Best AI tools for< Natural Language Processing Engineer >
Infographic
23 - AI tool Sites
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
NVIDIA Toronto AI Lab
The NVIDIA Toronto AI Lab is a research laboratory focused on advancing the state-of-the-art in artificial intelligence. The lab's researchers are working on a wide range of AI topics, including deep learning, machine learning, computer vision, natural language processing, and robotics.
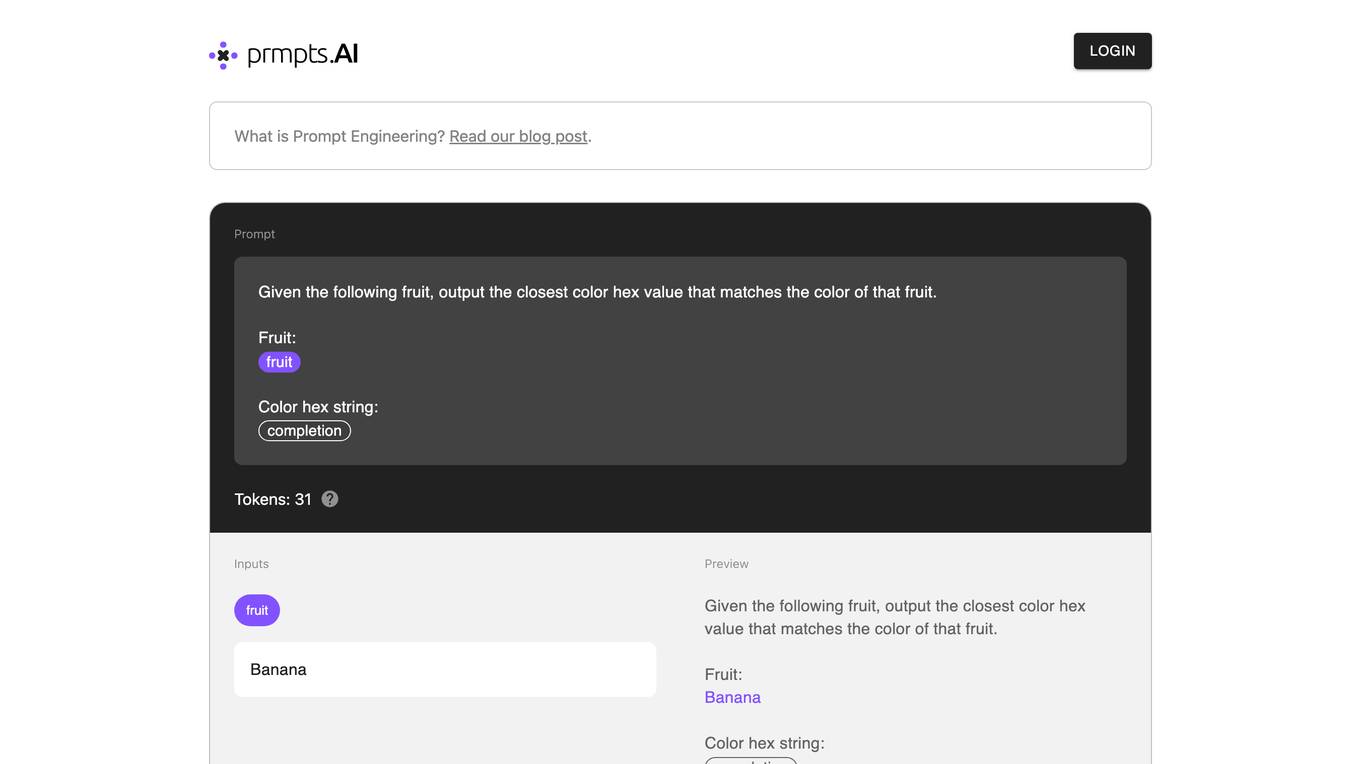
prmpts.AI
prmpts.AI is a prompt engineering sandbox that allows users to experiment with different prompts and see how they affect the output of AI models. It is a valuable tool for anyone who wants to learn more about prompt engineering or who wants to improve the performance of their AI models.
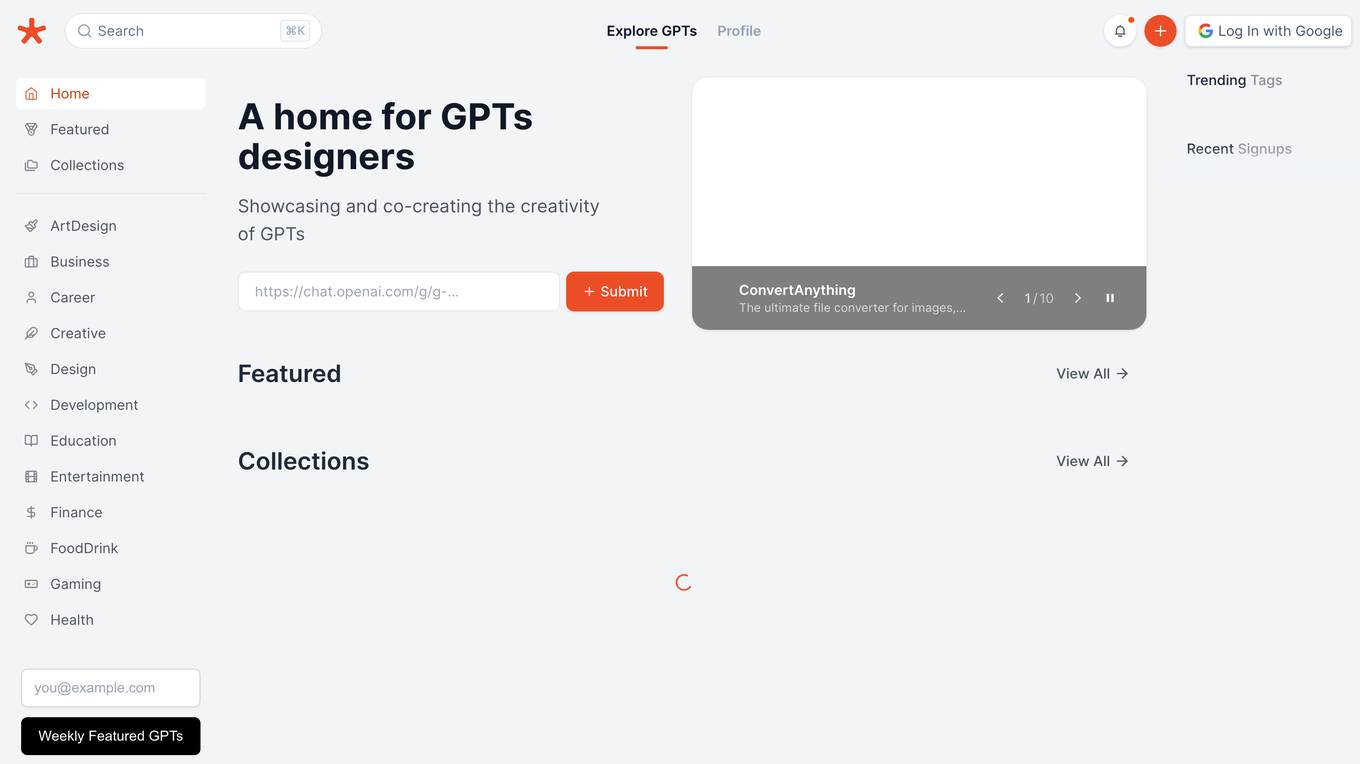
GPTs.Fan
GPTs.Fan is a comprehensive platform dedicated to GPT designers, providing a wealth of resources and support. It offers a vibrant community forum where designers can connect, share knowledge, and collaborate on projects. Additionally, GPTs.Fan features a curated collection of GPT-related tools, tutorials, and articles, empowering designers to stay up-to-date with the latest advancements in the field.

Google Gemma
Google Gemma is a lightweight, state-of-the-art open language model (LLM) developed by Google. It is part of the same research used in the creation of Google's Gemini models. Gemma models come in two sizes, the 2B and 7B parameter versions, where each has a base (pre-trained) and instruction-tuned modifications. Gemma models are designed to be cross-device compatible and optimized for Google Cloud and NVIDIA GPUs. They are also accessible through Kaggle, Hugging Face, Google Cloud with Vertex AI or GKE. Gemma models can be used for a variety of applications, including text generation, summarization, RAG, and both commercial and research use.
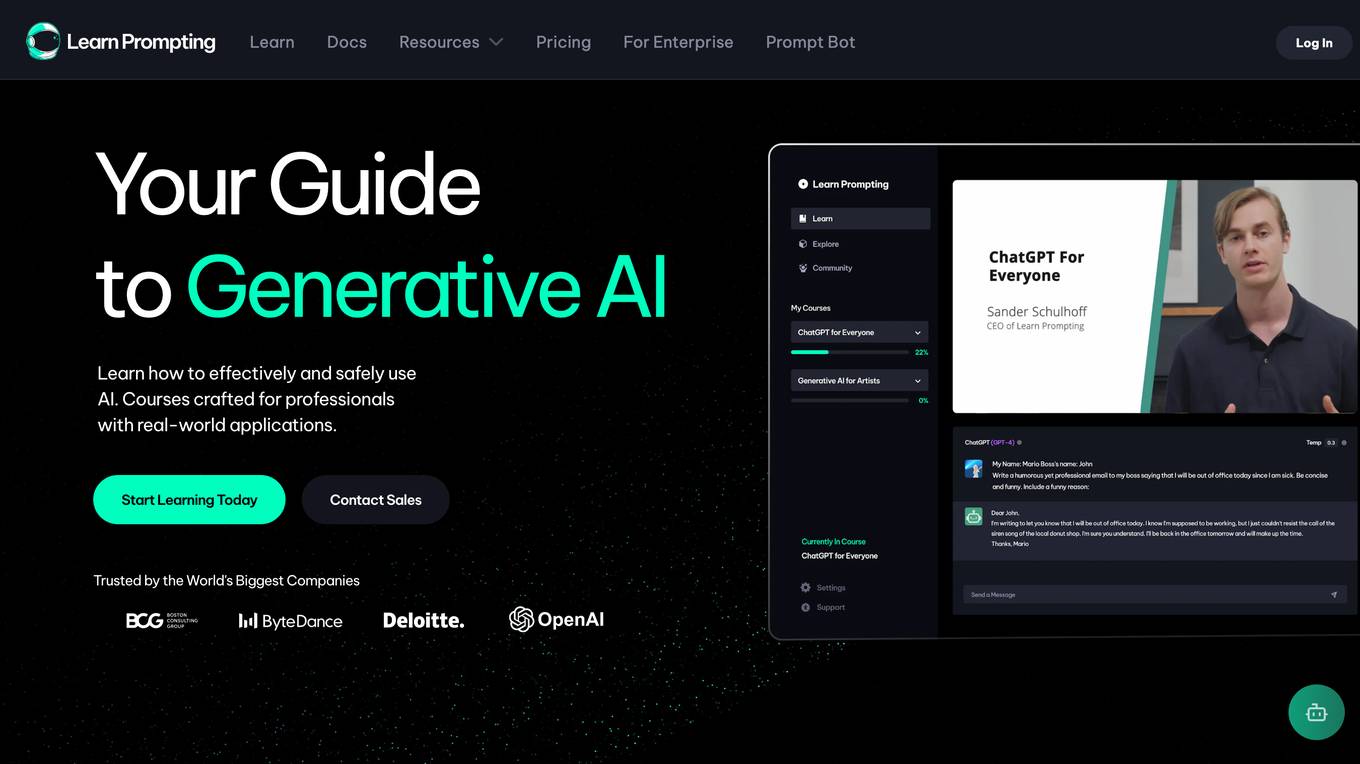
Learn Prompting
Learn Prompting is a free, open-source course that teaches you how to communicate with AI effectively and safely. It covers everything from the basics of AI communication to more advanced techniques, such as prompt engineering and gradient-based techniques. Learn Prompting also has a large Discord community of people who are interested in learning how to prompt. This makes it a great resource for anyone who wants to learn more about AI and how to use it effectively.
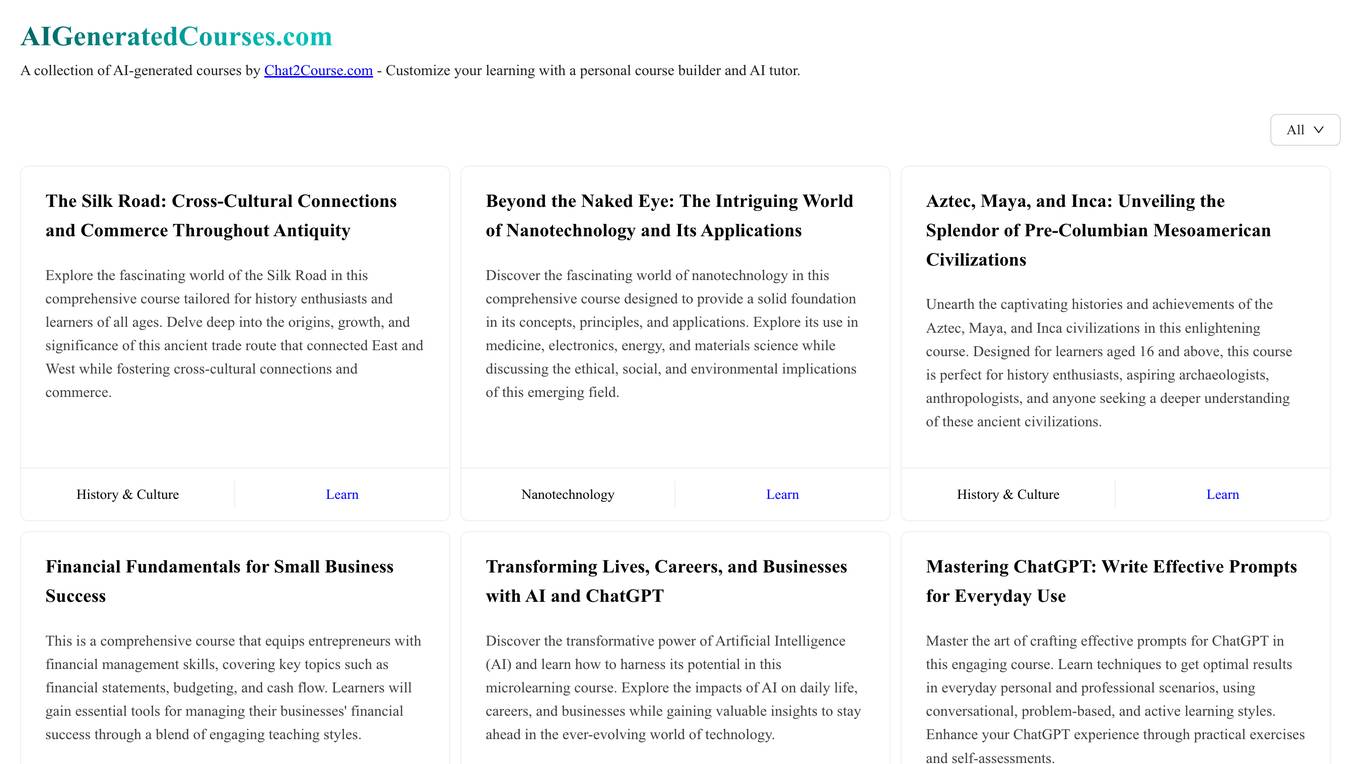
AIGeneratedCourses
AIGeneratedCourses is a collection of AI-generated courses created by Chat2Course.com. These courses are designed to help you learn about a variety of AI-related topics, including machine learning, deep learning, and natural language processing. The courses are easy to follow and are perfect for beginners who want to learn more about AI.

