
langchain_dart
Build LLM-powered Dart/Flutter applications.
Stars: 497

LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).
README:



Build LLM-powered Dart/Flutter applications.
LangChain.dart is an unofficial Dart port of the popular LangChain Python framework created by Harrison Chase.
LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, translation, extraction, recsys, etc.).
The components can be grouped into a few core modules:
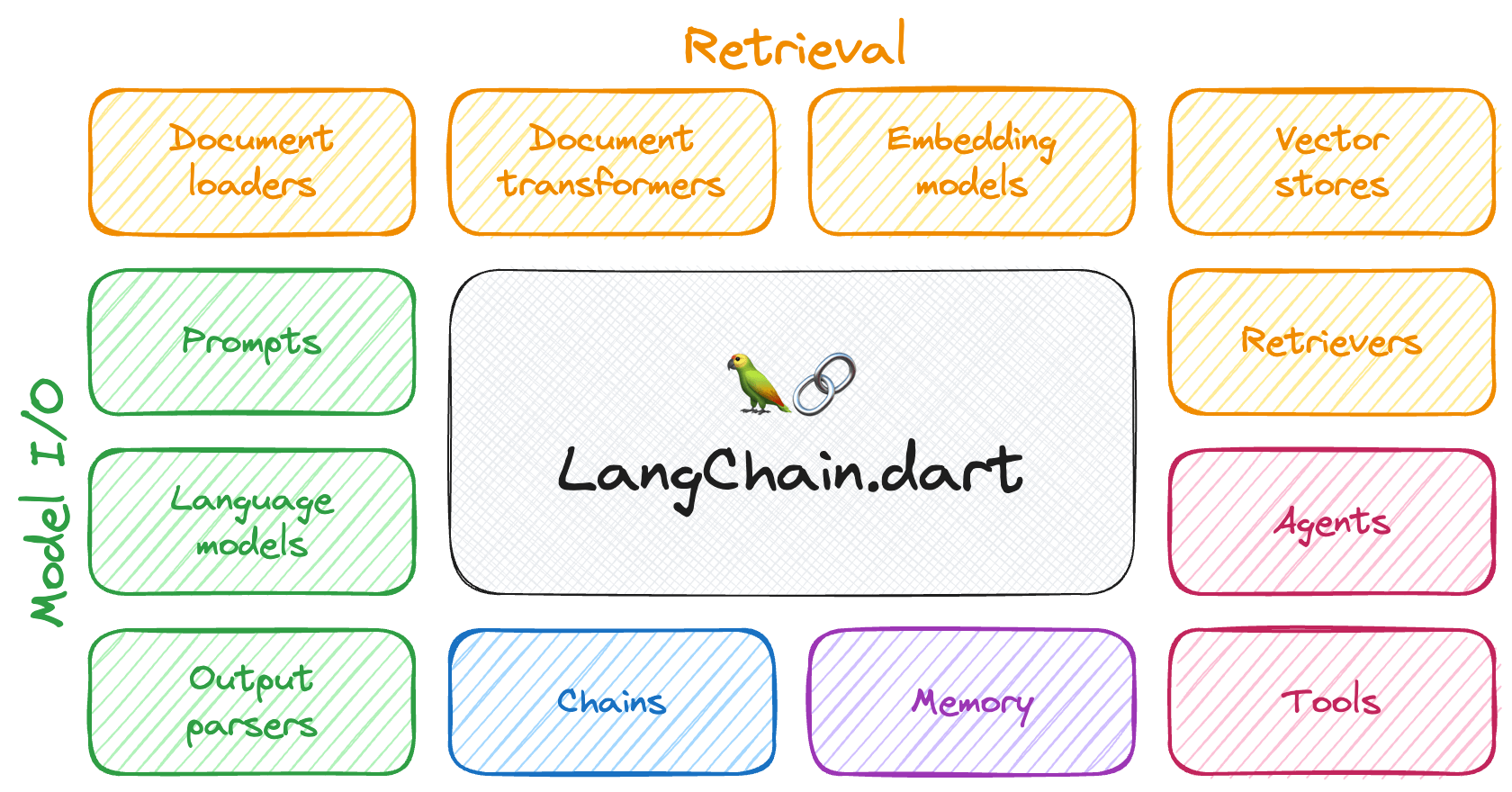
- 📃 Model I/O: LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers).
