
llm-app-stack
None
Stars: 929
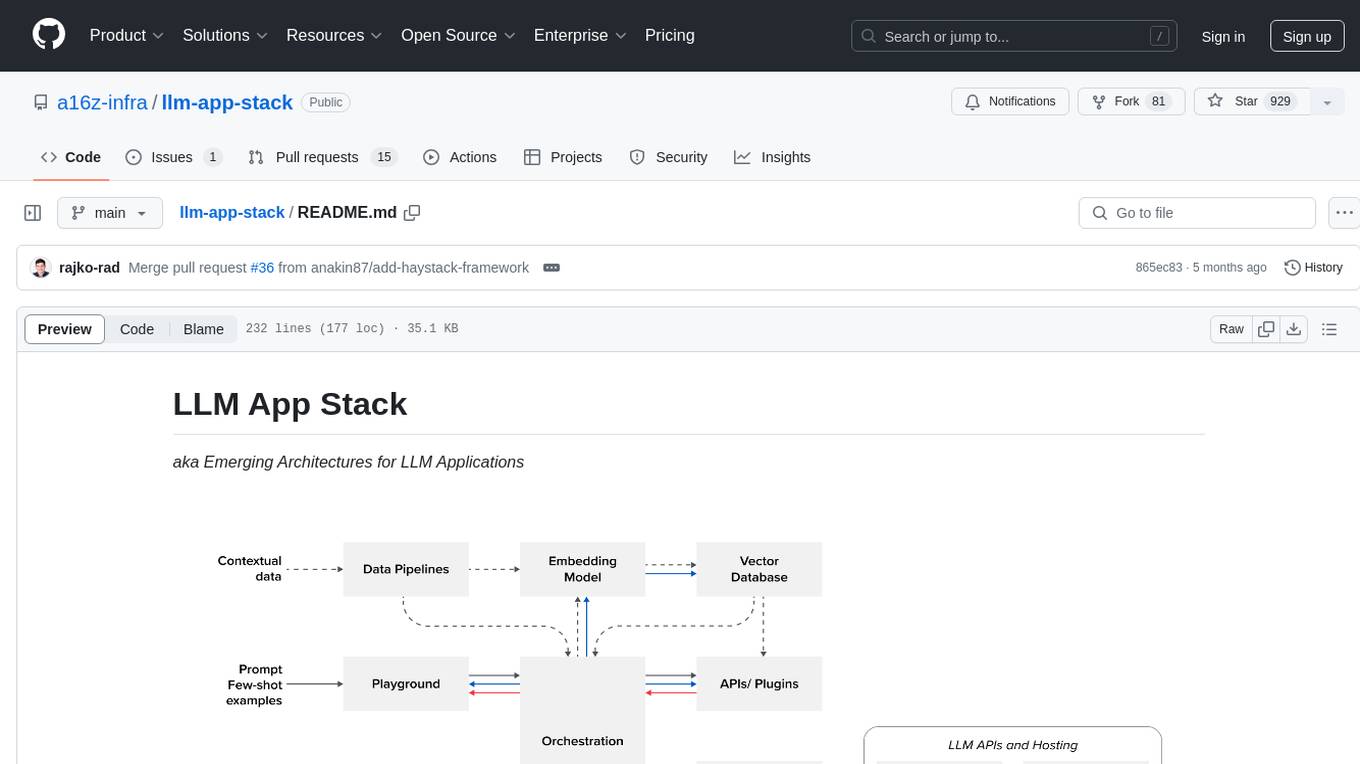
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
README:
aka Emerging Architectures for LLM Applications
This is a list of available tools, projects, and vendors at each layer of the LLM app stack.
Our original article included only the most popular options, based on user interviews. This repo is meant to be more comprehensive, covering all available options in each category. We probably still missed some important projects, so please open a PR if you see anything missing.
We also included Perplexity and Cursor.sh prompts to make searching and markdown table formatting easier.