Human or Not
Human or Not is a social Turing game where you chat with someone for two minutes and try to figure out if it was a fellow human or an AI bot. The experiment has ended, but you can read more about the research here.
AI Jobs
AI Jobs is a curated list of the best AI jobs for developers, designers and marketers. It provides a platform for companies to post their AI-related job openings and for job seekers to find their dream AI job. The website also includes a blog with articles on the latest AI trends and technologies.
Kavaza.AI
Kavaza.AI is a platform that allows users to create and monetize their own AI companions. These companions can be used for a variety of purposes, such as customer service, education, and entertainment. Kavaza.AI provides users with the tools and resources they need to create high-quality AI companions that are both engaging and informative.
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.

Deep Learning
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The online version of the book is now complete and will remain available online for free. The deep learning textbook can now be ordered on Amazon. For up to date announcements, join our mailing list.

Artificial Intelligence: A Modern Approach, 4th US ed.
Artificial Intelligence: A Modern Approach, 4th US ed. is the authoritative, most-used AI textbook, adopted by over 1500 schools. It covers the entire spectrum of AI, from the fundamentals to the latest advances. The book is written in a clear and concise style, with a wealth of examples and exercises. It is suitable for both undergraduate and graduate students, as well as professionals in the field of AI.
Innovatiana
Innovatiana is a data labeling outsourcing company that provides high-quality training data for AI models. They specialize in computer vision, data moderation, document processing, natural language processing, and data collection. Innovatiana is committed to ethical and sustainable practices, and they pay their data labelers fair wages and provide them with good working conditions. They also use a variety of quality control measures to ensure that their data is accurate and reliable.
Amazon Science
Amazon Science is a research and development organization within Amazon that focuses on developing new technologies and products in the fields of artificial intelligence, machine learning, and computer science. The organization is home to a team of world-renowned scientists and engineers who are working on a wide range of projects, including developing new algorithms for machine learning, building new computer vision systems, and creating new natural language processing tools. Amazon Science is also responsible for developing new products and services that use these technologies, such as the Amazon Echo and the Amazon Fire TV.

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.

Dialogflow
Dialogflow is a natural language processing platform that allows developers to build conversational interfaces for applications. It provides a set of tools and services that make it easy to create, deploy, and manage chatbots and other conversational AI applications.
Undressing AI
Undressing AI is a website that provides information about artificial intelligence (AI) and its potential impact on society. The site includes articles, videos, and other resources on topics such as the history of AI, the different types of AI, and the ethical implications of AI.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.

Anthropic
Anthropic is a research and deployment company founded in 2021 by former OpenAI researchers Dario Amodei, Daniela Amodei, and Geoffrey Irving. The company is developing large language models, including Claude, a multimodal AI model that can perform a variety of language-related tasks, such as answering questions, generating text, and translating languages.
SoundHound
SoundHound is a leading innovator of conversational intelligence and voice AI technologies. Our independent voice AI platform is built for more natural conversation, enabling businesses to create customized and scalable voice AI solutions for their specific industries and use cases. With SoundHound, you can build voice assistants, enhance smart devices, improve customer experiences, and drive business value.
Clarifai
Clarifai is a full-stack AI platform that provides developers and ML engineers with the fastest, production-grade deep learning platform. It offers a wide range of features, including data preparation, model building, model operationalization, and AI workflows. Clarifai is used by a variety of companies, including Fortune 500 companies and startups, to build AI applications in a variety of industries, including retail, manufacturing, and healthcare.
253 - Open Source Tools

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.
TypeChat
TypeChat is a library that simplifies the creation of natural language interfaces using types. Traditionally, building natural language interfaces has been challenging, often relying on complex decision trees to determine intent and gather necessary inputs for action. Large language models (LLMs) have simplified this process by allowing us to accept natural language input from users and match it to intent. However, this has introduced new challenges, such as the need to constrain the model's response for safety, structure responses from the model for further processing, and ensure the validity of the model's response. Prompt engineering aims to address these issues, but it comes with a steep learning curve and increased fragility as the prompt grows in size.
langfun
Langfun is a Python library that aims to make language models (LM) fun to work with. It enables a programming model that flows naturally, resembling the human thought process. Langfun emphasizes the reuse and combination of language pieces to form prompts, thereby accelerating innovation. Unlike other LM frameworks, which feed program-generated data into the LM, langfun takes a distinct approach: It starts with natural language, allowing for seamless interactions between language and program logic, and concludes with natural language and optional structured output. Consequently, langfun can aptly be described as Language as functions, capturing the core of its methodology.

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

botpress
Botpress is a platform for building next-generation chatbots and assistants powered by OpenAI. It provides a range of tools and integrations to help developers quickly and easily create and deploy chatbots for various use cases.

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.
langchaingo
LangChain Go is a Go language implementation of LangChain, a framework for building applications with LLMs through composability. It provides a simple and easy-to-use API for interacting with LLMs, making it easy to add language-based features to your applications.
llm-universe
This project is a tutorial on developing large model applications for novice developers. It aims to provide a comprehensive introduction to large model development, focusing on Alibaba Cloud servers and integrating personal knowledge assistant projects. The tutorial covers the following topics: 1. **Introduction to Large Models**: A simplified introduction for novice developers on what large models are, their characteristics, what LangChain is, and how to develop an LLM application. 2. **How to Call Large Model APIs**: This section introduces various methods for calling APIs of well-known domestic and foreign large model products, including calling native APIs, encapsulating them as LangChain LLMs, and encapsulating them as Fastapi calls. It also provides a unified encapsulation for various large model APIs, such as Baidu Wenxin, Xunfei Xinghuo, and Zh譜AI. 3. **Knowledge Base Construction**: Loading, processing, and vector database construction of different types of knowledge base documents. 4. **Building RAG Applications**: Integrating LLM into LangChain to build a retrieval question and answer chain, and deploying applications using Streamlit. 5. **Verification and Iteration**: How to implement verification and iteration in large model development, and common evaluation methods. The project consists of three main parts: 1. **Introduction to LLM Development**: A simplified version of V1 aims to help beginners get started with LLM development quickly and conveniently, understand the general process of LLM development, and build a simple demo. 2. **LLM Development Techniques**: More advanced LLM development techniques, including but not limited to: Prompt Engineering, processing of multiple types of source data, optimizing retrieval, recall ranking, Agent framework, etc. 3. **LLM Application Examples**: Introduce some successful open source cases, analyze the ideas, core concepts, and implementation frameworks of these application examples from the perspective of this course, and help beginners understand what kind of applications they can develop through LLM. Currently, the first part has been completed, and everyone is welcome to read and learn; the second and third parts are under creation. **Directory Structure Description**: requirements.txt: Installation dependencies in the official environment notebook: Notebook source code file docs: Markdown documentation file figures: Pictures data_base: Knowledge base source file used

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.
Pathway-AI-Bootcamp
Welcome to the μLearn x Pathway Initiative, an exciting adventure into the world of Artificial Intelligence (AI)! This comprehensive course, developed in collaboration with Pathway, will empower you with the knowledge and skills needed to navigate the fascinating world of AI, with a special focus on Large Language Models (LLMs).
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.
Agently
Agently is a development framework that helps developers build AI agent native application really fast. You can use and build AI agent in your code in an extremely simple way. You can create an AI agent instance then interact with it like calling a function in very few codes like this below. Click the run button below and witness the magic. It's just that simple: python # Import and Init Settings import Agently agent = Agently.create_agent() agent\ .set_settings("current_model", "OpenAI")\ .set_settings("model.OpenAI.auth", {"api_key": ""}) # Interact with the agent instance like calling a function result = agent\ .input("Give me 3 words")\ .output([("String", "one word")])\ .start() print(result) ['apple', 'banana', 'carrot'] And you may notice that when we print the value of `result`, the value is a `list` just like the format of parameter we put into the `.output()`. In Agently framework we've done a lot of work like this to make it easier for application developers to integrate Agent instances into their business code. This will allow application developers to focus on how to build their business logic instead of figure out how to cater to language models or how to keep models satisfied.
core
The Cheshire Cat is a framework for building custom AIs on top of any language model. It provides an API-first approach, making it easy to add a conversational layer to your application. The Cat remembers conversations and documents, and uses them in conversation. It is extensible via plugins, and supports event callbacks, function calling, and conversational forms. The Cat is easy to use, with an admin panel that allows you to chat with the AI, visualize memory and plugins, and adjust settings. It is also production-ready, 100% dockerized, and supports any language model.
soul-engine
OPEN SOULS offers developers clean, simple, and extensible abstractions for directing the cognitive processes of large language models (LLMs), streamlining the creation of more effective and engaging AI souls. This repo is the public, monorepo hosting our open source core, our command line tool, and code for interacting with the hosted Soul Engine. AI Souls are agentic and embodied digital beings, one day comprising thousands of mental processes (managed by the Soul Engine). Unlike traditional chatbots, this code will give digital souls personality, drive, ego, and will.
json_repair
This simple package can be used to fix an invalid json string. To know all cases in which this package will work, check out the unit test. Inspired by https://github.com/josdejong/jsonrepair Motivation Some LLMs are a bit iffy when it comes to returning well formed JSON data, sometimes they skip a parentheses and sometimes they add some words in it, because that's what an LLM does. Luckily, the mistakes LLMs make are simple enough to be fixed without destroying the content. I searched for a lightweight python package that was able to reliably fix this problem but couldn't find any. So I wrote one How to use from json_repair import repair_json good_json_string = repair_json(bad_json_string) # If the string was super broken this will return an empty string You can use this library to completely replace `json.loads()`: import json_repair decoded_object = json_repair.loads(json_string) or just import json_repair decoded_object = json_repair.repair_json(json_string, return_objects=True) Read json from a file or file descriptor JSON repair provides also a drop-in replacement for `json.load()`: import json_repair try: file_descriptor = open(fname, 'rb') except OSError: ... with file_descriptor: decoded_object = json_repair.load(file_descriptor) and another method to read from a file: import json_repair try: decoded_object = json_repair.from_file(json_file) except OSError: ... except IOError: ... Keep in mind that the library will not catch any IO-related exception and those will need to be managed by you Performance considerations If you find this library too slow because is using `json.loads()` you can skip that by passing `skip_json_loads=True` to `repair_json`. Like: from json_repair import repair_json good_json_string = repair_json(bad_json_string, skip_json_loads=True) I made a choice of not using any fast json library to avoid having any external dependency, so that anybody can use it regardless of their stack. Some rules of thumb to use: - Setting `return_objects=True` will always be faster because the parser returns an object already and it doesn't have serialize that object to JSON - `skip_json_loads` is faster only if you 100% know that the string is not a valid JSON - If you are having issues with escaping pass the string as **raw** string like: `r"string with escaping\"" Adding to requirements Please pin this library only on the major version! We use TDD and strict semantic versioning, there will be frequent updates and no breaking changes in minor and patch versions. To ensure that you only pin the major version of this library in your `requirements.txt`, specify the package name followed by the major version and a wildcard for minor and patch versions. For example: json_repair==0.* In this example, any version that starts with `0.` will be acceptable, allowing for updates on minor and patch versions. How it works This module will parse the JSON file following the BNF definition:
SiLLM
SiLLM is a toolkit that simplifies the process of training and running Large Language Models (LLMs) on Apple Silicon by leveraging the MLX framework. It provides features such as LLM loading, LoRA training, DPO training, a web app for a seamless chat experience, an API server with OpenAI compatible chat endpoints, and command-line interface (CLI) scripts for chat, server, LoRA fine-tuning, DPO fine-tuning, conversion, and quantization.

lagent
Lagent is a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents. It also provides some typical tools to augment LLM. The overview of our framework is shown below:

RecAI
RecAI is a project that explores the integration of Large Language Models (LLMs) into recommender systems, addressing the challenges of interactivity, explainability, and controllability. It aims to bridge the gap between general-purpose LLMs and domain-specific recommender systems, providing a holistic perspective on the practical requirements of LLM4Rec. The project investigates various techniques, including Recommender AI agents, selective knowledge injection, fine-tuning language models, evaluation, and LLMs as model explainers, to create more sophisticated, interactive, and user-centric recommender systems.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.
Play-with-LLMs
This repository provides a comprehensive guide to training, evaluating, and building applications with Large Language Models (LLMs). It covers various aspects of LLMs, including pretraining, fine-tuning, reinforcement learning from human feedback (RLHF), and more. The repository also includes practical examples and code snippets to help users get started with LLMs quickly and easily.
Large-Language-Models
Large Language Models (LLM) are used to browse the Wolfram directory and associated URLs to create the category structure and good word embeddings. The goal is to generate enriched prompts for GPT, Wikipedia, Arxiv, Google Scholar, Stack Exchange, or Google search. The focus is on one subdirectory: Probability & Statistics. Documentation is in the project textbook `Projects4.pdf`, which is available in the folder. It is recommended to download the document and browse your local copy with Chrome, Edge, or other viewers. Unlike on GitHub, you will be able to click on all the links and follow the internal navigation features. Look for projects related to NLP and LLM / xLLM. The best starting point is project 7.2.2, which is the core project on this topic, with references to all satellite projects. The project textbook (with solutions to all projects) is the core document needed to participate in the free course (deep tech dive) called **GenAI Fellowship**. For details about the fellowship, follow the link provided. An uncompressed version of `crawl_final_stats.txt.gz` is available on Google drive, which contains all the crawled data needed as input to the Python scripts in the XLLM5 and XLLM6 folders.
Weekly-Top-LLM-Papers
This repository provides a curated list of weekly published Large Language Model (LLM) papers. It includes top important LLM papers for each week, organized by month and year. The papers are categorized into different time periods, making it easy to find the most recent and relevant research in the field of LLM.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.
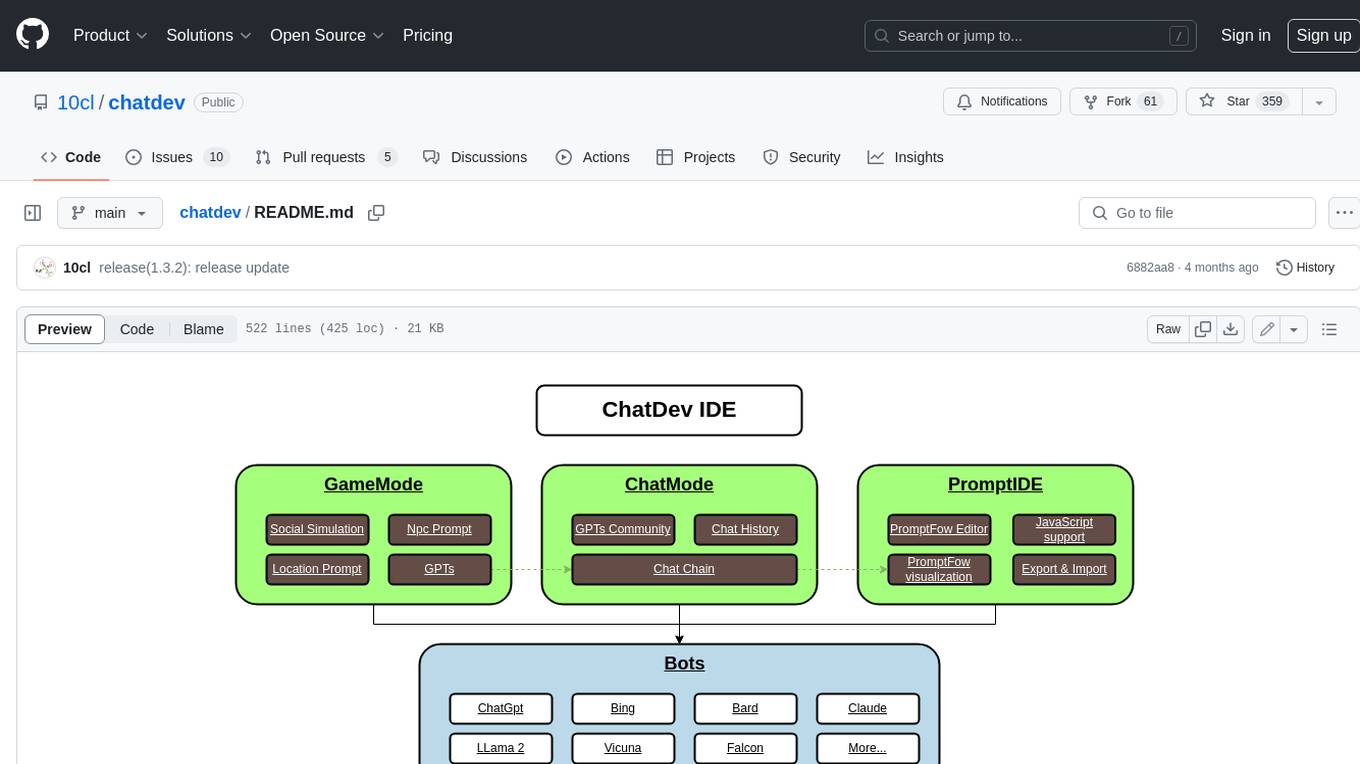
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.
ai-deadlines
Countdown timers to keep track of a bunch of CV/NLP/ML/RO conference deadlines.
emeltal
Emeltal is a local ML voice chat tool that uses high-end models to provide a self-contained, user-friendly out-of-the-box experience. It offers a hand-picked list of proven open-source high-performance models, aiming to provide the best model for each category/size combination. Emeltal heavily relies on the llama.cpp for LLM processing, and whisper.cpp for voice recognition. Text rendering uses Ink to convert between Markdown and HTML. It uses PopTimer for debouncing things. Emeltal is released under the terms of the MIT license, and all model data which is downloaded locally by the app comes from HuggingFace, and use of the models and data is subject to the respective license of each specific model.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.
LLMs-from-scratch
This repository contains the code for coding, pretraining, and finetuning a GPT-like LLM and is the official code repository for the book Build a Large Language Model (From Scratch). In _Build a Large Language Model (From Scratch)_, you'll discover how LLMs work from the inside out. In this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples. The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT.
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.
funcchain
Funcchain is a Python library that allows you to easily write cognitive systems by leveraging Pydantic models as output schemas and LangChain in the backend. It provides a seamless integration of LLMs into your apps, utilizing OpenAI Functions or LlamaCpp grammars (json-schema-mode) for efficient structured output. Funcchain compiles the Funcchain syntax into LangChain runnables, enabling you to invoke, stream, or batch process your pipelines effortlessly.

sailor-llm
Sailor is a suite of open language models tailored for South-East Asia (SEA), focusing on languages such as Indonesian, Thai, Vietnamese, Malay, and Lao. Developed with careful data curation, Sailor models are designed to understand and generate text across diverse linguistic landscapes of the SEA region. Built from Qwen 1.5, Sailor encompasses models of varying sizes, spanning from 0.5B to 7B versions for different requirements. Benchmarking results demonstrate Sailor's proficiency in tasks such as question answering, commonsense reasoning, reading comprehension, and more in SEA languages.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.
quarkus-langchain4j
This repository contains Quarkus extensions that facilitate seamless integration between Quarkus and LangChain4j, enabling easy incorporation of Large Language Models (LLMs) into your Quarkus applications. Here is a non-exhaustive list of features that are currently supported: Declarative AI services, Integration with diverse LLMs (OpenAI GPTs, Hugging Faces, Ollama...), Tool support, Embedding support, Document store integration (Redis, Chroma, Infinispan...), Native compilation support, Integration with Quarkus observability stack (metrics, tracing...).

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
llm-python
A set of instructional materials, code samples and Python scripts featuring LLMs (GPT etc) through interfaces like llamaindex, langchain, Chroma (Chromadb), Pinecone etc. Mainly used to store reference code for my LangChain tutorials on YouTube.

llms-from-scratch-cn
This repository provides a detailed tutorial on how to build your own large language model (LLM) from scratch. It includes all the code necessary to create a GPT-like LLM, covering the encoding, pre-training, and fine-tuning processes. The tutorial is written in a clear and concise style, with plenty of examples and illustrations to help you understand the concepts involved. It is suitable for developers and researchers with some programming experience who are interested in learning more about LLMs and how to build them.
zep
Zep is a long-term memory service for AI Assistant apps. With Zep, you can provide AI assistants with the ability to recall past conversations, no matter how distant, while also reducing hallucinations, latency, and cost. Zep persists and recalls chat histories, and automatically generates summaries and other artifacts from these chat histories. It also embeds messages and summaries, enabling you to search Zep for relevant context from past conversations. Zep does all of this asyncronously, ensuring these operations don't impact your user's chat experience. Data is persisted to database, allowing you to scale out when growth demands. Zep also provides a simple, easy to use abstraction for document vector search called Document Collections. This is designed to complement Zep's core memory features, but is not designed to be a general purpose vector database. Zep allows you to be more intentional about constructing your prompt: 1. automatically adding a few recent messages, with the number customized for your app; 2. a summary of recent conversations prior to the messages above; 3. and/or contextually relevant summaries or messages surfaced from the entire chat session. 4. and/or relevant Business data from Zep Document Collections.
ai_all_resources
This repository is a compilation of excellent ML and DL tutorials created by various individuals and organizations. It covers a wide range of topics, including machine learning fundamentals, deep learning, computer vision, natural language processing, reinforcement learning, and more. The resources are organized into categories, making it easy to find the information you need. Whether you're a beginner or an experienced practitioner, you're sure to find something valuable in this repository.
llm-hosting-container
The LLM Hosting Container repository provides Dockerfile and associated resources for building and hosting containers for large language models, specifically the HuggingFace Text Generation Inference (TGI) container. This tool allows users to easily deploy and manage large language models in a containerized environment, enabling efficient inference and deployment of language-based applications.
LLM-Workshop
This repository contains a collection of resources for learning about and using Large Language Models (LLMs). The resources include tutorials, code examples, and links to additional resources. LLMs are a type of artificial intelligence that can understand and generate human-like text. They have a wide range of potential applications, including natural language processing, machine translation, and chatbot development.
Paper-Reading-ConvAI
Paper-Reading-ConvAI is a repository that contains a list of papers, datasets, and resources related to Conversational AI, mainly encompassing dialogue systems and natural language generation. This repository is constantly updating.
pyAIML
PyAIML is a Python implementation of the AIML (Artificial Intelligence Markup Language) interpreter. It aims to be a simple, standards-compliant interpreter for AIML 1.0.1. PyAIML is currently in pre-alpha development, so use it at your own risk. For more information on PyAIML, see the CHANGES.txt and SUPPORTED_TAGS.txt files.

nlux
nlux is an open-source Javascript and React JS library that makes it super simple to integrate powerful large language models (LLMs) like ChatGPT into your web app or website. With just a few lines of code, you can add conversational AI capabilities and interact with your favourite LLM.

spacy-llm
This package integrates Large Language Models (LLMs) into spaCy, featuring a modular system for **fast prototyping** and **prompting** , and turning unstructured responses into **robust outputs** for various NLP tasks, **no training data** required. It supports open-source LLMs hosted on Hugging Face 🤗: Falcon, Dolly, Llama 2, OpenLLaMA, StableLM, Mistral. Integration with LangChain 🦜️🔗 - all `langchain` models and features can be used in `spacy-llm`. Tasks available out of the box: Named Entity Recognition, Text classification, Lemmatization, Relationship extraction, Sentiment analysis, Span categorization, Summarization, Entity linking, Translation, Raw prompt execution for maximum flexibility. Soon: Semantic role labeling. Easy implementation of **your own functions** via spaCy's registry for custom prompting, parsing and model integrations. For an example, see here. Map-reduce approach for splitting prompts too long for LLM's context window and fusing the results back together
generative-ai-go
The Google AI Go SDK enables developers to use Google's state-of-the-art generative AI models (like Gemini) to build AI-powered features and applications. It supports use cases like generating text from text-only input, generating text from text-and-images input (multimodal), building multi-turn conversations (chat), and embedding.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.
module-ballerinax-ai.agent
This library provides functionality required to build ReAct Agent using Large Language Models (LLMs).
promptbuddy
Prompt Buddy is a Microsoft Teams app that provides a central location for teams to share and discover their favorite AI prompts. It comes preloaded with Microsoft Copilot and other categories, but users can also add their own custom prompts. The app is easy to use and allows users to upvote their favorite prompts, which raises them to the top of the leaderboard. Prompt Buddy also supports dark mode and offers a mobile layout for use on phones. It is built on the Power Platform and can be customized and extended by the installer.

client-js
The Mistral JavaScript client is a library that allows you to interact with the Mistral AI API. With this client, you can perform various tasks such as listing models, chatting with streaming, chatting without streaming, and generating embeddings. To use the client, you can install it in your project using npm and then set up the client with your API key. Once the client is set up, you can use it to perform the desired tasks. For example, you can use the client to chat with a model by providing a list of messages. The client will then return the response from the model. You can also use the client to generate embeddings for a given input. The embeddings can then be used for various downstream tasks such as clustering or classification.
mlx-llm
mlx-llm is a library that allows you to run Large Language Models (LLMs) on Apple Silicon devices in real-time using Apple's MLX framework. It provides a simple and easy-to-use API for creating, loading, and using LLM models, as well as a variety of applications such as chatbots, fine-tuning, and retrieval-augmented generation.
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.
LLPhant
LLPhant is a comprehensive PHP Generative AI Framework that provides a simple and powerful way to build apps. It supports Symfony and Laravel and offers a wide range of features, including text generation, chatbots, text summarization, and more. LLPhant is compatible with OpenAI and Ollama and can be used to perform a variety of tasks, including creating semantic search, chatbots, personalized content, and text summarization.

rivet
Rivet is a desktop application for creating complex AI agents and prompt chaining, and embedding it in your application. Rivet currently has LLM support for OpenAI GPT-3.5 and GPT-4, Anthropic Claude Instant and Claude 2, [Anthropic Claude 3 Haiku, Sonnet, and Opus](https://www.anthropic.com/news/claude-3-family), and AssemblyAI LeMUR framework for voice data. Rivet has embedding/vector database support for OpenAI Embeddings and Pinecone. Rivet also supports these additional integrations: Audio Transcription from AssemblyAI. Rivet core is a TypeScript library for running graphs created in Rivet. It is used by the Rivet application, but can also be used in your own applications, so that Rivet can call into your own application's code, and your application can call into Rivet graphs.

