
gen-cv
Vision AI Solution Accelerator
Stars: 417

This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.
README:

This repository serves as a rich resource offering numerous examples of synthetic image generation, manipulation, and reasoning. Utilizing Azure Machine Learning, Computer Vision, OpenAI, and widely acclaimed open-source frameworks like Stable Diffusion, it equips users with practical insights into the application of these powerful tools in the realm of image processing.
- 🆕Azure OpenAI Vision Fine-tuning for video analysis
- 🆕Azure OpenAI Vision Fine-tuning starter
- 🆕 Guided Content Generation
- Find and analyze Videos using GPT4-Vision with Video Enhancements
- Create engagaing Avatar Videos
- Create interactive Avatar Experiences
- Stable Diffusion XL with Azure Machine Learning
- Azure Computer Vision in a Day Workshop
- Explore the OpenAI DALL E-2 API
- Create images with the Azure OpenAI DALL E-2 API
- Remove background from images using the Florence foundation model
- Precise Inpainting with Segment Anything, DALLE-2 and Stable Diffusion
- Add custom objects and styles to image generation models with Dreambooth
- Create and find images with Stable Diffusion and Florence Vector Search
- Manage image embeddings with the Cognitive Search Vector Store
The code within this repository has been tested on both Github Codespaces compute and an Azure Machine Learning Compute Instance. Although the use of a GPU is not a requirement, it is highly recommended if you aim to generate a large number of sample images using Stable Diffusion.
Follow these steps to get started:
- Clone this repository on your preferred compute using the following command:
git clone https://github.com/Azure/gen-cv.git- Create your Python environment and install the necessary dependencies. For our development, we utilized Conda. You can do the same with these commands:
conda create -n gen-cv python=3.10
conda activate gen-cv
pip install -r requirements.txt- From the list provided above, select a sample notebook. After making your selection, configure the Jupyter notebook to use the kernel associated with the environment you set up in Step 2.
- Copy the
.env.templatefile to.envto store your parameters:
cp .env.template .env- Add the required parameters and keys for your services to the
.envfile.
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gen-cv
Similar Open Source Tools
gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.
dstoolkit-text2sql-and-imageprocessing
This repository provides sample code for improving RAG applications with rich data sources including SQL Warehouses and documents analysed with Azure Document Intelligence. It includes components for Text2SQL generation and querying, linking Azure Document Intelligence with AI Search for processing complex documents, and deploying AI search indexes. The plugins and skills aim to enhance response quality in RAG applications by accessing and pulling data from SQL tables, drawing insights from complex charts and images, and intelligently grouping similar sentences.
chat-with-your-data-solution-accelerator
Chat with your data using OpenAI and AI Search. This solution accelerator uses an Azure OpenAI GPT model and an Azure AI Search index generated from your data, which is integrated into a web application to provide a natural language interface, including speech-to-text functionality, for search queries. Users can drag and drop files, point to storage, and take care of technical setup to transform documents. There is a web app that users can create in their own subscription with security and authentication.
aihub
AI Hub is a comprehensive solution that leverages artificial intelligence and cloud computing to provide functionalities such as document search and retrieval, call center analytics, image analysis, brand reputation analysis, form analysis, document comparison, and content safety moderation. It integrates various Azure services like Cognitive Search, ChatGPT, Azure Vision Services, and Azure Document Intelligence to offer scalable, extensible, and secure AI-powered capabilities for different use cases and scenarios.
PythonDataScienceFullThrottle
PythonDataScienceFullThrottle is a comprehensive repository containing various Python scripts, libraries, and tools for data science enthusiasts. It includes a wide range of functionalities such as data preprocessing, visualization, machine learning algorithms, and statistical analysis. The repository aims to provide a one-stop solution for individuals looking to dive deep into the world of data science using Python.
