
llm-compressor
Transformers-compatible library for applying various compression algorithms to LLMs for optimized deployment with vLLM
Stars: 2754
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.
README:

llmcompressor is an easy-to-use library for optimizing models for deployment with vllm, including:
- Comprehensive set of quantization algorithms for weight-only and activation quantization
- Seamless integration with Hugging Face models and repositories
-
safetensors-based file format compatible withvllm - Large model support via
accelerate
✨ Read the announcement blog here! ✨
💬 Join us on the vLLM Community Slack and share your questions, thoughts, or ideas in:
#sig-quantization#llm-compressor
Big updates have landed in LLM Compressor! To get a more in-depth look, check out the LLM Compressor overview.
Some of the exciting new features include:
-
Batched Calibration Support: LLM Compressor now supports calibration with batch sizes > 1. A new
batch_sizeargument has been added to thedataset_argumentsenabling the option to improve quantization speed. Defaultbatch_sizeis currently set to 1 -
New Model-Free PTQ Pathway: A new model-free PTQ pathway has been added to LLM Compressor, called
model_free_ptq. This pathway allows you to quantize your model without the requirement of Hugging Face model definition and is especially useful in cases whereoneshotmay fail. This pathway is currently supported for data-free pathways only i.e FP8 quantization and was leveraged to quantize the Mistral Large 3 model. Additional examples have been added illustrating how LLM Compressor can be used for Kimi K2 -
Extended KV Cache and Attention Quantization Support: LLM Compressor now supports attention quantization. KV Cache quantization, which previously only supported per-tensor scales, has been extended to support any quantization scheme including a new
per-headquantization scheme. Support for these checkpoints is on-going in vLLM and scripts to get started have been added to the experimental folder -
Generalized AWQ Support: The AWQModifier has been updated to support quantization schemes beyond W4A16 (e.g W4AFp8). In particular, AWQ no longer constrains that the quantization config needs to have the same settings for
group_size,symmetric, andnum_bitsfor each config_group -
AutoRound Quantization Support: Added
AutoRoundModifierfor quantization using AutoRound, an advanced post-training algorithm that optimizes rounding and clipping ranges through sign-gradient descent. This approach combines the efficiency of post-training quantization with the adaptability of parameter tuning, delivering robust compression for large language models while maintaining strong performance -
Experimental MXFP4 Support: Models can now be quantized using an
MXFP4pre-set scheme. Examples can be found under the experimental folder. This pathway is still experimental as support and validation with vLLM is still a WIP. - R3 Transform Support: LLM Compressor now supports applying transforms to attention in the style of SpinQuant's R3 rotation. Note: this feature is currently not yet supported in vLLM. An example applying R3 can be found in the experimental folder
- Activation Quantization: W8A8 (int8 and fp8)
- Mixed Precision: W4A16, W8A16, NVFP4 (W4A4 and W4A16 support)
- 2:4 Semi-structured and Unstructured Sparsity
- Simple PTQ
- GPTQ
- AWQ
- SmoothQuant
- SparseGPT
- AutoRound
Please refer to compression_schemes.md for detailed information about available optimization schemes and their use cases.
pip install llmcompressorApplying quantization with llmcompressor:
- Activation quantization to
int8 - Activation quantization to
fp8 - Activation quantization to
fp4 - Activation quantization to
fp4using AutoRound - Activation quantization to
fp8and weight quantization toint4 - Weight only quantization to
fp4(NVFP4 format) - Weight only quantization to
fp4(MXFP4 format) - Weight only quantization to
int4using GPTQ - Weight only quantization to
int4using AWQ - Weight only quantization to
int4using AutoRound - KV Cache quantization to
fp8 - Attention quantization to
fp8(experimental) - Attention quantization to
nvfp4with SpinQuant (experimental) - Quantizing MoE LLMs
- Quantizing Vision-Language Models
- Quantizing Audio-Language Models
- Quantizing Models Non-uniformly
Deep dives into advanced usage of llmcompressor:
Let's quantize Qwen3-30B-A3B with FP8 weights and activations using the Round-to-Nearest algorithm.
Note that the model can be swapped for a local or remote HF-compatible checkpoint and the recipe may be changed to target different quantization algorithms or formats.
