
docetl
A system for agentic LLM-powered data processing and ETL
Stars: 1538
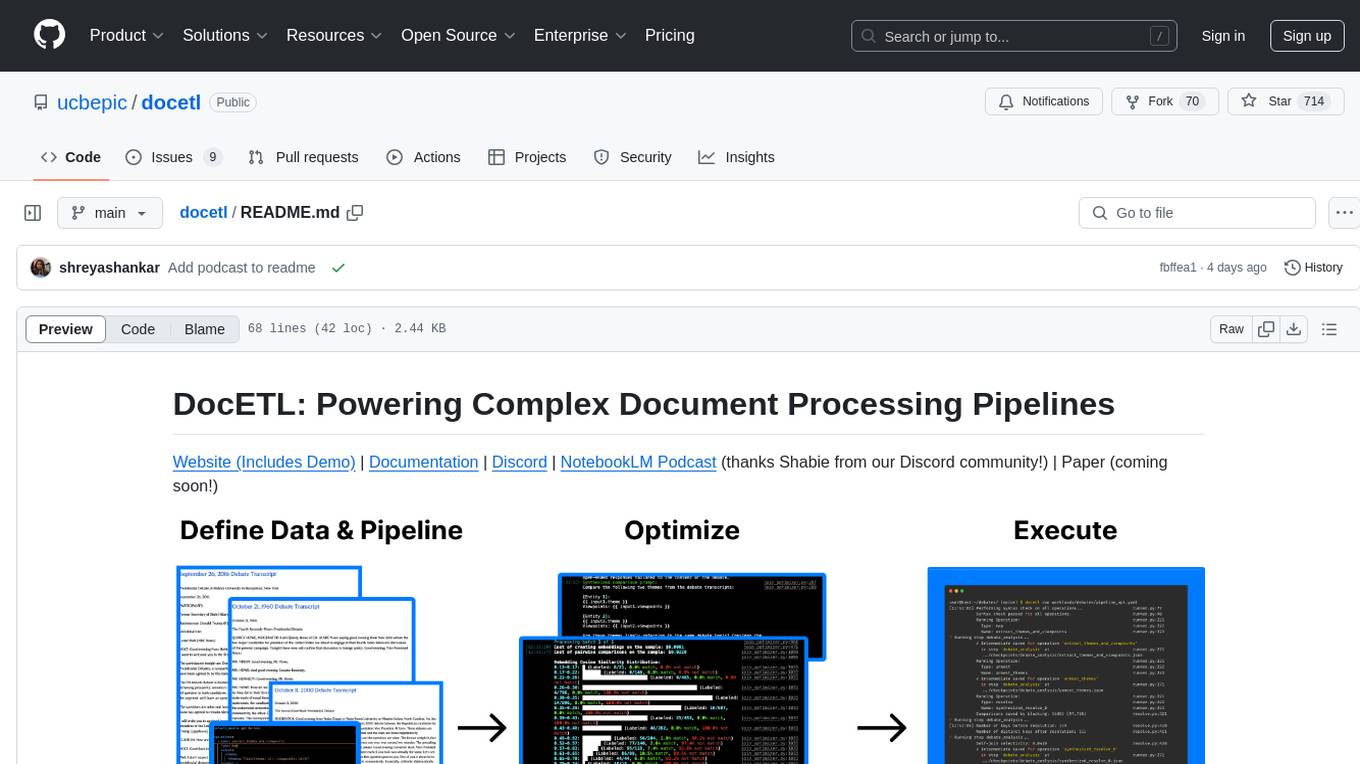
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
README:


DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers:
- An interactive UI playground for iterative prompt engineering and pipeline development
- A Python package for running production pipelines from the command line or Python code
There are two main ways to use DocETL:
DocWrangler helps you iteratively develop your pipeline:
- Experiment with different prompts and see results in real-time
- Build your pipeline step by step
- Export your finalized pipeline configuration for production use

DocWrangler is hosted at docetl.org/playground. But to run the playground locally, you can either:
- Use Docker (recommended for quick start):
make docker - Set up the development environment manually
See the Playground Setup Guide for detailed instructions.
If you want to use DocETL as a Python package:
- Python 3.10 or later
- OpenAI API key
pip install docetlCreate a .env file in your project directory:
OPENAI_API_KEY=your_api_key_here # Required for LLM operations (or the key for the LLM of your choice)To see examples of how to use DocETL, check out the tutorial.