- 📚 Retrieval: assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG).
- 🤖 Agents: "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task.
The different components can be composed together using the LangChain Expression Language (LCEL).
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP), serving as essential components in a wide range of applications, such as question-answering, summarization, translation, and text generation.
The adoption of LLMs is creating a new tech stack in its wake. However, emerging libraries and tools are predominantly being developed for the Python and JavaScript ecosystems. As a result, the number of applications leveraging LLMs in these ecosystems has grown exponentially.
In contrast, the Dart / Flutter ecosystem has not experienced similar growth, which can likely be attributed to the scarcity of Dart and Flutter libraries that streamline the complexities associated with working with LLMs.
LangChain.dart aims to fill this gap by abstracting the intricacies of working with LLMs in Dart and Flutter, enabling developers to harness their combined potential effectively.
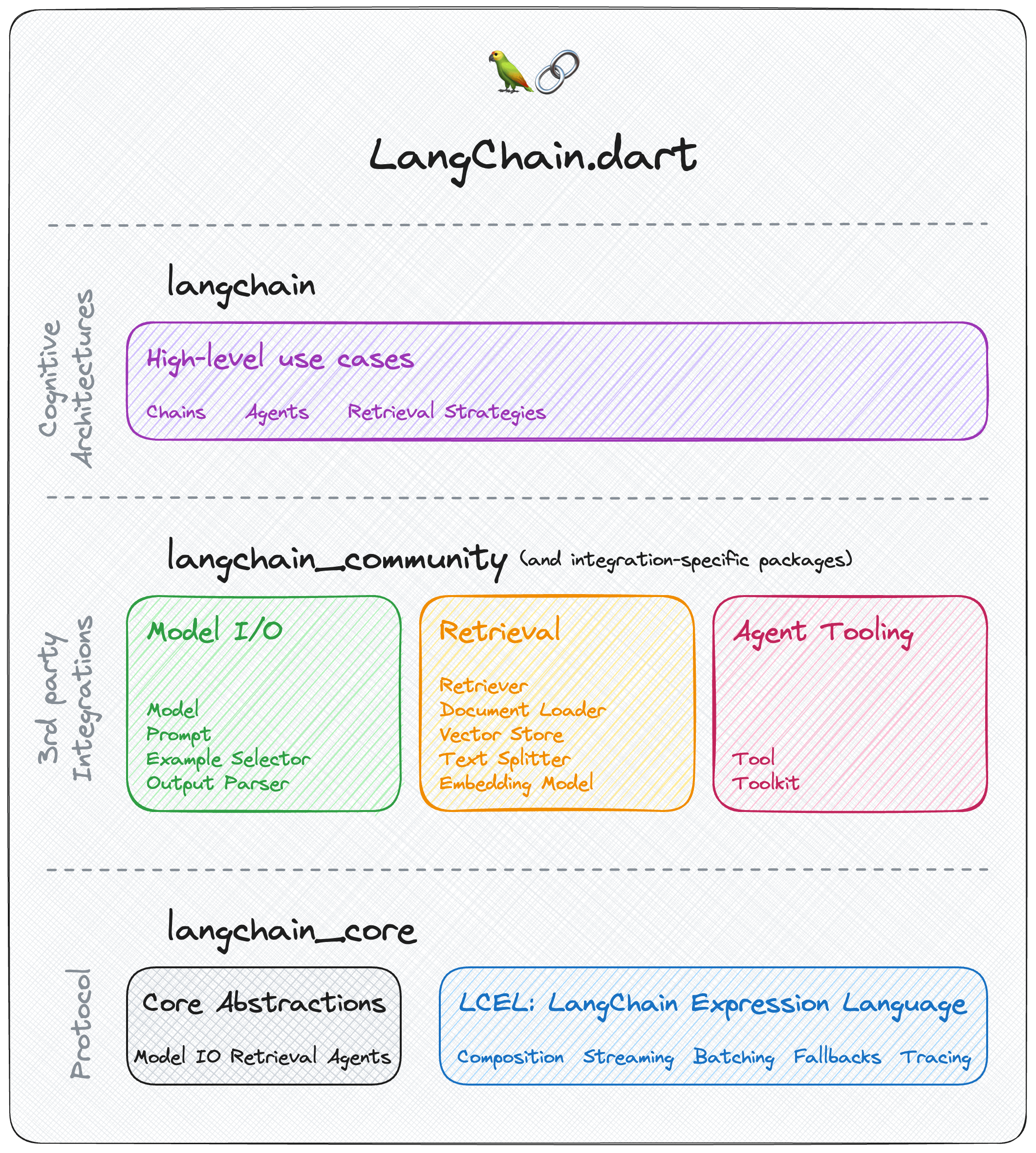
LangChain.dart has a modular design that allows developers to import only the components they need. The ecosystem consists of several packages:

Contains only the core abstractions as well as LangChain Expression Language as a way to compose them together.
Depend on this package to build frameworks on top of LangChain.dart or to interoperate with it.
Contains higher-level and use-case specific chains, agents, and retrieval algorithms that are at the core of the application's cognitive architecture.
Depend on this package to build LLM applications with LangChain.dart.
This package exposes
langchain_coreso you don't need to depend on it explicitly.

