
ControlLLM
ControlLLM: Augment Language Models with Tools by Searching on Graphs
Stars: 174

ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.
README:
ControlLLM: Augmenting Large Language Models with Tools by Searching on Graphs
[Paper] [Project Page] [Demo] [🤗 Space]
We present ControlLLM, a novel framework that enables large language models (LLMs) to utilize multi-modal tools for solving complex real-world tasks. Despite the remarkable performance of LLMs, they still struggle with tool invocation due to ambiguous user prompts, inaccurate tool selection and parameterization, and inefficient tool scheduling. To overcome these challenges, our framework comprises three key components: (1) a $\textit{task decomposer}$ that breaks down a complex task into clear subtasks with well-defined inputs and outputs; (2) a $\textit{Thoughts-on-Graph (ToG) paradigm}$ that searches the optimal solution path on a pre-built tool graph, which specifies the parameter and dependency relations among different tools; and (3) an $\textit{execution engine with a rich toolbox}$ that interprets the solution path and runs the tools efficiently on different computational devices. We evaluate our framework on diverse tasks involving image, audio, and video processing, demonstrating its superior accuracy, efficiency, and versatility compared to existing methods.
https://github.com/OpenGVLab/ControlLLM/assets/13723743/cf72861e-0e7b-4c15-89ee-7fa1d838d00f
- Image Perception
- Image Editing
- Image Generation
- Video Perception
- Video Editing
- Video Generation
- Audio Perception
- Audio Generation
- Multi-Solution
- Pointing Inputs
- Resource Type Awareness
- ✅ (🔥 New) Rlease online demo and 🤗Hugging Face space.
- ✅ (🔥 New) Support PixArt-alpha, a state-of-the-art method for Text-to-Image synthesis.
- Linux
- Python 3.10+
- PyTorch 2.0+
- CUDA 11.8+
Execute the following command in the root directory:
git clone https://github.com/OpenGVLab/ControlLLM.git
cd controlllmSetup environment:
conda create -n cllm python=3.10
conda activate cllm
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidiaInstall LLaVA:
pip install git+https://github.com/haotian-liu/LLaVA.gitThen install other dependencies:
pip install -r requirements.txt
pip install -e .Please put your personal OpenAI Key and Weather Key into the corresponding environment variables.
😬 Launch all in one endpoint:
# openai key
export OPENAI_API_KEY="..."
# openai base
export OPENAI_BASE_URL="..."
# weather api key
export WEATHER_API_KEY="..."
# resource dir
export SERVER_ROOT="./server_resources"
python -m cllm.services.launch --port 10056 --host 0.0.0.0Take image generation as an example, we first launch the service.
python -m cllm.services.image_generation.launch --port 10011 --host 0.0.0.0
Then, we can call the services via python api:
from cllm.services.image_generation.api import *
setup(port=10011)
text2image('A horse')export OPENAI_BASE_URL="..."
export OPENAI_API_KEY="..."
python -m cllm.services.tog.launch --port 10052 --host 0.0.0.0Use openssl to generate the certificate:
mkdir certificate
openssl req -x509 -newkey rsa:4096 -keyout certificate/key.pem -out certificate/cert.pem -sha256 -days 365 -nodesLast, you can launch gradio demo in your server:
export TOG_PORT=10052
export CLLM_SERVICES_PORT=10056
export CLIENT_ROOT="./client_resources"
export GRADIO_TEMP_DIR="$HOME/.tmp"
export OPENAI_BASE_URL="..."
export OPENAI_API_KEY="..."
python -m cllm.app.gradio --controller "cllm.agents.tog.Controller" --server-port 10003 --httpsAlternatively, you can set above variables in run.sh and launch all services by running:
bash ./run.shThis project is released under the Apache 2.0 license.