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.
AiLearning-Theory-Applying
This repository provides a comprehensive guide to understanding and applying artificial intelligence (AI) theory, including basic knowledge, machine learning, deep learning, and natural language processing (BERT). It features detailed explanations, annotated code, and datasets to help users grasp the concepts and implement them in practice. The repository is continuously updated to ensure the latest information and best practices are covered.
awesome-hallucination-detection
This repository provides a curated list of papers, datasets, and resources related to the detection and mitigation of hallucinations in large language models (LLMs). Hallucinations refer to the generation of factually incorrect or nonsensical text by LLMs, which can be a significant challenge for their use in real-world applications. The resources in this repository aim to help researchers and practitioners better understand and address this issue.
LLM-Tuning
LLM-Tuning is a collection of tools and resources for fine-tuning large language models (LLMs). It includes a library of pre-trained LoRA models, a set of tutorials and examples, and a community forum for discussion and support. LLM-Tuning makes it easy to fine-tune LLMs for a variety of tasks, including text classification, question answering, and dialogue generation. With LLM-Tuning, you can quickly and easily improve the performance of your LLMs on downstream tasks.
LLM.swift
LLM.swift is a simple and readable library that allows you to interact with large language models locally with ease for macOS, iOS, watchOS, tvOS, and visionOS. It's a lightweight abstraction layer over `llama.cpp` package, so that it stays as performant as possible while is always up to date. Theoretically, any model that works on `llama.cpp` should work with this library as well. It's only a single file library, so you can copy, study and modify the code however you want.

kor
Kor is a prototype tool designed to help users extract structured data from text using Language Models (LLMs). It generates prompts, sends them to specified LLMs, and parses the output. The tool works with the parsing approach and is integrated with the LangChain framework. Kor is compatible with pydantic v2 and v1, and schema is typed checked using pydantic. It is primarily used for extracting information from text based on provided reference examples and schema documentation. Kor is designed to work with all good-enough LLMs regardless of their support for function/tool calling or JSON modes.

instructor-php
Instructor for PHP is a library designed for structured data extraction in PHP, powered by Large Language Models (LLMs). It simplifies the process of extracting structured, validated data from unstructured text or chat sequences. Instructor enhances workflow by providing a response model, validation capabilities, and max retries for requests. It supports classes as response models and provides features like partial results, string input, extracting scalar and enum values, and specifying data models using PHP type hints or DocBlock comments. The library allows customization of validation and provides detailed event notifications during request processing. Instructor is compatible with PHP 8.2+ and leverages PHP reflection, Symfony components, and SaloonPHP for communication with LLM API providers.

llm_qlora
LLM_QLoRA is a repository for fine-tuning Large Language Models (LLMs) using QLoRA methodology. It provides scripts for training LLMs on custom datasets, pushing models to HuggingFace Hub, and performing inference. Additionally, it includes models trained on HuggingFace Hub, a blog post detailing the QLoRA fine-tuning process, and instructions for converting and quantizing models. The repository also addresses troubleshooting issues related to Python versions and dependencies.
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.
awesome-local-llms
The 'awesome-local-llms' repository is a curated list of open-source tools for local Large Language Model (LLM) inference, covering both proprietary and open weights LLMs. The repository categorizes these tools into LLM inference backend engines, LLM front end UIs, and all-in-one desktop applications. It collects GitHub repository metrics as proxies for popularity and active maintenance. Contributions are encouraged, and users can suggest additional open-source repositories through the Issues section or by running a provided script to update the README and make a pull request. The repository aims to provide a comprehensive resource for exploring and utilizing local LLM tools.
fairseq
Fairseq is a sequence modeling toolkit that enables researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. It provides reference implementations of various sequence modeling papers covering CNN, LSTM networks, Transformer networks, LightConv, DynamicConv models, Non-autoregressive Transformers, Finetuning, and more. The toolkit supports multi-GPU training, fast generation on CPU and GPU, mixed precision training, extensibility, flexible configuration based on Hydra, and full parameter and optimizer state sharding. Pre-trained models are available for translation and language modeling with a torch.hub interface. Fairseq also offers pre-trained models and examples for tasks like XLS-R, cross-lingual retrieval, wav2vec 2.0, unsupervised quality estimation, and more.
enhance_llm
The enhance_llm repository contains three main parts: 1. Vector model domain fine-tuning based on llama_index and qwen fine-tuning BGE vector model. 2. Large model domain fine-tuning based on PEFT fine-tuning qwen1.5-7b-chat, with sft and dpo. 3. High-order retrieval enhanced generation (RAG) system based on the above domain work, implementing a two-stage RAG system. It includes query rewriting, recall reordering, retrieval reordering, multi-turn dialogue, and more. The repository also provides hardware and environment configurations along with star history and licensing information.
langchain4j-aideepin
LangChain4j-AIDeepin is an open-source, offline deployable retrieval enhancement generation (RAG) project based on large language models such as ChatGPT and Langchain4j application framework. It offers features like registration & login, multi-session support, image generation, prompt words, quota control, knowledge base, model-based search, model switching, and search engine switching. The project integrates models like ChatGPT 3.5, Tongyi Qianwen, Wenxin Yiyuan, Ollama, and DALL-E 2. The backend uses technologies like JDK 17, Spring Boot 3.0.5, Langchain4j, and PostgreSQL with pgvector extension, while the frontend is built with Vue3, TypeScript, and PNPM.
instruct-ner
Instruct NER is a solution for complex Named Entity Recognition tasks, including Nested NER, based on modern Large Language Models (LLMs). It provides tools for dataset creation, training, automatic metric calculation, inference, error analysis, and model implementation. Users can create instructions for LLM, build dictionaries with labels, and generate model input templates. The tool supports various entity types and datasets, such as RuDReC, NEREL-BIO, CoNLL-2003, and MultiCoNER II. It offers training scripts for LLMs and metric calculation functions. Instruct NER models like Llama, Mistral, T5, and RWKV are implemented, with HuggingFace models available for adaptation and merging.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

co-llm
Co-LLM (Collaborative Language Models) is a tool for learning to decode collaboratively with multiple language models. It provides a method for data processing, training, and inference using a collaborative approach. The tool involves steps such as formatting/tokenization, scoring logits, initializing Z vector, deferral training, and generating results using multiple models. Co-LLM supports training with different collaboration pairs and provides baseline training scripts for various models. In inference, it uses 'vllm' services to orchestrate models and generate results through API-like services. The tool is inspired by allenai/open-instruct and aims to improve decoding performance through collaborative learning.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
amber-data-prep
This repository contains the code to prepare the data for the Amber 7B language model. The final training data comes from three sources: RedPajama V1, RefinedWeb, and StarCoderData. The data preparation involves downloading untokenized data, tokenizing the data using the Huggingface tokenizer, concatenating tokens into 2048 token sequences, merging datasets, and splitting the merged dataset into 360 chunks. Each tokenized data chunk is a jsonl file containing samples with 2049 tokens. The repository provides scripts for downloading datasets, tokenizing and concatenating sequences, validating data, and merging subsets into chunks.
SmallLanguageModel-project
This repository provides all the necessary items to build a Language Model from scratch, inspired by Karpathy's nanoGPT and Shakespeare generator. It includes data collection tools, data processing scripts, various models like BERT, GPT, and Seq-2-Seq, along with tokenizer and training files.

Chinese-Tiny-LLM
Chinese-Tiny-LLM is a repository containing procedures for cleaning Chinese web corpora and pre-training code. It introduces CT-LLM, a 2B parameter language model focused on the Chinese language. The model primarily uses Chinese data from a 1,200 billion token corpus, showing excellent performance in Chinese language tasks. The repository includes tools for filtering, deduplication, and pre-training, aiming to encourage further research and innovation in language model development.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.
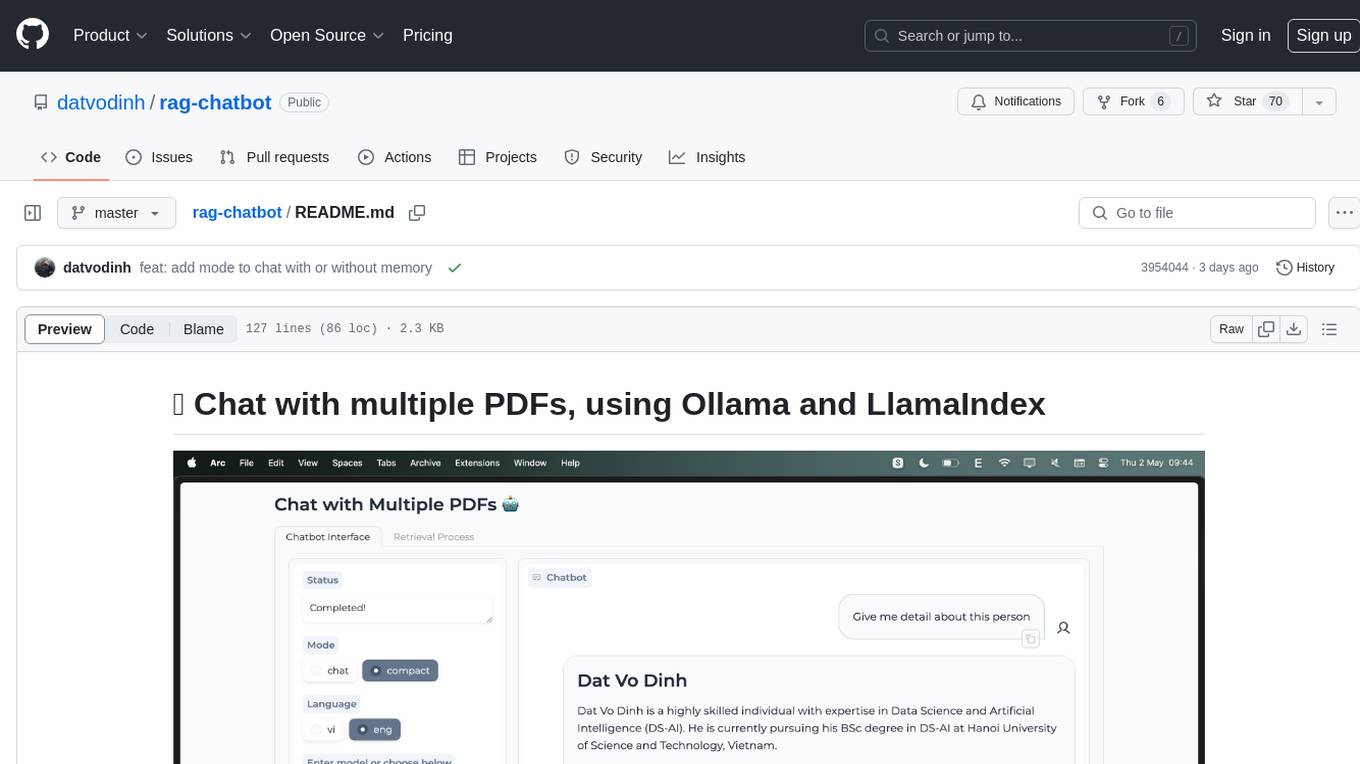
rag-chatbot
rag-chatbot is a tool that allows users to chat with multiple PDFs using Ollama and LlamaIndex. It provides an easy setup for running on local machines or Kaggle notebooks. Users can leverage models from Huggingface and Ollama, process multiple PDF inputs, and chat in multiple languages. The tool offers a simple UI with Gradio, supporting chat with history and QA modes. Setup instructions are provided for both Kaggle and local environments, including installation steps for Docker, Ollama, Ngrok, and the rag_chatbot package. Users can run the tool locally and access it via a web interface. Future enhancements include adding evaluation, better embedding models, knowledge graph support, improved document processing, MLX model integration, and Corrective RAG.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.
LLM4IR-Survey
LLM4IR-Survey is a collection of papers related to large language models for information retrieval, organized according to the survey paper 'Large Language Models for Information Retrieval: A Survey'. It covers various aspects such as query rewriting, retrievers, rerankers, readers, search agents, and more, providing insights into the integration of large language models with information retrieval systems.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.
llm-search
pyLLMSearch is an advanced RAG system that offers a convenient question-answering system with a simple YAML-based configuration. It enables interaction with multiple collections of local documents, with improvements in document parsing, hybrid search, chat history, deep linking, re-ranking, customizable embeddings, and more. The package is designed to work with custom Large Language Models (LLMs) from OpenAI or installed locally. It supports various document formats, incremental embedding updates, dense and sparse embeddings, multiple embedding models, 'Retrieve and Re-rank' strategy, HyDE (Hypothetical Document Embeddings), multi-querying, chat history, and interaction with embedded documents using different models. It also offers simple CLI and web interfaces, deep linking, offline response saving, and an experimental API.
SemanticKernel.Assistants
This repository contains an assistant proposal for the Semantic Kernel, allowing the usage of assistants without relying on OpenAI Assistant APIs. It runs locally planners and plugins for the assistants, providing scenarios like Assistant with Semantic Kernel plugins, Multi-Assistant conversation, and AutoGen conversation. The Semantic Kernel is a lightweight SDK enabling integration of AI Large Language Models with conventional programming languages, offering functions like semantic functions, native functions, and embeddings-based memory. Users can bring their own model for the assistants and host them locally. The repository includes installation instructions, usage examples, and information on creating new conversation threads with the assistant.
SPAG
This repository contains the implementation of Self-Play of Adversarial Language Game (SPAG) as described in the paper 'Self-playing Adversarial Language Game Enhances LLM Reasoning'. The SPAG involves training Language Models (LLMs) in an adversarial language game called Adversarial Taboo. The repository provides tools for imitation learning, self-play episode collection, and reinforcement learning on game episodes to enhance LLM reasoning abilities. The process involves training models using GPUs, launching imitation learning, conducting self-play episodes, assigning rewards based on outcomes, and learning the SPAG model through reinforcement learning. Continuous improvements on reasoning benchmarks can be observed by repeating the episode-collection and SPAG-learning processes.
autolabel
Autolabel is a Python library designed to label, clean, and enrich text datasets using Large Language Models (LLMs). It provides a simple 3-step process for labeling data, supports various NLP tasks, and offers features like confidence estimation, explanations, and state management. Users can access Refuel hosted LLMs for labeling and confidence estimation, and the library supports commercial and open source LLMs from providers like OpenAI, Anthropic, HuggingFace, and Google. Autolabel aims to streamline the labeling process for machine learning tasks by leveraging state-of-the-art LLM techniques and minimizing costs and experimentation time.
LLM-Agents-Papers
A repository that lists papers related to Large Language Model (LLM) based agents. The repository covers various topics including survey, planning, feedback & reflection, memory mechanism, role playing, game playing, tool usage & human-agent interaction, benchmark & evaluation, environment & platform, agent framework, multi-agent system, and agent fine-tuning. It provides a comprehensive collection of research papers on LLM-based agents, exploring different aspects of AI agent architectures and applications.