Contains third-party integrations and community-contributed components that are not part of the core LangChain.dart API.
Depend on this package if you want to use any of the integrations or components it provides.
Popular third-party integrations (e.g. langchain_openai, langchain_google, langchain_ollama, etc.) are moved to their own packages so that they can be imported independently without depending on the entire langchain_community package.
Depend on an integration-specific package if you want to use the specific integration.
| Package | Version | Description |
|---|---|---|
| langchain_anthropic |  |
Anthopic integration (Claude 3.5 Sonnet, Opus, Haiku, Instant, etc.) |
| langchain_chroma |  |
Chroma vector database integration |
| langchain_firebase |  |
Firebase integration (VertexAI for Firebase (Gemini 1.5 Pro, Gemini 1.5 Flash, etc.)) |
| langchain_google |  |
Google integration (GoogleAI, VertexAI, Gemini, PaLM 2, Embeddings, Vector Search, etc.) |
| langchain_mistralai |  |
Mistral AI integration (Mistral-7B, Mixtral 8x7B, Mixtral 8x22B, Mistral Small, Mistral Large, embeddings, etc.). |
| langchain_ollama |  |
Ollama integration (Llama 3.2, Gemma 2, Phi-3.5, Mistral nemo, WizardLM-2, CodeGemma, Command R, LLaVA, DBRX, Qwen, Dolphin, DeepSeek Coder, Vicuna, Orca, etc.) |
| langchain_openai |  |
OpenAI integration (GPT-4o, o1, Embeddings, Tools, Vision, DALL·E 3, etc.) and OpenAI Compatible services (TogetherAI, Anyscale, OpenRouter, One API, Groq, Llamafile, GPT4All, etc.) |
| langchain_pinecone |  |
Pinecone vector database integration |
| langchain_supabase |  |
Supabase Vector database integration |
The following packages are maintained (and used internally) by LangChain.dart, although they can also be used independently:
Depend on an API client package if you just want to consume the API of a specific provider directly without using LangChain.dart abstractions.
