optimization.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

rclip
rclip is a command-line photo search tool powered by the OpenAI's CLIP neural network. It allows users to search for images using text queries, similar image search, and combining multiple queries. The tool extracts features from photos to enable searching and indexing, with options for previewing results in supported terminals or custom viewers. Users can install rclip on Linux, macOS, and Windows using different installation methods. The repository follows the Conventional Commits standard and welcomes contributions from the community.
seemore
seemore is a vision language model developed in Pytorch, implementing components like image encoder, vision-language projector, and decoder language model. The model is built from scratch, including attention mechanisms and patch creation. It is designed for readability and hackability, with the intention to be improved upon. The implementation is based on public publications and borrows attention mechanism from makemore by Andrej Kapathy. The code was developed on Databricks using a single A100 for compute, and MLFlow is used for tracking metrics. The tool aims to provide a simplistic version of vision language models like Grok 1.5/GPT-4 Vision, suitable for experimentation and learning.
RPG-DiffusionMaster
This repository contains the official implementation of RPG, a powerful training-free paradigm for text-to-image generation and editing. RPG utilizes proprietary or open-source MLLMs as prompt recaptioner and region planner with complementary regional diffusion. It achieves state-of-the-art results and can generate high-resolution images. The codebase supports diffusers and various diffusion backbones, including SDXL and SD v1.4/1.5. Users can reproduce results with GPT-4, Gemini-Pro, or local MLLMs like miniGPT-4. The repository provides tools for quick start, regional diffusion with GPT-4, and regional diffusion with local LLMs.
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.
ChatSim
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.
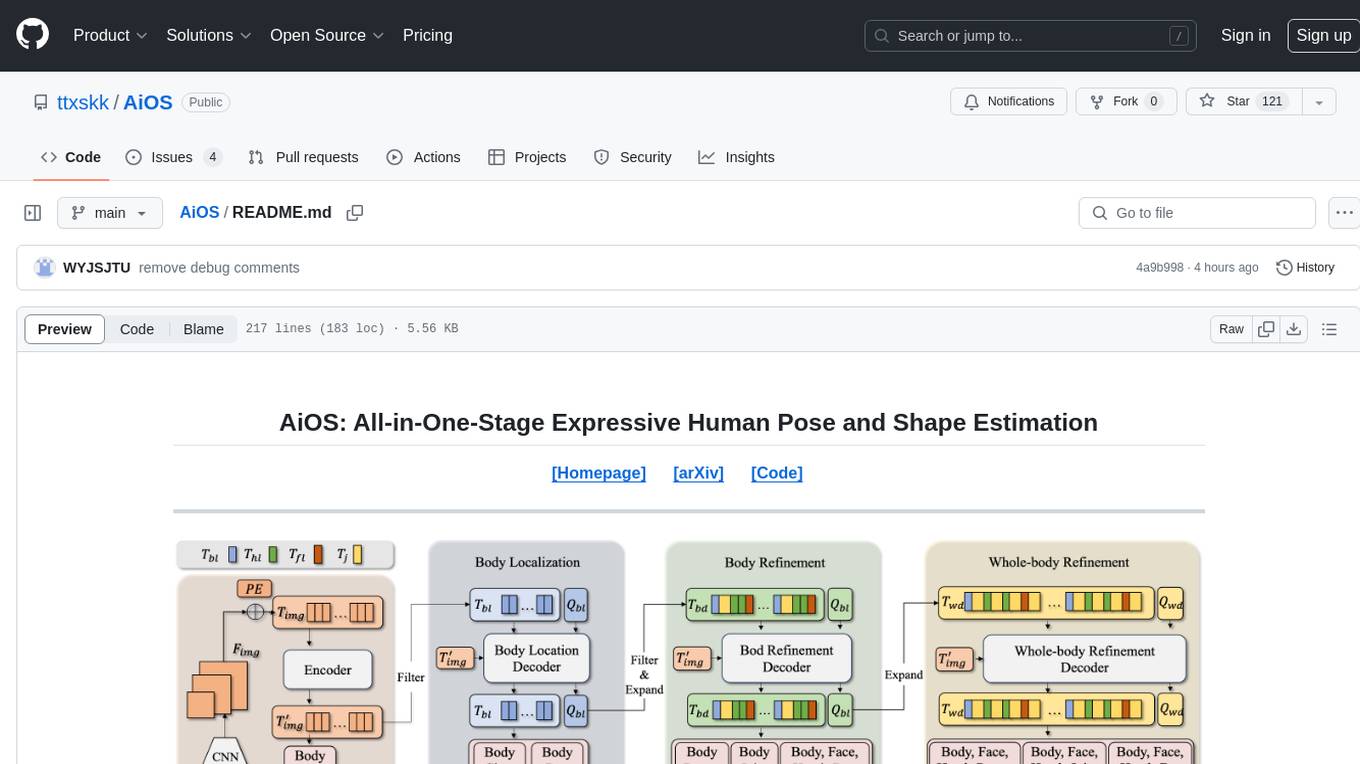
AiOS
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.
SoM-LLaVA
SoM-LLaVA is a new data source and learning paradigm for Multimodal LLMs, empowering open-source Multimodal LLMs with Set-of-Mark prompting and improved visual reasoning ability. The repository provides a new dataset that is complementary to existing training sources, enhancing multimodal LLMs with Set-of-Mark prompting and improved general capacity. By adding 30k SoM data to the visual instruction tuning stage of LLaVA, the tool achieves 1% to 6% relative improvements on all benchmarks. Users can train SoM-LLaVA via command line and utilize the implementation to annotate COCO images with SoM. Additionally, the tool can be loaded in Huggingface for further usage.
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.
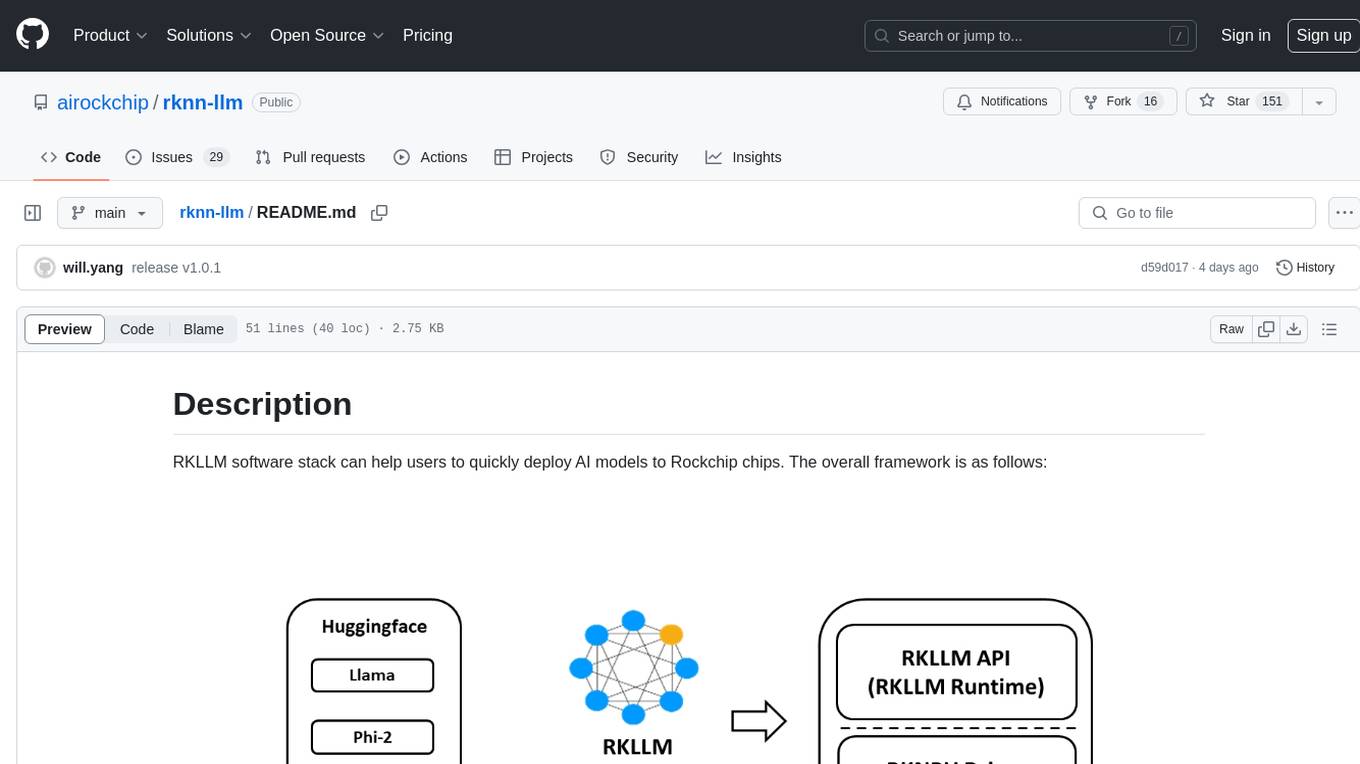
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.
open-model-database
OpenModelDB is a community-driven database of AI upscaling models, providing a centralized platform for users to access and compare various models. The repository contains a collection of models and model metadata, facilitating easy exploration and evaluation of different AI upscaling solutions. With a focus on enhancing the accessibility and usability of AI models, OpenModelDB aims to streamline the process of finding and selecting the most suitable models for specific tasks or projects.
Awesome-LLM-3D
This repository is a curated list of papers related to 3D tasks empowered by Large Language Models (LLMs). It covers tasks such as 3D understanding, reasoning, generation, and embodied agents. The repository also includes other Foundation Models like CLIP and SAM to provide a comprehensive view of the area. It is actively maintained and updated to showcase the latest advances in the field. Users can find a variety of research papers and projects related to 3D tasks and LLMs in this repository.
llmblueprint
LLM Blueprint is an official implementation of a paper that enables text-to-image generation with complex and detailed prompts. It leverages Large Language Models (LLMs) to extract critical components from text prompts, including bounding box coordinates for foreground objects, detailed textual descriptions for individual objects, and a succinct background context. The tool operates in two phases: Global Scene Generation creates an initial scene using object layouts and background context, and an Iterative Refinement Scheme refines box-level content to align with textual descriptions, ensuring consistency and improving recall compared to baseline diffusion models.
ScreenAgent
ScreenAgent is a project focused on creating an environment for Visual Language Model agents (VLM Agent) to interact with real computer screens. The project includes designing an automatic control process for agents to interact with the environment and complete multi-step tasks. It also involves building the ScreenAgent dataset, which collects screenshots and action sequences for various daily computer tasks. The project provides a controller client code, configuration files, and model training code to enable users to control a desktop with a large model.
