
llm-consortium
llm-consortium orchestrates mulitple LLMs, iteratively refines & achieves consensus.
Stars: 167
LLM Consortium is a plugin for the `llm` package that implements a model consortium system with iterative refinement and response synthesis. It orchestrates multiple learned language models to collaboratively solve complex problems through structured dialogue, evaluation, and arbitration. The tool supports multi-model orchestration, iterative refinement, advanced arbitration, database logging, configurable parameters, hundreds of models, and the ability to save and load consortium configurations.
README:
Based on Karpathy's observation:
"I find that recently I end up using all of the models and all the time. One aspect is the curiosity of who gets what, but the other is that for a lot of problems they have this "NP Complete" nature to them, where coming up with a solution is significantly harder than verifying a candidate solution. So your best performance will come from just asking all the models, and then getting them to come to a consensus."
A plugin for the llm package that implements a model consortium system with iterative refinement and response synthesis. This plugin orchestrates multiple learned language models to collaboratively solve complex problems through structured dialogue, evaluation and arbitration.
The following Mermaid diagram illustrates the core algorithm flow of the LLM Karpathy Consortium:
flowchart TD
A[Start] --> B[Get Model Responses]
B --> C[Synthesize Responses]
C --> D{Check Confidence}
D -- Confidence >= Threshold --> E[Return Final Result]
D -- Confidence < Threshold --> F{Max Iterations Reached?}
F -- No --> G[Prepare Next Iteration]
G --> B
F -- Yes --> E- Multi-Model Orchestration: Coordinate responses from multiple LLMs simultaneously
- Iterative Refinement: Automatically refine responses through multiple rounds until confidence threshold is met
- Advanced Arbitration: Uses a designated arbiter model to synthesize and evaluate responses
- Database Logging: Built-in SQLite logging of all interactions and responses
- Configurable Parameters: Adjustable confidence thresholds, iteration limits, and model selection
- Hundreds of Models: Supports all models available via llm plugins
- Save and Load Consortium Configurations: Save your favorite model configurations to reuse later.
-
Enhanced Model Selection: Added support for the latest models including
claude-3-5-sonnet-20240620anddeepseek-chat. - Improved Confidence Calculation: Refined the confidence threshold algorithm for better accuracy.
- Extended Logging: Added more detailed logging options for debugging and analysis.
- User Feedback Integration: Implemented a feedback loop to incorporate user input into the refinement process.
- Performance Optimization: Improved the speed and efficiency of the orchestration process.
First, get https://github.com/simonw/llm
uv:
uv tool install llmpipx:
pipx install llmllm install llm-consortiumThe consortium command now defaults to the run subcommand, allowing for more concise usage.
Basic usage:
llm consortium "What are the key considerations for AGI safety?"This will:
- Send the prompt to multiple models in parallel.
- Gather responses including reasoning and confidence.
- Use an arbiter model to synthesize the responses and identify key points of agreement/disagreement.
- The arbiter model evaluates confidence.
- If confidence is below the threshold and the maximum iterations have not been reached:
- Refinement areas are identified.
- A new iteration begins with an enhanced prompt.
- The process continues until the confidence threshold is met or the maximum iterations have been reached.
-
-m, --models: Models to include in consortium (can specify multiple). Defaults toclaude-3-opus-20240229,claude-3-sonnet-20240229,gpt-4, andgemini-pro. -
--arbiter: Model to use as arbiter (default:claude-3-opus-20240229). -
--confidence-threshold: Minimum confidence threshold (default:0.8). -
--max-iterations: Maximum number of iteration rounds (default:3). -
--system: Custom system prompt. -
--output: Save full results to a JSON file. -
--stdin/--no-stdin: Read additional input from stdin and append to prompt (default: enabled). -
--raw: Output raw response from arbiter model and individual model responses (default: enabled).