| Package | Version | Description |
|---|---|---|
| anthropic_sdk_dart |  |
Anthropic API client |
| chromadb |  |
Chroma DB API client |
| googleai_dart |  |
Google AI for Developers API client |
| mistralai_dart |  |
Mistral AI API client |
| ollama_dart |  |
Ollama API client |
| openai_dart |  |
OpenAI API client |
| openai_realtime_dart |  |
OpenAI Realtime API client |
| tavily_dart |  |
Tavily API client |
| vertex_ai |  |
GCP Vertex AI API client |
The following integrations are available in LangChain.dart:
| Chat model | Package | Streaming | Multi-modal | Tool-call | Description |
|---|---|---|---|---|---|
| ChatAnthropic | langchain_anthropic | ✔ | ✔ | ✔ | Anthropic Messages API (aka Claude API) |
| ChatFirebaseVertexAI | langchain_firebase | ✔ | ✔ | ✔ | Vertex AI for Firebase API (aka Gemini API) |
| ChatGoogleGenerativeAI | langchain_google | ✔ | ✔ | ✔ | Google AI for Developers API (aka Gemini API) |
| ChatMistralAI | langchain_mistralai | ✔ | Mistral Chat API | ||
| ChatOllama | langchain_ollama | ✔ | ✔ | ✔ | Ollama Chat API |
| ChatOpenAI | langchain_openai | ✔ | ✔ | ✔ | OpenAI Chat API and OpenAI Chat API compatible services (GitHub Models, TogetherAI, Anyscale, OpenRouter, One API, Groq, Llamafile, GPT4All, FastChat, etc.) |
| ChatVertexAI | langchain_google | GCP Vertex AI Chat API |
Note: Prefer using Chat Models over LLMs as many providers have deprecated them.
| LLM | Package | Streaming | Description |
|---|---|---|---|
| Ollama | langchain_ollama | ✔ | Ollama Completions API |
| OpenAI | langchain_openai | ✔ | OpenAI Completions API |
| VertexAI | langchain_google | GCP Vertex AI Text API |
| Vector store | Package | Description |
|---|---|---|
| Chroma | langchain_chroma | Chroma integration |
| MemoryVectorStore | langchain | In-memory vector store for prototype and testing |
| ObjectBoxVectorStore | langchain_community | ObjectBox integration |
| Pinecone | langchain_pinecone | Pinecone integration |
| Supabase | langchain_supabase | Supabase Vector integration |
| VertexAIMatchingEngine | langchain_google | Vertex AI Vector Search (former Matching Engine) integration |
| Tool | Package | Description |
|---|---|---|
| CalculatorTool | langchain_community | To calculate math expressions |
| OpenAIDallETool | langchain_openai | OpenAI's DALL-E Image Generator |
| TavilyAnswerTool | langchain_community | Returns an answer for a query using the Tavily search engine |
| TavilySearchResultsTool | langchain_community | Returns a list of results for a query using the Tavily search engine |
To start using LangChain.dart, add langchain as a dependency to your pubspec.yaml file. Also, include the dependencies for the specific integrations you want to use (e.g.langchain_community, langchain_openai, langchain_google, etc.):
dependencies:
langchain: {version}
langchain_community: {version}
langchain_openai: {version}
langchain_google: {version}
...The most basic building block of LangChain.dart is calling an LLM on some prompt. LangChain.dart provides a unified interface for calling different LLMs. For example, we can use ChatGoogleGenerativeAI to call Google's Gemini model:
final model = ChatGoogleGenerativeAI(apiKey: googleApiKey);
final prompt = PromptValue.string('Hello world!');
final result = await model.invoke(prompt);
// Hello everyone! I'm new here and excited to be part of this community.But the power of LangChain.dart comes from chaining together multiple components to implement complex use cases. For example, a RAG (Retrieval-Augmented Generation) pipeline that would accept a user query, retrieve relevant documents from a vector store, format them using prompt templates, invoke the model, and parse the output:
// 1. Create a vector store and add documents to it
final vectorStore = MemoryVectorStore(
embeddings: OpenAIEmbeddings(apiKey: openaiApiKey),
);
await vectorStore.addDocuments(
documents: [
Document(pageContent: 'LangChain was created by Harrison'),
Document(pageContent: 'David ported LangChain to Dart in LangChain.dart'),
],
);
// 2. Define the retrieval chain
final retriever = vectorStore.asRetriever();
final setupAndRetrieval = Runnable.fromMap<String>({
'context': retriever.pipe(
Runnable.mapInput((docs) => docs.map((d) => d.pageContent).join('\n')),
),
'question': Runnable.passthrough(),
});
// 3. Construct a RAG prompt template
final promptTemplate = ChatPromptTemplate.fromTemplates([
(ChatMessageType.system, 'Answer the question based on only the following context:\n{context}'),
(ChatMessageType.human, '{question}'),
]);
// 4. Define the final chain
final model = ChatOpenAI(apiKey: openaiApiKey);
const outputParser = StringOutputParser<ChatResult>();
final chain = setupAndRetrieval
.pipe(promptTemplate)
.pipe(model)
.pipe(outputParser);
// 5. Run the pipeline
final res = await chain.invoke('Who created LangChain.dart?');
print(res);
// David created LangChain.dart- LangChain.dart documentation
- Code Assist AI (Chatbot for LangChain.dart documentation)
- Sample apps
- LangChain.dart blog
- Project board
Stay up-to-date on the latest news and updates on the field, have great discussions, and get help in the official LangChain.dart Discord server.