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.
UHGEval
UHGEval is a comprehensive framework designed for evaluating the hallucination phenomena. It includes UHGEval, a framework for evaluating hallucination, XinhuaHallucinations dataset, and UHGEval-dataset pipeline for creating XinhuaHallucinations. The framework offers flexibility and extensibility for evaluating common hallucination tasks, supporting various models and datasets. Researchers can use the open-source pipeline to create customized datasets. Supported tasks include QA, dialogue, summarization, and multi-choice tasks.
langchain-extract
LangChain Extract is a simple web server that allows you to extract information from text and files using LLMs. It is built using FastAPI, LangChain, and Postgresql. The backend closely follows the extraction use-case documentation and provides a reference implementation of an app that helps to do extraction over data using LLMs. This repository is meant to be a starting point for building your own extraction application which may have slightly different requirements or use cases.

py-llm-core
PyLLMCore is a light-weighted interface with Large Language Models with native support for llama.cpp, OpenAI API, and Azure deployments. It offers a Pythonic API that is simple to use, with structures provided by the standard library dataclasses module. The high-level API includes the assistants module for easy swapping between models. PyLLMCore supports various models including those compatible with llama.cpp, OpenAI, and Azure APIs. It covers use cases such as parsing, summarizing, question answering, hallucinations reduction, context size management, and tokenizing. The tool allows users to interact with language models for tasks like parsing text, summarizing content, answering questions, reducing hallucinations, managing context size, and tokenizing text.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
aligner
Aligner is a model-agnostic alignment tool that learns correctional residuals between preferred and dispreferred answers using a small model. It can be directly applied to various open-source and API-based models with only one-off training, suitable for rapid iteration and improving model performance. Aligner has shown significant improvements in helpfulness, harmlessness, and honesty dimensions across different large language models.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.
LLM-Fine-Tuning-Azure
A fine-tuning guide for both OpenAI and Open-Source Large Language Models on Azure. Fine-Tuning retrains an existing pre-trained LLM using example data, resulting in a new 'custom' fine-tuned LLM optimized for task-specific examples. Use cases include improving LLM performance on specific tasks and introducing information not well represented by the base LLM model. Suitable for cases where latency is critical, high accuracy is required, and clear evaluation metrics are available. Learning path includes labs for fine-tuning GPT and Llama2 models via Dashboards and Python SDK.
awesome-azure-openai-llm
This repository is a collection of references to Azure OpenAI, Large Language Models (LLM), and related services and libraries. It provides information on various topics such as RAG, Azure OpenAI, LLM applications, agent design patterns, semantic kernel, prompting, finetuning, challenges & abilities, LLM landscape, surveys & references, AI tools & extensions, datasets, and evaluations. The content covers a wide range of topics related to AI, machine learning, and natural language processing, offering insights into the latest advancements in the field.

LongRoPE
LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.
LLM-Fine-Tuning
This GitHub repository contains examples of fine-tuning open source large language models. It showcases the process of fine-tuning and quantizing large language models using efficient techniques like Lora and QLora. The repository serves as a practical guide for individuals looking to optimize the performance of language models through fine-tuning.
buffer-of-thought-llm
Buffer of Thoughts (BoT) is a thought-augmented reasoning framework designed to enhance the accuracy, efficiency, and robustness of large language models (LLMs). It introduces a meta-buffer to store high-level thought-templates distilled from problem-solving processes, enabling adaptive reasoning for efficient problem-solving. The framework includes a buffer-manager to dynamically update the meta-buffer, ensuring scalability and stability. BoT achieves significant performance improvements on reasoning-intensive tasks and demonstrates superior generalization ability and robustness while being cost-effective compared to other methods.

catalyst
Catalyst is a C# Natural Language Processing library designed for speed, inspired by spaCy's design. It provides pre-trained models, support for training word and document embeddings, and flexible entity recognition models. The library is fast, modern, and pure-C#, supporting .NET standard 2.0. It is cross-platform, running on Windows, Linux, macOS, and ARM. Catalyst offers non-destructive tokenization, named entity recognition, part-of-speech tagging, language detection, and efficient binary serialization. It includes pre-built models for language packages and lemmatization. Users can store and load models using streams. Getting started with Catalyst involves installing its NuGet Package and setting the storage to use the online repository. The library supports lazy loading of models from disk or online. Users can take advantage of C# lazy evaluation and native multi-threading support to process documents in parallel. Training a new FastText word2vec embedding model is straightforward, and Catalyst also provides algorithms for fast embedding search and dimensionality reduction.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
generative_ai_with_langchain
Generative AI with LangChain is a code repository for building large language model (LLM) apps with Python, ChatGPT, and other LLMs. The repository provides code examples, instructions, and configurations for creating generative AI applications using the LangChain framework. It covers topics such as setting up the development environment, installing dependencies with Conda or Pip, using Docker for environment setup, and setting API keys securely. The repository also emphasizes stability, code updates, and user engagement through issue reporting and feedback. It aims to empower users to leverage generative AI technologies for tasks like building chatbots, question-answering systems, software development aids, and data analysis applications.
RAGMeUp
RAG Me Up is a generic framework that enables users to perform Retrieve and Generate (RAG) on their own dataset easily. It consists of a small server and UIs for communication. Best run on GPU with 16GB vRAM. Users can combine RAG with fine-tuning using LLaMa2Lang repository. The tool allows configuration for LLM, data, LLM parameters, prompt, and document splitting. Funding is sought to democratize AI and advance its applications.
june
june-va is a local voice chatbot that combines Ollama for language model capabilities, Hugging Face Transformers for speech recognition, and the Coqui TTS Toolkit for text-to-speech synthesis. It provides a flexible, privacy-focused solution for voice-assisted interactions on your local machine, ensuring that no data is sent to external servers. The tool supports various interaction modes including text input/output, voice input/text output, text input/audio output, and voice input/audio output. Users can customize the tool's behavior with a JSON configuration file and utilize voice conversion features for voice cloning. The application can be further customized using a configuration file with attributes for language model, speech-to-text model, and text-to-speech model configurations.
LLM101n
LLM101n is a course focused on building a Storyteller AI Large Language Model (LLM) from scratch in Python, C, and CUDA. The course covers various topics such as language modeling, machine learning, attention mechanisms, tokenization, optimization, device usage, precision training, distributed optimization, datasets, inference, finetuning, deployment, and multimodal applications. Participants will gain a deep understanding of AI, LLMs, and deep learning through hands-on projects and practical examples.
hume-python-sdk
The Hume AI Python SDK allows users to integrate Hume APIs directly into their Python applications. Users can access complete documentation, quickstart guides, and example notebooks to get started. The SDK is designed to provide support for Hume's expressive communication platform built on scientific research. Users are encouraged to create an account at beta.hume.ai and stay updated on changes through Discord. The SDK may undergo breaking changes to improve tooling and ensure reliable releases in the future.
agents
Agents 2.0 is a framework for training language agents using symbolic learning, inspired by connectionist learning for neural nets. It implements main components of connectionist learning like back-propagation and gradient-based weight update in the context of agent training using language-based loss, gradients, and weights. The framework supports optimizing multi-agent systems and allows multiple agents to take actions in one node.
inspectus
Inspectus is a versatile visualization tool for large language models. It provides multiple views, including Attention Matrix, Query Token Heatmap, Key Token Heatmap, and Dimension Heatmap, to offer insights into language model behaviors. Users can interact with the tool in Jupyter notebooks through an easy-to-use Python API. Inspectus allows users to visualize attention scores between tokens, analyze how tokens focus on each other during processing, and explore the relationships between query and key tokens. The tool supports the visualization of attention maps from Huggingface transformers and custom attention maps, making it a valuable resource for researchers and developers working with language models.
rageval
Rageval is an evaluation tool for Retrieval-augmented Generation (RAG) methods. It helps evaluate RAG systems by performing tasks such as query rewriting, document ranking, information compression, evidence verification, answer generation, and result validation. The tool provides metrics for answer correctness and answer groundedness, along with benchmark results for ASQA and ALCE datasets. Users can install and use Rageval to assess the performance of RAG models in question-answering tasks.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.
LLM-workshop-2024
LLM-workshop-2024 is a tutorial designed for coders interested in understanding the building blocks of large language models (LLMs), how LLMs work, and how to code them from scratch in PyTorch. The tutorial covers topics such as introduction to LLMs, understanding LLM input data, coding LLM architecture, pretraining LLMs, loading pretrained weights, and finetuning LLMs using open-source libraries. Participants will learn to implement a small GPT-like LLM, including data input pipeline, core architecture components, and pretraining code.
ax
Ax is a Typescript library that allows users to build intelligent agents inspired by agentic workflows and the Stanford DSP paper. It seamlessly integrates with multiple Large Language Models (LLMs) and VectorDBs to create RAG pipelines or collaborative agents capable of solving complex problems. The library offers advanced features such as streaming validation, multi-modal DSP, and automatic prompt tuning using optimizers. Users can easily convert documents of any format to text, perform smart chunking, embedding, and querying, and ensure output validation while streaming. Ax is production-ready, written in Typescript, and has zero dependencies.
Wechat-AI-Assistant
Wechat AI Assistant is a project that enables multi-modal interaction with ChatGPT AI assistant within WeChat. It allows users to engage in conversations, role-playing, respond to voice messages, analyze images and videos, summarize articles and web links, and search the internet. The project utilizes the WeChatFerry library to control the Windows PC desktop WeChat client and leverages the OpenAI Assistant API for intelligent multi-modal message processing. Users can interact with ChatGPT AI in WeChat through text or voice, access various tools like bing_search, browse_link, image_to_text, text_to_image, text_to_speech, video_analysis, and more. The AI autonomously determines which code interpreter and external tools to use to complete tasks. Future developments include file uploads for AI to reference content, integration with other APIs, and login support for enterprise WeChat and WeChat official accounts.
searchGPT
searchGPT is an open-source project that aims to build a search engine based on Large Language Model (LLM) technology to provide natural language answers. It supports web search with real-time results, file content search, and semantic search from sources like the Internet. The tool integrates LLM technologies such as OpenAI and GooseAI, and offers an easy-to-use frontend user interface. The project is designed to provide grounded answers by referencing real-time factual information, addressing the limitations of LLM's training data. Contributions, especially from frontend developers, are welcome under the MIT License.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.
Train-llm-from-scratch
Train-llm-from-scratch is a repository that guides users through training a Large Language Model (LLM) from scratch. The model size can be adjusted based on available computing power. The repository utilizes deepspeed for distributed training and includes detailed explanations of the code and key steps at each stage to facilitate learning. Users can train their own tokenizer or use pre-trained tokenizers like ChatGLM2-6B. The repository provides information on preparing pre-training data, processing training data, and recommended SFT data for fine-tuning. It also references other projects and books related to LLM training.

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.
summary-of-a-haystack
This repository contains data and code for the experiments in the SummHay paper. It includes publicly released Haystacks in conversational and news domains, along with scripts for running the pipeline, visualizing results, and benchmarking automatic evaluation. The data structure includes topics, subtopics, insights, queries, retrievers, summaries, evaluation summaries, and documents. The pipeline involves scripts for retriever scores, summaries, and evaluation scores using GPT-4o. Visualization scripts are provided for compiling and visualizing results. The repository also includes annotated samples for benchmarking and citation information for the SummHay paper.
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
PhoGPT
PhoGPT is an open-source 4B-parameter generative model series for Vietnamese, including the base pre-trained monolingual model PhoGPT-4B and its chat variant, PhoGPT-4B-Chat. PhoGPT-4B is pre-trained from scratch on a Vietnamese corpus of 102B tokens, with an 8192 context length and a vocabulary of 20K token types. PhoGPT-4B-Chat is fine-tuned on instructional prompts and conversations, demonstrating superior performance. Users can run the model with inference engines like vLLM and Text Generation Inference, and fine-tune it using llm-foundry. However, PhoGPT has limitations in reasoning, coding, and mathematics tasks, and may generate harmful or biased responses.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
llm_recipes
This repository showcases the author's experiments with Large Language Models (LLMs) for text generation tasks. It includes dataset preparation, preprocessing, model fine-tuning using libraries such as Axolotl and HuggingFace, and model evaluation.
orch
orch is a library for building language model powered applications and agents for the Rust programming language. It can be used for tasks such as text generation, streaming text generation, structured data generation, and embedding generation. The library provides functionalities for executing various language model tasks and can be integrated into different applications and contexts. It offers flexibility for developers to create language model-powered features and applications in Rust.
llm-leaderboard
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.
InstructGraph
InstructGraph is a framework designed to enhance large language models (LLMs) for graph-centric tasks by utilizing graph instruction tuning and preference alignment. The tool collects and decomposes 29 standard graph datasets into four groups, enabling LLMs to better understand and generate graph data. It introduces a structured format verbalizer to transform graph data into a code-like format, facilitating code understanding and generation. Additionally, it addresses hallucination problems in graph reasoning and generation through direct preference optimization (DPO). The tool aims to bridge the gap between textual LLMs and graph data, offering a comprehensive solution for graph-related tasks.
AnyGPT
AnyGPT is a unified multimodal language model that utilizes discrete representations for processing various modalities like speech, text, images, and music. It aligns the modalities for intermodal conversions and text processing. AnyInstruct dataset is constructed for generative models. The model proposes a generative training scheme using Next Token Prediction task for training on a Large Language Model (LLM). It aims to compress vast multimodal data on the internet into a single model for emerging capabilities. The tool supports tasks like text-to-image, image captioning, ASR, TTS, text-to-music, and music captioning.
engine-core
Engine Core is a project that demonstrates a pattern for enabling Large Language Models (LLMs) to undertake tasks with a dynamic system prompt and a collection of tool functions known as chat strategies. These strategies allow for the dynamic alteration of chat history, system prompts, and available tools on every run. The project includes example strategies such as demoStrategy, backendStrategy, and shellStrategy. Additionally, LLM integrations like Anthropic or OpenAI have been extracted into adapters to enable running the same app code and strategies while switching foundation models.
llm_aided_ocr
The LLM-Aided OCR Project is an advanced system that enhances Optical Character Recognition (OCR) output by leveraging natural language processing techniques and large language models. It offers features like PDF to image conversion, OCR using Tesseract, error correction using LLMs, smart text chunking, markdown formatting, duplicate content removal, quality assessment, support for local and cloud-based LLMs, asynchronous processing, detailed logging, and GPU acceleration. The project provides detailed technical overview, text processing pipeline, LLM integration, token management, quality assessment, logging, configuration, and customization. It requires Python 3.12+, Tesseract OCR engine, PDF2Image library, PyTesseract, and optional OpenAI or Anthropic API support for cloud-based LLMs. The installation process involves setting up the project, installing dependencies, and configuring environment variables. Users can place a PDF file in the project directory, update input file path, and run the script to generate post-processed text. The project optimizes processing with concurrent processing, context preservation, and adaptive token management. Configuration settings include choosing between local or API-based LLMs, selecting API provider, specifying models, and setting context size for local LLMs. Output files include raw OCR output and LLM-corrected text. Limitations include performance dependency on LLM quality and time-consuming processing for large documents.

xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.
Foundations-of-LLMs
Foundations-of-LLMs is a comprehensive book aimed at readers interested in large language models, providing systematic explanations of foundational knowledge and introducing cutting-edge technologies. The book covers traditional language models, evolution of large language model architectures, prompt engineering, parameter-efficient fine-tuning, model editing, and retrieval-enhanced generation. Each chapter uses an animal as a theme to explain specific technologies, enhancing readability. The content is based on the author team's exploration and understanding of the field, with continuous monthly updates planned. The book includes a 'Paper List' for each chapter to track the latest advancements in related technologies.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.
wikipedia-semantic-search
This repository showcases a project that indexes millions of Wikipedia articles using Upstash Vector. It includes a semantic search engine and a RAG chatbot SDK. The project involves preparing and embedding Wikipedia articles, indexing vectors, building a semantic search engine, and implementing a RAG chatbot. Key features include indexing over 144 million vectors, multilingual support, cross-lingual semantic search, and a RAG chatbot. Technologies used include Upstash Vector, Upstash Redis, Upstash RAG Chat SDK, SentenceTransformers, and Meta-Llama-3-8B-Instruct for LLM provider.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
LLMs-at-DoD
This repository contains tutorials for using Large Language Models (LLMs) in the U.S. Department of Defense. The tutorials utilize open-source frameworks and LLMs, allowing users to run them in their own cloud environments. The repository is maintained by the Defense Digital Service and welcomes contributions from users.
binary-mlc-llm-libs
The binary-mlc-llm-libs repository contains model libraries stored in a specific format. The file names include metadata such as context window size, sliding window size, and prefill chunk size. Default configurations are provided for some models, with certain metadata values omitted if they are the same as default choices. Users can access various pre-trained language models for different tasks using this repository.
LangBridge
LangBridge is a tool that bridges mT5 encoder and the target LM together using only English data. It enables models to effectively solve multilingual reasoning tasks without the need for multilingual supervision. The tool provides pretrained models like Orca 2, MetaMath, Code Llama, Llemma, and Llama 2 for various instruction-tuned and not instruction-tuned scenarios. Users can install the tool to replicate evaluations from the paper and utilize the models for multilingual reasoning tasks. LangBridge is particularly useful for low-resource languages and may lower performance in languages where the language model is already proficient.
Chat-With-RTX-python-api
This repository contains a Python API for Chat With RTX, which allows users to interact with RTX models for natural language processing. The API provides functionality to send messages and receive responses from various LLM models. It also includes information on the speed of different models supported by Chat With RTX. The repository has a history of updates, including the removal of a feature and the addition of a new model for speech-to-text conversion. The repository is licensed under CC0.
LLM-Microscope
LLM-Microscope is a toolkit designed for quantifying and visualizing language model internals. It provides functions for calculating anisotropy, intrinsic dimension, and linearity score. The toolkit also includes a Logit Lens feature for analyzing model predictions and losses. Users can easily install the toolkit using pip and explore the functionalities through provided examples.
RAG_Hack
RAGHack is a hackathon focused on building AI applications using the power of RAG (Retrieval Augmented Generation). RAG combines large language models with search engine knowledge to provide contextually relevant answers. Participants can learn to build RAG apps on Azure AI using various languages and retrievers, explore frameworks like LangChain and Semantic Kernel, and leverage technologies such as agents and vision models. The hackathon features live streams, hack submissions, and prizes for innovative projects.
open-assistant-api
Open Assistant API is an open-source, self-hosted AI intelligent assistant API compatible with the official OpenAI interface. It supports integration with more commercial and private models, R2R RAG engine, internet search, custom functions, built-in tools, code interpreter, multimodal support, LLM support, and message streaming output. Users can deploy the service locally and expand existing features. The API provides user isolation based on tokens for SaaS deployment requirements and allows integration of various tools to enhance its capability to connect with the external world.
flow-prompt
Flow Prompt is a dynamic library for managing and optimizing prompts for large language models. It facilitates budget-aware operations, dynamic data integration, and efficient load distribution. Features include CI/CD testing, dynamic prompt development, multi-model support, real-time insights, and prompt testing and evolution.

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.
devdocs-to-llm
The devdocs-to-llm repository is a work-in-progress tool that aims to convert documentation from DevDocs format to Long Language Model (LLM) format. This tool is designed to streamline the process of converting documentation for use with LLMs, making it easier for developers to leverage large language models for various tasks. By automating the conversion process, developers can quickly adapt DevDocs content for training and fine-tuning LLMs, enabling them to create more accurate and contextually relevant language models.
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.
cursive-py
Cursive is a universal and intuitive framework for interacting with LLMs. It is extensible, allowing users to hook into any part of a completion life cycle. Users can easily describe functions that LLMs can use with any supported model. Cursive aims to bridge capabilities between different models, providing a single interface for users to choose any model. It comes with built-in token usage and costs calculations, automatic retry, and model expanding features. Users can define and describe functions, generate Pydantic BaseModels, hook into completion life cycle, create embeddings, and configure retry and model expanding behavior. Cursive supports various models from OpenAI, Anthropic, OpenRouter, Cohere, and Replicate, with options to pass API keys for authentication.

Reflection_Tuning
Reflection-Tuning is a project focused on improving the quality of instruction-tuning data through a reflection-based method. It introduces Selective Reflection-Tuning, where the student model can decide whether to accept the improvements made by the teacher model. The project aims to generate high-quality instruction-response pairs by defining specific criteria for the oracle model to follow and respond to. It also evaluates the efficacy and relevance of instruction-response pairs using the r-IFD metric. The project provides code for reflection and selection processes, along with data and model weights for both V1 and V2 methods.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.
LangChain-Udemy-Course
LangChain-Udemy-Course is a comprehensive course directory focusing on LangChain, a framework for generative AI applications. The course covers various aspects such as OpenAI API usage, prompt templates, Chains exploration, callback functions, memory techniques, RAG implementation, autonomous agents, hybrid search, LangSmith utilization, microservice architecture, and LangChain Expression Language. Learners gain theoretical knowledge and practical insights to understand and apply LangChain effectively in generative AI scenarios.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.

Hands-On-Large-Language-Models
Hands-On Large Language Models is a repository containing code examples from the book 'The Illustrated LLM Book' by Jay Alammar and Maarten Grootendorst. The repository provides practical tools and concepts for using Large Language Models with over 250 custom-made figures. It covers topics such as language model introduction, tokens and embeddings, transformer LLMs, text classification, text clustering, prompt engineering, text generation techniques, semantic search, multimodal LLMs, text embedding models, fine-tuning representation models, and fine-tuning generation models. The examples are designed to be run on Google Colab with T4 GPU support, but can be adapted to other cloud platforms as well.

oreilly-retrieval-augmented-gen-ai
This repository focuses on Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs). It provides code and resources to augment LLMs with real-time data for dynamic, context-aware applications. The content covers topics such as semantic search, fine-tuning embeddings, building RAG chatbots, evaluating LLMs, and using knowledge graphs in RAG. Prerequisites include Python skills, knowledge of machine learning and LLMs, and introductory experience with NLP and AI models.
Awesome-Graph-LLM
Awesome-Graph-LLM is a curated collection of research papers exploring the intersection of graph-based techniques with Large Language Models (LLMs). The repository aims to bridge the gap between LLMs and graph structures prevalent in real-world applications by providing a comprehensive list of papers covering various aspects of graph reasoning, node classification, graph classification/regression, knowledge graphs, multimodal models, applications, and tools. It serves as a valuable resource for researchers and practitioners interested in leveraging LLMs for graph-related tasks.
local-assistant-examples
The Local Assistant Examples repository is a collection of educational examples showcasing the use of large language models (LLMs). It was initially created for a blog post on building a RAG model locally, and has since expanded to include more examples and educational material. Each example is housed in its own folder with a dedicated README providing instructions on how to run it. The repository is designed to be simple and educational, not for production use.
LongRecipe
LongRecipe is a tool designed for efficient long context generalization in large language models. It provides a recipe for extending the context window of language models while maintaining their original capabilities. The tool includes data preprocessing steps, model training stages, and a process for merging fine-tuned models to enhance foundational capabilities. Users can follow the provided commands and scripts to preprocess data, train models in multiple stages, and merge models effectively.

py-vectara-agentic
The `vectara-agentic` Python library is designed for developing powerful AI assistants using Vectara and Agentic-RAG. It supports various agent types, includes pre-built tools for domains like finance and legal, and enables easy creation of custom AI assistants and agents. The library provides tools for summarizing text, rephrasing text, legal tasks like summarizing legal text and critiquing as a judge, financial tasks like analyzing balance sheets and income statements, and database tools for inspecting and querying databases. It also supports observability via LlamaIndex and Arize Phoenix integration.
chatlab
ChatLab is a Python package that simplifies experimenting with OpenAI's chat models. It provides an interactive interface for chatting with the models and registering custom functions. Users can easily create chat experiments, visualize color palettes, work with function registry, create knowledge graphs, and perform direct parallel function calling. The tool enables users to interact with chat models and customize functionalities for various tasks.
awesome-rag
Awesome RAG is a curated list of retrieval-augmented generation (RAG) in large language models. It includes papers, surveys, general resources, lectures, talks, tutorials, workshops, tools, and other collections related to retrieval-augmented generation. The repository aims to provide a comprehensive overview of the latest advancements, techniques, and applications in the field of RAG.

weblinx
WebLINX is a Python library and dataset for real-world website navigation with multi-turn dialogue. The repository provides code for training models reported in the WebLINX paper, along with a comprehensive API to work with the dataset. It includes modules for data processing, model evaluation, and utility functions. The modeling directory contains code for processing, training, and evaluating models such as DMR, LLaMA, MindAct, Pix2Act, and Flan-T5. Users can install specific dependencies for HTML processing, video processing, model evaluation, and library development. The evaluation module provides metrics and functions for evaluating models, with ongoing work to improve documentation and functionality.
langkit
LangKit is an open-source text metrics toolkit for monitoring language models. It offers methods for extracting signals from input/output text, compatible with whylogs. Features include text quality, relevance, security, sentiment, toxicity analysis. Installation via PyPI. Modules contain UDFs for whylogs. Benchmarks show throughput on AWS instances. FAQs available.
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
prism
Prism is a Laravel package for integrating Large Language Models (LLMs) into applications. It simplifies text generation, multi-step conversations, and AI tools integration. Focus on developing exceptional AI applications without technical complexities.
RAGHub
RAGHub is a community-driven project focused on cataloging new and emerging frameworks, projects, and resources in the Retrieval-Augmented Generation (RAG) ecosystem. It aims to help users stay ahead of changes in the field by providing a platform for the latest innovations in RAG. The repository includes information on RAG frameworks, evaluation frameworks, optimization frameworks, citation frameworks, engines, search reranker frameworks, projects, resources, and real-world use cases across industries and professions.
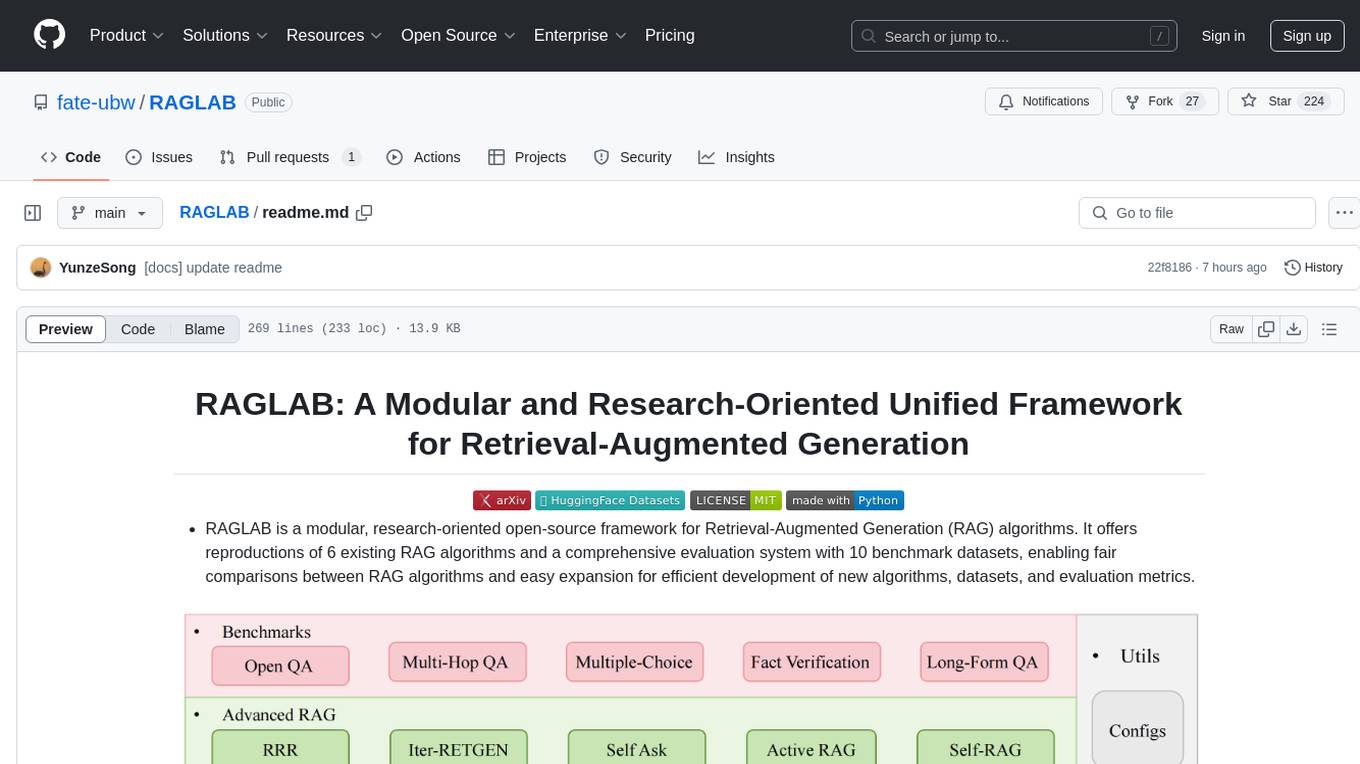
RAGLAB
RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics. The framework supports the entire RAG pipeline, provides advanced algorithm implementations, fair comparison platform, efficient retriever client, versatile generator support, and flexible instruction lab. It also includes features like Interact Mode for quick understanding of algorithms and Evaluation Mode for reproducing paper results and scientific research.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.
MMLU-Pro
MMLU-Pro is an enhanced benchmark designed to evaluate language understanding models across broader and more challenging tasks. It integrates more challenging, reasoning-focused questions and increases answer choices per question, significantly raising difficulty. The dataset comprises over 12,000 questions from academic exams and textbooks across 14 diverse domains. Experimental results show a significant drop in accuracy compared to the original MMLU, with greater stability under varying prompts. Models utilizing Chain of Thought reasoning achieved better performance on MMLU-Pro.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.
Awesome-Efficient-AIGC
This repository, Awesome Efficient AIGC, collects efficient approaches for AI-generated content (AIGC) to cope with its huge demand for computing resources. It includes efficient Large Language Models (LLMs), Diffusion Models (DMs), and more. The repository is continuously improving and welcomes contributions of works like papers and repositories that are missed by the collection.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.

