
chat-your-doc
Awesome LLM application repo
Stars: 67

Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.
README:
Chat Your Doc is an experimental project aimed at exploring various applications based on LLM. Although it is nominally a chatbot project, its purpose is broader. The project explores various applications using tools such as LangChain, LlamaIndex. In the "Lab Apps" section, you can find many examples, including simple and complex ones. The project focuses on researching and exploring various LLM applications, while also incorporating other fields such as UX and computer vision. The "Lab App" section includes a table with links to various apps, descriptions, launch commands, and demos.
- .....

Also, take a look at a use-case known as Knowledge Center that leverages different RAG or Chunking techniques in this repository.
- Video: https://drive.google.com/file/d/1AMAi561gbAuHyT5BQFt7wlg5Xockx-Ni/view?usp=drive_link
- Source: https://github.com/XinyueZ/chat-your-doc/blob/master/simple/multimodal_chat.py
- Start:
streamlit run simple/multimodal_chat.py --server.port 8000 --server.enableCORS false
For OpenAI, set API-KEY to your environment variables.
export OPENAI_API_KEY="sk-$TJHGFHJDSFDGAFDFRTHT§$%$%&§%&"conda env create -n chat-ur-doc -f environment.yml
conda activate chat-ur-docpip install -r requirements.txt- LangChain/LangGraph: Build Reflection Enabled Agentic 👨🏻💻 code
- Llama-Index/AgentWorkflow: Build Reflection Enabled Agentic 👨🏻💻 code
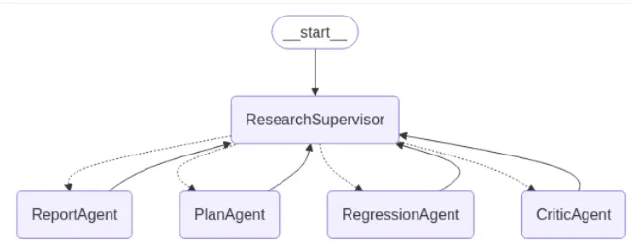
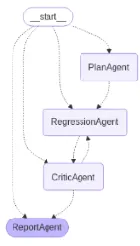
- LangGraph / swarm and supervisor: Build Reflection Enabled Agentic 👨🏻💻 supervisor 👨🏻💻 swarm
- CrewAI / Hierarchical Manager: Build Reflection Enabled Agentic 👨🏻💻 code
- (Llama-Index Workflows)Translation Agent via Reflection Workflow 👨🏻💻 code
- OpenAI Agent SDK: Build Reflection Enabled Agentic 👨🏻💻 code
ref: https://python.langchain.com/docs/modules/data_connection/vectorstores/
Chroma, FAISS
pip install chromadb
pip install faiss-cpu
LLM fine-tuning step: Tokenizing
Chat with your PDF (Streamlit Demo)
LLM, LangChain Agent, Computer Vision
How to Use OpenAI Assistants (API)
Experience with the LangChain App Template
wine price app, prompt and query wine price. The application has been created, just need to create data, install Poetry and run it.
Full instructions for creating a LangChain App Template can be found here: LangChain App Template
Llama-Index: RAG with Vector and Summary
Multi-Retrievers with Vector and Summary pattern implementation.
Llama-Index: RAG with Vector and Summary by using Agent
Agent for Vector and Summary pattern implementation.
Intuitively create an agent from scratch with LangChain.
Intuitively create an agent from scratch with LlamaIndex.
Multi-Query Retrieval with RAG
Enhance query context with intermediate queries during RAG to improve information retrieval for the original query.
Explain how prio-reasoning works in LangChain(qa-chain with refine) and LlamaIndex (MultiStepQueryEngine).
Introduce the Multi-Query pattern in bundle and step-down solutions.
Introduce the hello,world version use-case with LangGraph, just simple example to kick off the topic.
Quick Tour: Ollama+Gemma+LangChain
Use ollama to deploy and use Gemma with langchain on local machine.
RAG with Hypothetical Document Embeddings(HyDE)
Hypothetical Document Embeddings, two-steps process of RAG. Implementation of HyDE retrieval by LlamaIndex, hybrid, local or remote LLMs.
LangChain: Use LLM Agent for World GPU Demand Prediction Report
Reflecting the analytical methods of the AI era, based on the Agent mechanism and generative AI, intelligently generates necessary information and code.
LangChain: Multi-User Conversation Support
By using some methods, make the conversation able to happen among multiple users, achieving the basic of a simple “group conversation”.
LangChain: History-Driven RAG Enhanced By LLM-Chain Routing LangChain
Using LLM to predict the routing of the chain and achieve Retrieval Augmented Generation with help of conversation history applying HyDE or refined standalone query.
LangChain: Multi-User Conversation Support(Follow-up)
A follow-up read: Use Cohere’s documents and a special field in additional_kwargsfeature to enhance the organization of information in multi-user conversation.
(Llama-Index Workflow)Translation Agent via Reflection Workflow
Implemention of Translation Agent: Agentic translation using reflection workflow with Llama-Index workflow framework.
Ollama Workaround: DeepSeek R1 Tool Support
Tool support of Ollama served DeepSeek R1 is still not very well, in this text there is a solution to workaround it and some how we can call tool according to the model response.
| App | Description | Launch | Demo |
|---|---|---|---|
| i-ask.sh | Simply ask & answer via OpenAI API | i-ask.sh "Who is Joe Biden?" |
 |
| chat_openai.py | Just one chat session | streamlit run simple/chat_openai.py --server.port 8000 --server.enableCORS false |
 |
| open_api_llm_app.py | Use OpenAI LLM to answer simple question | streamlit run simple/open_api_llm_app.py --server.port 8001 --server.enableCORS false |
 |
| read_html_app.py | Get html content and chunk | streamlit run simple/read_html_app.py --server.port 8002 --server.enableCORS false |
 |
| chatbot.py | Basic chatbot | streamlit run simple/chatbot.py --server.port 8003 --server.enableCORS false |
 