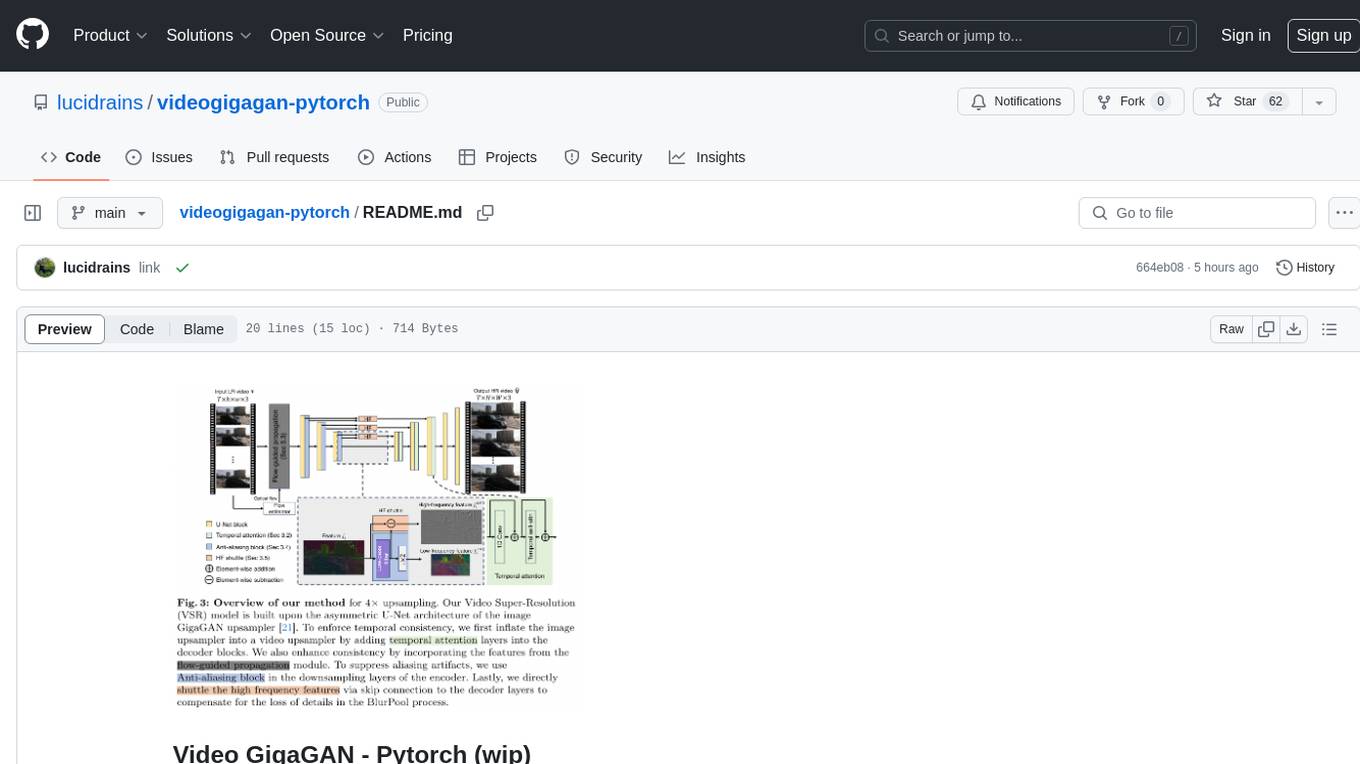
videogigagan-pytorch
Video GigaGAN - Pytorch is an implementation of Video GigaGAN, a state-of-the-art video upsampling technique developed by Adobe AI labs. The project aims to provide a Pytorch implementation for researchers and developers interested in video super-resolution. The codebase allows users to replicate the results of the original research paper and experiment with video upscaling techniques. The repository includes the necessary code and resources to train and test the GigaGAN model on video datasets. Researchers can leverage this implementation to enhance the visual quality of low-resolution videos and explore advancements in video super-resolution technology.
landingai-python
The LandingLens Python library contains the LandingLens development library and examples that show how to integrate your app with LandingLens in a variety of scenarios. The library allows users to acquire images from different sources, run inference on computer vision models deployed in LandingLens, and provides examples in Jupyter Notebooks and Python apps for various tasks such as object detection, home automation, satellite image analysis, license plate detection, and streaming video analysis.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
yolo-ios-app
The Ultralytics YOLO iOS App GitHub repository offers an advanced object detection tool leveraging YOLOv8 models for iOS devices. Users can transform their devices into intelligent detection tools to explore the world in a new and exciting way. The app provides real-time detection capabilities with multiple AI models to choose from, ranging from 'nano' to 'x-large'. Contributors are welcome to participate in this open-source project, and licensing options include AGPL-3.0 for open-source use and an Enterprise License for commercial integration. Users can easily set up the app by following the provided steps, including cloning the repository, adding YOLOv8 models, and running the app on their iOS devices.
SimpleAICV_pytorch_training_examples
SimpleAICV_pytorch_training_examples is a repository that provides simple training and testing examples for various computer vision tasks such as image classification, object detection, semantic segmentation, instance segmentation, knowledge distillation, contrastive learning, masked image modeling, OCR text detection, OCR text recognition, human matting, salient object detection, interactive segmentation, image inpainting, and diffusion model tasks. The repository includes support for multiple datasets and networks, along with instructions on how to prepare datasets, train and test models, and use gradio demos. It also offers pretrained models and experiment records for download from huggingface or Baidu-Netdisk. The repository requires specific environments and package installations to run effectively.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.
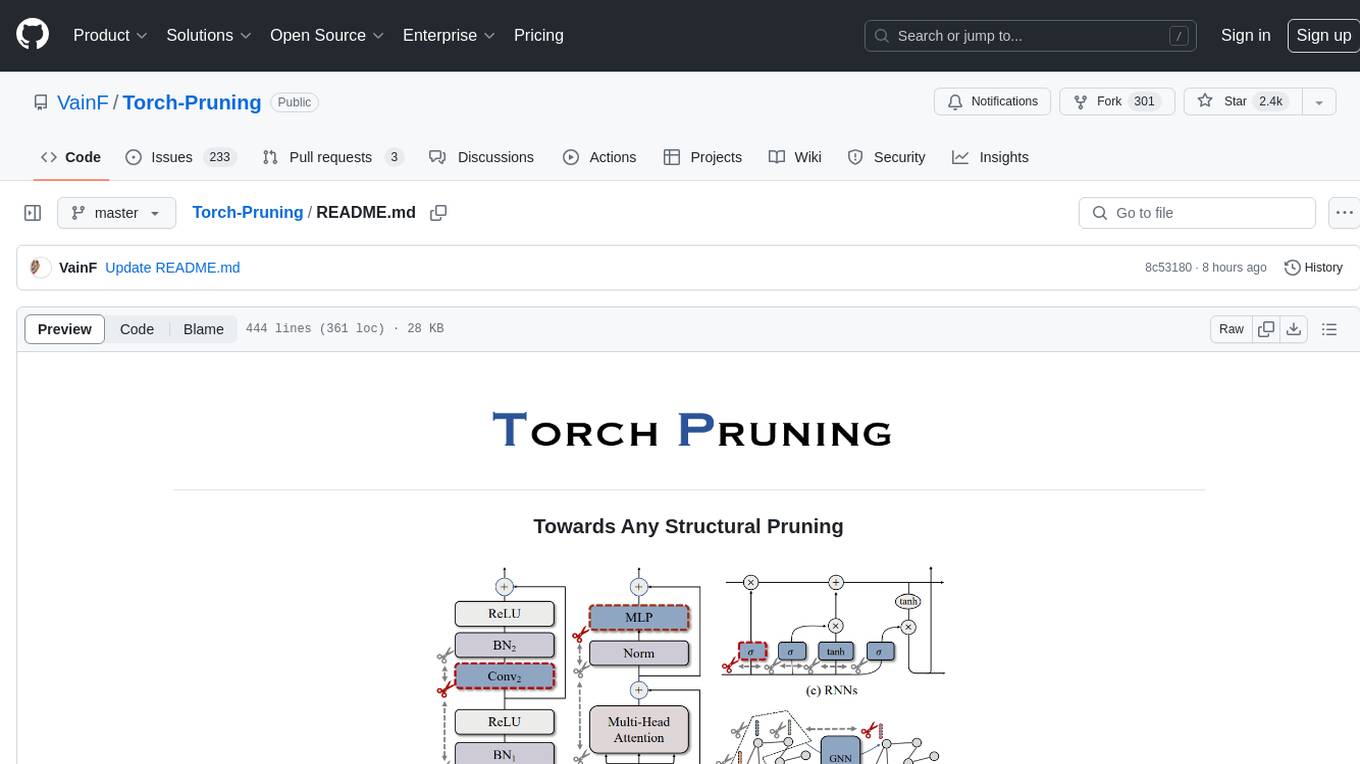
Torch-Pruning
Torch-Pruning (TP) is a library for structural pruning that enables pruning for a wide range of deep neural networks. It uses an algorithm called DepGraph to physically remove parameters. The library supports pruning off-the-shelf models from various frameworks and provides benchmarks for reproducing results. It offers high-level pruners, dependency graph for automatic pruning, low-level pruning functions, and supports various importance criteria and modules. Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions.
Model-References
The 'Model-References' repository contains examples for training and inference using Intel Gaudi AI Accelerator. It includes models for computer vision, natural language processing, audio, generative models, MLPerf™ training, and MLPerf™ inference. The repository provides performance data and model validation information for various frameworks like PyTorch. Users can find examples of popular models like ResNet, BERT, and Stable Diffusion optimized for Intel Gaudi AI accelerator.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.
ztachip
ztachip is a RISCV accelerator designed for vision and AI edge applications, offering up to 20-50x acceleration compared to non-accelerated RISCV implementations. It features an innovative tensor processor hardware to accelerate various vision tasks and TensorFlow AI models. ztachip introduces a new tensor programming paradigm for massive processing/data parallelism. The repository includes technical documentation, code structure, build procedures, and reference design examples for running vision/AI applications on FPGA devices. Users can build ztachip as a standalone executable or a micropython port, and run various AI/vision applications like image classification, object detection, edge detection, motion detection, and multi-tasking on supported hardware.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.

MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.
InternGPT
InternGPT (iGPT) is a pointing-language-driven visual interactive system that enhances communication between users and chatbots by incorporating pointing instructions. It improves chatbot accuracy in vision-centric tasks, especially in complex visual scenarios. The system includes an auxiliary control mechanism to enhance the control capability of the language model. InternGPT features a large vision-language model called Husky, fine-tuned for high-quality multi-modal dialogue. Users can interact with ChatGPT by clicking, dragging, and drawing using a pointing device, leading to efficient communication and improved chatbot performance in vision-related tasks.
openfoodfacts-ai
The openfoodfacts-ai repository is dedicated to tracking and storing experimental AI endeavors, models training, and wishlists related to nutrition table detection, category prediction, logos and labels detection, spellcheck, and other AI projects for Open Food Facts. It serves as a hub for integrating AI models into production and collaborating on AI-related issues. The repository also hosts trained models and datasets for public use and experimentation.
BentoDiffusion
BentoDiffusion is a BentoML example project that demonstrates how to serve and deploy diffusion models in the Stable Diffusion (SD) family. These models are specialized in generating and manipulating images based on text prompts. The project provides a guide on using SDXL Turbo as an example, along with instructions on prerequisites, installing dependencies, running the BentoML service, and deploying to BentoCloud. Users can interact with the deployed service using Swagger UI or other methods. Additionally, the project offers the option to choose from various diffusion models available in the repository for deployment.
sunone_aimbot
Sunone Aimbot is an AI-powered aim bot for first-person shooter games. It leverages YOLOv8 and YOLOv10 models, PyTorch, and various tools to automatically target and aim at enemies within the game. The AI model has been trained on more than 30,000 images from popular first-person shooter games like Warface, Destiny 2, Battlefield 2042, CS:GO, Fortnite, The Finals, CS2, and more. The aimbot can be configured through the `config.ini` file to adjust various settings related to object search, capture methods, aiming behavior, hotkeys, mouse settings, shooting options, Arduino integration, AI model parameters, overlay display, debug window, and more. Users are advised to follow specific recommendations to optimize performance and avoid potential issues while using the aimbot.
crossfire-yolo-TensorRT
This repository supports the YOLO series models and provides an AI auto-aiming tool based on YOLO-TensorRT for the game CrossFire. Users can refer to the provided link for compilation and running instructions. The tool includes functionalities for screenshot + inference, mouse movement, and smooth mouse movement. The next goal is to automatically set the optimal PID parameters on the local machine. Developers are welcome to contribute to the improvement of this tool.
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.

react-native-fast-tflite
A high-performance TensorFlow Lite library for React Native that utilizes JSI for power, zero-copy ArrayBuffers for efficiency, and low-level C/C++ TensorFlow Lite core API for direct memory access. It supports swapping out TensorFlow Models at runtime and GPU-accelerated delegates like CoreML/Metal/OpenGL. Easy VisionCamera integration allows for seamless usage. Users can load TensorFlow Lite models, interpret input and output data, and utilize GPU Delegates for faster computation. The library is suitable for real-time object detection, image classification, and other machine learning tasks in React Native applications.
RookieAI_yolov8
RookieAI_yolov8 is an open-source project designed for developers and users interested in utilizing YOLOv8 models for object detection tasks. The project provides instructions for setting up the required libraries and Pytorch, as well as guidance on using custom or official YOLOv8 models. Users can easily train their own models and integrate them with the software. The tool offers features for packaging the code, managing model files, and organizing the necessary resources for running the software. It also includes updates and optimizations for better performance and functionality, with a focus on FPS game aimbot functionalities. The project aims to provide a comprehensive solution for object detection tasks using YOLOv8 models.
Awesome-CVPR2024-ECCV2024-AIGC
A Collection of Papers and Codes for CVPR 2024 AIGC. This repository compiles and organizes research papers and code related to CVPR 2024 and ECCV 2024 AIGC (Artificial Intelligence and Graphics Computing). It serves as a valuable resource for individuals interested in the latest advancements in the field of computer vision and artificial intelligence. Users can find a curated list of papers and accompanying code repositories for further exploration and research. The repository encourages collaboration and contributions from the community through stars, forks, and pull requests.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.

hordelib
horde-engine is a wrapper around ComfyUI designed to run inference pipelines visually designed in the ComfyUI GUI. It enables users to design inference pipelines in ComfyUI and then call them programmatically, maintaining compatibility with the existing horde implementation. The library provides features for processing Horde payloads, initializing the library, downloading and validating models, and generating images based on input data. It also includes custom nodes for preprocessing and tasks such as face restoration and QR code generation. The project depends on various open source projects and bundles some dependencies within the library itself. Users can design ComfyUI pipelines, convert them to the backend format, and run them using the run_image_pipeline() method in hordelib.comfy.Comfy(). The project is actively developed and tested using git, tox, and a specific model directory structure.
awesome-openvino
Awesome OpenVINO is a curated list of AI projects based on the OpenVINO toolkit, offering a rich assortment of projects, libraries, and tutorials covering various topics like model optimization, deployment, and real-world applications across industries. It serves as a valuable resource continuously updated to maximize the potential of OpenVINO in projects, featuring projects like Stable Diffusion web UI, Visioncom, FastSD CPU, OpenVINO AI Plugins for GIMP, and more.
vision-llms-are-blind
This repository contains the code and data for the paper 'Vision Language Models Are Blind'. It explores the limitations of large language models with vision capabilities (VLMs) in performing basic visual tasks that are easy for humans. The repository presents benchmark results showcasing the poor performance of state-of-the-art VLMs on tasks like counting line intersections, identifying circles, letters, and shapes, and following color-coded paths. The research highlights the challenges faced by VLMs in understanding visual information accurately, drawing parallels to myopia and blindness in human vision.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
AI-resources
AI-resources is a repository containing links to various resources for learning Artificial Intelligence. It includes video lectures, courses, tutorials, and open-source libraries related to deep learning, reinforcement learning, machine learning, and more. The repository categorizes resources for beginners, average users, and advanced users/researchers, providing a comprehensive collection of materials to enhance knowledge and skills in AI.
mslearn-ai-vision
The 'mslearn-ai-vision' repository contains lab files for Azure AI Vision modules. It provides hands-on exercises and resources for learning about AI vision capabilities on the Azure platform. The labs cover topics such as image recognition, object detection, and image classification using Azure's AI services. By following the lab exercises, users can gain practical experience in building and deploying AI vision solutions in the cloud.
anylabeling
AnyLabeling is a tool for effortless data labeling with AI support from YOLO and Segment Anything. It combines features from LabelImg and Labelme with an improved UI and auto-labeling capabilities. Users can annotate images with polygons, rectangles, circles, lines, and points, as well as perform auto-labeling using YOLOv5 and Segment Anything. The tool also supports text detection, recognition, and Key Information Extraction (KIE) labeling, with multiple language options available such as English, Vietnamese, and Chinese.
AI-Playground
AI Playground is an open-source project and AI PC starter app designed for AI image creation, image stylizing, and chatbot functionalities on a PC powered by an Intel Arc GPU. It leverages libraries from GitHub and Huggingface, providing users with the ability to create AI-generated content and interact with chatbots. The tool requires specific hardware specifications and offers packaged installers for ease of setup. Users can also develop the project environment, link it to the development environment, and utilize alternative models for different AI tasks.
AirLine
AirLine is a learnable edge-based line detection algorithm designed for various robotic tasks such as scene recognition, 3D reconstruction, and SLAM. It offers a novel approach to extracting line segments directly from edges, enhancing generalization ability for unseen environments. The algorithm balances efficiency and accuracy through a region-grow algorithm and local edge voting scheme for line parameterization. AirLine demonstrates state-of-the-art precision with significant runtime acceleration compared to other learning-based methods, making it ideal for low-power robots.
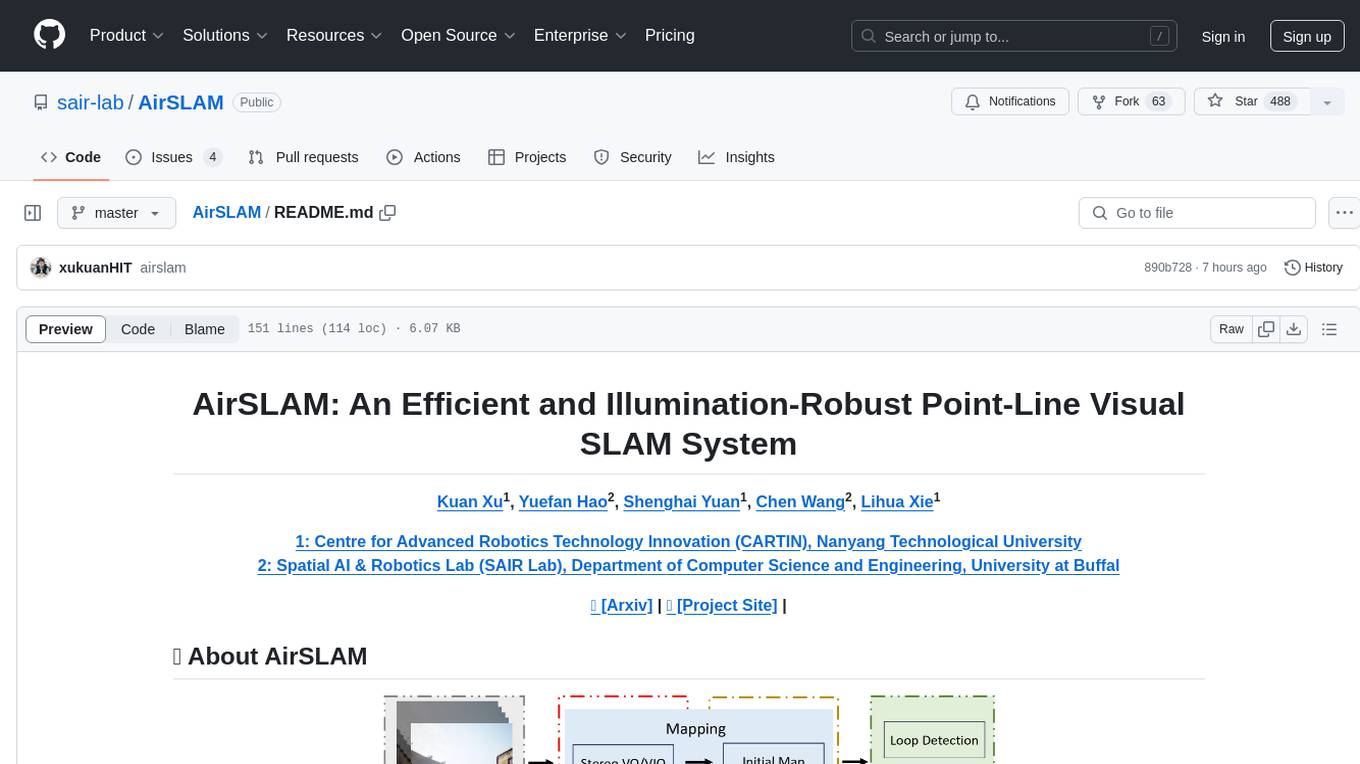
AirSLAM
AirSLAM is an efficient visual SLAM system designed to tackle short-term and long-term illumination challenges. It combines deep learning techniques with traditional optimization methods, featuring a unified CNN for keypoint and structural line extraction. The system includes a relocalization pipeline for map reuse, accelerated using C++ and NVIDIA TensorRT. Outperforming other SLAM systems in challenging environments, it runs at 73Hz on PC and 40Hz on embedded platforms.

Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.
tappas
Hailo TAPPAS is a set of full application examples that implement pipeline elements and pre-trained AI tasks. It demonstrates Hailo's system integration scenarios on predefined systems, aiming to accelerate time to market, simplify integration with Hailo's runtime SW stack, and provide a starting point for customers to fine-tune their applications. The tool supports both Hailo-15 and Hailo-8, offering various example applications optimized for different common hosts. TAPPAS includes pipelines for single network, two network, and multi-stream processing, as well as high-resolution processing via tiling. It also provides example use case pipelines like License Plate Recognition and Multi-Person Multi-Camera Tracking. The tool is regularly updated with new features, bug fixes, and platform support.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.
reComputer-Jetson-for-Beginners
The reComputer Jetson Orin Beginner Guide is a comprehensive resource designed to help developers explore and harness the powerful AI computing capabilities of the NVIDIA Jetson Orin platform. The guide covers a wide range of topics, from basic tools and getting started to advanced applications in computer vision, generative AI, robotics, and more. With step-by-step tutorials and hands-on projects, users can learn to master NVIDIA's core technologies and popular AI frameworks, enabling them to innovate in AI and robotics. The guide is suitable for beginners looking to dive into AI development and build cutting-edge projects with Jetson Orin.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.

nncase
nncase is a neural network compiler for AI accelerators that supports multiple inputs and outputs, static memory allocation, operators fusion and optimizations, float and quantized uint8 inference, post quantization from float model with calibration dataset, and flat model with zero copy loading. It can be installed via pip and supports TFLite, Caffe, and ONNX ops. Users can compile nncase from source using Ninja or make. The tool is suitable for tasks like image classification, object detection, image segmentation, pose estimation, and more.

EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
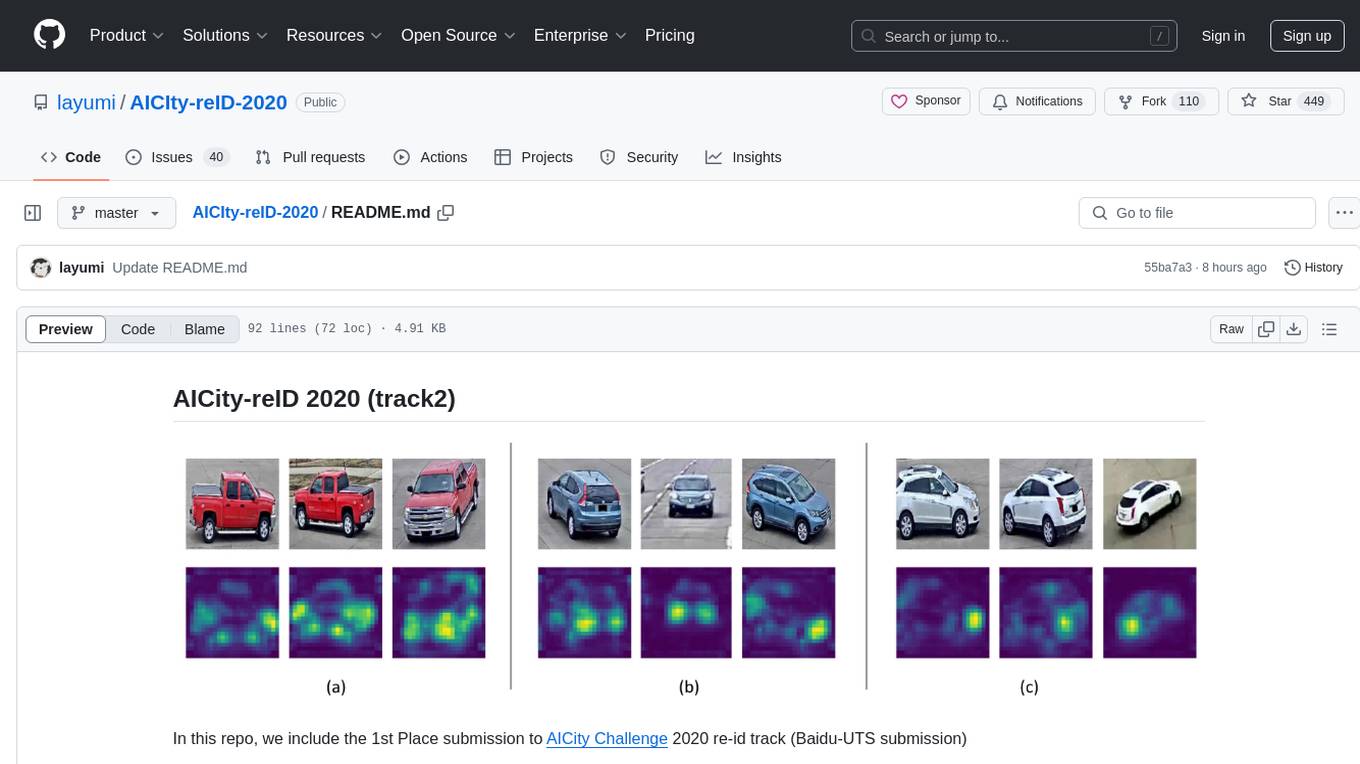
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.
face-api
FaceAPI is an AI-powered tool for face detection, rotation tracking, face description, recognition, age, gender, and emotion prediction. It can be used in both browser and NodeJS environments using TensorFlow/JS. The tool provides live demos for processing images and webcam feeds, along with NodeJS examples for various tasks such as face similarity comparison and multiprocessing. FaceAPI offers different pre-built versions for client-side browser execution and server-side NodeJS execution, with or without TFJS pre-bundled. It is compatible with TFJS 2.0+ and TFJS 3.0+.
DeepLearing-Interview-Awesome-2024
DeepLearning-Interview-Awesome-2024 is a repository that covers various topics related to deep learning, computer vision, big models (LLMs), autonomous driving, smart healthcare, and more. It provides a collection of interview questions with detailed explanations sourced from recent academic papers and industry developments. The repository is aimed at assisting individuals in academic research, work innovation, and job interviews. It includes six major modules covering topics such as large language models (LLMs), computer vision models, common problems in computer vision and perception algorithms, deep learning basics and frameworks, as well as specific tasks like 3D object detection, medical image segmentation, and more.
AI-Video-Boilerplate-Simple
AI-video-boilerplate-simple is a free Live AI Video boilerplate for testing out live video AI experiments. It includes a simple Flask server that serves files, supports live video from various sources, and integrates with Roboflow for AI vision. Users can use this template for projects, research, business ideas, and homework. It is lightweight and can be deployed on popular cloud platforms like Replit, Vercel, Digital Ocean, or Heroku.
AI-Competition-Collections
AI-Competition-Collections is a repository that collects and curates various experiences and tips from AI competitions. It includes posts on competition experiences in computer vision, NLP, speech, and other AI-related fields. The repository aims to provide valuable insights and techniques for individuals participating in AI competitions, covering topics such as image classification, object detection, OCR, adversarial attacks, and more.

