
ava
All-in-one desktop app for running LLMs locally.
Stars: 407
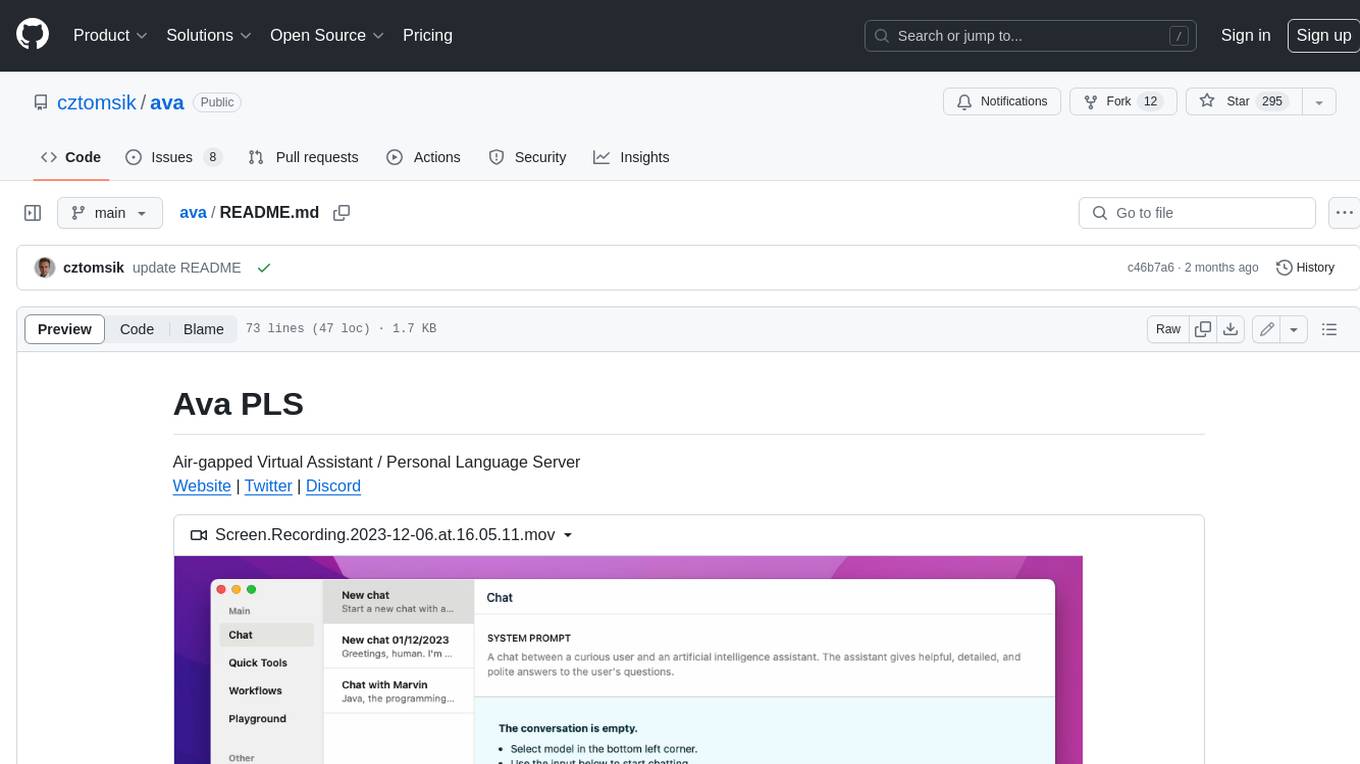
Air-gapped Virtual Assistant / Personal Language Server
README:
Ava is an open-source desktop application for running language models locally on your computer. It's batteries-included GUI for llama.cpp
- Download latest artifacts from Github Actions
- or build it yourself with
zig build runorzig build run -Dheadless=true.
- Zig, C++ (llama.cpp), SQLite
- Preact, Preact Signals, Twind
MIT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ava
Similar Open Source Tools
nodetool
NodeTool is a platform designed for AI enthusiasts, developers, and creators, providing a visual interface to access a variety of AI tools and models. It simplifies access to advanced AI technologies, offering resources for content creation, data analysis, automation, and more. With features like a visual editor, seamless integration with leading AI platforms, model manager, and API integration, NodeTool caters to both newcomers and experienced users in the AI field.
jean
Jean is an AI assistant application that helps manage multiple projects, worktrees, and sessions with Claude CLI. It provides automated worktree management, context loading from sessions and GitHub, magic Git commands/prompts, merge conflict resolution, worktree/archiving, and more. The tool is designed to streamline project management and version control tasks.