OpenAIWorkshop
Azure OpenAI Service provides REST API access to OpenAI's powerful language models including GPT-3, Codex and Embeddings. Users can easily adapt models for content generation, summarization, semantic search, and natural language to code translation. The workshop covers basics, prompt engineering, common NLP tasks, generative tasks, conversational dialog, and learning methods. It guides users to build applications with PowerApp, query SQL data, create data pipelines, and work with proprietary datasets. Target audience includes Power Users, Software Engineers, Data Scientists, and AI architects and Managers.

kdbai-samples
KDB.AI is a time-based vector database that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. It supports multiple index types, distance metrics, top-N and metadata filtered retrieval, as well as Python and REST interfaces. The repository contains samples demonstrating various use-cases such as temporal similarity search, document search, image search, recommendation systems, sentiment analysis, and more. KDB.AI integrates with platforms like ChatGPT, Langchain, and LlamaIndex. The setup steps require Unix terminal, Python 3.8+, and pip installed. Users can install necessary Python packages and run Jupyter notebooks to interact with the samples.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.
AutoGroq
AutoGroq is a revolutionary tool that dynamically generates tailored teams of AI agents based on project requirements, eliminating manual configuration. It enables users to effortlessly tackle questions, problems, and projects by creating expert agents, workflows, and skillsets with ease and efficiency. With features like natural conversation flow, code snippet extraction, and support for multiple language models, AutoGroq offers a seamless and intuitive AI assistant experience for developers and users.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.
data-formulator
Data Formulator is an AI-powered tool developed by Microsoft Research to help data analysts create rich visualizations iteratively. It combines user interface interactions with natural language inputs to simplify the process of describing chart designs while delegating data transformation to AI. Users can utilize features like blended UI and NL inputs, data threads for history navigation, and code inspection to create impressive visualizations. The tool supports local installation for customization and Codespaces for quick setup. Developers can build new data analysis tools on top of Data Formulator, and research papers are available for further reading.

xef
xef.ai is a one-stop library designed to bring the power of modern AI to applications and services. It offers integration with Large Language Models (LLM), image generation, and other AI services. The library is packaged in two layers: core libraries for basic AI services integration and integrations with other libraries. xef.ai aims to simplify the transition to modern AI for developers by providing an idiomatic interface, currently supporting Kotlin. Inspired by LangChain and Hugging Face, xef.ai may transmit source code and user input data to third-party services, so users should review privacy policies and take precautions. Libraries are available in Maven Central under the `com.xebia` group, with `xef-core` as the core library. Developers can add these libraries to their projects and explore examples to understand usage.
TagUI
TagUI is an open-source RPA tool that allows users to automate repetitive tasks on their computer, including tasks on websites, desktop apps, and the command line. It supports multiple languages and offers features like interacting with identifiers, automating data collection, moving data between TagUI and Excel, and sending Telegram notifications. Users can create RPA robots using MS Office Plug-ins or text editors, run TagUI on the cloud, and integrate with other RPA tools. TagUI prioritizes enterprise security by running on users' computers and not storing data. It offers detailed logs, enterprise installation guides, and support for centralised reporting.

NaLLM
The NaLLM project repository explores the synergies between Neo4j and Large Language Models (LLMs) through three primary use cases: Natural Language Interface to a Knowledge Graph, Creating a Knowledge Graph from Unstructured Data, and Generating a Report using static and LLM data. The repository contains backend and frontend code organized for easy navigation. It includes blog posts, a demo database, instructions for running demos, and guidelines for contributing. The project aims to showcase the potential of Neo4j and LLMs in various applications.