GIMP-ML
A.I. for GNU Image Manipulation Program (GIMP-ML) is a repository that provides Python plugins for using computer vision models in GIMP. The code base and models are continuously updated to support newer and more stable functionality. Users can edit images with text, outpaint images, and generate images from text using models like Dalle 2 and Dalle 3. The repository encourages citations using a specific bibtex entry and follows the MIT license for GIMP-ML and the original models.
Virtual_Avatar_ChatBot
Virtual_Avatar_ChatBot is a free AI Chatbot with visual movement that runs on your local computer with minimal GPU requirement. It supports various features like Oogbabooga, betacharacter.ai, and Locall LLM. The tool requires Windows 7 or above, Python, C++ Compiler, Git, and other dependencies. Users can contribute to the open-source project by reporting bugs, creating pull requests, or suggesting new features. The goal is to enhance Voicevox functionality, support local LLM inference, and give the waifu access to the internet. The project references various tools like desktop-waifu, CharacterAI, Whisper, PYVTS, COQUI-AI, VOICEVOX, and VOICEVOX API.
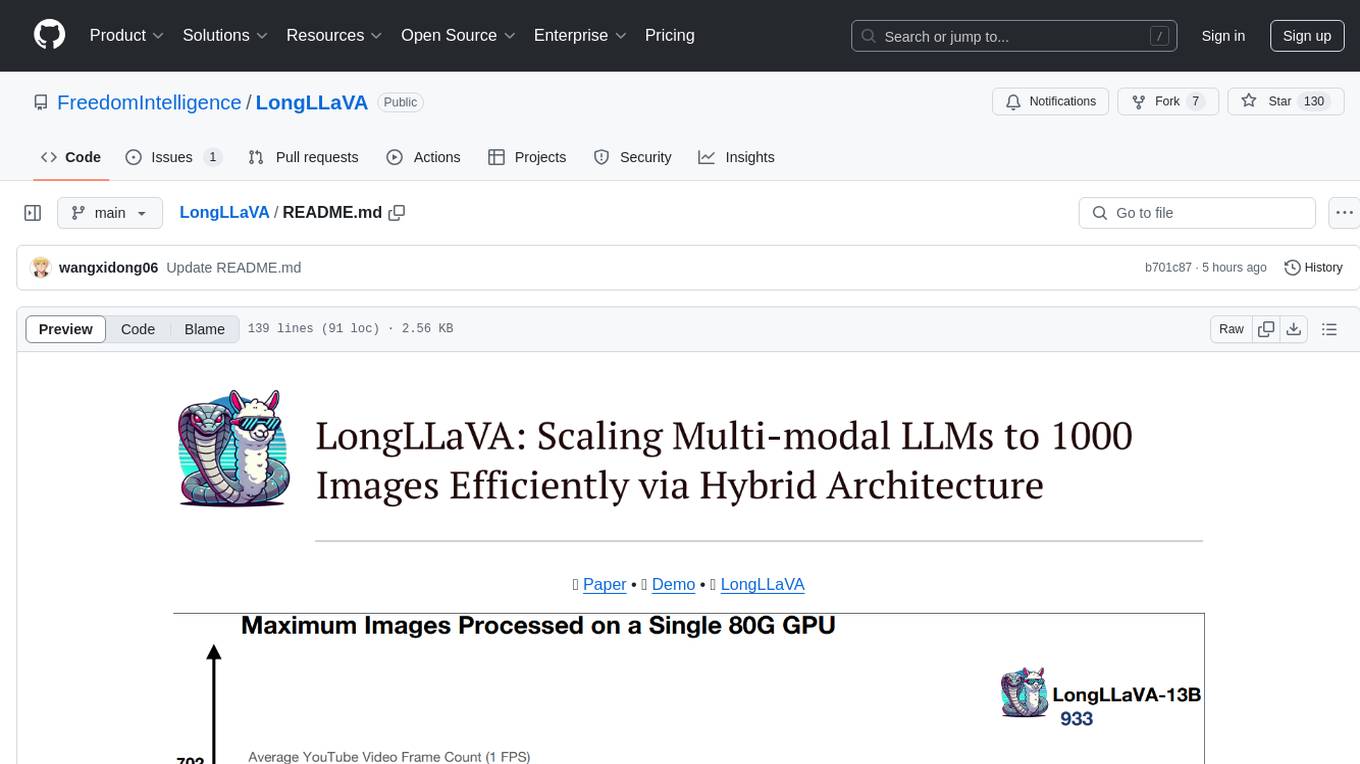
LongLLaVA
LongLLaVA is a tool for scaling multi-modal LLMs to 1000 images efficiently via hybrid architecture. It includes stages for single-image alignment, instruction-tuning, and multi-image instruction-tuning, with evaluation through a command line interface and model inference. The tool aims to achieve GPT-4V level capabilities and beyond, providing reproducibility of results and benchmarks for efficiency and performance.
aitviewer
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. It provides a native Python interface for loading and displaying SMPL[-H/-X], MANO, FLAME, STAR, and SUPR sequences in an interactive viewer. Users can render 3D data on top of images, edit SMPL sequences and poses, export screenshots and videos, and utilize a high-performance ModernGL-based rendering pipeline. The tool is designed for easy use and hacking, with features like headless mode, remote mode, animatable camera paths, and a built-in extensible GUI.
awesome-flux-ai
Awesome Flux AI is a curated list of resources, tools, libraries, and applications related to Flux AI technology. It serves as a comprehensive collection for developers, researchers, and enthusiasts interested in Flux AI. The platform offers open-source text-to-image AI models developed by Black Forest Labs, aiming to advance generative deep learning models for media, creativity, efficiency, and diversity.
flux-fine-tuner
This is a Cog training model that creates LoRA-based fine-tunes for the FLUX.1 family of image generation models. It includes features such as automatic image captioning during training, image generation using LoRA, uploading fine-tuned weights to Hugging Face, automated test suite for continuous deployment, and Weights and biases integration. The tool is designed for users to fine-tune Flux models on Replicate for image generation tasks.
MiKaPo
MiKaPo is a web-based tool that allows users to pose MMD models in real-time using video input. It utilizes technologies such as Mediapipe for 3D key points detection, Babylon.js for 3D scene rendering, babylon-mmd for MMD model viewing, and Vite+React for the web framework. Users can upload videos and images, select different environments, and choose models for posing. MiKaPo also supports camera input and Ollama (electron version). The tool is open to feature requests and pull requests, with ongoing development to add VMD export functionality.
spear
SPEAR is a Simulator for Photorealistic Embodied AI Research that addresses limitations in existing simulators by offering 300 unique virtual indoor environments with detailed geometry, photorealistic materials, and unique floor plans. It provides an OpenAI Gym interface for interaction via Python, released under an MIT License. The simulator was developed with support from the Intelligent Systems Lab at Intel and Kujiale.
edgeai
Embedded inference of Deep Learning models is quite challenging due to high compute requirements. TI’s Edge AI software product helps optimize and accelerate inference on TI’s embedded devices. It supports heterogeneous execution of DNNs across cortex-A based MPUs, TI’s latest generation C7x DSP, and DNN accelerator (MMA). The solution simplifies the product life cycle of DNN development and deployment by providing a rich set of tools and optimized libraries.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.
SageAttention
SageAttention is an official implementation of an accurate 8-bit attention mechanism for plug-and-play inference acceleration. It is optimized for RTX4090 and RTX3090 GPUs, providing performance improvements for specific GPU architectures. The tool offers a technique called 'smooth_k' to ensure accuracy in processing FP16/BF16 data. Users can easily replace 'scaled_dot_product_attention' with SageAttention for faster video processing.

Vision-LLM-Alignment
Vision-LLM-Alignment is a repository focused on implementing alignment training for visual large language models (LLMs), including SFT training, reward model training, and PPO/DPO training. It supports various model architectures and provides datasets for training. The repository also offers benchmark results and installation instructions for users.
ComfyUI-fal-API
ComfyUI-fal-API is a repository containing custom nodes for using Flux models with fal API in ComfyUI. It provides nodes for image generation, video generation, language models, and vision language models. Users can easily install and configure the repository to access various nodes for different tasks such as generating images, creating videos, processing text, and understanding images. The repository also includes troubleshooting steps and is licensed under the Apache License 2.0.
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.