If you find this project useful in your research, please cite our paper:
@article{2023controlllm,
title={ControlLLM: Augment Language Models with Tools by Searching on Graphs},
author={Liu, Zhaoyang and Lai, Zeqiang and Gao, Zhangwei and Cui, Erfei and Li, Zhiheng and Zhu, Xizhou and Lu, Lewei and Chen, Qifeng and Qiao, Yu and Dai, Jifeng and Wang, Wenhai},
journal={arXiv preprint arXiv:2305.10601},
year={2023}
}- Thanks to the open source of the following projects: Hugging Face LangChain SAM Stable Diffusion ControlNet InstructPix2Pix EasyOCR ImageBind PixArt-alpha LLaVA Modelscope AudioCraft Whisper Llama 2 LLaMA
If you want to join our WeChat group, please scan the following QR Code to add our assistant as a Wechat friend:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ControlLLM
Similar Open Source Tools
ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.
deer-flow
DeerFlow is a community-driven Deep Research framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It supports FaaS deployment and one-click deployment based on Volcengine. The framework includes core capabilities like LLM integration, search and retrieval, RAG integration, MCP seamless integration, human collaboration, report post-editing, and content creation. The architecture is based on a modular multi-agent system with components like Coordinator, Planner, Research Team, and Text-to-Speech integration. DeerFlow also supports interactive mode, human-in-the-loop mechanism, and command-line arguments for customization.
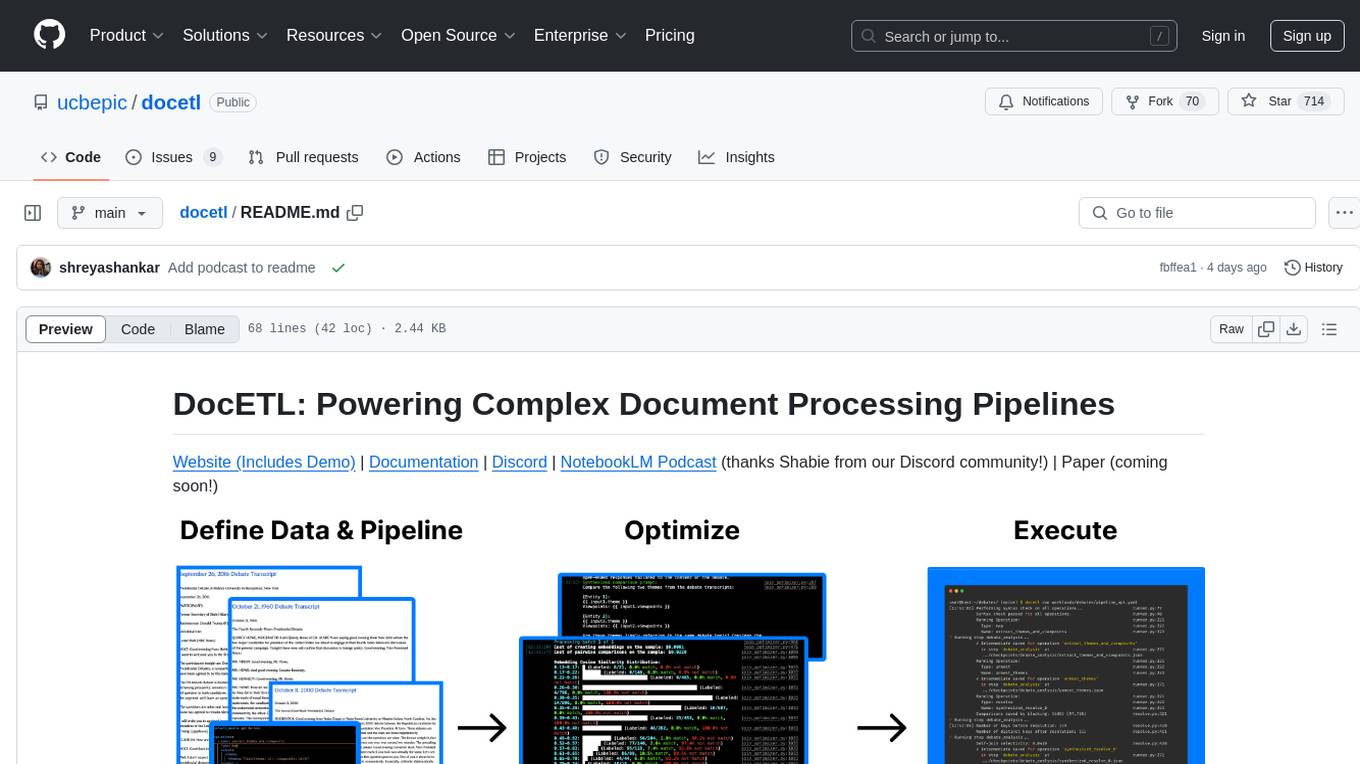
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
single-file-agents
Single File Agents (SFA) is a collection of powerful single-file agents built on top of uv, a modern Python package installer and resolver. These agents aim to perform specific tasks efficiently, demonstrating precise prompt engineering and GenAI patterns. The repository contains agents built across major GenAI providers like Gemini, OpenAI, and Anthropic. Each agent is self-contained, minimal, and built on modern Python for fast and reliable dependency management. Users can run these scripts from their server or directly from a gist. The agents are patternful, emphasizing the importance of setting up effective prompts, tools, and processes for reusability.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
