
VideoTree
Code for paper "VideoTree: Adaptive Tree-based Video Representation for LLM Reasoning on Long Videos"
Stars: 94
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.
README:
This is the official implementation for VideoTree (CVPR2025)
Authors: Ziyang Wang*, Shoubin Yu*, Elias Stengel-Eskin*, Jaehong Yoon, Feng Cheng, Gedas Bertasius, Mohit Bansal
We introduce VideoTree, a query-adaptive and hierarchical framework for long-video understanding with LLMs. Specifically, VideoTree dynamically extracts query-related information from the input video and builds a tree-based video representation for LLM reasoning.


Install environment.
Python 3.8 or above is required.
git clone https://github.com/Ziyang412/VideoTree.git
cd VideoTree
python3 -m venv videetree_env
source activate videetree_env/bin/activate
pip install openai
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install pandas
pip install transformers==4.28.1
pip install accelerateDownload dataset annotations and extracted captions.
Download data.zip from the File LLoVi provided.
unzip data.zipYou could extract captions for EgoSchema at ./data. It also contains dataset annotations.
Specifically, LaViLa base model is leveraged to extract EgoSchema captions at 1 FPS.
Download EgoSchema Videos.
Please follow EgoSchema to download the orginal EgoSchema videos. After downloading, please extract the videos into 1 FPS video frames (save in image format for faster loading speed). Please save in the format of ./data/egoschema_frames/{video_id}/{frame_id}.jpg. Then, to further speed up the tree building process, we extract the visual features for each frame using EVA-CLIP-8B and save the features in ./data/egoschema_features/{video_id}.pt.
python data_extraction/extract_images.py
python data_extraction/extract_features.pySince the orginal Kmeans-pytorch package doesn't set a iteration limit and will cause perpetual loop issue, we update the init file of the original kmeans-pytorch package.
git clone https://github.com/subhadarship/kmeans_pytorch
cd kmeans_pytorchPlease replace the init file in "kmeans_pytorch" folder with the file we provide in "./kmeans_pytorch" folder (this repo). And run the following command.
pip install --editable .Due to the limit of time, we are still updating the codebase. We will also incorporate the scipts/captions for NeXT-QA and IntentQA in the future.
Please update the feature, asgs (in util.py) and output path before running the code.
sh scripts/breath_expansion.sh
Please update the feature, the output of last step (the relevance output path and first level cluster information) and output path before running the code.
python depth_expansion.py
Please update the tree node index file (output of last step), data files and output path before running the code.
sh scripts/egoschema_qa.sh--save_info: save more information, e.g. token usage, detailed prompts, etc.
--num_examples_to_run: how many examples to run. -1 (default) to run all.
--start_from_scratch: ignore existing output files. Start from scratch.We thank the developers of LLoVi, LifelongMemory, EVA-CLIP, Kmeans-pytorch and SKlearn Clustering for their public code release. We also thank the authors of VideoAgent for the helpful discussion.
Please cite our paper if you use our models in your works:
@article{wang2024videotree,
title={VideoTree: Adaptive Tree-based Video Representation for LLM Reasoning on Long Videos},
author={Wang, Ziyang and Yu, Shoubin and Stengel-Eskin, Elias and Yoon, Jaehong and Cheng, Feng and Bertasius, Gedas and Bansal, Mohit},
journal={arXiv preprint arXiv:2405.19209},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VideoTree
Similar Open Source Tools
VideoTree
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.

TaskWeaver
TaskWeaver is a code-first agent framework designed for planning and executing data analytics tasks. It interprets user requests through code snippets, coordinates various plugins to execute tasks in a stateful manner, and preserves both chat history and code execution history. It supports rich data structures, customized algorithms, domain-specific knowledge incorporation, stateful execution, code verification, easy debugging, security considerations, and easy extension. TaskWeaver is easy to use with CLI and WebUI support, and it can be integrated as a library. It offers detailed documentation, demo examples, and citation guidelines.