tingly-box
Tingly Box is a tool that helps in deciding which model to call, compressing context, and routing requests efficiently. It offers secure, reliable, and customizable functional extensions. With features like unified API, smart routing, context compression, auto API translation, blazing fast performance, flexible authentication, visual control panel, and client-side usage stats, Tingly Box provides a comprehensive solution for managing AI models and tokens. It supports integration with various IDEs, CLI tools, SDKs, and AI applications, making it versatile and easy to use. The tool also allows seamless integration with OAuth providers like Claude Code, enabling users to utilize existing quotas in OpenAI-compatible tools. Tingly Box aims to simplify AI model management and usage by providing a single endpoint for multiple providers with minimal configuration, promoting seamless integration with SDKs and CLI tools.
neuropilot
NeuroPilot is an open-source AI-powered education platform that transforms study materials into interactive learning resources. It provides tools like contextual chat, smart notes, flashcards, quizzes, and AI podcasts. Supported by various AI models and embedding providers, it offers features like WebSocket streaming, JSON or vector database support, file-based storage, and configurable multi-provider setup for LLMs and TTS engines. The technology stack includes Node.js, TypeScript, Vite, React, TailwindCSS, JSON database, multiple LLM providers, and Docker for deployment. Users can contribute to the project by integrating AI models, adding mobile app support, improving performance, enhancing accessibility features, and creating documentation and tutorials.
jan
Jan is an open-source ChatGPT alternative that runs 100% offline on your computer. It supports universal architectures, including Nvidia GPUs, Apple M-series, Apple Intel, Linux Debian, and Windows x64. Jan is currently in development, so expect breaking changes and bugs. It is lightweight and embeddable, and can be used on its own within your own projects.
codemie-code
Unified AI Coding Assistant CLI for managing multiple AI agents like Claude Code, Google Gemini, OpenCode, and custom AI agents. Supports OpenAI, Azure OpenAI, AWS Bedrock, LiteLLM, Ollama, and Enterprise SSO. Features built-in LangGraph agent with file operations, command execution, and planning tools. Cross-platform support for Windows, Linux, and macOS. Ideal for developers seeking a powerful alternative to GitHub Copilot or Cursor.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.

AionUi
AionUi is a user interface library for building modern and responsive web applications. It provides a set of customizable components and styles to create visually appealing user interfaces. With AionUi, developers can easily design and implement interactive web interfaces that are both functional and aesthetically pleasing. The library is built using the latest web technologies and follows best practices for performance and accessibility. Whether you are working on a personal project or a professional application, AionUi can help you streamline the UI development process and deliver a seamless user experience.
databend
Databend is an open-source cloud data warehouse built in Rust, offering fast query execution and data ingestion for complex analysis of large datasets. It integrates with major cloud platforms, provides high performance with AI-powered analytics, supports multiple data formats, ensures data integrity with ACID transactions, offers flexible indexing options, and features community-driven development. Users can try Databend through a serverless cloud or Docker installation, and perform tasks such as data import/export, querying semi-structured data, managing users/databases/tables, and utilizing AI functions.
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.
awesome-code-ai
A curated list of AI coding tools, including code completion, refactoring, and assistants. This list includes both open-source and commercial tools, as well as tools that are still in development. Some of the most popular AI coding tools include GitHub Copilot, CodiumAI, Codeium, Tabnine, and Replit Ghostwriter.
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.
MentraOS
MentraOS is an open source operating system designed for smart glasses. It simplifies the development of smart glasses apps by handling pairing, connection, data streaming, and cross-compatibility. Developers can create apps using the TypeScript SDK quickly and easily, with access to smart glasses I/O components like displays, microphones, cameras, and speakers. The platform emphasizes cross-compatibility, speed of app development, control over device features, and easy distribution to users. The MentraOS Community is dedicated to promoting open, cross-compatible, and user-controlled personal computing through the development and support of MentraOS.

executorch
ExecuTorch is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch Edge ecosystem and enables efficient deployment of PyTorch models to edge devices. Key value propositions of ExecuTorch are: * **Portability:** Compatibility with a wide variety of computing platforms, from high-end mobile phones to highly constrained embedded systems and microcontrollers. * **Productivity:** Enabling developers to use the same toolchains and SDK from PyTorch model authoring and conversion, to debugging and deployment to a wide variety of platforms. * **Performance:** Providing end users with a seamless and high-performance experience due to a lightweight runtime and utilizing full hardware capabilities such as CPUs, NPUs, and DSPs.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.