forecastbench
ForecastBench is a dynamic benchmark tool for evaluating LLM forecasting accuracy with human comparison groups. It provides a contamination-free environment and serves as a proxy for general intelligence. The tool offers leaderboards and datasets updated nightly, along with instructions for submitting models. Users can explore detailed information on the wiki and cite the tool using the provided BibTeX citation. Developers can set up the tool locally, run GCP Cloud Functions, and contribute to the project by following specific guidelines.
CoML
CoML (formerly MLCopilot) is an interactive coding assistant for data scientists and machine learning developers, empowered on large language models. It offers an out-of-the-box interactive natural language programming interface for data mining and machine learning tasks, integration with Jupyter lab and Jupyter notebook, and a built-in large knowledge base of machine learning to enhance the ability to solve complex tasks. The tool is designed to assist users in coding tasks related to data analysis and machine learning using natural language commands within Jupyter environments.
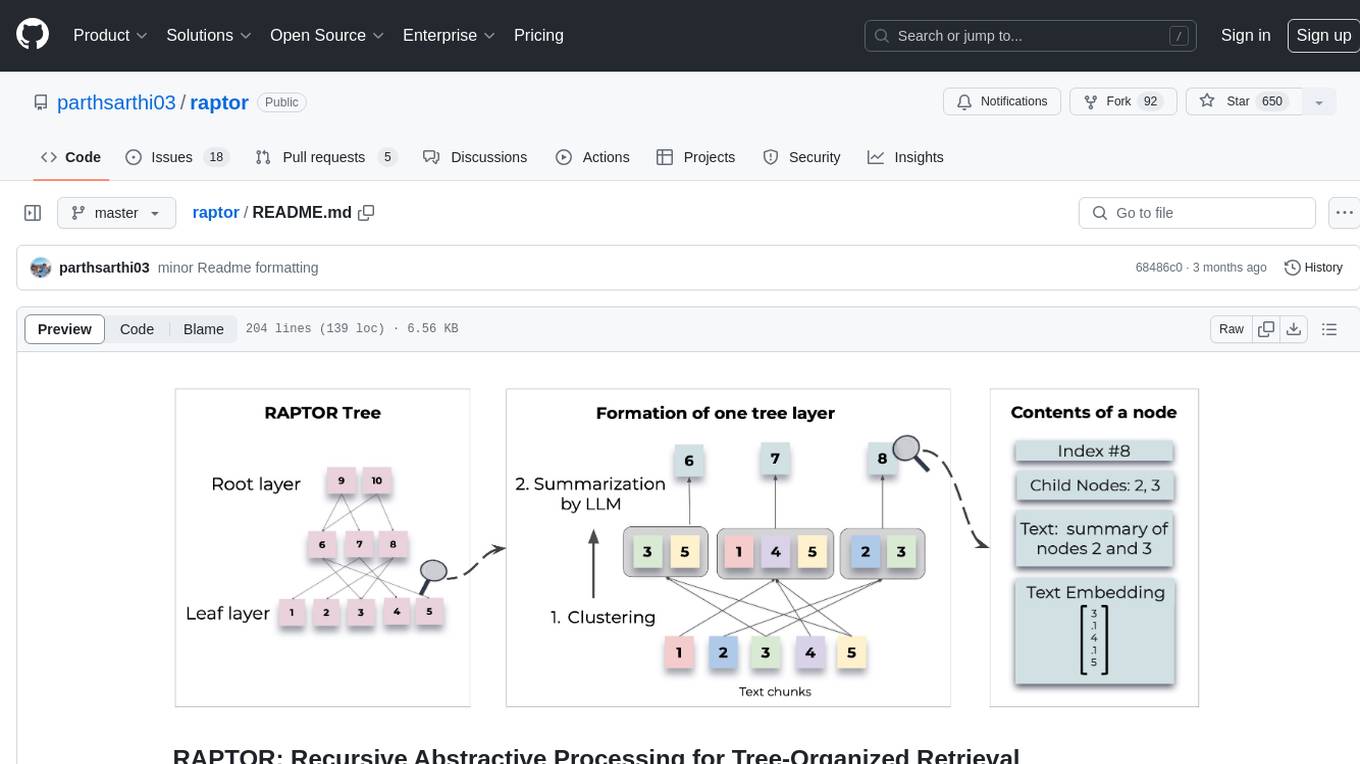
raptor
RAPTOR introduces a novel approach to retrieval-augmented language models by constructing a recursive tree structure from documents. This allows for more efficient and context-aware information retrieval across large texts, addressing common limitations in traditional language models. Users can add documents to the tree, answer questions based on indexed documents, save and load the tree, and extend RAPTOR with custom summarization, question-answering, and embedding models. The tool is designed to be flexible and customizable for various NLP tasks.
oxy
