
airbyte-platform
The platform that powers Airbyte. Please file issues in https://github.com/airbytehq/airbyte
Stars: 273

Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.
README:
Data integration platform for ELT pipelines from APIs, databases & files to databases, warehouses & lakes






We believe that only an open-source solution to data movement can cover the long tail of data sources while empowering data engineers to customize existing connectors. Our ultimate vision is to help you move data from any source to any destination. Airbyte already provides 300+ connectors for popular APIs, databases, data warehouses and data lakes.
Airbyte connectors can be implemented in any language and take the form of a Docker image that follows the Airbyte specification. You can create new connectors very fast with:
- The low-code Connector Development Kit (CDK) for API connectors (demo)
- The Python CDK (tutorial)
Airbyte has a built-in scheduler and uses Temporal to orchestrate jobs and ensure reliability at scale. Airbyte leverages dbt to normalize extracted data and can trigger custom transformations in SQL and dbt. You can also orchestrate Airbyte syncs with Airflow, Prefect, Dagster, or Kestra.

Explore our demo app.
Read the Quickstart documentation.
You can also programmatically manage sources, destinations, and connections with YAML files, Octavia CLI, and API.
Deployment options: Docker, AWS EC2, Azure, GCP, Kubernetes, Restack, Plural, Oracle Cloud, Digital Ocean...
Airbyte Cloud is the fastest and most reliable way to run Airbyte. You can get started with free credits in minutes.
Sign up for Airbyte Cloud.
Get started by checking Github issues and creating a Pull Request. An easy way to start contributing is to update an existing connector or create a new connector using the low-code and Python CDKs. You can find the code for existing connectors in the connectors directory. The Airbyte platform is written in Java, and the frontend in React. You can also contribute to our docs and tutorials. Advanced Airbyte users can apply to the Maintainer program and Writer Program.
Read the Contributing guide.
Airbyte takes security issues very seriously. If you have any concerns about Airbyte or believe you have uncovered a vulnerability, please get in touch via the e-mail address [email protected]. In the message, try to provide a description of the issue and ideally a way of reproducing it. The security team will get back to you as soon as possible.
Note that this security address should be used only for undisclosed vulnerabilities. Dealing with fixed issues or general questions on how to use the security features should be handled regularly via the user and the dev lists. Please report any security problems to us before disclosing it publicly.
See the LICENSE file for licensing information, and our FAQ for any questions you may have on that topic.
- Weekly office hours for live informal sessions with the Airbyte team
- Slack for quick discussion with the Community and Airbyte team
- Discourse for deeper conversations about features, connectors, and problems
- GitHub for code, issues and pull requests
- Youtube for videos on data engineering
- Newsletter for product updates and data news
- Blog for data insigts articles, tutorials and updates
- Docs for Airbyte features
- Roadmap for planned features
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for airbyte-platform
Similar Open Source Tools
airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.

HuggingFists
HuggingFists is a low-code data flow tool that enables convenient use of LLM and HuggingFace models. It provides functionalities similar to Langchain, allowing users to design, debug, and manage data processing workflows, create and schedule workflow jobs, manage resources environment, and handle various data artifact resources. The tool also offers account management for users, allowing centralized management of data source accounts and API accounts. Users can access Hugging Face models through the Inference API or locally deployed models, as well as datasets on Hugging Face. HuggingFists supports breakpoint debugging, branch selection, function calls, workflow variables, and more to assist users in developing complex data processing workflows.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.
posthog
PostHog is an all-in-one, open source platform for building successful products. It provides tools for product analytics, web analytics, session replays, feature flags, experiments, error tracking, surveys, data warehouse, data pipelines, LLM analytics, and workflows. Users can get started with a generous free tier, self-host the platform, or use PostHog Cloud. The platform supports various SDKs and libraries for popular languages and frameworks, making it versatile and easy to integrate. PostHog is suitable for teams looking to understand user behavior, improve product performance, and automate actions or messages to users.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.
PyAirbyte
PyAirbyte brings the power of Airbyte to every Python developer by providing a set of utilities to use Airbyte connectors in Python. It enables users to easily manage secrets, work with various connectors like GitHub, Shopify, and Postgres, and contribute to the project. PyAirbyte is not a replacement for Airbyte but complements it, supporting data orchestration frameworks like Airflow and Snowpark. Users can develop ETL pipelines and import connectors from local directories. The tool simplifies data integration tasks for Python developers.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.

onnx
Open Neural Network Exchange (ONNX) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types. Currently, we focus on the capabilities needed for inferencing (scoring). ONNX is widely supported and can be found in many frameworks, tools, and hardware, enabling interoperability between different frameworks and streamlining the path from research to production to increase the speed of innovation in the AI community. Join us to further evolve ONNX.
csghub
CSGHub is an open source platform for managing large model assets, including datasets, model files, and codes. It offers functionalities similar to a privatized Huggingface, managing assets in a manner akin to how OpenStack Glance manages virtual machine images. Users can perform operations such as uploading, downloading, storing, verifying, and distributing assets through various interfaces. The platform provides microservice submodules and standardized OpenAPIs for easy integration with users' systems. CSGHub is designed for large models and can be deployed On-Premise for offline operation.
data-formulator
Data Formulator is an AI-powered tool developed by Microsoft Research to help data analysts create rich visualizations iteratively. It combines user interface interactions with natural language inputs to simplify the process of describing chart designs while delegating data transformation to AI. Users can utilize features like blended UI and NL inputs, data threads for history navigation, and code inspection to create impressive visualizations. The tool supports local installation for customization and Codespaces for quick setup. Developers can build new data analysis tools on top of Data Formulator, and research papers are available for further reading.
csghub-server
CSGHub Server is a part of the open source and reliable large model assets management platform - CSGHub. It focuses on management of models, datasets, and other LLM assets through REST API. Key features include creation and management of users and organizations, auto-tagging of model and dataset labels, search functionality, online preview of dataset files, content moderation for text and image, download of individual files, tracking of model and dataset activity data. The tool is extensible and customizable, supporting different git servers, flexible LFS storage system configuration, and content moderation options. The roadmap includes support for more Git servers, Git LFS, dataset online viewer, model/dataset auto-tag, S3 protocol support, model format conversion, and model one-click deploy. The project is licensed under Apache 2.0 and welcomes contributions.