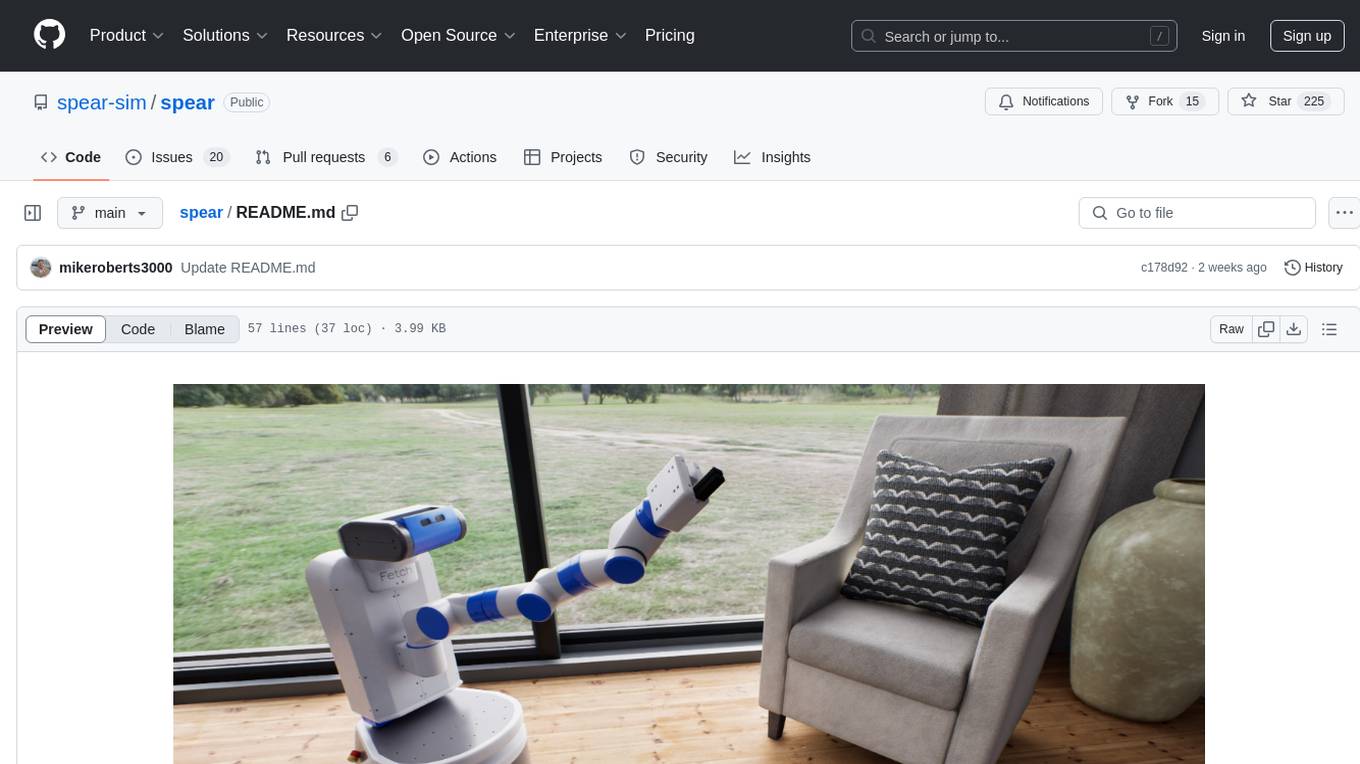
spear
SPEAR is a Simulator for Photorealistic Embodied AI Research that addresses limitations in existing simulators by offering 300 unique virtual indoor environments with detailed geometry, photorealistic materials, and unique floor plans. It provides an OpenAI Gym interface for interaction via Python, released under an MIT License. The simulator was developed with support from the Intelligent Systems Lab at Intel and Kujiale.
Build-your-own-AI-Assistant-Solution-Accelerator
Build-your-own-AI-Assistant-Solution-Accelerator is a pre-release and preview solution that helps users create their own AI assistants. It leverages Azure Open AI Service, Azure AI Search, and Microsoft Fabric to identify, summarize, and categorize unstructured information. Users can easily find relevant articles and grants, generate grant applications, and export them as PDF or Word documents. The solution accelerator provides reusable architecture and code snippets for building AI assistants with enterprise data. It is designed for researchers looking to explore flu vaccine studies and grants to accelerate grant proposal submissions.