|
| retriever.py | Use concept of retriever and LangChain Expression Language (LCEL) | streamlit run simple/retriever.py --server.port 8004 --server.enableCORS false |
 
|
| hello_llamaindex.py | A very simple LlamaIndex to break ice of the story. | streamlit run simple/hello_llamaindex.py --server.port 8005 --server.enableCORS false |
|
| llamaindex_context.py | A simple app of LlamaIndex, introduce of context for configuration, StorageContext, ServiceContext. | streamlit run simple/llamaindex_context.py --server.port 8006 --server.enableCORS false |
|
| llamaindex_hub_simple.py | A simple app of LlamaIndex, introduce of load stuff from https://llamahub.ai/. | streamlit run simple/llamaindex_hub_simple.py --server.port 8007 --server.enableCORS false |
|
| prio_reasoning_context.py | A simple app that based on RAG with Prio-Reasoning pattern in LlamaIndex or LangChain. | streamlit run simple/prio_reasoning_context.py --server.port 8008 --server.enableCORS false |
read   
|
| ollama_gemma.py | A Ollama for Gemma integration with the langchain. |
read 
|
|
| nvidia_vs_groq.py | Compare Nvidia API and Groq, by using llama2 and mixtral_8x7b
|
streamlit run simple/nvidia_vs_groq.py --server.port 8009 --server.enableCORS false |
read  
|
| llamaindex_workflow_reflection_flow.py | Implemention of Translation Agent: Agentic translation using reflection workflow with Llama-Index workflow framework | streamlit run simple/llamaindex_workflow_reflection_flow.py --server.port 8009 --server.enableCORS false |
read 
|
| langchain_citation_chain.py | (LangChain) Retrieval Augmented Generation with Citations, inspired by Llama-index version | Llama-index version | |
| lc_deepseek_tool_call.py | Use some workarounds to apply tool calling on Ollama served DeepSeek R1 | python simple/lc_deepseek_tool_call.py |
Ollama Workaround: DeepSeek R1 Tool Support |
| li_deepseek_agent.py | LlamaIndex to apply ReAct with Ollama served DeepSeek R1 | python simple/li_deepseek_agent.py |
| App | Description | Launch | Demo |
|---|---|---|---|
| sim_app.py | Use the vector database to save file in chunks and retrieve similar content from the database | streamlit run intermediate/sim_app.py --server.port 8002 --server.enableCORS false |
 |
| llm_chain_translator_app.py | Use LLMChain to do language translation | streamlit run intermediate/llm_chain_translator_app.py --server.port 8003 --server.enableCORS false |
|
| html_summary_chat_app.py | Summary html content | streamlit run intermediate/html_summary_chat_app.py --server.port 8004 --server.enableCORS false |
 |
| html_2_json_app.py | Summary html keypoints into keypoint json | streamlit run intermediate/html_2_json_app.py --server.port 8005 --server.enableCORS false |
 |
| assistants.py | Use OpenAI Assistants API in different ways | streamlit run intermediate/assistants.py --server.port 8006 --server.enableCORS false |