Advanced usage with options:
llm consortium "Your complex query" \
--models claude-3-opus-20240229 \
--models claude-3-sonnet-20240229 \
--models gpt-4 \
--models gemini-pro \
--arbiter claude-3-opus-20240229 \
--confidence-threshold 0.8 \
--max-iterations 3 \
--output results.jsonThe consortium command also provides subcommands for managing configurations:
llm consortium save my-consortium \
--models claude-3-opus-20240229 \
--models gpt-4 \
--arbiter claude-3-opus-20240229 \
--confidence-threshold 0.9 \
--max-iterations 5This command saves the current configuration as a model with the name my-consortium.
llm -m my-consortium "What are the key considerations for AGI safety?"llm consortium listThis command displays all available saved consortium configurations.
llm consortium show my-consortiumThis command shows the details of a saved consortium named my-consortium.
llm consortium remove my-consortiumThis command removes the saved consortium named my-consortium.
The plugin uses a structured XML format for responses, including the synthesis, analysis, confidence and, if present, dissenting views.
<synthesis>
[Synthesized response to the query]
</synthesis>
<confidence>
[Confidence level from 0 to 1]
</confidence>
<analysis>
[Analysis of the model responses, synthesis reasoning, and identification of key points of agreement or disagreement]
</analysis>
<dissent>
[Notable dissenting views and refinement areas]
</dissent>All interactions are automatically logged to a SQLite database located in the LLM user directory.
from llm_consortium import ConsortiumOrchestrator
orchestrator = ConsortiumOrchestrator(
models=["claude-3-opus-20240229", "gpt-4", "gemini-pro"],
confidence_threshold=0.8,
max_iterations=3,
arbiter="claude-3-opus-20240229"
)
result = await orchestrator.orchestrate("Your prompt")
print(f"Synthesized Response: {result['synthesis']['synthesis']}")
print(f"Confidence: {result['synthesis']['confidence']}")
print(f"Analysis: {result['synthesis']['analysis']}")MIT License
Developed as part of the LLM ecosystem, inspired by Andrej Karpathy's work on model collaboration and iteration.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-consortium
Similar Open Source Tools
llm-consortium
LLM Consortium is a plugin for the `llm` package that implements a model consortium system with iterative refinement and response synthesis. It orchestrates multiple learned language models to collaboratively solve complex problems through structured dialogue, evaluation, and arbitration. The tool supports multi-model orchestration, iterative refinement, advanced arbitration, database logging, configurable parameters, hundreds of models, and the ability to save and load consortium configurations.
evolving-agents
A toolkit for agent autonomy, evolution, and governance enabling agents to learn from experience, collaborate, communicate, and build new tools within governance guardrails. It focuses on autonomous evolution, agent self-discovery, governance firmware, self-building systems, and agent-centric architecture. The toolkit leverages existing frameworks to enable agent autonomy and self-governance, moving towards truly autonomous AI systems.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.

artkit
ARTKIT is a Python framework developed by BCG X for automating prompt-based testing and evaluation of Gen AI applications. It allows users to develop automated end-to-end testing and evaluation pipelines for Gen AI systems, supporting multi-turn conversations and various testing scenarios like Q&A accuracy, brand values, equitability, safety, and security. The framework provides a simple API, asynchronous processing, caching, model agnostic support, end-to-end pipelines, multi-turn conversations, robust data flows, and visualizations. ARTKIT is designed for customization by data scientists and engineers to enhance human-in-the-loop testing and evaluation, emphasizing the importance of tailored testing for each Gen AI use case.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.

cortex
Cortex is a tool that simplifies and accelerates the process of creating applications utilizing modern AI models like chatGPT and GPT-4. It provides a structured interface (GraphQL or REST) to a prompt execution environment, enabling complex augmented prompting and abstracting away model connection complexities like input chunking, rate limiting, output formatting, caching, and error handling. Cortex offers a solution to challenges faced when using AI models, providing a simple package for interacting with NL AI models.
