
humanoid-gym
Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer https://arxiv.org/abs/2404.05695
Stars: 388
Humanoid-Gym is a reinforcement learning framework designed for training locomotion skills for humanoid robots, focusing on zero-shot transfer from simulation to real-world environments. It integrates a sim-to-sim framework from Isaac Gym to Mujoco for verifying trained policies in different physical simulations. The codebase is verified with RobotEra's XBot-S and XBot-L humanoid robots. It offers comprehensive training guidelines, step-by-step configuration instructions, and execution scripts for easy deployment. The sim2sim support allows transferring trained policies to accurate simulated environments. The upcoming features include Denoising World Model Learning and Dexterous Hand Manipulation. Installation and usage guides are provided along with examples for training PPO policies and sim-to-sim transformations. The code structure includes environment and configuration files, with instructions on adding new environments. Troubleshooting tips are provided for common issues, along with a citation and acknowledgment section.
README:
This repository contains the code for our paper Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer by Xinyang Gu*, Yen-Jen Wang*, and Jianyu Chen.

Welcome to our Humanoid-Gym!
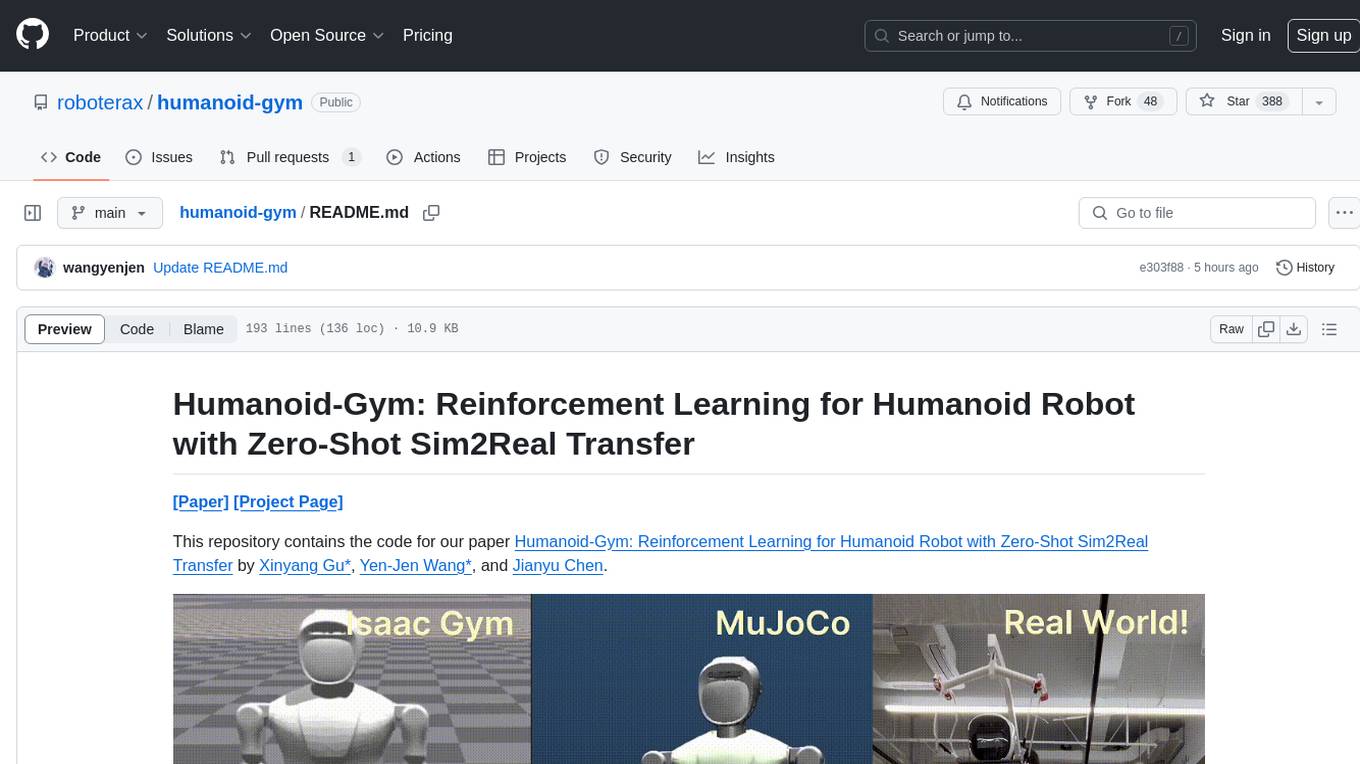
Humanoid-Gym is an easy-to-use reinforcement learning (RL) framework based on Nvidia Isaac Gym, designed to train locomotion skills for humanoid robots, emphasizing zero-shot transfer from simulation to the real-world environment. Humanoid-Gym also integrates a sim-to-sim framework from Isaac Gym to Mujoco that allows users to verify the trained policies in different physical simulations to ensure the robustness and generalization of the policies.
