
metaflow
Build, Manage and Deploy AI/ML Systems
Stars: 8693

Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.
README:

Metaflow is a human-centric framework designed to help scientists and engineers build and manage real-life AI and ML systems. Serving teams of all sizes and scale, Metaflow streamlines the entire development lifecycle—from rapid prototyping in notebooks to reliable, maintainable production deployments—enabling teams to iterate quickly and deliver robust systems efficiently.
Originally developed at Netflix and now supported by Outerbounds, Metaflow is designed to boost the productivity for research and engineering teams working on a wide variety of projects, from classical statistics to state-of-the-art deep learning and foundation models. By unifying code, data, and compute at every stage, Metaflow ensures seamless, end-to-end management of real-world AI and ML systems.
Today, Metaflow powers thousands of AI and ML experiences across a diverse array of companies, large and small, including Amazon, Doordash, Dyson, Goldman Sachs, Ramp, and many others. At Netflix alone, Metaflow supports over 3000 AI and ML projects, executes hundreds of millions of data-intensive high-performance compute jobs processing petabytes of data and manages tens of petabytes of models and artifacts for hundreds of users across its AI, ML, data science, and engineering teams.
Metaflow provides a simple and friendly pythonic API that covers foundational needs of AI and ML systems:

- Rapid local prototyping, support for notebooks, and built-in support for experiment tracking, versioning and visualization.
- Effortlessly scale horizontally and vertically in your cloud, utilizing both CPUs and GPUs, with fast data access for running massive embarrassingly parallel as well as gang-scheduled compute workloads reliably and efficiently.
- Easily manage dependencies and deploy with one-click to highly available production orchestrators with built in support for reactive orchestration.
For full documentation, check out our API Reference or see our Release Notes for the latest features and improvements.
Getting up and running is easy. If you don't know where to start, Metaflow sandbox will have you running and exploring in seconds.
To install Metaflow in your Python environment from PyPI:
pip install metaflowAlternatively, using conda-forge:
conda install -c conda-forge metaflowOnce installed, a great way to get started is by following our tutorial. It walks you through creating and running your first Metaflow flow step by step.
For more details on Metaflow’s features and best practices, check out:
If you need help, don’t hesitate to reach out on our Slack community!