LangBot
LangBot is a highly stable, extensible, and multimodal instant messaging chatbot platform based on large language models. It supports various large models, adapts to group chats and private chats, and has capabilities for multi-turn conversations, tool invocation, and multimodal interactions. It is deeply integrated with Dify and currently supports QQ and QQ channels, with plans to support platforms like WeChat, WhatsApp, and Discord. The platform offers high stability, comprehensive functionality, native support for access control, rate limiting, sensitive word filtering mechanisms, and simple configuration with multiple deployment options. It also features plugin extension capabilities, an active community, and a new web management panel for managing LangBot instances through a browser.

chonkie
Chonkie is a lightweight and fast RAG chunking library designed to efficiently split text for RAG (Retrieval-Augmented Generation) applications. It offers various chunking methods like TokenChunker, WordChunker, SentenceChunker, SemanticChunker, SDPMChunker, and an experimental LateChunker. Chonkie is feature-rich, easy to use, fast, supports multiple tokenizers, and comes with a cute pygmy hippo mascot. It aims to provide a no-nonsense solution for chunking text without the need to worry about dependencies or bloat.

LongBench
LongBench v2 is a benchmark designed to assess the ability of large language models (LLMs) to handle long-context problems requiring deep understanding and reasoning across various real-world multitasks. It consists of 503 challenging multiple-choice questions with contexts ranging from 8k to 2M words, covering six major task categories. The dataset is collected from nearly 100 highly educated individuals with diverse professional backgrounds and is designed to be challenging even for human experts. The evaluation results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2.

ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
tamingLLMs
The 'Taming LLMs' repository provides a practical guide to the pitfalls and challenges associated with Large Language Models (LLMs) when building applications. It focuses on key limitations and implementation pitfalls, offering practical Python examples and open source solutions to help engineers and technical leaders navigate these challenges. The repository aims to equip readers with the knowledge to harness the power of LLMs while avoiding their inherent limitations.
mcphost
MCPHost is a CLI host application that enables Large Language Models (LLMs) to interact with external tools through the Model Context Protocol (MCP). It acts as a host in the MCP client-server architecture, allowing language models to access external tools and data sources, maintain consistent context across interactions, and execute commands safely. The tool supports interactive conversations with Claude 3.5 Sonnet and Ollama models, multiple concurrent MCP servers, dynamic tool discovery and integration, configurable server locations and arguments, and a consistent command interface across model types.
SLMs-Survey
SLMs-Survey is a comprehensive repository that includes papers and surveys on small language models. It covers topics such as technology, on-device applications, efficiency, enhancements for LLMs, and trustworthiness. The repository provides a detailed overview of existing SLMs, their architecture, enhancements, and specific applications in various domains. It also includes information on SLM deployment optimization techniques and the synergy between SLMs and LLMs.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.
Awesome-Audio-LLM
Awesome-Audio-LLM is a repository dedicated to various models and methods related to audio and language processing. It includes a wide range of research papers and models developed by different institutions and authors. The repository covers topics such as bridging audio and language, speech emotion recognition, voice assistants, and more. It serves as a comprehensive resource for those interested in the intersection of audio and language processing.

langfair
LangFair is a Python library for bias and fairness assessments of large language models (LLMs). It offers a comprehensive framework for choosing bias and fairness metrics, demo notebooks, and a technical playbook. Users can tailor evaluations to their use cases with a Bring Your Own Prompts approach. The focus is on output-based metrics practical for governance audits and real-world testing.
TapeAgents
TapeAgents is a framework that leverages a structured, replayable log of the agent session to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thoughts, actions, control flow steps, and append them to the tape. Key features include building agents as low-level state machines or high-level multi-agent team configurations, debugging agents with TapeAgent studio or TapeBrowser apps, serving agents with response streaming, and optimizing agent configurations using successful tapes. The Tape-centric design of TapeAgents provides ultimate flexibility in project development, allowing access to tapes for making prompts, generating next steps, and controlling agent behavior.
llm_agents
LLM Agents is a small library designed to build agents controlled by large language models. It aims to provide a better understanding of how such agents work in a concise manner. The library allows agents to be instructed by prompts, use custom-built components as tools, and run in a loop of Thought, Action, Observation. The agents leverage language models to generate Thought and Action, while tools like Python REPL, Google search, and Hacker News search provide Observations. The library requires setting up environment variables for OpenAI API and SERPAPI API keys. Users can create their own agents by importing the library and defining tools accordingly.

VisionLLM
VisionLLM is a series of large language models designed for vision-centric tasks. The latest version, VisionLLM v2, is a generalist multimodal model that supports hundreds of vision-language tasks, including visual understanding, perception, and generation.
miniLLMFlow
Mini LLM Flow is a 100-line minimalist LLM framework designed for agents, task decomposition, RAG, etc. It aims to be the framework used by LLMs, focusing on high-level programming paradigms while stripping away low-level implementation details. It serves as a learning resource and allows LLMs to design, build, and maintain projects themselves.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
intro-to-llms-365
This repository serves as a resource for the Introduction to Large Language Models (LLMs) course, providing Jupyter notebooks with hands-on examples and exercises to help users learn the basics of Large Language Models. It includes information on installed packages, updates, and setting up a virtual environment for managing packages and running Jupyter notebooks.
ai-tutor-rag-system
The AI Tutor RAG System repository contains Jupyter notebooks supporting the RAG course, focusing on enhancing AI models with retrieval-based methods. It covers foundational and advanced concepts in retrieval-augmented generation, including data retrieval techniques, model integration with retrieval systems, and practical applications of RAG in real-world scenarios.

ModernBERT
ModernBERT is a repository focused on modernizing BERT through architecture changes and scaling. It introduces FlexBERT, a modular approach to encoder building blocks, and heavily relies on .yaml configuration files to build models. The codebase builds upon MosaicBERT and incorporates Flash Attention 2. The repository is used for pre-training and GLUE evaluations, with a focus on reproducibility and documentation. It provides a collaboration between Answer.AI, LightOn, and friends.
confabulations
LLM Confabulation Leaderboard evaluates large language models based on confabulations and non-response rates to challenging questions. It includes carefully curated questions with no answers in provided texts, aiming to differentiate between various models. The benchmark combines confabulation and non-response rates for comprehensive ranking, offering insights into model performance and tendencies. Additional notes highlight the meticulous human verification process, challenges faced by LLMs in generating valid responses, and the use of temperature settings. Updates and other benchmarks are also mentioned, providing a holistic view of the evaluation landscape.
bailing
Bailing is an open-source voice assistant designed for natural conversations with users. It combines Automatic Speech Recognition (ASR), Voice Activity Detection (VAD), Large Language Model (LLM), and Text-to-Speech (TTS) technologies to provide a high-quality voice interaction experience similar to GPT-4o. Bailing aims to achieve GPT-4o-like conversation effects without the need for GPU, making it suitable for various edge devices and low-resource environments. The project features efficient open-source models, modular design allowing for module replacement and upgrades, support for memory function, tool integration for information retrieval and task execution via voice commands, and efficient task management with progress tracking and reminders.
handy-ollama
Handy-Ollama is a tutorial for deploying Ollama with hands-on practice, making the deployment of large language models accessible to everyone. The tutorial covers a wide range of content from basic to advanced usage, providing clear steps and practical tips for beginners and experienced developers to learn Ollama from scratch, deploy large models locally, and develop related applications. It aims to enable users to run large models on consumer-grade hardware, deploy models locally, and manage models securely and reliably.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.

quantalogic
QuantaLogic is a ReAct framework for building advanced AI agents that seamlessly integrates large language models with a robust tool system. It aims to bridge the gap between advanced AI models and practical implementation in business processes by enabling agents to understand, reason about, and execute complex tasks through natural language interaction. The framework includes features such as ReAct Framework, Universal LLM Support, Secure Tool System, Real-time Monitoring, Memory Management, and Enterprise Ready components.
LangGraph-learn
LangGraph-learn is a community-driven project focused on mastering LangGraph and other AI-related topics. It provides hands-on examples and resources to help users learn how to create and manage language model workflows using LangGraph and related tools. The project aims to foster a collaborative learning environment for individuals interested in AI and machine learning by offering practical examples and tutorials on building efficient and reusable workflows involving language models.
factualNLG
FactualNLG is a tool designed to analyze the consistency of edits in summaries. It includes a benchmark with various LLM models, data release for the SummEdits benchmark, explanation analysis for identifying inconsistent summaries, and prompts used in experiments.

Hurley-AI
Hurley AI is a next-gen framework for developing intelligent agents through Retrieval-Augmented Generation. It enables easy creation of custom AI assistants and agents, supports various agent types, and includes pre-built tools for domains like finance and legal. Hurley AI integrates with LLM inference services and provides observability with Arize Phoenix. Users can create Hurley RAG tools with a single line of code and customize agents with specific instructions. The tool also offers various helper functions to connect with Hurley RAG and search tools, along with pre-built tools for tasks like summarizing text, rephrasing text, understanding memecoins, and querying databases.
Fast-LLM
Fast-LLM is an open-source library designed for training large language models with exceptional speed, scalability, and flexibility. Built on PyTorch and Triton, it offers optimized kernel efficiency, reduced overheads, and memory usage, making it suitable for training models of all sizes. The library supports distributed training across multiple GPUs and nodes, offers flexibility in model architectures, and is easy to use with pre-built Docker images and simple configuration. Fast-LLM is licensed under Apache 2.0, developed transparently on GitHub, and encourages contributions and collaboration from the community.

npcsh
`npcsh` is a python-based command-line tool designed to integrate Large Language Models (LLMs) and Agents into one's daily workflow by making them available and easily configurable through the command line shell. It leverages the power of LLMs to understand natural language commands and questions, execute tasks, answer queries, and provide relevant information from local files and the web. Users can also build their own tools and call them like macros from the shell. `npcsh` allows users to take advantage of agents (i.e. NPCs) through a managed system, tailoring NPCs to specific tasks and workflows. The tool is extensible with Python, providing useful functions for interacting with LLMs, including explicit coverage for popular providers like ollama, anthropic, openai, gemini, deepseek, and openai-like providers. Users can set up a flask server to expose their NPC team for use as a backend service, run SQL models defined in their project, execute assembly lines, and verify the integrity of their NPC team's interrelations. Users can execute bash commands directly, use favorite command-line tools like VIM, Emacs, ipython, sqlite3, git, pipe the output of these commands to LLMs, or pass LLM results to bash commands.
chatmemory
ChatMemory is a simple yet powerful long-term memory manager that facilitates communication between AI and users. It organizes conversation data into history, summary, and knowledge entities, enabling quick retrieval of context and generation of clear, concise answers. The tool leverages vector search on summaries/knowledge and detailed history to provide accurate responses. It balances speed and accuracy by using lightweight retrieval and fallback detailed search mechanisms, ensuring efficient memory management and response generation beyond mere data retrieval.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.
UMbreLLa
UMbreLLa is a tool designed for deploying Large Language Models (LLMs) for personal agents. It combines offloading, speculative decoding, and quantization to optimize single-user LLM deployment scenarios. With UMbreLLa, 70B-level models can achieve performance comparable to human reading speed on an RTX 4070Ti, delivering exceptional efficiency and responsiveness, especially for coding tasks. The tool supports deploying models on various GPUs and offers features like code completion and CLI/Gradio chatbots. Users can configure the LLM engine for optimal performance based on their hardware setup.
llm-rankers
llm-rankers is a repository that provides implementations for Pointwise, Listwise, Pairwise, and Setwise Document Ranking using Large Language Models. It includes various methods for reranking documents retrieved by a first-stage retriever, such as BM25. The repository offers examples and code snippets for using LLMs to improve document ranking performance in information retrieval tasks. Additionally, it introduces a new setwise reranker called Rank-R1 with reasoning ability.