Quantization is applied by selecting an algorithm and calling the oneshot API.
from transformers import AutoModelForCausalLM, AutoTokenizer
from llmcompressor import oneshot
from llmcompressor.modifiers.quantization import QuantizationModifier
from llmcompressor.utils import dispatch_for_generation
MODEL_ID = "Qwen/Qwen3-30B-A3B"
# Load model.
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
# Configure the quantization algorithm and scheme.
# In this case, we:
# * quantize the weights to FP8 using RTN with block_size 128
# * quantize the activations dynamically to FP8 during inference
recipe = QuantizationModifier(
targets="Linear",
scheme="FP8_BLOCK",
ignore=["lm_head", "re:.*mlp.gate$"],
)
# Apply quantization.
oneshot(model=model, recipe=recipe)
# Confirm generations of the quantized model look sane.
print("========== SAMPLE GENERATION ==============")
dispatch_for_generation(model)
input_ids = tokenizer("Hello my name is", return_tensors="pt").input_ids.to(
model.device
)
output = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(output[0]))
print("==========================================")
# Save to disk in compressed-tensors format.
SAVE_DIR = MODEL_ID.split("/")[1] + "-FP8-BLOCK"
model.save_pretrained(SAVE_DIR)
tokenizer.save_pretrained(SAVE_DIR)The checkpoints created by llmcompressor can be loaded and run in vllm:
Install:
pip install vllmRun:
from vllm import LLM
model = LLM("Qwen/Qwen3-30B-A3B-FP8-BLOCK")
output = model.generate("My name is")- If you have any questions or requests open an issue and we will add an example or documentation.
- We appreciate contributions to the code, examples, integrations, and documentation as well as bug reports and feature requests! Learn how here.
If you find LLM Compressor useful in your research or projects, please consider citing it:
@software{llmcompressor2024,
title={{LLM Compressor}},
author={Red Hat AI and vLLM Project},
year={2024},
month={8},
url={https://github.com/vllm-project/llm-compressor},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-compressor
Similar Open Source Tools
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.
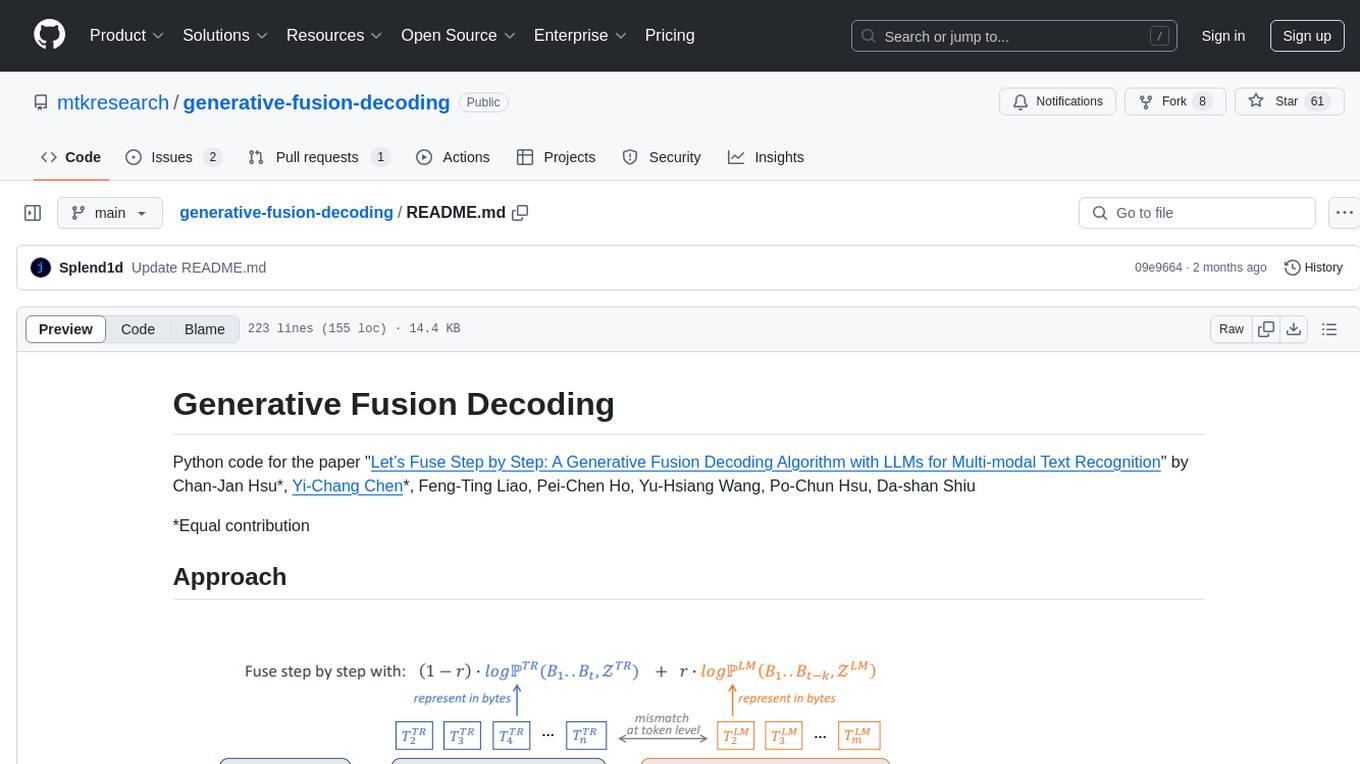
generative-fusion-decoding
Generative Fusion Decoding (GFD) is a novel shallow fusion framework that integrates Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). GFD operates across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. It simplifies the complexity of aligning different model sample spaces, allows LLMs to correct errors in tandem with the recognition model, increases robustness in long-form speech recognition, and enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. GFD significantly improves performance in ASR and OCR tasks, offering a unified solution for leveraging existing pre-trained models through step-by-step fusion.

py-llm-core
PyLLMCore is a light-weighted interface with Large Language Models with native support for llama.cpp, OpenAI API, and Azure deployments. It offers a Pythonic API that is simple to use, with structures provided by the standard library dataclasses module. The high-level API includes the assistants module for easy swapping between models. PyLLMCore supports various models including those compatible with llama.cpp, OpenAI, and Azure APIs. It covers use cases such as parsing, summarizing, question answering, hallucinations reduction, context size management, and tokenizing. The tool allows users to interact with language models for tasks like parsing text, summarizing content, answering questions, reducing hallucinations, managing context size, and tokenizing text.