read     
|
| hyde_retrieval.py | Implementation of HyDE retrieval by LlamaIndex, hybrid, local or remote LLMs. | streamlit run intermediate/hyde_retrieval.py --server.port 8007 --server.enableCORS false |
read   
|
| App | Description | Launch | Demo |
|---|---|---|---|
| qa_chain_pdf_app.py | Ask info from PDF file, chat with it | streamlit run advanced/qa_chain_pdf_app.py --server.port 8004 --server.enableCORS false |
 
|
| faiss_app.py | Ask info from a internet file, find similar docs and answer with VectorDBQAWithSourcesChain | streamlit run advanced/faiss_app.py --server.port 8005 --server.enableCORS false |
 
|
| html_2_json_output_app.py | Load html content and summary into json objects | streamlit run advanced/html_2_json_output_app.py --server.port 8006 --server.enableCORS false |
 
|
| joke_bot.py | Prompt engineering to get one random joke or rate one joke |
python advanced/joke_bot.py --rate "Why couldn't the bicycle stand up by itself? It was two tired." or python advanced/joke_bot.py --tell --num 4
|
 
|
| chat_ur_docs.py | Chat with documents freely | streamlit run advanced/chat_ur_docs.py --server.port 8004 --server.enableCORS false |
read 
|
| image_auto_annotation.py | Use LLM, LangChain Agent and GroundingDINO to detect objects on images freely (auto-annotation) | streamlit run advanced/image_auto_annotation.py --server.port 8006 --server.enableCORS false |
read 
|
| langgraph_auto_annotation.py | LangGraph, YOLOv8 World, Gemma, BlipProcessor or OpenAI-Vision to detect on image freely (auto-annotation) | streamlit run advanced/langgraph_auto_annotation.py --server.port 8006 --server.enableCORS false |
 |
| adv_rag.py | Advanced RAG approaches, use partition_pdf to extract texts and tables and analyze them | streamlit run advanced/adv_rag.py --server.port 8007 --server.enableCORS false |
read |
| llamaindex_vector_summary_retriever.py | Use LlamaIndex to apply vectory/summary pattern by using multi retrievers | streamlit run advanced/llamaindex_multi_vector_summary.py --server.port 8008 --server.enableCORS false |
read 
|
| llamaindex_vector_summary_agent.py | Use LlamaIndex to apply vectory/summary pattern by using agent | streamlit run advanced/llamaindex_multi_vector_summary_agent.py --server.port 8009 --server.enableCORS false |
read 
|
| multi_queries.py | Use LlamaIndex and LangChain to apply the multi-queries pattern, including build method of the LangChain, and custom retriever based solution in Llama-Index, also the other sub-query based solutions | streamlit run advanced/multi_queries.py --server.port 8010 --server.enableCORS false |
read  
|
| langgraph_agent_mailtool.py | Use LangGraph (Groq is used for agent) to driven a Email deliever of the custom receipts. | streamlit run advanced/langgraph_agent_mailtool.py --server.port 8011 --server.enableCORS false |
 