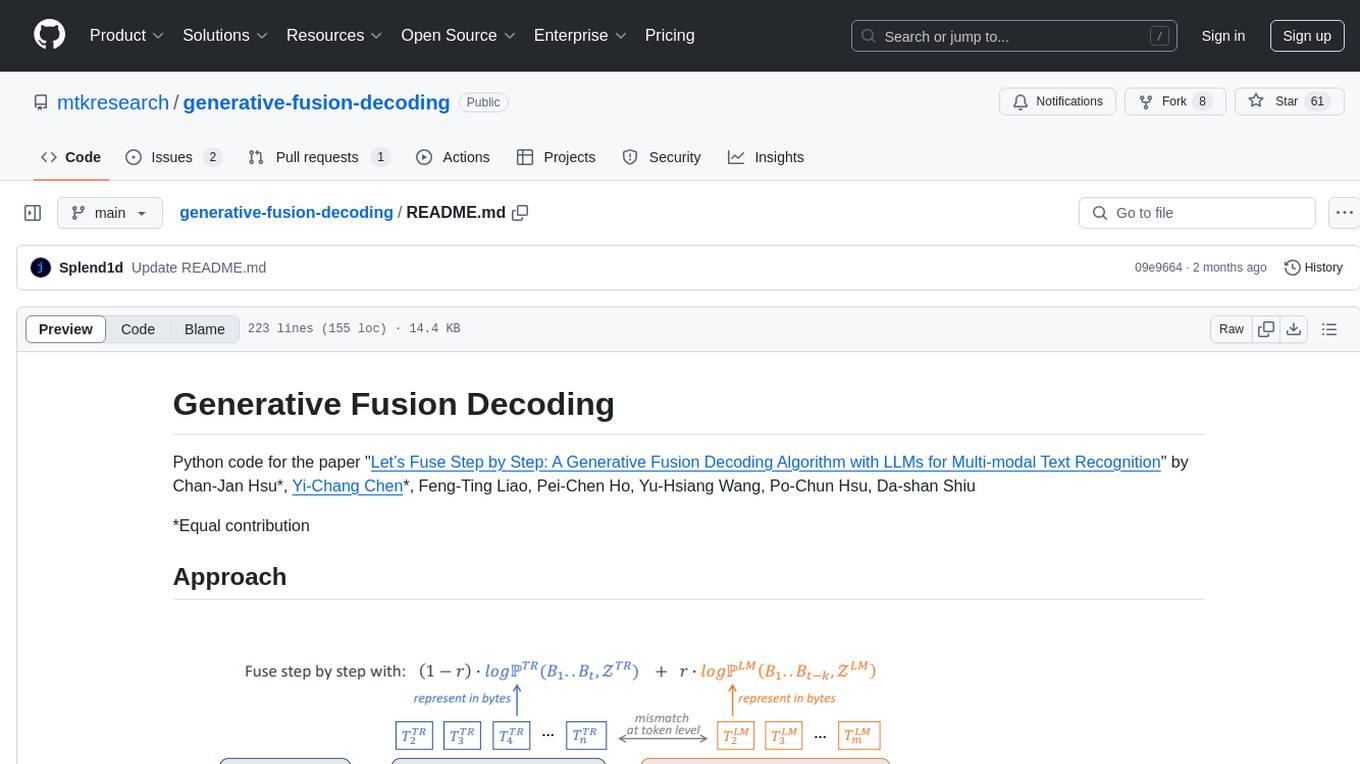
generative-fusion-decoding
Generative Fusion Decoding (GFD) is a novel shallow fusion framework that integrates Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). GFD operates across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. It simplifies the complexity of aligning different model sample spaces, allows LLMs to correct errors in tandem with the recognition model, increases robustness in long-form speech recognition, and enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. GFD significantly improves performance in ASR and OCR tasks, offering a unified solution for leveraging existing pre-trained models through step-by-step fusion.