PulsarRPA
PulsarRPA is a high-performance, distributed, open-source Robotic Process Automation (RPA) framework designed to handle large-scale RPA tasks with ease. It provides a comprehensive solution for browser automation, web content understanding, and data extraction. PulsarRPA addresses challenges of browser automation and accurate web data extraction from complex and evolving websites. It incorporates innovative technologies like browser rendering, RPA, intelligent scraping, advanced DOM parsing, and distributed architecture to ensure efficient, accurate, and scalable web data extraction. The tool is open-source, customizable, and supports cutting-edge information extraction technology, making it a preferred solution for large-scale web data extraction.
naas
Naas (Notebooks as a service) is an open source platform that enables users to create powerful data engines combining automation, analytics, and AI from Jupyter notebooks. It offers features like templates for automated data jobs and reports, drivers for data connectivity, and production-ready environment with scheduling and notifications. Naas aims to provide an alternative to Google Colab with enhanced low-code layers.
For similar tasks

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.
airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.
airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.
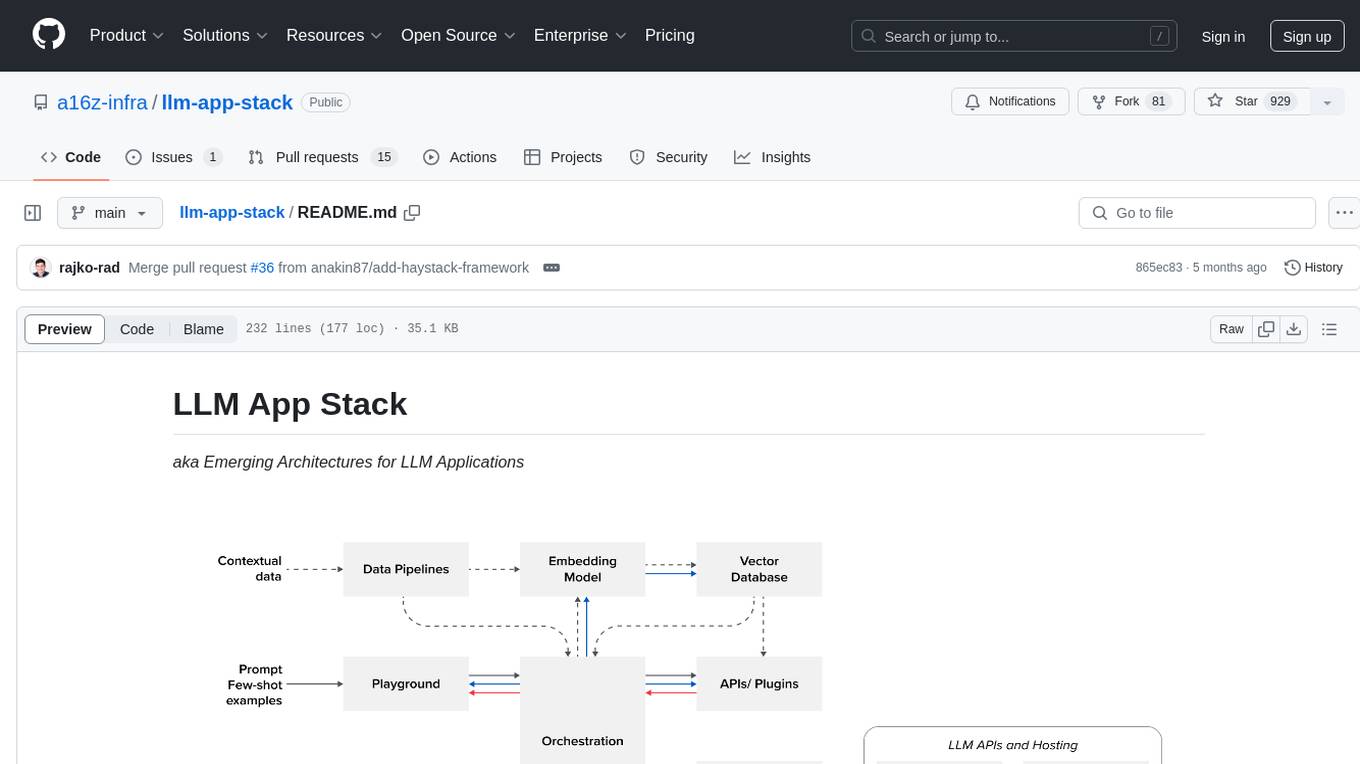
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
dataengineering-roadmap
A repository providing basic concepts, technical challenges, and resources on data engineering in Spanish. It is a curated list of free, Spanish-language materials found on the internet to facilitate the study of data engineering enthusiasts. The repository covers programming fundamentals, programming languages like Python, version control with Git, database fundamentals, SQL, design concepts, Big Data, analytics, cloud computing, data processing, and job search tips in the IT field.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.

terraform-provider-airbyte
Programatically control Airbyte Cloud through an API. Developers can create an API Key within the Developer Portal to make API requests. The provider allows for integration building by showing network request information and API usage details. It offers resources and data sources for various destinations and sources, enabling users to manage data flow between different services.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.
airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.