|
| llamaindex_adaptive_rag.py | App that implements the adaptive RAG pattern | streamlit run advanced/llamaindex_adaptive_rag.py --server.port 8012 --server.enableCORS false |
 |
| Notebook | Description | Demo |
|---|---|---|
| audio2text2LLM.ipynb | Basic audio to text and summary |  |
| audio2text2music.ipynb | audiocraft, Whisper, automatic-speech-recognition, speech to text, generate music by the text, synthesis speech+BGM |  |
| image_description.ipynb | Use OpenAI Vision or blip-image-captioning-base, blip-image-captioning-large, a use-case to get the image description. | |
| image_desc2music.ipynb | audiocraft blip-image-captioning-base, blip-image-captioning-large, a use-case to get the image description and generate music based on the image | |
| langchain_agent_scratch.ipynb | Create the agent from scratch in langchain |
read 
|
| llamaindex_agent_from_scratch.ipynb | Create the agent from scratch with LlamaIndex |
read 
|
| llamaindex_vector_summary_retriever.ipynb | Use LlamaIndex to apply vectory/summary pattern by using multi retrievers |
read
|
| llamaindex_vector_summary_agent.ipynb | Use LlamaIndex to apply vectory/summary pattern by using agent |
read
|
| multi_queries_retrieval.ipynb | Use LlamaIndex and LangChain to apply mutli-query pattern for RAG |
read 
|
| yolo8_world_and_openai_vision.py | Use YoLoV8 World and OpenAI Vision together to enchance image auto-annotation |  |
| yolo8_world_and_gemma.py | Use YoLoV8 World, OpenAI Vision, Ollama Gemma integration to enchance image auto-annotation | |
| langgraph_helloworld.ipynb | hello,world version of langgraph |
read  
|
| langchain_agent_gmail.ipynb | Use LangGraph to driven a Email deliever of the custom receipts. |
|
| hyde_retrieval.ipynb | Implementation of HyDE retrieval by LlamaIndex, hybrid, local or remote LLMs. |
read 
|
| agent_gpu_demand_prediction.ipynb | Use pure Agent (LangChain) to generate a report paper of global GPU demand prediction. |
read, , ,
|
| multi_user_conversation.ipynb | Try to do multi-user chat with LangChain, ConversationBufferMemory, ConversationChain, RunnableWithMessageHistory, ChatMessageHistory, convert_openai_messages and LCEL |
read read (Follow-up) |
| DenseXRetrieval.ipynb | Dense X Retrieval: What Retrieval Granularity Should We Use? by using Llama Packs | |
| llamaindex_query_router.ipynb | LLM application through query routing and long-context, a type of reflection flow based on the user query. Inspired by Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chat-your-doc
Similar Open Source Tools
chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.
pr-agent
PR-Agent is a tool designed to assist in efficiently reviewing and handling pull requests by providing AI feedback and suggestions. It offers various tools such as Review, Describe, Improve, Ask, Update CHANGELOG, and more, with the ability to run them via different interfaces like CLI, PR Comments, or automatically triggering them when a new PR is opened. The tool supports multiple git platforms and models, emphasizing real-life practical usage and modular, customizable tools.