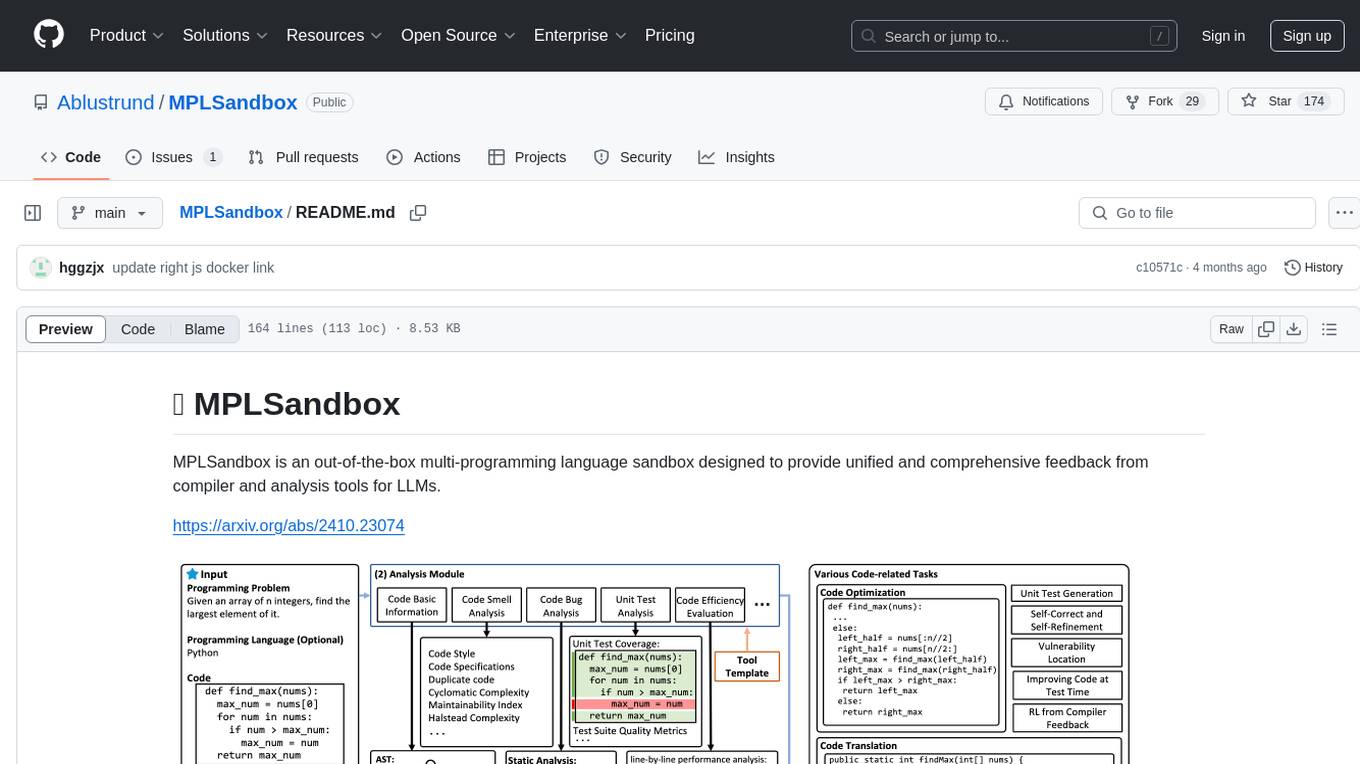
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.
OllamaSharp
OllamaSharp is a .NET binding for the Ollama API, providing an intuitive API client to interact with Ollama. It offers support for all Ollama API endpoints, real-time streaming, progress reporting, and an API console for remote management. Users can easily set up the client, list models, pull models with progress feedback, stream completions, and build interactive chats. The project includes a demo console for exploring and managing the Ollama host.
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
torchtitan
Torchtitan is a PyTorch native platform designed for rapid experimentation and large-scale training of generative AI models. It provides a flexible foundation for developers to build upon with extension points for creating custom extensions. The tool showcases PyTorch's latest distributed training features and supports pretraining Llama 3.1 LLMs of various sizes. It offers key features like multi-dimensional parallelisms, FSDP2 with per-parameter sharding, Tensor Parallel, Pipeline Parallel, and more. Users can contribute to the tool through the experiments folder and core contributions guidelines. Installation can be done from source, nightly builds, or stable releases. The tool also supports training Llama 3.1 models and provides guidance on starting a training run and multi-node training. Citation information is available for referencing the tool in academic work, and the source code is under a BSD 3 license.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.
aiconfig
AIConfig is a framework that makes it easy to build generative AI applications for production. It manages generative AI prompts, models and model parameters as JSON-serializable configs that can be version controlled, evaluated, monitored and opened in a local editor for rapid prototyping. It allows you to store and iterate on generative AI behavior separately from your application code, offering a streamlined AI development workflow.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.
For similar tasks
VideoTree
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
continue
Continue is an open-source autopilot for VS Code and JetBrains that allows you to code with any LLM. With Continue, you can ask coding questions, edit code in natural language, generate files from scratch, and more. Continue is easy to use and can help you save time and improve your coding skills.
anterion
Anterion is an open-source AI software engineer that extends the capabilities of `SWE-agent` to plan and execute open-ended engineering tasks, with a frontend inspired by `OpenDevin`. It is designed to help users fix bugs and prototype ideas with ease. Anterion is equipped with easy deployment and a user-friendly interface, making it accessible to users of all skill levels.
sglang
SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with LLMs faster and more controllable by co-designing the frontend language and the runtime system. The core features of SGLang include: - **A Flexible Front-End Language**: This allows for easy programming of LLM applications with multiple chained generation calls, advanced prompting techniques, control flow, multiple modalities, parallelism, and external interaction. - **A High-Performance Runtime with RadixAttention**: This feature significantly accelerates the execution of complex LLM programs by automatic KV cache reuse across multiple calls. It also supports other common techniques like continuous batching and tensor parallelism.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.
aider
Aider is a command-line tool that lets you pair program with GPT-3.5/GPT-4 to edit code stored in your local git repository. Aider will directly edit the code in your local source files and git commit the changes with sensible commit messages. You can start a new project or work with an existing git repo. Aider is unique in that it lets you ask for changes to pre-existing, larger codebases.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.