For similar tasks
gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.
starter-applets
This repository contains the source code for Google AI Studio's starter apps — a collection of small apps that demonstrate how Gemini can be used to create interactive experiences. These apps are built to run inside AI Studio, but the versions included here can run standalone using the Gemini API. The apps cover spatial understanding, video analysis, and map exploration, showcasing Gemini's capabilities in these areas. Developers can use these starter applets to kickstart their projects and learn how to leverage Gemini for spatial reasoning and interactive experiences.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
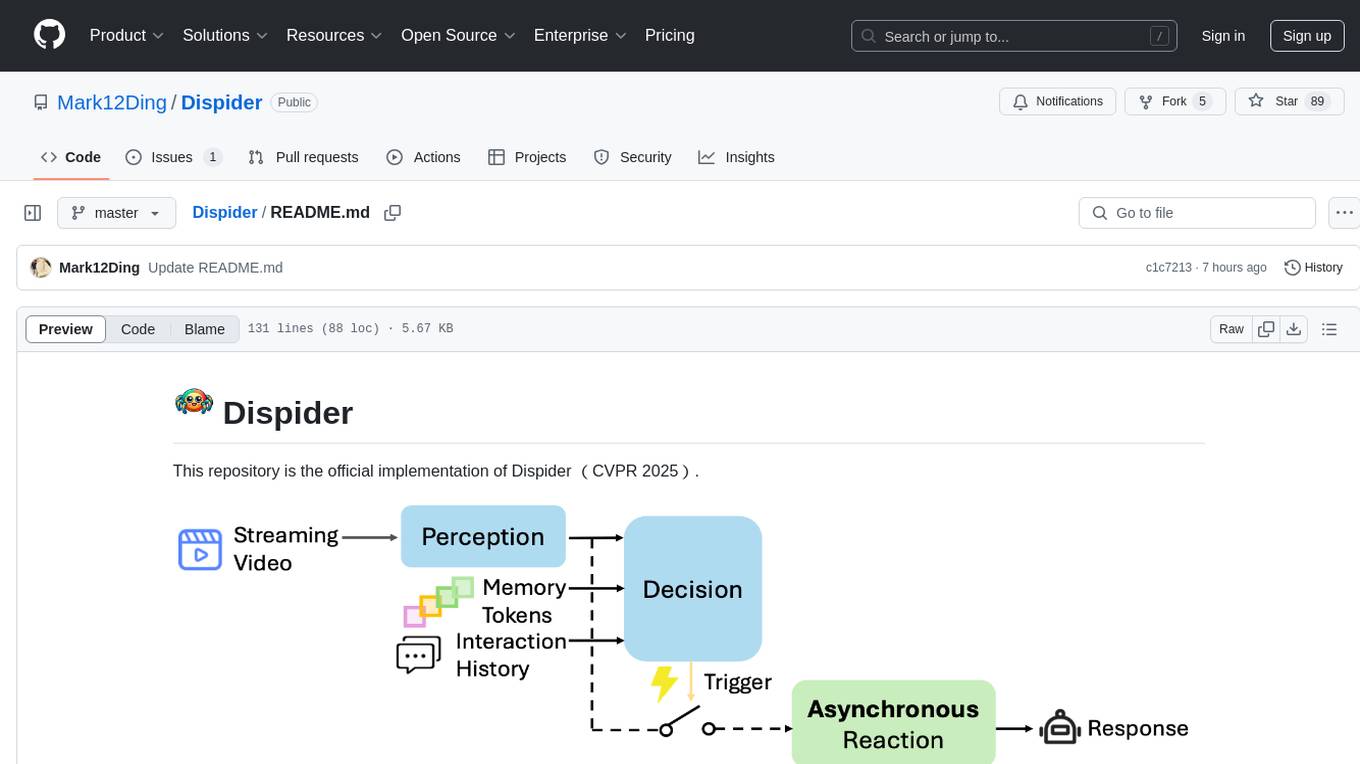
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.
spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.