While you can get started with Metaflow easily on your laptop, the main benefits of Metaflow lie in its ability to scale out to external compute clusters and to deploy to production-grade workflow orchestrators. To benefit from these features, follow this guide to configure Metaflow and the infrastructure behind it appropriately.
We'd love to hear from you. Join our community Slack workspace!
We welcome contributions to Metaflow. Please see our contribution guide for more details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for metaflow
Similar Open Source Tools
metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.
InferenceMAX
InferenceMAX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks and models. It runs a suite of benchmarks every night to capture progress in near real-time, providing a live indicator of inference performance. The tool addresses the challenge of rapidly evolving software ecosystems by benchmarking the latest software packages, ensuring that benchmarks do not go stale. InferenceMAX™ is supported by industry leaders and contributors, providing transparent and reproducible benchmarks that help the ML community make informed decisions about hardware and software performance.
foundationallm
FoundationaLLM is a platform designed for deploying, scaling, securing, and governing generative AI in enterprises. It allows users to create AI agents grounded in enterprise data, integrate REST APIs, experiment with large language models, centrally manage AI agents and assets, deploy scalable vectorization data pipelines, enable non-developer users to create their own AI agents, control access with role-based access controls, and harness capabilities from Azure AI and Azure OpenAI. The platform simplifies integration with enterprise data sources, provides fine-grain security controls, load balances across multiple endpoints, and is extensible to new data sources and orchestrators. FoundationaLLM addresses the need for customized copilots or AI agents that are secure, licensed, flexible, and suitable for enterprise-scale production.
foundationallm
FoundationaLLM is a platform designed for deploying, scaling, securing, and governing generative AI in enterprises. It allows users to create AI agents grounded in enterprise data, integrate REST APIs, experiment with various large language models, centrally manage AI agents and their assets, deploy scalable vectorization data pipelines, enable non-developer users to create their own AI agents, control access with role-based access controls, and harness capabilities from Azure AI and Azure OpenAI. The platform simplifies integration with enterprise data sources, provides fine-grain security controls, scalability, extensibility, and addresses the challenges of delivering enterprise copilots or AI agents.
motleycrew
Motleycrew is an ultimate framework for building multi-agent AI systems, allowing users to mix and match AI agents and tools from popular frameworks, design advanced workflows, and leverage dynamic knowledge graphs with simplicity and elegance. It acts as a conductor orchestrating a symphony of AI agents and tools, providing building blocks for creating AI systems and enabling users to focus on high-level design while taking care of the rest. The framework offers integration with various tools, flexibility in providing agents with tools or other agents, advanced flow design capabilities, and built-in observability and caching features.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.
examples
This repository contains a collection of sample applications and Jupyter Notebooks for hands-on experience with Pinecone vector databases and common AI patterns, tools, and algorithms. It includes production-ready examples for review and support, as well as learning-optimized examples for exploring AI techniques and building applications. Users can contribute, provide feedback, and collaborate to improve the resource.
csghub
CSGHub is an open source platform for managing large model assets, including datasets, model files, and codes. It offers functionalities similar to a privatized Huggingface, managing assets in a manner akin to how OpenStack Glance manages virtual machine images. Users can perform operations such as uploading, downloading, storing, verifying, and distributing assets through various interfaces. The platform provides microservice submodules and standardized OpenAPIs for easy integration with users' systems. CSGHub is designed for large models and can be deployed On-Premise for offline operation.
ai-hub
The Enterprise Azure OpenAI Hub is a comprehensive repository designed to guide users through the world of Generative AI on the Azure platform. It offers a structured learning experience to accelerate the transition from concept to production in an Enterprise context. The hub empowers users to explore various use cases with Azure services, ensuring security and compliance. It provides real-world examples and playbooks for practical insights into solving complex problems and developing cutting-edge AI solutions. The repository also serves as a library of proven patterns, aligning with industry standards and promoting best practices for secure and compliant AI development.
Build-Modern-AI-Apps
This repository serves as a hub for Microsoft Official Build & Modernize AI Applications reference solutions and content. It provides access to projects demonstrating how to build Generative AI applications using Azure services like Azure OpenAI, Azure Container Apps, Azure Kubernetes, and Azure Cosmos DB. The solutions include Vector Search & AI Assistant, Real-Time Payment and Transaction Processing, and Medical Claims Processing. Additionally, there are workshops like the Intelligent App Workshop for Microsoft Copilot Stack, focusing on infusing intelligence into traditional software systems using foundation models and design thinking.
god-level-ai
A drill of scientific methods, processes, algorithms, and systems to build stories & models. An in-depth learning resource for humans. This is a drill for people who aim to be in the top 1% of Data and AI experts. The repository provides a routine for deep and shallow work sessions, covering topics from Python to AI/ML System Design and Personal Branding & Portfolio. It emphasizes the importance of continuous effort and action in the tech field.
AI-Engineer-Headquarters
AI Engineer Headquarters is a comprehensive learning resource designed to help individuals master scientific methods, processes, algorithms, and systems to build stories and models in the field of Data and AI. The repository provides in-depth content through video sessions and text materials, catering to individuals aspiring to be in the top 1% of Data and AI experts. It covers various topics such as AI engineering foundations, large language models, retrieval-augmented generation, fine-tuning LLMs, reinforcement learning, ethical AI, agentic workflows, and career acceleration. The learning approach emphasizes action-oriented drills and routines, encouraging consistent effort and dedication to excel in the AI field.
partykit
PartyServer is a repository containing libraries, examples, and documentation for building real-time apps with Cloudflare Workers. It includes core libraries for working with Durable Objects, WebSockets, Yjs support for real-time collaborative editing, pubsub at scale, state synchronization, and task scheduling. The repository also offers small examples in the `fixtures` directory to demonstrate usage. PartyServer aims to simplify the development of real-time applications by providing enhanced features and utilities for working with various technologies.
ai_gallery
AI Gallery is a showcase site built using React and Nextjs for static site generation, featuring interactive visualizations of classic algorithms, classic games implementation, and various interesting widgets. The project utilizes AI assistance from Claude 3.5 and GPT-4 to create components and enhance the development process. It aims to continually add more components with AI assistance, providing a platform for contributors to leverage AI in frontend development.
farmvibes-ai
FarmVibes.AI is a repository focused on developing multi-modal geospatial machine learning models for agriculture and sustainability. It enables users to fuse various geospatial and spatiotemporal datasets, such as satellite imagery, drone imagery, and weather data, to generate robust insights for agriculture-related problems. The repository provides fusion workflows, data preparation tools, model training notebooks, and an inference engine to facilitate the creation of geospatial models tailored for agriculture and farming. Users can interact with the tools via a local cluster, REST API, or a Python client, and the repository includes documentation and notebook examples to guide users in utilizing FarmVibes.AI for tasks like harvest date detection, climate impact estimation, micro climate prediction, and crop identification.
FedML
FedML is a unified and scalable machine learning library for running training and deployment anywhere at any scale. It is highly integrated with FEDML Nexus AI, a next-gen cloud service for LLMs & Generative AI. FEDML Nexus AI provides holistic support of three interconnected AI infrastructure layers: user-friendly MLOps, a well-managed scheduler, and high-performance ML libraries for running any AI jobs across GPU Clouds.
For similar tasks