This codebase is verified by RobotEra's XBot-S (1.2 meter tall humanoid robot) and XBot-L (1.65 meter tall humanoid robot) in real-world environment with zero-shot sim-to-real transfer.
This repository offers comprehensive guidance and scripts for the training of humanoid robots. Humanoid-Gym features specialized rewards for humanoid robots, simplifying the difficulty of sim-to-real transfer. In this repository, we use RobotEra's XBot-L as a primary example. It can also be used for other robots with minimal adjustments. Our resources cover setup, configuration, and execution. Our goal is to fully prepare the robot for real-world locomotion by providing in-depth training and optimization.
- Comprehensive Training Guidelines: We offer thorough walkthroughs for each stage of the training process.
- Step-by-Step Configuration Instructions: Our guidance is clear and succinct, ensuring an efficient setup process.
- Execution Scripts for Easy Deployment: Utilize our pre-prepared scripts to streamline the training workflow.
We also share our sim2sim pipeline, which allows you to transfer trained policies to highly accurate and carefully designed simulated environments. Once you acquire the robot, you can confidently deploy the RL-trained policies in real-world settings.
Our simulator settings, particularly with Mujoco, are finely tuned to closely mimic real-world scenarios. This careful calibration ensures that the performances in both simulated and real-world environments are closely aligned. This improvement makes our simulations more trustworthy and enhances our confidence in their applicability to real-world scenarios.
Denoising World Model Learning(DWL) presents an advanced sim-to-real framework that integrates state estimation and system identification. This dual-method approach ensures the robot's learning and adaptation are both practical and effective in real-world contexts.
- Enhanced Sim-to-real Adaptability: Techniques to optimize the robot's transition from simulated to real environments.
- Improved State Estimation Capabilities: Advanced tools for precise and reliable state analysis.
- Generate a new Python virtual environment with Python 3.8 using
conda create -n myenv python=3.8. - For the best performance, we recommend using NVIDIA driver version 525
sudo apt install nvidia-driver-525. The minimal driver version supported is 515. If you're unable to install version 525, ensure that your system has at least version 515 to maintain basic functionality. - Install PyTorch 1.13 with Cuda-11.7:
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
- Install numpy-1.23 with
conda install numpy=1.23. - Install Isaac Gym:
- Download and install Isaac Gym Preview 4 from https://developer.nvidia.com/isaac-gym.
cd isaacgym/python && pip install -e .- Run an example with
cd examples && python 1080_balls_of_solitude.py. - Consult
isaacgym/docs/index.htmlfor troubleshooting.
- Install humanoid-gym:
- Clone this repository.
cd humanoid_gym && pip install -e .
# Launching PPO Policy Training for 'v1' Across 4096 Environments
# This command initiates the PPO algorithm-based training for the humanoid task.
python scripts/train.py --task=humanoid_ppo --run_name v1 --headless --num_envs 4096
# Evaluating the Trained PPO Policy 'v1'
# This command loads the 'v1' policy for performance assessment in its environment.
# Additionally, it automatically exports a JIT model, suitable for deployment purposes.
python scripts/play.py --task=humanoid_ppo --run_name v1
# Implementing Simulation-to-Simulation Model Transformation
# This command facilitates a sim-to-sim transformation using exported 'v1' policy.
python scripts/sim2sim.py --load_model /path/to/logs/XBot_ppo/exported/policies/policy_1.pt
# Run our trained policy
python scripts/sim2sim.py --load_model /path/to/logs/XBot_ppo/exported/policies/policy_example.pt
-
humanoid_ppo
- Purpose: Baseline, PPO policy, Multi-frame low-level control
- Observation Space: Variable $(47 \times H)$ dimensions, where $H$ is the number of frames
- $[O_{t-H} ... O_t]$
- Privileged Information: $73$ dimensions
-
humanoid_dwl (coming soon)
-
Training Command: For training the PPO policy, execute:
python humanoid/scripts/train.py --task=humanoid_ppo --load_run log_file_path --name run_name -
Running a Trained Policy: To deploy a trained PPO policy, use:
python humanoid/scripts/play.py --task=humanoid_ppo --load_run log_file_path --name run_name - By default, the latest model of the last run from the experiment folder is loaded. However, other run iterations/models can be selected by adjusting
load_runandcheckpointin the training config.