xaitk-saliency
The `xaitk-saliency` package is an open source Explainable AI (XAI) framework for visual saliency algorithm interfaces and implementations, designed for analytics and autonomy applications. It provides saliency algorithms for various image understanding tasks such as image classification, image similarity, object detection, and reinforcement learning. The toolkit targets data scientists and developers who aim to incorporate visual saliency explanations into their workflow or product, offering both direct accessibility for experimentation and modular integration into systems and applications through Strategy and Adapter patterns. The package includes documentation, examples, and a demonstration tool for visual saliency generation in a user-interface.
scaleapi-python-client
The Scale AI Python SDK is a tool that provides a Python interface for interacting with the Scale API. It allows users to easily create tasks, manage projects, upload files, and work with evaluation tasks, training tasks, and Studio assignments. The SDK handles error handling and provides detailed documentation for each method. Users can also manage teammates, project groups, and batches within the Scale Studio environment. The SDK supports various functionalities such as creating tasks, retrieving tasks, canceling tasks, auditing tasks, updating task attributes, managing files, managing team members, and working with evaluation and training tasks.
Plug-play-modules
Plug-play-modules is a comprehensive collection of plug-and-play modules for AI, deep learning, and computer vision applications. It includes various convolution variants, latest attention mechanisms, feature fusion modules, up-sampling/down-sampling modules, suitable for tasks like image classification, object detection, instance segmentation, semantic segmentation, single object tracking (SOT), multi-object tracking (MOT), infrared object tracking (RGBT), image de-raining, de-fogging, de-blurring, super-resolution, and more. The modules are designed to enhance model performance and feature extraction capabilities across various tasks.
AIAS
AIAS is a comprehensive AI training platform that offers courses and practical examples in various AI fields such as traditional image processing, deep learning algorithms, JavaAI applications, NLP, web development, image generation, and desktop application development. The platform also provides SDKs for tasks like image recognition, OCR, natural language processing, audio processing, video analysis, and big data analysis. Users can access training materials, source code, and tools for developing AI applications across different domains.
DeepSparkHub
DeepSparkHub is a repository that curates hundreds of application algorithms and models covering various fields in AI and general computing. It supports mainstream intelligent computing scenarios in markets such as smart cities, digital individuals, healthcare, education, communication, energy, and more. The repository provides a wide range of models for tasks such as computer vision, face detection, face recognition, instance segmentation, image generation, knowledge distillation, network pruning, object detection, 3D object detection, OCR, pose estimation, self-supervised learning, semantic segmentation, super resolution, tracking, traffic forecast, GNN, HPC, methodology, multimodal, NLP, recommendation, reinforcement learning, speech recognition, speech synthesis, and 3D reconstruction.
qapyq
qapyq is an image viewer and AI-assisted editing tool designed to help curate datasets for generative AI models. It offers features such as image viewing, editing, captioning, batch processing, and AI assistance. Users can perform tasks like cropping, scaling, editing masks, tagging, and applying sorting and filtering rules. The tool supports state-of-the-art captioning and masking models, with options for model settings, GPU acceleration, and quantization. qapyq aims to streamline the process of preparing images for training AI models by providing a user-friendly interface and advanced functionalities.
SG-Nav
SG-Nav is an online 3D scene graph prompting tool designed for LLM-based zero-shot object navigation. It proposes a framework that constructs an online 3D scene graph to prompt LLMs, allowing direct application to various scenes and categories without the need for training.
zenu
ZeNu is a high-performance deep learning framework implemented in pure Rust, featuring a pure Rust implementation for safety and performance, GPU performance comparable to PyTorch with CUDA support, a simple and intuitive API, and a modular design for easy extension. It supports various layers like Linear, Convolution 2D, LSTM, and optimizers such as SGD and Adam. ZeNu also provides device support for CPU and CUDA (NVIDIA GPU) with CUDA 12.3 and cuDNN 9. The project structure includes main library, automatic differentiation engine, neural network layers, matrix operations, optimization algorithms, CUDA implementation, and other support crates. Users can find detailed implementations like MNIST classification, CIFAR10 classification, and ResNet implementation in the examples directory. Contributions to ZeNu are welcome under the MIT License.
yolo-flutter-app
Ultralytics YOLO for Flutter is a Flutter plugin that allows you to integrate Ultralytics YOLO computer vision models into your mobile apps. It supports both Android and iOS platforms, providing APIs for object detection and image classification. The plugin leverages Flutter Platform Channels for seamless communication between the client and host, handling all processing natively. Before using the plugin, you need to export the required models in `.tflite` and `.mlmodel` formats. The plugin provides support for tasks like detection and classification, with specific instructions for Android and iOS platforms. It also includes features like camera preview and methods for object detection and image classification on images. Ultralytics YOLO thrives on community collaboration and offers different licensing paths for open-source and commercial use cases.
sdk-examples
Spectacular AI SDK fuses data from cameras and IMU sensors to output an accurate 6-degree-of-freedom pose of a device, enabling Visual-Inertial SLAM for tracking robots and vehicles, as well as Augmented, Mixed, and Virtual Reality. The SDK includes a Mapping API for real-time and offline 3D reconstruction use cases.
cuckoo
Cuckoo is a Decentralized AI Platform that focuses on GPU-sharing for text-to-image generation and LLM inference. It provides a platform for users to generate images using Telegram or Discord.
fiftyone-brain
FiftyOne Brain contains the open source AI/ML capabilities for the FiftyOne ecosystem, enabling users to automatically analyze and manipulate their datasets and models. Features include visual similarity search, query by text, finding unique and representative samples, finding media quality problems and annotation mistakes, and more.
awesome-object-detection-datasets
This repository is a curated list of awesome public object detection and recognition datasets. It includes a wide range of datasets related to object detection and recognition tasks, such as general detection and recognition datasets, autonomous driving datasets, adverse weather datasets, person detection datasets, anti-UAV datasets, optical aerial imagery datasets, low-light image datasets, infrared image datasets, SAR image datasets, multispectral image datasets, 3D object detection datasets, vehicle-to-everything field datasets, super-resolution field datasets, and face detection and recognition datasets. The repository also provides information on tools for data annotation, data augmentation, and data management related to object detection tasks.
MaixCDK
MaixCDK (Maix C/CPP Development Kit) is a C/C++ development kit that integrates practical functions such as AI, machine vision, and IoT. It provides easy-to-use encapsulation for quickly building projects in vision, artificial intelligence, IoT, robotics, industrial cameras, and more. It supports hardware-accelerated execution of AI models, common vision algorithms, OpenCV, and interfaces for peripheral operations. MaixCDK offers cross-platform support, easy-to-use API, simple environment setup, online debugging, and a complete ecosystem including MaixPy and MaixVision. Supported devices include Sipeed MaixCAM, Sipeed MaixCAM-Pro, and partial support for Common Linux.
ComfyUI-HunyuanVideo-Nyan
ComfyUI-HunyuanVideo-Nyan is a repository that provides tools for manipulating the attention of LLM models, allowing users to shuffle the AI's attention and cause confusion. The repository includes a Nerdy Transformer Shuffle node that enables users to mess with the LLM's attention layers, providing a workflow for installation and usage. It also offers a new SAE-informed Long-CLIP model with high accuracy, along with recommendations for CLIP models. Users can find detailed instructions on how to use the provided nodes to scale CLIP & LLM factors and create high-quality nature videos. The repository emphasizes compatibility with other related tools and provides insights into the functionality of the included nodes.
LlamaV-o1
LlamaV-o1 is a Large Multimodal Model designed for spontaneous reasoning tasks. It outperforms various existing models on multimodal reasoning benchmarks. The project includes a Step-by-Step Visual Reasoning Benchmark, a novel evaluation metric, and a combined Multi-Step Curriculum Learning and Beam Search Approach. The model achieves superior performance in complex multi-step visual reasoning tasks in terms of accuracy and efficiency.
llama-cookbook
The Llama Cookbook is the official guide for building with Llama Models, providing resources for inference, fine-tuning, and end-to-end use-cases of Llama Text and Vision models. The repository includes popular community approaches, use-cases, and recipes for working with Llama models. It covers topics such as multimodal inference, inferencing using Llama Guard, and specific tasks like Email Agent and Text to SQL. The structure includes sections for 3P Integrations, End to End Use Cases, Getting Started guides, and the source code for the original llama-recipes library.

MAVIS
MAVIS (Math Visual Intelligent System) is an AI-driven application that allows users to analyze visual data such as images and generate interactive answers based on them. It can perform complex mathematical calculations, solve programming tasks, and create professional graphics. MAVIS supports Python for coding and frameworks like Matplotlib, Plotly, Seaborn, Altair, NumPy, Math, SymPy, and Pandas. It is designed to make projects more efficient and professional.
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.
InsPLAD
InsPLAD is a dataset and benchmark for power line asset inspection in UAV images. It contains 10,607 high-resolution UAV color images of seventeen unique power line assets with six defects. The dataset is used for object detection, defect classification, and anomaly detection tasks in computer vision. InsPLAD offers challenges like multi-scale objects, intra-class variation, cluttered background, and varied lighting conditions, aiming to improve state-of-the-art methods in the field.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.

LabelQuick
LabelQuick_V2.0 is a fast image annotation tool designed and developed by the AI Horizon team. This version has been optimized and improved based on the previous version. It provides an intuitive interface and powerful annotation and segmentation functions to efficiently complete dataset annotation work. The tool supports video object tracking annotation, quick annotation by clicking, and various video operations. It introduces the SAM2 model for accurate and efficient object detection in video frames, reducing manual intervention and improving annotation quality. The tool is designed for Windows systems and requires a minimum of 6GB of memory.
BetterOCR
BetterOCR is a tool that enhances text detection by combining multiple OCR engines with LLM (Language Model). It aims to improve OCR results, especially for languages with limited training data or noisy outputs. The tool combines results from EasyOCR, Tesseract, and Pororo engines, along with LLM support from OpenAI. Users can provide custom context for better accuracy, view performance examples by language, and upcoming features include box detection, improved interface, and async support. The package is under rapid development and contributions are welcomed.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
algebraic-nnhw
This repository contains the source code for a GEMM & deep learning hardware accelerator system used to validate proposed systolic array hardware architectures implementing efficient matrix multiplication algorithms to increase performance-per-area limits of GEMM & AI accelerators. Achieved results include up to 3× faster CNN inference, >2× higher mults/multiplier/clock cycle, and low area with high clock frequency. The system is specialized for inference of non-sparse DNN models with fixed-point/quantized inputs, fully accelerating all DNN layers in hardware, and highly optimizing GEMM acceleration.
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.
holohub
Holohub is a central repository for the NVIDIA Holoscan AI sensor processing community to share reference applications, operators, tutorials, and benchmarks. It includes example applications, community components, package configurations, and tutorials. Users and developers of the Holoscan platform are invited to reuse and contribute to this repository. The repository provides detailed instructions on prerequisites, building, running applications, contributing, and glossary terms. It also offers a searchable catalog of available components on the Holoscan SDK User Guide website.
ollama-playground
Ollama Projects is a repository containing code for various projects built using Ollama's open-source models. The projects include Chat with PDF, Chat with PDF Using Hybrid RAG, AI Scraper, Image Search, OCR, Object Detection, Emotion Detection, and AI Researcher. These projects showcase the capabilities of Ollama's models and provide insights into AI applications in different domains.
Electronic-Component-Sorter
The Electronic Component Classifier is a project that uses machine learning and artificial intelligence to automate the identification and classification of electrical and electronic components. It features component classification into seven classes, user-friendly design, and integration with Flask for a user-friendly interface. The project aims to reduce human error in component identification, make the process safer and more reliable, and potentially help visually impaired individuals in identifying electronic components.
vlmrun-cookbook
VLM Run Cookbook is a repository containing practical examples and tutorials for extracting structured data from images, videos, and documents using Vision Language Models (VLMs). It offers comprehensive Colab notebooks demonstrating real-world applications of VLM Run, with complete code and documentation for easy adaptation. The examples cover various domains such as financial documents and TV news analysis.
plants_disease_detection
This repository contains code for the AI challenger competition on plant disease detection. The goal is to classify nearly 50,000 plant leaf photos into 61 categories based on 'species-disease-severity'. The framework used is Keras with TensorFlow backend, implementing DenseNet for image classification. Data is uploaded to a private dataset on Kaggle for model training. The code includes data preparation, model training, and prediction steps.
finetrainers
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.