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.
metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.
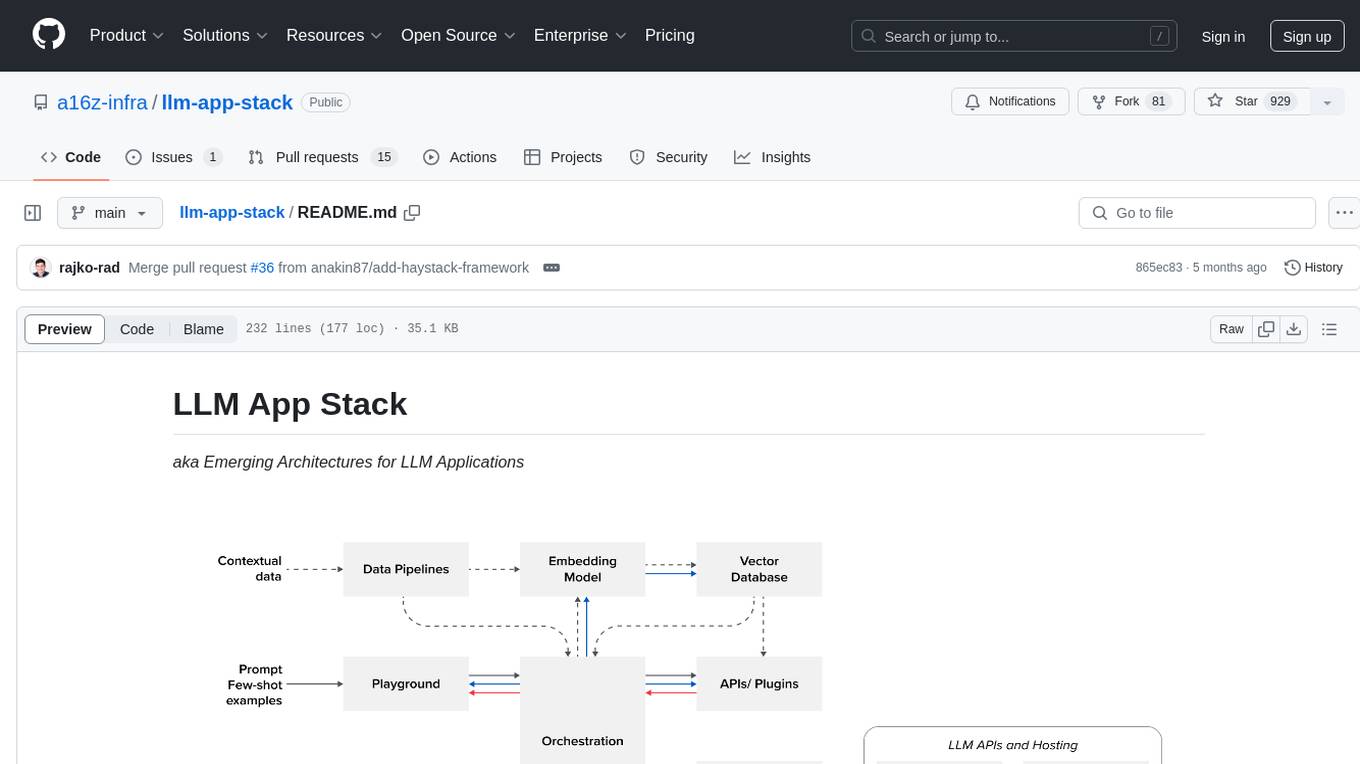
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
dataengineering-roadmap
A repository providing basic concepts, technical challenges, and resources on data engineering in Spanish. It is a curated list of free, Spanish-language materials found on the internet to facilitate the study of data engineering enthusiasts. The repository covers programming fundamentals, programming languages like Python, version control with Git, database fundamentals, SQL, design concepts, Big Data, analytics, cloud computing, data processing, and job search tips in the IT field.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.

terraform-provider-airbyte
Programatically control Airbyte Cloud through an API. Developers can create an API Key within the Developer Portal to make API requests. The provider allows for integration building by showing network request information and API usage details. It offers resources and data sources for various destinations and sources, enabling users to manage data flow between different services.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.