| 📢 Call for Collaborators 📢 |
|---|
| We are looking for collaborators to join the core group of maintainers. |
New contributors welcome! Check out our Contributors Guide for help getting started.
Join us on Discord to meet other maintainers. We'll help you get your first contribution in no time!
- LangChain: The original Python LangChain project.
- LangChain.js: A JavaScript port of LangChain.
- LangChain.go: A Go port of LangChain.
- LangChain.rb: A Ruby port of LangChain.

LangChain.dart is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for langchain_dart
Similar Open Source Tools
langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.

llm4ad
LLM4AD is an open-source Python-based platform leveraging Large Language Models (LLMs) for Automatic Algorithm Design (AD). It provides unified interfaces for methods, tasks, and LLMs, along with features like evaluation acceleration, secure evaluation, logs, GUI support, and more. The platform was originally developed for optimization tasks but is versatile enough to be used in other areas such as machine learning, science discovery, game theory, and engineering design. It offers various search methods and algorithm design tasks across different domains. LLM4AD supports remote LLM API, local HuggingFace LLM deployment, and custom LLM interfaces. The project is licensed under the MIT License and welcomes contributions, collaborations, and issue reports.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

vscode-unify-chat-provider
The 'vscode-unify-chat-provider' repository is a tool that integrates multiple LLM API providers into VS Code's GitHub Copilot Chat using the Language Model API. It offers free tier access to mainstream models, perfect compatibility with major LLM API formats, deep adaptation to API features, best performance with built-in parameters, out-of-the-box configuration, import/export support, great UX, and one-click use of various models. The tool simplifies model setup, migration, and configuration for users, providing a seamless experience within VS Code for utilizing different language models.
RustySEO
RustySEO is a free, modern SEO/GEO toolkit designed to help users crawl and analyze websites and server logs without crawl limits. It is an all-in-one, cross-platform marketing toolkit for comprehensive SEO & GEO analysis, providing actionable insights into marketing and SEO strategies. The tool offers features such as shallow & deep crawl, technical diagnostics, on-page SEO analysis, dashboards, reporting, topic and keyword generators, AI chatbot, crawl history, image conversion and optimization, and more. RustySEO aims to be a robust, free alternative to costly commercial SEO tools, with integrations like Google PageSpeed Insights, Google Gemini, and more.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.

MiniCPM-V-CookBook
MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.
cocoindex
CocoIndex is the world's first open-source engine that supports both custom transformation logic and incremental updates specialized for data indexing. Users declare the transformation, CocoIndex creates & maintains an index, and keeps the derived index up to date based on source update, with minimal computation and changes. It provides a Python library for data indexing with features like text embedding, code embedding, PDF parsing, and more. The tool is designed to simplify the process of indexing data for semantic search and structured information extraction.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.
langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.