- Please note: Before initiating the sim-to-sim process, ensure that you run
play.pyto export a JIT policy. -
Mujoco-based Sim2Sim Deployment: Utilize Mujoco for executing simulation-to-simulation (sim2sim) deployments with the command below:
python scripts/sim2sim.py --load_model /path/to/export/model.pt
-
CPU and GPU Usage: To run simulations on the CPU, set both
--sim_device=cpuand--rl_device=cpu. For GPU operations, specify--sim_device=cuda:{0,1,2...}and--rl_device={0,1,2...}accordingly. Please note thatCUDA_VISIBLE_DEVICESis not applicable, and it's essential to match the--sim_deviceand--rl_devicesettings. -
Headless Operation: Include
--headlessfor operations without rendering. - Rendering Control: Press 'v' to toggle rendering during training.
-
Policy Location: Trained policies are saved in
humanoid/logs/<experiment_name>/<date_time>_<run_name>/model_<iteration>.pt.
For RL training, please refer to humanoid/utils/helpers.py#L161.
For the sim-to-sim process, please refer to humanoid/scripts/sim2sim.py#L169.
- Every environment hinges on an
envfile (legged_robot.py) and aconfigurationfile (legged_robot_config.py). The latter houses two classes:LeggedRobotCfg(encompassing all environmental parameters) andLeggedRobotCfgPPO(denoting all training parameters). - Both
envandconfigclasses use inheritance. - Non-zero reward scales specified in
cfgcontribute a function of the corresponding name to the sum-total reward. - Tasks must be registered with
task_registry.register(name, EnvClass, EnvConfig, TrainConfig). Registration may occur withinenvs/__init__.py, or outside of this repository.
The base environment legged_robot constructs a rough terrain locomotion task. The corresponding configuration does not specify a robot asset (URDF/ MJCF) and no reward scales.
- If you need to add a new environment, create a new folder in the
envs/directory with a configuration file named<your_env>_config.py. The new configuration should inherit from existing environment configurations. - If proposing a new robot:
- Insert the corresponding assets in the
resources/folder. - In the
cfgfile, set the path to the asset, define body names, default_joint_positions, and PD gains. Specify the desiredtrain_cfgand the environment's name (python class). - In the
train_cfg, set theexperiment_nameandrun_name.
- Insert the corresponding assets in the
- If needed, create your environment in
<your_env>.py. Inherit from existing environments, override desired functions and/or add your reward functions. - Register your environment in
humanoid/envs/__init__.py. - Modify or tune other parameters in your
cfgorcfg_trainas per requirements. To remove the reward, set its scale to zero. Avoid modifying the parameters of other environments! - If you want a new robot/environment to perform sim2sim, you may need to modify
humanoid/scripts/sim2sim.py:- Check the joint mapping of the robot between MJCF and URDF.
- Change the initial joint position of the robot according to your trained policy.
Observe the following cases:
# error
ImportError: libpython3.8.so.1.0: cannot open shared object file: No such file or directory
# solution
# set the correct path
export LD_LIBRARY_PATH="~/miniconda3/envs/your_env/lib:$LD_LIBRARY_PATH"
# OR
sudo apt install libpython3.8
# error
AttributeError: module 'distutils' has no attribute 'version'
# solution
# install pytorch 1.12.0
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
# error, results from libstdc++ version distributed with conda differing from the one used on your system to build Isaac Gym
ImportError: /home/roboterax/anaconda3/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.20` not found (required by /home/roboterax/carbgym/python/isaacgym/_bindings/linux64/gym_36.so)
# solution
mkdir ${YOUR_CONDA_ENV}/lib/_unused
mv ${YOUR_CONDA_ENV}/lib/libstdc++* ${YOUR_CONDA_ENV}/lib/_unusedPlease cite the following if you use this code or parts of it:
@article{gu2024humanoid,
title={Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer},
author={Gu, Xinyang and Wang, Yen-Jen and Chen, Jianyu},
journal={arXiv preprint arXiv:2404.05695},
year={2024}
}
The implementation of Humanoid-Gym relies on resources from legged_gym and rsl_rl projects, created by the Robotic Systems Lab. We specifically utilize the LeggedRobot implementation from their research to enhance our codebase.