Adaptive-MT-LLM-Fine-tuning
The repository Adaptive-MT-LLM-Fine-tuning contains code and data for the paper 'Fine-tuning Large Language Models for Adaptive Machine Translation'. It focuses on enhancing Mistral 7B, a large language model, for real-time adaptive machine translation in the medical domain. The fine-tuning process involves using zero-shot and one-shot translation prompts to improve terminology and style adherence. The repository includes training and test data, data processing code, fuzzy match retrieval techniques, fine-tuning methods, conversion to CTranslate2 format, tokenizers, translation codes, and evaluation metrics.
omniai
OmniAI provides a unified Ruby API for integrating with multiple AI providers, streamlining AI development by offering a consistent interface for features such as chat, text-to-speech, speech-to-text, and embeddings. It ensures seamless interoperability across platforms and effortless switching between providers, making integrations more flexible and reliable.
LLMs-in-Production
LLMs in Production is a repository for the book with Manning Publications, containing chapter listings and setup instructions. It provides environments for each chapter, linters, formatters, and tests. The scripts are designed to be run from the project root.
llm-engineer-toolkit
The LLM Engineer Toolkit is a curated repository containing over 120 LLM libraries categorized for various tasks such as training, application development, inference, serving, data extraction, data generation, agents, evaluation, monitoring, prompts, structured outputs, safety, security, embedding models, and other miscellaneous tools. It includes libraries for fine-tuning LLMs, building applications powered by LLMs, serving LLM models, extracting data, generating synthetic data, creating AI agents, evaluating LLM applications, monitoring LLM performance, optimizing prompts, handling structured outputs, ensuring safety and security, embedding models, and more. The toolkit covers a wide range of tools and frameworks to streamline the development, deployment, and optimization of large language models.
inference-speed-tests
This repository contains inference speed tests on Local Large Language Models on various devices. It provides results for different models tested on Macbook Pro and Mac Studio. Users can contribute their own results by running models with the provided prompt and adding the tokens-per-second output. Note that the results are not verified.
AIGC_text_detector
AIGC_text_detector is a repository containing the official codes for the paper 'Multiscale Positive-Unlabeled Detection of AI-Generated Texts'. It includes detector models for both English and Chinese texts, along with stronger detectors developed with enhanced training strategies. The repository provides links to download the detector models, datasets, and necessary preprocessing tools. Users can train RoBERTa and BERT models on the HC3-English dataset using the provided scripts.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.
free-llm-collect
This repository is a collection of free large language models (LLMs) that can be used for various natural language processing tasks. It includes information on different free LLM APIs and projects that can be deployed without cost. Users can find details on the performance, login requirements, function calling capabilities, and deployment environments of each listed LLM source.
flash-tokenizer
FlashTokenizer is a high-performance CPU tokenizer library implemented in C++ for LLM inference serving. It is 10 times faster than BertTokenizerFast in transformers, offering the highest speed and accuracy. Developed to be faster, more accurate, and easier to use than existing tokenizers like BertTokenizerFast, FlashTokenizer is implemented in C++ for straightforward maintenance. It supports parallel processing at the C++ level for batch encoding, delivering outstanding speed. The tokenizer is based on the LinMax Tokenizer proposed in Fast WordPiece Tokenization, enabling tokenization in linear time.
rag-in-action
rag-in-action is a GitHub repository that provides a practical course structure for developing a RAG system based on DeepSeek. The repository likely contains resources, code samples, and tutorials to guide users through the process of building and implementing a RAG system using DeepSeek technology. Users interested in learning about RAG systems and their development may find this repository helpful in gaining hands-on experience and practical knowledge in this area.
reasoning-from-scratch
This repository contains the code for developing a large language model (LLM) reasoning model. The book 'Build a Reasoning Model (From Scratch)' provides a hands-on approach to understanding and implementing reasoning capabilities in LLMs. It guides users through creating a small but functional reasoning model, mirroring approaches used in large-scale models like DeepSeek R1 and GPT-5 Thinking. The code includes methods for loading weights of pretrained models.
langgraph4j
Langgraph4j is a Java library for language processing tasks such as text classification, sentiment analysis, and named entity recognition. It provides a set of tools and algorithms for analyzing text data and extracting useful information. The library is designed to be efficient and easy to use, making it suitable for both research and production applications.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.
Awesome-LLM-Ensemble
Awesome-LLM-Ensemble is a collection of papers on LLM Ensemble, focusing on the comprehensive use of multiple large language models to benefit from their individual strengths. It provides a systematic review of recent developments in LLM Ensemble, including taxonomy, methods for ensemble before, during, and after inference, benchmarks, applications, and related surveys.
architext
Architext is a Python library designed for Large Language Model (LLM) applications, focusing on Context Engineering. It provides tools to construct and reorganize input context for LLMs dynamically. The library aims to elevate context construction from ad-hoc to systematic engineering, enabling precise manipulation of context content for AI Agents.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.
DeepMCPAgent
DeepMCPAgent is a model-agnostic tool that enables the creation of LangChain/LangGraph agents powered by MCP tools over HTTP/SSE. It allows for dynamic discovery of tools, connection to remote MCP servers, and integration with any LangChain chat model instance. The tool provides a deep agent loop for enhanced functionality and supports typed tool arguments for validated calls. DeepMCPAgent emphasizes the importance of MCP-first approach, where agents dynamically discover and call tools rather than hardcoding them.

dexto
Dexto is a lightweight runtime for creating and running AI agents that turn natural language into real-world actions. It serves as the missing intelligence layer for building AI applications, standalone chatbots, or as the reasoning engine inside larger products. Dexto features a powerful CLI and Web UI for running AI agents, supports multiple interfaces, allows hot-swapping of LLMs from various providers, connects to remote tool servers via the Model Context Protocol, is config-driven with version-controlled YAML, offers production-ready core features, extensibility for custom services, and enables multi-agent collaboration via MCP and A2A.
wikipedia-mcp
The Wikipedia MCP Server is a Model Context Protocol (MCP) server that provides real-time access to Wikipedia information for Large Language Models (LLMs). It allows AI assistants to retrieve accurate and up-to-date information from Wikipedia to enhance their responses. The server offers features such as searching Wikipedia, retrieving article content, getting article summaries, extracting specific sections, discovering links within articles, finding related topics, supporting multiple languages and country codes, optional caching for improved performance, and compatibility with Google ADK agents and other AI frameworks. Users can install the server using pipx, Smithery, PyPI, virtual environment, or from source. The server can be run with various options for transport protocol, language, country/locale, caching, access token, and more. It also supports Docker and Kubernetes deployment. The server provides MCP tools for interacting with Wikipedia, such as searching articles, getting article content, summaries, sections, links, coordinates, related topics, and extracting key facts. It also supports country/locale codes and language variants for languages like Chinese, Serbian, Kurdish, and Norwegian. The server includes example prompts for querying Wikipedia and provides MCP resources for interacting with Wikipedia through MCP endpoints. The project structure includes main packages, API implementation, core functionality, utility functions, and a comprehensive test suite for reliability and functionality testing.
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
happy-llm
Happy-LLM is a systematic learning tutorial for Large Language Models (LLM) that covers NLP research methods, LLM architecture, training process, and practical applications. It aims to help readers understand the principles and training processes of large language models. The tutorial delves into Transformer architecture, attention mechanisms, pre-training language models, building LLMs, training processes, and practical applications like RAG and Agent technologies. It is suitable for students, researchers, and LLM enthusiasts with programming experience, Python knowledge, and familiarity with deep learning and NLP concepts. The tutorial encourages hands-on practice and participation in LLM projects and competitions to deepen understanding and contribute to the open-source LLM community.

Open-dLLM
Open-dLLM is the most open release of a diffusion-based large language model, providing pretraining, evaluation, inference, and checkpoints. It introduces Open-dCoder, the code-generation variant of Open-dLLM. The repo offers a complete stack for diffusion LLMs, enabling users to go from raw data to training, checkpoints, evaluation, and inference in one place. It includes pretraining pipeline with open datasets, inference scripts for easy sampling and generation, evaluation suite with various metrics, weights and checkpoints on Hugging Face, and transparent configs for full reproducibility.

RustGPT
A complete Large Language Model implementation in pure Rust with no external ML frameworks. Demonstrates building a transformer-based language model from scratch, including pre-training, instruction tuning, interactive chat mode, full backpropagation, and modular architecture. Model learns basic world knowledge and conversational patterns. Features custom tokenization, greedy decoding, gradient clipping, modular layer system, and comprehensive test coverage. Ideal for understanding modern LLMs and key ML concepts. Dependencies include ndarray for matrix operations and rand for random number generation. Contributions welcome for model persistence, performance optimizations, better sampling, evaluation metrics, advanced architectures, training improvements, data handling, and model analysis. Follows standard Rust conventions and encourages contributions at beginner, intermediate, and advanced levels.

raif
Raif is a lightweight Python library for analyzing text data. It provides functionalities for text preprocessing, feature extraction, and text classification. With Raif, users can easily clean and preprocess text data, extract relevant features, and build machine learning models for text classification tasks. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists.
mangaba_ai
Mangaba AI is a minimalist repository for creating intelligent and versatile AI agents with A2A (Agent-to-Agent) and MCP (Model Context Protocol) protocols. It supports any AI provider, facilitates communication between agents, manages context effectively, and offers integrated functionalities like chat, analysis, and translation. The setup is straightforward with only 2 steps to get started. The repository includes scripts for automated configuration, manual setup, and environment validation. Users can easily chat with context, analyze text, translate, and interact with multiple agents using A2A protocol. The MCP protocol handles advanced context management automatically, categorizing context types and priorities. The repository also provides examples, documentation, and a comprehensive wiki in Brazilian Portuguese for beginners and developers.

LLMs-playground
LLMs-playground is a repository containing code examples and tutorials for learning and experimenting with Large Language Models (LLMs). It provides a hands-on approach to understanding how LLMs work and how to fine-tune them for specific tasks. The repository covers various LLM architectures, pre-training techniques, and fine-tuning strategies, making it a valuable resource for researchers, students, and practitioners interested in natural language processing and machine learning. By exploring the code and following the tutorials, users can gain practical insights into working with LLMs and apply their knowledge to real-world projects.
agentmark
AgentMark is a tool designed to make it easy for developers to develop, test, and evaluate AI Agents. It combines Markdown syntax with JSX components to create reliable Agents. The tool seamlessly integrates with SDKs, offering comprehensive tooling such as full type safety, unified prompt configuration, syntax highlighting, loops and conditionals, custom SDK adapters, and support for text, object, image, and speech generation across multiple model providers.
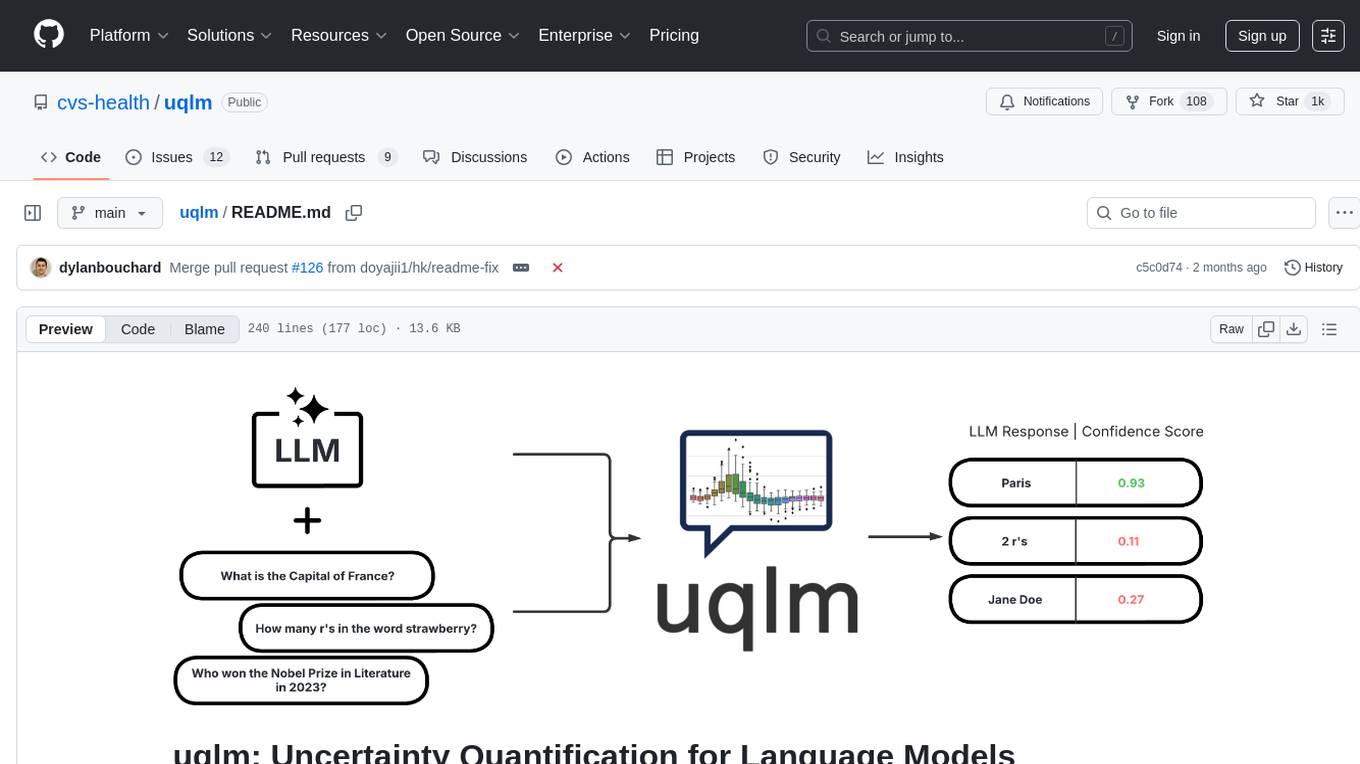
uqlm
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques. It provides response-level scorers for quantifying uncertainty of LLM outputs, categorized into four main types: Black-Box Scorers, White-Box Scorers, LLM-as-a-Judge Scorers, and Ensemble Scorers. Users can leverage different scorers to assess uncertainty in generated responses, with options for off-the-shelf usage or customization. The library offers illustrative code snippets and detailed information on available scorers for each type, along with example usage for conducting hallucination detection. Additionally, UQLM includes documentation, example notebooks, and associated research for further exploration and understanding.

blades
Blades is a multimodal AI Agent framework in Go, supporting custom models, tools, memory, middleware, and more. It is well-suited for multi-turn conversations, chain reasoning, and structured output. The framework provides core components like Agent, Prompt, Chain, ModelProvider, Tool, Memory, and Middleware, enabling developers to build intelligent applications with flexible configuration and high extensibility. Blades leverages the characteristics of Go to achieve high decoupling and efficiency, making it easy to integrate different language model services and external tools. The project is in its early stages, inviting Go developers and AI enthusiasts to contribute and explore the possibilities of building AI applications in Go.
rllm
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads. The framework provides tools for training coding models, software engineering agents, and language agents using reinforcement learning techniques. It supports various models of different sizes and capabilities, enabling users to achieve state-of-the-art performance in coding and language-related tasks. rLLM is designed to be user-friendly, scalable, and efficient for training and deploying language agents in diverse applications.
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.
simple-llm-eval
Simpleval is a Python package for evaluating Large Language Models (LLMs) using the 'LLM as a Judge' technique. It supports various LLM providers such as OpenAI, Google, AWS, Anthropic, Azure, and more. The package includes reports for analyzing and summarizing evaluation results.
Qing-Digital-Self
Qing-Digital-Self is a project that creates a personal digital twin by fine-tuning a large language model on your chat history. The aim is to replicate your unique style of expression and conversational behavior accurately. The project includes bilingual support and comprehensive tutorials covering data extraction, chat data cleaning and conversion, LlamaFactory fine-tuning process, and testing and usage of the fine-tuned model. It offers a different perspective and assistance compared to similar projects. The project is currently in development with version v0.1.6, and welcomes contributions and issue reports from developers.
33 - OpenAI Gpts

Research Paper Explorer
Explains Arxiv papers with examples, analogies, and direct PDF links.


Automated AI Prompt Categorizer
Comprehensive categorization and organization for AI Prompts
Instruction Assistant Operating Director
Full step by step guidance and copy & paste text for developing assistants with specific use cases.
DataLearnerAI-GPT
Using OpenLLMLeaderboard data to answer your questions about LLM. For Currently!
AI-Driven Lab
recommends AI research these days in Japanese using AI-driven's-lab articles
Auto Custom Actions GPT
This GPT help you on one single task, generating valid OpenAI Schemas for Custom Actions in GPTs


KingLand ∞ L'Élite Numérique IA
Plateforme innovante en IA pour passionnés de technologie, offrant conseils et articles via 100 IA collaboratives.

Generative AI Examiner
For "Generative AI Test". Examiner in Generative AI, posing questions and providing feedback.