To run DocWrangler locally, you have two options:
The easiest way to get the DocWrangler playground running:
- Create the required environment files:
Create .env in the root directory:
OPENAI_API_KEY=your_api_key_here
BACKEND_ALLOW_ORIGINS=http://localhost:3000,http://127.0.0.1:3000
BACKEND_HOST=0.0.0.0
BACKEND_PORT=8000
BACKEND_RELOAD=True
FRONTEND_HOST=0.0.0.0
FRONTEND_PORT=3000Create .env.local in the website directory:
OPENAI_API_KEY=sk-xxx
OPENAI_API_BASE=https://api.openai.com/v1
MODEL_NAME=gpt-4o-mini
NEXT_PUBLIC_BACKEND_HOST=localhost
NEXT_PUBLIC_BACKEND_PORT=8000- Run Docker:
make dockerThis will:
- Create a Docker volume for persistent data
- Build the DocETL image
- Run the container with the UI accessible at http://localhost:3000
To clean up Docker resources (note that this will delete the Docker volume):
make docker-cleanFor development or if you prefer not to use Docker:
- Clone the repository:
git clone https://github.com/ucbepic/docetl.git
cd docetl- Set up environment variables in
.envin the root/top-level directory:
OPENAI_API_KEY=your_api_key_here
BACKEND_ALLOW_ORIGINS=http://localhost:3000,http://127.0.0.1:3000
BACKEND_HOST=localhost
BACKEND_PORT=8000
BACKEND_RELOAD=True
FRONTEND_HOST=0.0.0.0
FRONTEND_PORT=3000And create an .env.local file in the website directory with the following:
OPENAI_API_KEY=sk-xxx
OPENAI_API_BASE=https://api.openai.com/v1
MODEL_NAME=gpt-4o-mini
NEXT_PUBLIC_BACKEND_HOST=localhost
NEXT_PUBLIC_BACKEND_PORT=8000- Install dependencies:
make install # Install Python package
make install-ui # Install UI dependenciesNote that the OpenAI API key, base, and model name are for the UI assistant only; not the DocETL pipeline execution engine.
- Start the development server:
make run-ui-dev- Visit http://localhost:3000/playground to access the interactive UI.
If you're planning to contribute or modify DocETL, you can verify your setup by running the test suite:
make tests-basic # Runs basic test suite (costs < $0.01 with OpenAI)For detailed documentation and tutorials, visit our documentation.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for docetl
Similar Open Source Tools
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.
CoML
CoML (formerly MLCopilot) is an interactive coding assistant for data scientists and machine learning developers, empowered on large language models. It offers an out-of-the-box interactive natural language programming interface for data mining and machine learning tasks, integration with Jupyter lab and Jupyter notebook, and a built-in large knowledge base of machine learning to enhance the ability to solve complex tasks. The tool is designed to assist users in coding tasks related to data analysis and machine learning using natural language commands within Jupyter environments.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.
cover-agent
CodiumAI Cover Agent is a tool designed to help increase code coverage by automatically generating qualified tests to enhance existing test suites. It utilizes Generative AI to streamline development workflows and is part of a suite of utilities aimed at automating the creation of unit tests for software projects. The system includes components like Test Runner, Coverage Parser, Prompt Builder, and AI Caller to simplify and expedite the testing process, ensuring high-quality software development. Cover Agent can be run via a terminal and is planned to be integrated into popular CI platforms. The tool outputs debug files locally, such as generated_prompt.md, run.log, and test_results.html, providing detailed information on generated tests and their status. It supports multiple LLMs and allows users to specify the model to use for test generation.
nextjs-openai-doc-search
This starter project is designed to process `.mdx` files in the `pages` directory to use as custom context within OpenAI Text Completion prompts. It involves building a custom ChatGPT style doc search powered by Next.js, OpenAI, and Supabase. The project includes steps for pre-processing knowledge base, storing embeddings in Postgres, performing vector similarity search, and injecting content into OpenAI GPT-3 text completion prompt.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
LLM-Engineers-Handbook
The LLM Engineer's Handbook is an official repository containing a comprehensive guide on creating an end-to-end LLM-based system using best practices. It covers data collection & generation, LLM training pipeline, a simple RAG system, production-ready AWS deployment, comprehensive monitoring, and testing and evaluation framework. The repository includes detailed instructions on setting up local and cloud dependencies, project structure, installation steps, infrastructure setup, pipelines for data processing, training, and inference, as well as QA, tests, and running the project end-to-end.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.
langstream
LangStream is a tool for natural language processing tasks, providing a CLI for easy installation and usage. Users can try sample applications like Chat Completions and create their own applications using the developer documentation. It supports running on Kubernetes for production-ready deployment, with support for various Kubernetes distributions and external components like Apache Kafka or Apache Pulsar cluster. Users can deploy LangStream locally using minikube and manage the cluster with mini-langstream. Development requirements include Docker, Java 17, Git, Python 3.11+, and PIP, with the option to test local code changes using mini-langstream.
mint-bench
MINT benchmark aims to evaluate LLMs' ability to solve tasks with multi-turn interactions by (1) using tools and (2) leveraging natural language feedback.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.
telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.