Oxy is an open-source framework for building comprehensive agentic analytics systems grounded in deterministic execution principles. Written in Rust and declarative by design, Oxy provides the foundational components needed to transform AI-driven data analysis into reliable, production-ready systems through structured primitives, semantic understanding, and predictable execution.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.

open-deep-research
Open Deep Research is an open-source tool designed to generate AI-powered reports from web search results efficiently. It combines Bing Search API for search results retrieval, JinaAI for content extraction, and customizable report generation. Users can customize settings, export reports in multiple formats, and benefit from rate limiting for stability. The tool aims to streamline research and report creation in a user-friendly platform.

log10
Log10 is a one-line Python integration to manage your LLM data. It helps you log both closed and open-source LLM calls, compare and identify the best models and prompts, store feedback for fine-tuning, collect performance metrics such as latency and usage, and perform analytics and monitor compliance for LLM powered applications. Log10 offers various integration methods, including a python LLM library wrapper, the Log10 LLM abstraction, and callbacks, to facilitate its use in both existing production environments and new projects. Pick the one that works best for you. Log10 also provides a copilot that can help you with suggestions on how to optimize your prompt, and a feedback feature that allows you to add feedback to your completions. Additionally, Log10 provides prompt provenance, session tracking and call stack functionality to help debug prompt chains. With Log10, you can use your data and feedback from users to fine-tune custom models with RLHF, and build and deploy more reliable, accurate and efficient self-hosted models. Log10 also supports collaboration, allowing you to create flexible groups to share and collaborate over all of the above features.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.
For similar tasks

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.
ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.
starter-applets
This repository contains the source code for Google AI Studio's starter apps — a collection of small apps that demonstrate how Gemini can be used to create interactive experiences. These apps are built to run inside AI Studio, but the versions included here can run standalone using the Gemini API. The apps cover spatial understanding, video analysis, and map exploration, showcasing Gemini's capabilities in these areas. Developers can use these starter applets to kickstart their projects and learn how to leverage Gemini for spatial reasoning and interactive experiences.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
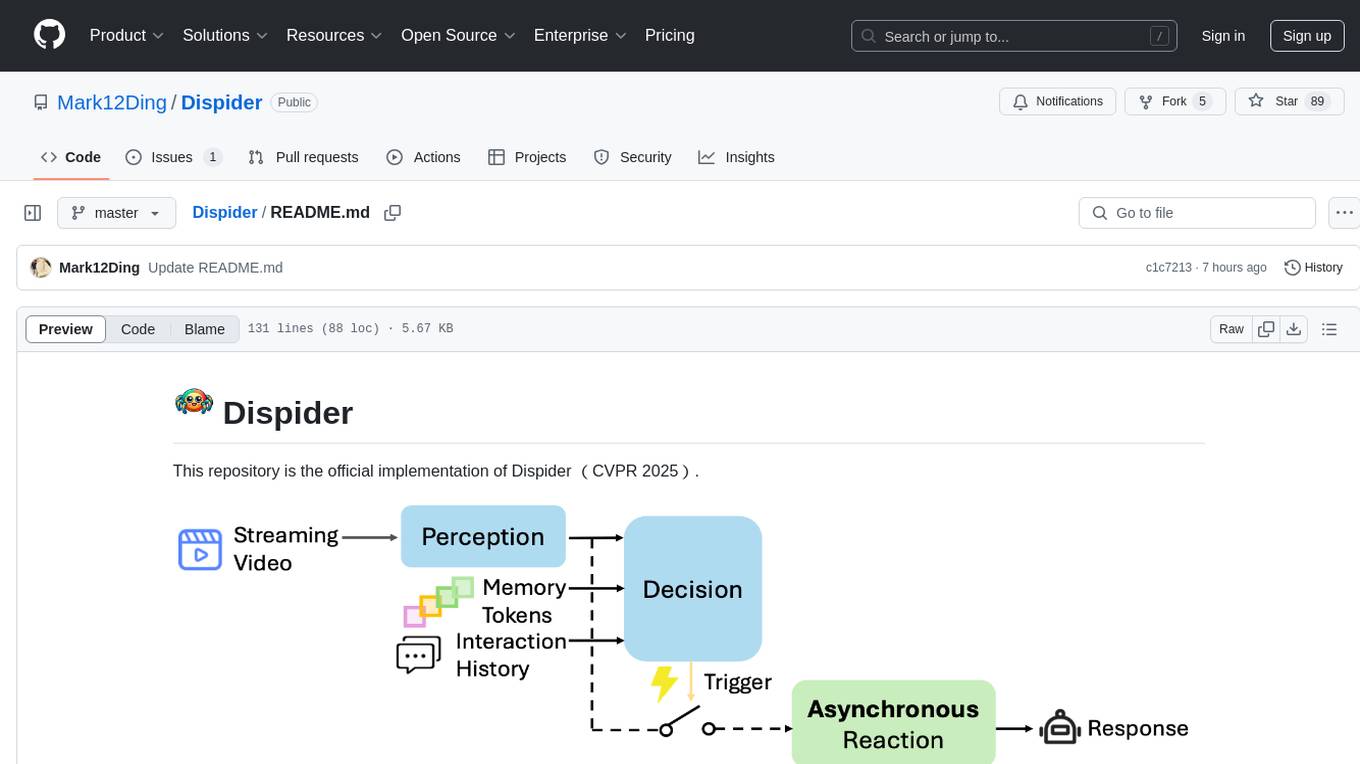
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.