awesome-and-novel-works-in-slam
This repository contains a curated list of cutting-edge works in Simultaneous Localization and Mapping (SLAM). It includes research papers, projects, and tools related to various aspects of SLAM, such as 3D reconstruction, semantic mapping, novel algorithms, large-scale mapping, and more. The repository aims to showcase the latest advancements in SLAM technology and provide resources for researchers and practitioners in the field.
shitspotter
The 'ShitSpotter' repository is dedicated to developing a poop-detection algorithm and dataset for creating a phone app that helps locate dog poop in outdoor environments. The project involves training a PyTorch network to detect poop in images and provides scripts for detecting poop in unseen images using a pretrained model. The dataset consists of mostly outdoor images taken with a phone, with a process involving before and after pictures of the poop. The project aims to enable various applications, such as AR glasses for poop detection and efficient cleaning of public areas by city governments. The code, dataset, and pretrained models are open source with permissive licensing and distributed via IPFS, BitTorrent, and centralized mechanisms.

deeppowers
Deeppowers is a powerful Python library for deep learning applications. It provides a wide range of tools and utilities to simplify the process of building and training deep neural networks. With Deeppowers, users can easily create complex neural network architectures, perform efficient training and optimization, and deploy models for various tasks. The library is designed to be user-friendly and flexible, making it suitable for both beginners and experienced deep learning practitioners.

supallm
Supallm is a Python library for super resolution of images using deep learning techniques. It provides pre-trained models for enhancing image quality by increasing resolution. The library is easy to use and allows users to upscale images with high fidelity and detail. Supallm is suitable for tasks such as enhancing image quality, improving visual appearance, and increasing the resolution of low-quality images. It is a valuable tool for researchers, photographers, graphic designers, and anyone looking to enhance image quality using AI technology.
cad-recode
CAD-Recode is a 3D CAD reverse engineering method implemented in Python using the CadQuery library. It transforms point clouds into 3D CAD models by leveraging a pre-trained model and additional linear layers. The repository includes an inference demo for users to generate CAD models from point clouds. CAD-Recode has achieved state-of-the-art performance in CAD reconstruction benchmarks such as DeepCAD, Fusion360, and CC3D. Researchers and engineers can utilize this tool to reverse engineer CAD code from point clouds efficiently.
LLMOCR
LLMOCR is a tool that utilizes a local Large Language Model (LLM) to extract text from images. It offers a user-friendly GUI and supports GPU acceleration for faster inference. The tool is cross-platform, compatible with Windows, macOS ARM, and Linux. Users can prompt the LLM to process images in a customized way. The processing is done locally on the user's machine, ensuring data privacy and security. LLMOCR requires Python 3.8 or higher and KoboldCPP for installation and operation.
FaceAiSharp
FaceAiSharp is a .NET library designed for face-related computer vision tasks. It offers functionalities such as face detection, face recognition, facial landmarks detection, and eye state detection. The library utilizes pretrained ONNX models for accurate and efficient results, enabling users to integrate these capabilities into their .NET applications easily. With a focus on simplicity and performance, FaceAiSharp provides a local processing solution without relying on cloud services, supporting image-based face processing using ImageSharp. It is cross-platform compatible, supporting Windows, Linux, Android, and more.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.
foundations-of-gen-ai
This repository contains code for the O'Reilly Live Online Training for 'Transformer Architectures for Generative AI'. The course provides a deep understanding of transformer architectures and their impact on natural language processing (NLP) and vision tasks. Participants learn to harness transformers to tackle problems in text, image, and multimodal AI through theory and practical exercises.
cortex.cpp
Cortex.cpp is an open-source platform designed as the brain for robots, offering functionalities such as vision, speech, language, tabular data processing, and action. It provides an AI platform for running AI models with multi-engine support, hardware optimization with automatic GPU detection, and an OpenAI-compatible API. Users can download models from the Hugging Face model hub, run models, manage resources, and access advanced features like multiple quantizations and engine management. The tool is under active development, promising rapid improvements for users.
star-vector
StarVector is a multimodal vision-language model for Scalable Vector Graphics (SVG) generation. It can be used to perform image2SVG and text2SVG generation. StarVector works directly in the SVG code space, leveraging visual understanding to apply accurate SVG primitives. It achieves state-of-the-art performance in producing compact and semantically rich SVGs. The tool provides Hugging Face model checkpoints for image2SVG vectorization, with models like StarVector-8B and StarVector-1B. It also offers datasets like SVG-Stack, SVG-Fonts, SVG-Icons, SVG-Emoji, and SVG-Diagrams for evaluation. StarVector can be trained using Deepspeed or FSDP for tasks like Image2SVG and Text2SVG generation. The tool provides a demo with options for HuggingFace generation or VLLM backend for faster generation speed.
QuestCameraKit
QuestCameraKit is a collection of template and reference projects demonstrating how to use Meta Quest’s new Passthrough Camera API (PCA) for advanced AR/VR vision, tracking, and shader effects. It includes samples like Color Picker, Object Detection with Unity Sentis, QR Code Tracking with ZXing, Frosted Glass Shader, OpenAI vision model, and WebRTC video streaming. The repository provides detailed instructions on how to run each sample and troubleshoot known issues. Users can explore various functionalities such as converting 3D points to 2D image pixels, detecting objects, tracking QR codes, applying custom shader effects, interacting with OpenAI's vision model, and streaming camera feed over WebRTC.
osm-ai-helper
OSM-AI-helper is a Blueprint by Mozilla.ai designed to assist users in mapping features in OpenStreetMap using object detection and image segmentation models. It provides tools for identifying and mapping various features, such as swimming pools, in OpenStreetMap. Users can also create custom datasets and fine-tune models for different use cases. The project is licensed under the AGPL-3.0 License and welcomes contributions from the community.

mmf
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. It contains reference implementations of state-of-the-art vision and language models, allowing distributed training. MMF serves as a starter codebase for challenges around vision and language datasets, such as The Hateful Memes, TextVQA, TextCaps, and VQA challenges. It is scalable, fast, and un-opinionated, providing a solid foundation for vision and language multimodal research projects.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and fostering collaboration. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, configuration management, training job monitoring, media upload, and prediction. The repository also includes tutorial-style Jupyter notebooks demonstrating SDK usage.

cosmos-predict1
Cosmos-Predict1 is a specialized branch of Cosmos World Foundation Models (WFMs) focused on future state prediction, offering diffusion-based and autoregressive-based world foundation models for Text2World and Video2World generation. It includes image and video tokenizers for efficient tokenization, along with post-training and pre-training scripts for Physical AI builders. The tool provides various models for different tasks such as text to visual world generation, video-based future visual world generation, and tokenization of images and videos.
omnihuman
OmniHuman is an AI model designed to understand humanoids and text. It provides functionalities to process images and videos, generating text descriptions for human actions depicted in the visual content. The tool offers support for various tasks related to human pose recognition and action understanding. Users can easily integrate OmniHuman into their projects to enhance the capabilities of their applications in recognizing and interpreting human actions in images and videos.
edge-ai-libraries
The Edge AI Libraries project is a collection of libraries, microservices, and tools for Edge application development. It includes sample applications showcasing generic AI use cases. Key components include Anomalib, Dataset Management Framework, Deep Learning Streamer, ECAT EnableKit, EtherCAT Masterstack, FLANN, OpenVINO toolkit, Audio Analyzer, ORB Extractor, PCL, PLCopen Servo, Real-time Data Agent, RTmotion, Audio Intelligence, Deep Learning Streamer Pipeline Server, Document Ingestion, Model Registry, Multimodal Embedding Serving, Time Series Analytics, Vector Retriever, Visual-Data Preparation, VLM Inference Serving, Intel Geti, Intel SceneScape, Visual Pipeline and Platform Evaluation Tool, Chat Question and Answer, Document Summarization, PLCopen Benchmark, PLCopen Databus, Video Search and Summarization, Isolation Forest Classifier, Random Forest Microservices. Visit sub-directories for instructions and guides.

notebooks
The 'notebooks' repository contains a collection of fine-tuning notebooks for various models, including Gemma3N, Qwen3, Llama 3.2, Phi-4, Mistral v0.3, and more. These notebooks are designed for tasks such as data preparation, model training, evaluation, and model saving. Users can access guided notebooks for different types of models like Conversational, Vision, TTS, GRPO, and more. The repository also includes specific use-case notebooks for tasks like text classification, tool calling, multiple datasets, KTO, inference chat UI, conversational tasks, chatML, and text completion.
nndeploy
nndeploy is a tool that allows you to quickly build your visual AI workflow without the need for frontend technology. It provides ready-to-use algorithm nodes for non-AI programmers, including large language models, Stable Diffusion, object detection, image segmentation, etc. The workflow can be exported as a JSON configuration file, supporting Python/C++ API for direct loading and running, deployment on cloud servers, desktops, mobile devices, edge devices, and more. The framework includes mainstream high-performance inference engines and deep optimization strategies to help you transform your workflow into enterprise-level production applications.
AIGC-Interview-Book
AIGC-Interview-Book is the ultimate guide for AIGC algorithm and development job interviews, covering a wide range of topics such as AIGC, traditional deep learning, autonomous driving, AI agent, machine learning, computer vision, natural language processing, reinforcement learning, embodied intelligence, metaverse, AGI, Python, Java, C/C++, Go, embedded systems, front-end, back-end, testing, and operations. The repository consolidates industry experience and insights from frontline AIGC algorithm experts, providing resources on AIGC knowledge framework, internal referrals at AIGC big companies, interview experiences, company guides, AI campus recruitment schedule, interview preparation, salary insights, coding guide, and job-seeking Q&A. It serves as a valuable resource for AIGC-related professionals, students, and job seekers, offering insights and guidance for career advancement and job interviews in the AIGC field.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.