mentals-ai
Mentals AI is a tool designed for creating and operating agents that feature loops, memory, and various tools, all through straightforward markdown syntax. This tool enables you to concentrate solely on the agent’s logic, eliminating the necessity to compose underlying code in Python or any other language. It redefines the foundational frameworks for future AI applications by allowing the creation of agents with recursive decision-making processes, integration of reasoning frameworks, and control flow expressed in natural language. Key concepts include instructions with prompts and references, working memory for context, short-term memory for storing intermediate results, and control flow from strings to algorithms. The tool provides a set of native tools for message output, user input, file handling, Python interpreter, Bash commands, and short-term memory. The roadmap includes features like a web UI, vector database tools, agent's experience, and tools for image generation and browsing. The idea behind Mentals AI originated from studies on psychoanalysis executive functions and aims to integrate 'System 1' (cognitive executor) with 'System 2' (central executive) to create more sophisticated agents.

datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.
mergekit
Mergekit is a toolkit for merging pre-trained language models. It uses an out-of-core approach to perform unreasonably elaborate merges in resource-constrained situations. Merges can be run entirely on CPU or accelerated with as little as 8 GB of VRAM. Many merging algorithms are supported, with more coming as they catch my attention.
ice-score
ICE-Score is a tool designed to instruct large language models to evaluate code. It provides a minimum viable product (MVP) for evaluating generated code snippets using inputs such as problem, output, task, aspect, and model. Users can also evaluate with reference code and enable zero-shot chain-of-thought evaluation. The tool is built on codegen-metrics and code-bert-score repositories and includes datasets like CoNaLa and HumanEval. ICE-Score has been accepted to EACL 2024.
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.
For similar tasks

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

RAGElo
RAGElo is a streamlined toolkit for evaluating Retrieval Augmented Generation (RAG)-powered Large Language Models (LLMs) question answering agents using the Elo rating system. It simplifies the process of comparing different outputs from multiple prompt and pipeline variations to a 'gold standard' by allowing a powerful LLM to judge between pairs of answers and questions. RAGElo conducts tournament-style Elo ranking of LLM outputs, providing insights into the effectiveness of different settings.
llm-consortium
LLM Consortium is a plugin for the `llm` package that implements a model consortium system with iterative refinement and response synthesis. It orchestrates multiple learned language models to collaboratively solve complex problems through structured dialogue, evaluation, and arbitration. The tool supports multi-model orchestration, iterative refinement, advanced arbitration, database logging, configurable parameters, hundreds of models, and the ability to save and load consortium configurations.
judges
The 'judges' repository is a small library designed for using and creating LLM-as-a-Judge evaluators. It offers a curated set of LLM evaluators in a low-friction format for various use cases, backed by research. Users can use these evaluators off-the-shelf or as inspiration for building custom LLM evaluators. The library provides two types of judges: Classifiers that return boolean values and Graders that return scores on a numerical or Likert scale. Users can combine multiple judges using the 'Jury' object and evaluate input-output pairs with the '.judge()' method. Additionally, the repository includes detailed instructions on picking a model, sending data to an LLM, using classifiers, combining judges, and creating custom LLM judges with 'AutoJudge'.
mcp-rubber-duck
MCP Rubber Duck is a Model Context Protocol server that acts as a bridge to query multiple LLMs, including OpenAI-compatible HTTP APIs and CLI coding agents. Users can explain their problems to various AI 'ducks' to get different perspectives. The tool offers features like universal OpenAI compatibility, CLI agent support, conversation management, multi-duck querying, consensus voting, LLM-as-Judge evaluation, structured debates, health monitoring, usage tracking, and more. It supports various HTTP providers like OpenAI, Google Gemini, Anthropic, Groq, Together AI, Perplexity, and CLI providers like Claude Code, Codex, Gemini CLI, Grok, Aider, and custom agents. Users can install the tool globally, configure it using environment variables, and access interactive UIs for comparing ducks, voting, debating, and usage statistics. The tool provides multiple tools for asking questions, chatting, clearing conversations, listing ducks, comparing responses, voting, judging, iterating, debating, and more. It also offers prompt templates for different analysis purposes and extensive documentation for setup, configuration, tools, prompts, CLI providers, MCP Bridge, guardrails, Docker deployment, troubleshooting, contributing, license, acknowledgments, changelog, registry & directory, and support.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.