hcaptcha-challenger
hCaptcha Challenger is a tool designed to gracefully face hCaptcha challenges using a multimodal large language model. It does not rely on Tampermonkey scripts or third-party anti-captcha services, instead implementing interfaces for 'AI vs AI' scenarios. The tool supports various challenge types such as image labeling, drag and drop, and advanced tasks like self-supervised challenges and Agentic Workflow. Users can access documentation in multiple languages and leverage resources for tasks like model training, dataset annotation, and model upgrading. The tool aims to enhance user experience in handling hCaptcha challenges with innovative AI capabilities.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.
pr-agent
PR-Agent is a tool that helps to efficiently review and handle pull requests by providing AI feedbacks and suggestions. It supports various commands such as generating PR descriptions, providing code suggestions, answering questions about the PR, and updating the CHANGELOG.md file. PR-Agent can be used via CLI, GitHub Action, GitHub App, Docker, and supports multiple git providers and models. It emphasizes real-life practical usage, with each tool having a single GPT-4 call for quick and affordable responses. The PR Compression strategy enables effective handling of both short and long PRs, while the JSON prompting strategy allows for modular and customizable tools. PR-Agent Pro, the hosted version by CodiumAI, provides additional benefits such as full management, improved privacy, priority support, and extra features.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).
Topu-ai
TOPU Md is a simple WhatsApp user bot created by Topu Tech. It offers various features such as multi-device support, AI photo enhancement, downloader commands, hidden NSFW commands, logo commands, anime commands, economy menu, various games, and audio/video editor commands. Users can fork the repo, get a session ID by pairing code, and deploy on Heroku. The bot requires Node version 18.x or higher for optimal performance. Contributions to TOPU-MD are welcome, and the tool is safe for use on WhatsApp and Heroku. The tool is licensed under the MIT License and is designed to enhance the WhatsApp experience with diverse features.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.
auto-dev
AutoDev is an AI-powered coding wizard that supports multiple languages, including Java, Kotlin, JavaScript/TypeScript, Rust, Python, Golang, C/C++/OC, and more. It offers a range of features, including auto development mode, copilot mode, chat with AI, customization options, SDLC support, custom AI agent integration, and language features such as language support, extensions, and a DevIns language for AI agent development. AutoDev is designed to assist developers with tasks such as auto code generation, bug detection, code explanation, exception tracing, commit message generation, code review content generation, smart refactoring, Dockerfile generation, CI/CD config file generation, and custom shell/command generation. It also provides a built-in LLM fine-tune model and supports UnitEval for LLM result evaluation and UnitGen for code-LLM fine-tune data generation.

helicone
Helicone is an open-source observability platform designed for Language Learning Models (LLMs). It logs requests to OpenAI in a user-friendly UI, offers caching, rate limits, and retries, tracks costs and latencies, provides a playground for iterating on prompts and chat conversations, supports collaboration, and will soon have APIs for feedback and evaluation. The platform is deployed on Cloudflare and consists of services like Web (NextJs), Worker (Cloudflare Workers), Jawn (Express), Supabase, and ClickHouse. Users can interact with Helicone locally by setting up the required services and environment variables. The platform encourages contributions and provides resources for learning, documentation, and integrations.
airswap-protocols
AirSwap Protocols is a repository containing smart contracts for developers and traders on the AirSwap peer-to-peer trading network. It includes various packages for functionalities like server registry, atomic token swap, staking, rewards pool, batch token and order calls, libraries, and utils. The repository follows a branching and release process for contracts and tools, with steps for regular development process and individual package features or patches. Users can deploy and verify contracts using specific commands with network flags.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.

phoenix
Phoenix is a tool that provides MLOps and LLMOps insights at lightning speed with zero-config observability. It offers a notebook-first experience for monitoring models and LLM Applications by providing LLM Traces, LLM Evals, Embedding Analysis, RAG Analysis, and Structured Data Analysis. Users can trace through the execution of LLM Applications, evaluate generative models, explore embedding point-clouds, visualize generative application's search and retrieval process, and statistically analyze structured data. Phoenix is designed to help users troubleshoot problems related to retrieval, tool execution, relevance, toxicity, drift, and performance degradation.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.
vlmrun-cookbook
VLM Run Cookbook is a repository containing practical examples and tutorials for extracting structured data from images, videos, and documents using Vision Language Models (VLMs). It offers comprehensive Colab notebooks demonstrating real-world applications of VLM Run, with complete code and documentation for easy adaptation. The examples cover various domains such as financial documents and TV news analysis.