CogVideo
CogVideo is a Python library for analyzing and processing video data. It provides functionalities for video segmentation, object detection, and tracking. With CogVideo, users can extract meaningful information from video streams, enabling applications in computer vision, surveillance, and video analytics. The library is designed to be user-friendly and efficient, making it suitable for both research and industrial projects.
AliceVision
AliceVision is a photogrammetric computer vision framework which provides a 3D reconstruction pipeline. It is designed to process images from different viewpoints and create detailed 3D models of objects or scenes. The framework includes various algorithms for feature detection, matching, and structure from motion. AliceVision is suitable for researchers, developers, and enthusiasts interested in computer vision, photogrammetry, and 3D modeling. It can be used for applications such as creating 3D models of buildings, archaeological sites, or objects for virtual reality and augmented reality experiences.

deepteam
Deepteam is a powerful open-source tool designed for deep learning projects. It provides a user-friendly interface for training, testing, and deploying deep neural networks. With Deepteam, users can easily create and manage complex models, visualize training progress, and optimize hyperparameters. The tool supports various deep learning frameworks and allows seamless integration with popular libraries like TensorFlow and PyTorch. Whether you are a beginner or an experienced deep learning practitioner, Deepteam simplifies the development process and accelerates model deployment.
achatbot
achatbot is a factory tool that allows users to create chat bots with various functionalities such as llm (language models), asr (automatic speech recognition), tts (text-to-speech), vad (voice activity detection), ocr (optical character recognition), and object detection. The tool provides a structured project with features like chat bots for cmd, grpc, and http servers. It supports various chat bot processors, transport connectors, and AI modules for different tasks. Users can run chat bots locally or deploy them on cloud services like vercel, Cloudflare, AWS Lambda, or Docker. The tool also includes UI components for easy deployment and service architecture diagrams for reference.
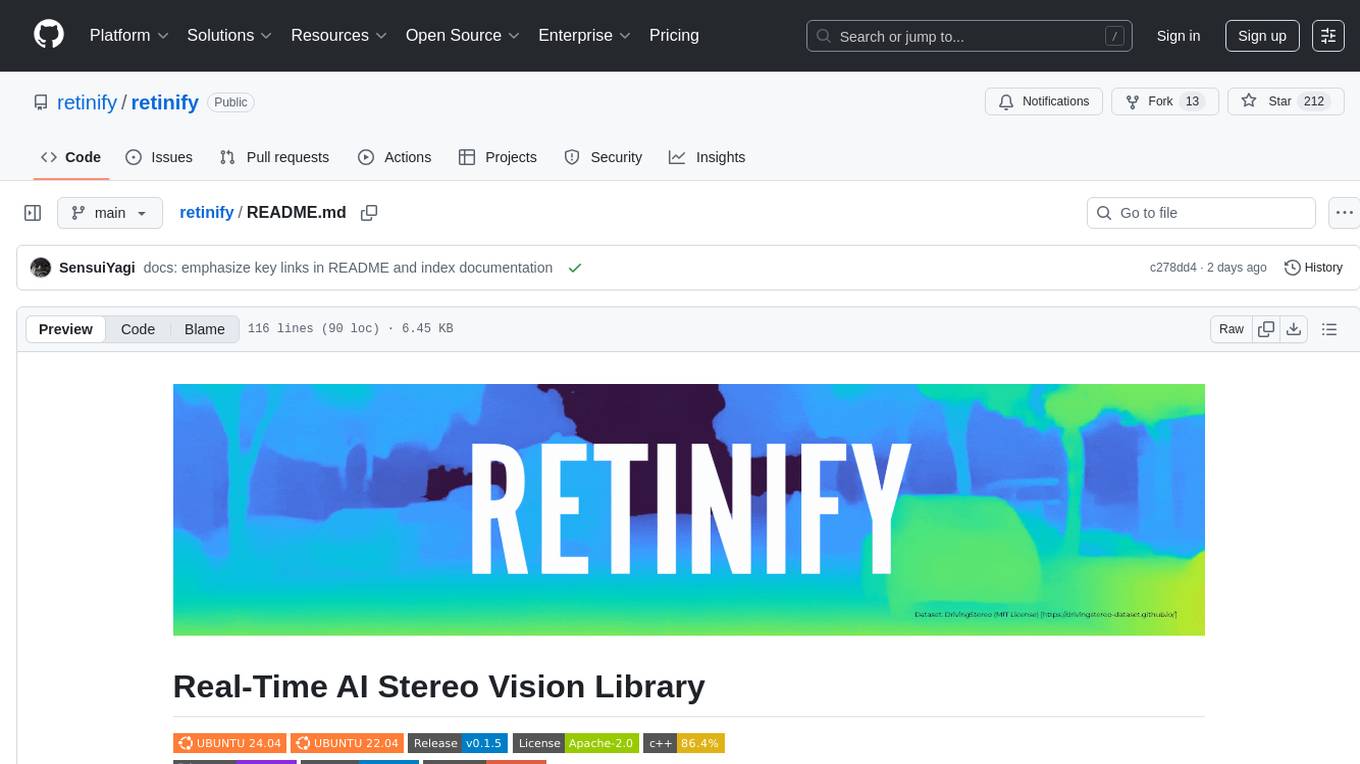
retinify
Retinify is an advanced AI-powered stereo vision library designed for robotics, enabling real-time, high-precision 3D perception by leveraging GPU and NPU acceleration. It is open source under Apache-2.0 license, offers high precision 3D mapping and object recognition, runs computations on GPU for fast performance, accepts stereo images from any rectified camera setup, is cost-efficient using minimal hardware, and has minimal dependencies on CUDA Toolkit, cuDNN, and TensorRT. The tool provides a pipeline for stereo matching and supports various image data types independently of OpenCV.
DL-Hub
DL-Hub is a deep learning repository containing various study materials and code projects in the fields of machine learning, deep learning, computer vision, natural language processing, and web crawling. It includes paper analysis, deep learning projects, graph neural network replications, machine learning algorithms, transformer models, and optimization implementations. The repository aims to provide valuable resources for learning and research in the deep learning and machine learning domains.
map-anything
MapAnything is an end-to-end trained transformer model for 3D reconstruction tasks, supporting over 12 different tasks including multi-image sfm, multi-view stereo, monocular metric depth estimation, and more. It provides a simple and efficient way to regress the factored metric 3D geometry of a scene from various inputs like images, calibration, poses, or depth. The tool offers flexibility in combining different geometric inputs for enhanced reconstruction results. It includes interactive demos, support for COLMAP & GSplat, data processing for training & benchmarking, and pre-trained models on Hugging Face Hub with different licensing options.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!

MiniCPM-V-CookBook
MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.
LLaVA-OneVision-1.5
LLaVA-OneVision 1.5 is a fully open framework for democratized multimodal training, introducing a novel family of large multimodal models achieving state-of-the-art performance at lower cost through training on native resolution images. It offers superior performance across multiple benchmarks, high-quality data at scale with concept-balanced and diverse caption data, and an ultra-efficient training framework with support for MoE, FP8, and long sequence parallelization. The framework is fully open for community access and reproducibility, providing high-quality pre-training & SFT data, complete training framework & code, training recipes & configurations, and comprehensive training logs & metrics.
LLM
LLM is a repository focused on providing educational courses on artificial intelligence models, specifically focusing on language and image understanding. The courses are taught by Alireza Akhavan Pour and cover topics such as generative AI models and language-image understanding. The repository also includes information on how to contact the team through Telegram channels for course updates and Q&A sessions. Participants are encouraged to add their LLM or VLM course certificates to their LinkedIn profiles and tag Alireza Akhavan Pour for recognition and resume enhancement.
jimeng-free-api-all
Jimeng AI Free API is a reverse-engineered API server that encapsulates Jimeng AI's image and video generation capabilities into OpenAI-compatible API interfaces. It supports the latest jimeng-5.0-preview, jimeng-4.6 text-to-image models, Seedance 2.0 multi-image intelligent video generation, zero-configuration deployment, and multi-token support. The API is fully compatible with OpenAI API format, seamlessly integrating with existing clients and supporting multiple session IDs for polling usage.
Minimalistic-Comfy-Wrapper-WebUI
Minimalistic Comfy Wrapper WebUI is a user interface extension for ComfyUI that provides an additional inference-focused UI. It dynamically adapts to workflows, allowing users to change node titles and refresh the UI. The tool ensures stability by storing data in the browser's local storage, supports working with the same workflows in Comfy and the webui, offers better queues management, prompt presets, batch support, a minimalist image editor, and mobile-friendly UI. Users can install it from the ComfyUI manager and customize node titles for input and output nodes. The tool is designed for users who prefer a simpler interface for inference tasks and want to work with ComfyUI workflows from a different perspective.
20 - OpenAI Gpts

AI-Driven Lab
recommends AI research these days in Japanese using AI-driven's-lab articles
Street Sign Recognition GPT
Friendly and professional guide for street sign app development.

Pixie: Computer Vision Engineer
Expert in computer vision, deep learning, ready to assist you with 3d and geometric computer vision. https://github.com/kornia/pixie


KingLand ∞ L'Élite Numérique IA
Plateforme innovante en IA pour passionnés de technologie, offrant conseils et articles via 100 IA collaboratives.
Media AI Visionary
Leading AI & Media Expert: In-depth, Ethical, Insightful, developed on OpenAI