If you have further questions, please feel free to contact [email protected] or create an issue in this repository.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for humanoid-gym
Similar Open Source Tools
humanoid-gym
Humanoid-Gym is a reinforcement learning framework designed for training locomotion skills for humanoid robots, focusing on zero-shot transfer from simulation to real-world environments. It integrates a sim-to-sim framework from Isaac Gym to Mujoco for verifying trained policies in different physical simulations. The codebase is verified with RobotEra's XBot-S and XBot-L humanoid robots. It offers comprehensive training guidelines, step-by-step configuration instructions, and execution scripts for easy deployment. The sim2sim support allows transferring trained policies to accurate simulated environments. The upcoming features include Denoising World Model Learning and Dexterous Hand Manipulation. Installation and usage guides are provided along with examples for training PPO policies and sim-to-sim transformations. The code structure includes environment and configuration files, with instructions on adding new environments. Troubleshooting tips are provided for common issues, along with a citation and acknowledgment section.
torchtitan
Torchtitan is a PyTorch native platform designed for rapid experimentation and large-scale training of generative AI models. It provides a flexible foundation for developers to build upon with extension points for creating custom extensions. The tool showcases PyTorch's latest distributed training features and supports pretraining Llama 3.1 LLMs of various sizes. It offers key features like multi-dimensional parallelisms, FSDP2 with per-parameter sharding, Tensor Parallel, Pipeline Parallel, and more. Users can contribute to the tool through the experiments folder and core contributions guidelines. Installation can be done from source, nightly builds, or stable releases. The tool also supports training Llama 3.1 models and provides guidance on starting a training run and multi-node training. Citation information is available for referencing the tool in academic work, and the source code is under a BSD 3 license.
testzeus-hercules
Hercules is the world’s first open-source testing agent designed to handle the toughest testing tasks for modern web applications. It turns simple Gherkin steps into fully automated end-to-end tests, making testing simple, reliable, and efficient. Hercules adapts to various platforms like Salesforce and is suitable for CI/CD pipelines. It aims to democratize and disrupt test automation, making top-tier testing accessible to everyone. The tool is transparent, reliable, and community-driven, empowering teams to deliver better software. Hercules offers multiple ways to get started, including using PyPI package, Docker, or building and running from source code. It supports various AI models, provides detailed installation and usage instructions, and integrates with Nuclei for security testing and WCAG for accessibility testing. The tool is production-ready, open core, and open source, with plans for enhanced LLM support, advanced tooling, improved DOM distillation, community contributions, extensive documentation, and a bounty program.
habitat-lab
Habitat-Lab is a modular high-level library for end-to-end development in embodied AI. It is designed to train agents to perform a wide variety of embodied AI tasks in indoor environments, as well as develop agents that can interact with humans in performing these tasks.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.

AI-Scientist
The AI Scientist is a comprehensive system for fully automatic scientific discovery, enabling Foundation Models to perform research independently. It aims to tackle the grand challenge of developing agents capable of conducting scientific research and discovering new knowledge. The tool generates papers on various topics using Large Language Models (LLMs) and provides a platform for exploring new research ideas. Users can create their own templates for specific areas of study and run experiments to generate papers. However, caution is advised as the codebase executes LLM-written code, which may pose risks such as the use of potentially dangerous packages and web access.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
llm-applications
A comprehensive guide to building Retrieval Augmented Generation (RAG)-based LLM applications for production. This guide covers developing a RAG-based LLM application from scratch, scaling the major components, evaluating different configurations, implementing LLM hybrid routing, serving the application in a highly scalable and available manner, and sharing the impacts LLM applications have had on products.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.
cover-agent
CodiumAI Cover Agent is a tool designed to help increase code coverage by automatically generating qualified tests to enhance existing test suites. It utilizes Generative AI to streamline development workflows and is part of a suite of utilities aimed at automating the creation of unit tests for software projects. The system includes components like Test Runner, Coverage Parser, Prompt Builder, and AI Caller to simplify and expedite the testing process, ensuring high-quality software development. Cover Agent can be run via a terminal and is planned to be integrated into popular CI platforms. The tool outputs debug files locally, such as generated_prompt.md, run.log, and test_results.html, providing detailed information on generated tests and their status. It supports multiple LLMs and allows users to specify the model to use for test generation.