distilabel
Distilabel is a framework for synthetic data and AI feedback for AI engineers that require high-quality outputs, full data ownership, and overall efficiency. It helps you synthesize data and provide AI feedback to improve the quality of your AI models. With Distilabel, you can: * **Synthesize data:** Generate synthetic data to train your AI models. This can help you to overcome the challenges of data scarcity and bias. * **Provide AI feedback:** Get feedback from AI models on your data. This can help you to identify errors and improve the quality of your data. * **Improve your AI output quality:** By using Distilabel to synthesize data and provide AI feedback, you can improve the quality of your AI models and get better results.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.
llm-consortium
LLM Consortium is a plugin for the `llm` package that implements a model consortium system with iterative refinement and response synthesis. It orchestrates multiple learned language models to collaboratively solve complex problems through structured dialogue, evaluation, and arbitration. The tool supports multi-model orchestration, iterative refinement, advanced arbitration, database logging, configurable parameters, hundreds of models, and the ability to save and load consortium configurations.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.
LLM-as-HH
LLM-as-HH is a codebase that accompanies the paper ReEvo: Large Language Models as Hyper-Heuristics with Reflective Evolution. It introduces Language Hyper-Heuristics (LHHs) that leverage LLMs for heuristic generation with minimal manual intervention and open-ended heuristic spaces. Reflective Evolution (ReEvo) is presented as a searching framework that emulates the reflective design approach of human experts while surpassing human capabilities with scalable LLM inference, Internet-scale domain knowledge, and powerful evolutionary search. The tool can improve various algorithms on problems like Traveling Salesman Problem, Capacitated Vehicle Routing Problem, Orienteering Problem, Multiple Knapsack Problems, Bin Packing Problem, and Decap Placement Problem in both black-box and white-box settings.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.
For similar tasks
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.
llmc
llmc is an off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance. It provides users with the ability to quantize LLMs, choose from various compression algorithms, export transformed models for further optimization, and directly infer compressed models with a shallow memory footprint. The tool supports a range of model types and quantization algorithms, with ongoing development to include pruning techniques. Users can design their configurations for quantization and evaluation, with documentation and examples planned for future updates. llmc is a valuable resource for researchers working on post-training quantization of large language models.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.