together-cookbook
The Together Cookbook is a collection of code and guides designed to help developers build with open source models using Together AI. The recipes provide examples on how to chain multiple LLM calls, create agents that route tasks to specialized models, run multiple LLMs in parallel, break down tasks into parallel subtasks, build agents that iteratively improve responses, perform LoRA fine-tuning and inference, fine-tune LLMs for repetition, improve summarization capabilities, fine-tune LLMs on multi-step conversations, implement retrieval-augmented generation, conduct multimodal search and conditional image generation, visualize vector embeddings, improve search results with rerankers, implement vector search with embedding models, extract structured text from images, summarize and evaluate outputs with LLMs, generate podcasts from PDF content, and get LLMs to generate knowledge graphs.
For similar tasks

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

supersonic
SuperSonic is a next-generation BI platform that integrates Chat BI (powered by LLM) and Headless BI (powered by semantic layer) paradigms. This integration ensures that Chat BI has access to the same curated and governed semantic data models as traditional BI. Furthermore, the implementation of both paradigms benefits from the integration: * Chat BI's Text2SQL gets augmented with context-retrieval from semantic models. * Headless BI's query interface gets extended with natural language API. SuperSonic provides a Chat BI interface that empowers users to query data using natural language and visualize the results with suitable charts. To enable such experience, the only thing necessary is to build logical semantic models (definition of metric/dimension/tag, along with their meaning and relationships) through a Headless BI interface. Meanwhile, SuperSonic is designed to be extensible and composable, allowing custom implementations to be added and configured with Java SPI. The integration of Chat BI and Headless BI has the potential to enhance the Text2SQL generation in two dimensions: 1. Incorporate data semantics (such as business terms, column values, etc.) into the prompt, enabling LLM to better understand the semantics and reduce hallucination. 2. Offload the generation of advanced SQL syntax (such as join, formula, etc.) from LLM to the semantic layer to reduce complexity. With these ideas in mind, we develop SuperSonic as a practical reference implementation and use it to power our real-world products. Additionally, to facilitate further development we decide to open source SuperSonic as an extensible framework.
chat-ollama
ChatOllama is an open-source chatbot based on LLMs (Large Language Models). It supports a wide range of language models, including Ollama served models, OpenAI, Azure OpenAI, and Anthropic. ChatOllama supports multiple types of chat, including free chat with LLMs and chat with LLMs based on a knowledge base. Key features of ChatOllama include Ollama models management, knowledge bases management, chat, and commercial LLMs API keys management.
ChatIDE
ChatIDE is an AI assistant that integrates with your IDE, allowing you to converse with OpenAI's ChatGPT or Anthropic's Claude within your development environment. It provides a seamless way to access AI-powered assistance while coding, enabling you to get real-time help, generate code snippets, debug errors, and brainstorm ideas without leaving your IDE.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
xiaogpt
xiaogpt is a tool that allows you to play ChatGPT and other LLMs with Xiaomi AI Speaker. It supports ChatGPT, New Bing, ChatGLM, Gemini, Doubao, and Tongyi Qianwen. You can use it to ask questions, get answers, and have conversations with AI assistants. xiaogpt is easy to use and can be set up in a few minutes. It is a great way to experience the power of AI and have fun with your Xiaomi AI Speaker.

googlegpt
GoogleGPT is a browser extension that brings the power of ChatGPT to Google Search. With GoogleGPT, you can ask ChatGPT questions and get answers directly in your search results. You can also use GoogleGPT to generate text, translate languages, and more. GoogleGPT is compatible with all major browsers, including Chrome, Firefox, Edge, and Safari.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.