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.
habitat-sim
Habitat-Sim is a high-performance physics-enabled 3D simulator with support for 3D scans of indoor/outdoor spaces, CAD models of spaces and piecewise-rigid objects, configurable sensors, robots described via URDF, and rigid-body mechanics. It prioritizes simulation speed over the breadth of simulation capabilities, achieving several thousand frames per second (FPS) running single-threaded and over 10,000 FPS multi-process on a single GPU when rendering a scene from the Matterport3D dataset. Habitat-Sim simulates a Fetch robot interacting in ReplicaCAD scenes at over 8,000 steps per second (SPS), where each ‘step’ involves rendering 1 RGBD observation (128×128 pixels) and rigid-body dynamics for 1/30sec.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.

patchwork
PatchWork is an open-source framework designed for automating development tasks using large language models. It enables users to automate workflows such as PR reviews, bug fixing, security patching, and more through a self-hosted CLI agent and preferred LLMs. The framework consists of reusable atomic actions called Steps, customizable LLM prompts known as Prompt Templates, and LLM-assisted automations called Patchflows. Users can run Patchflows locally in their CLI/IDE or as part of CI/CD pipelines. PatchWork offers predefined patchflows like AutoFix, PRReview, GenerateREADME, DependencyUpgrade, and ResolveIssue, with the flexibility to create custom patchflows. Prompt templates are used to pass queries to LLMs and can be customized. Contributions to new patchflows, steps, and the core framework are encouraged, with chat assistants available to aid in the process. The roadmap includes expanding the patchflow library, introducing a debugger and validation module, supporting large-scale code embeddings, parallelization, fine-tuned models, and an open-source GUI. PatchWork is licensed under AGPL-3.0 terms, while custom patchflows and steps can be shared using the Apache-2.0 licensed patchwork template repository.
For similar tasks
humanoid-gym
Humanoid-Gym is a reinforcement learning framework designed for training locomotion skills for humanoid robots, focusing on zero-shot transfer from simulation to real-world environments. It integrates a sim-to-sim framework from Isaac Gym to Mujoco for verifying trained policies in different physical simulations. The codebase is verified with RobotEra's XBot-S and XBot-L humanoid robots. It offers comprehensive training guidelines, step-by-step configuration instructions, and execution scripts for easy deployment. The sim2sim support allows transferring trained policies to accurate simulated environments. The upcoming features include Denoising World Model Learning and Dexterous Hand Manipulation. Installation and usage guides are provided along with examples for training PPO policies and sim-to-sim transformations. The code structure includes environment and configuration files, with instructions on adding new environments. Troubleshooting tips are provided for common issues, along with a citation and acknowledgment section.

MineStudio
MineStudio is a simple and efficient Minecraft development kit for AI research. It contains tools and APIs for developing Minecraft AI agents, including a customizable simulator, trajectory data structure, policy models, offline and online training pipelines, inference framework, and benchmarking automation. The repository is under development and welcomes contributions and suggestions.
Awesome-World-Models
This repository is a curated list of papers related to World Models for General Video Generation, Embodied AI, and Autonomous Driving. It includes foundation papers, blog posts, technical reports, surveys, benchmarks, and specific world models for different applications. The repository serves as a valuable resource for researchers and practitioners interested in world models and their applications in robotics and AI.

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.
Forza-Mods-AIO
Forza Mods AIO is a free and open-source tool that enhances the gaming experience in Forza Horizon 4 and 5. It offers a range of time-saving and quality-of-life features, making gameplay more enjoyable and efficient. The tool is designed to streamline various aspects of the game, improving user satisfaction and overall enjoyment.
openssa
OpenSSA is an open-source framework for creating efficient, domain-specific AI agents. It enables the development of Small Specialist Agents (SSAs) that solve complex problems in specific domains. SSAs tackle multi-step problems that require planning and reasoning beyond traditional language models. They apply OODA for deliberative reasoning (OODAR) and iterative, hierarchical task planning (HTP). This "System-2 Intelligence" breaks down complex tasks into manageable steps. SSAs make informed decisions based on domain-specific knowledge. With OpenSSA, users can create agents that process, generate, and reason about information, making them more effective and efficient in solving real-world challenges.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.