- Data Pipelines
- Embedding Models
- Vector Databases
- Playgrounds
- Orchestrators
- APIs / Plugins
- LLM Caches
- Logging / Monitoring / Eval
- Validators
- LLM APIs (proprietary)
- LLM APIs (open source)
- App Hosting Platforms
- Cloud Providers
- Opinionated Clouds
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| Databricks | A unified data platform for building, deploying, and maintaining enterprise data solutions, including products (like MosaicML and MLflow) purpose-built for AI |  |
 |
| Airflow | A data pipeline framework to programmatically author, schedule, and monitor data pipelines and workflows, including for LLMs |  |
 |
| Unstructured.io | Open-source components for pre-processing documents such as PDFs, HTML, and Word documents for usage with LLM apps |  |
 |
| Fivetran | A platform that extracts, loads, and transforms data from various sources for analytics, AI, and operations | N/A |  |
| Airbyte | An open-source data integration engine that helps consolidate data in data warehouses, lakes, and databases |  |
 |
| Anyscale | An AI compute platform that allows developers to scale data ingest, preprocessing, embedding, and inference computations using Ray |  |
 |
| Alluxio | An open-source data platform at the intersection of compute and storage, bringing data closer to compute, to accelerate model training and serving, boost GPU utilization, and reduce costs for AI workloads |  |
 |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| OpenAI Ada Embedding 2 | OpenAI's most popular embedding model for capturing semantic relationships in text | n/a |  |
| Cohere AI | An independent commerical provider of LLMs, with particular focus on embeddings for semantic search, topic clustering, and vertical applications |  |
 |
| Sentence Transformers | An open-source Python framework for sentence, text, and image embeddings |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| Pinecone | A managed, cloud-native vector database with a simple API for high-performance AI applications | n/a |  |
| Weaviate | An open-source vector database that stores both objects and vectors |  |
 |
| ChromaDB | An AI-native, open-source embedding database platform for developers |  |
 |
| Pgvector | An open-source vector similarity search for Postgres, allowing for exact and approximate nearest-neighbor search |  |
 |
| Zilliz (Milvus) | An open-source vector database, built for developing and maintaining AI applications |  |
 |
| Qdrant | A vector database and vector similarity search engine |  |
 |
| Metal io | A managed service for developers to build applications with ML embeddings | N/A |  |
| LanceDB | A serverless vector database for AI applications |  |
 |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| OpenAI Playground | A web-based platform for experimenting with various machine-learning models developed by OpenAI | N/A | N/A |
| nat.dev | A platform that allows users to test prompts with multiple language models and compare their performance |  |
 |
| Humanloop | A platform that helps developers build applications on top of LLMs |  |
 |
| Parea AI | Platform and SDK for AI Engineers providing tools for LLM evaluation, observability, and a version-controlled enhanced prompt playground. |  |
 |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| Langchain | An open-source library that gives developers the tools to build applications powered by LLMs |  |
 |
| LlamaIndex | A data framework for LLM applications to ingest, structure, and access private or domain-specific data |  |
 |
| Autogen | A framework for automating and streamlining LLM workflows using customizable, conversable agents for complex AI applications |  |
 |
| Microsoft Semantic Kernel | A lightweight open-source orchestration SDK |  |
 |
| Haystack | LLM orchestration framework to build customizable, production-ready LLM applications |  |
 |
| Vercel AI SDK | An open-source library for developers to build streaming UIs in JavaScript and TypeScript |  |
 (node/npm) (node/npm) |
| Vectara AI | A search and discovery platform for AI conversations utilizing your own data |  |
N/A |
| ChatGPT | An AI chatbot that uses natural language processing to create humanlike conversational dialogue | N/A | N/A |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| Serp API | A real-time API to access Google search results, as well as handling proxies, solving captchas, and parsing structured data |  |
 |
| Wolfram Alpha API | A web-based API providing computational and presentation capabilities for integration into various applications | N/A |  |
| Zapier API AI Plugin | A plugin that allows you to connect 5,000+ apps and interact with them directly inside ChatGPT | N/A | N/A |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| Redis | An in-memory data structure store used as a database, cache, message broker, and streaming engine |  |
 |
| SQLite | A self-contained, serverless, zero-configuration, transactional SQL database engine |  |
 |
| GPTCache | An open-source tool for improving the efficiency and speed of GPT-based applications by implementing a cache to store the responses |  |
N/A |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| Braintrust Data | An AI product stack featuring evaluations, prompt playgrounds, continuous integration, dataset management, and access to various AI models through a single API |  |
 |
| Arize AI | An observability platform for both LLMs and supervised ML |  |
 |
| Weights & Biases | An MLOps platform for streamlining ML workflows |  |
 |
| MLflow | A platform to streamline ML development |  |
 |
| PromptLayer | A platform for tracking, managing, and sharing LLM prompt engineering |  |
 |
| Helicone | An open-source observability platform for LLMs |  |
 |
| Quotient AI | Quotient AI is a platform for evaluating AI products on real-world use-cases, during research, development, and in production | N/A | N/A |
| Portkey AI | A platform to develop, launch, maintain, and iterate generative AI apps and features | N/A | N/A |
| Freeplay AI | A platform to prototype, test, and optimize LLM features for customers | N/A | N/A |
| Gentrace | An API and SDKs for evaluating and observing generative data, with features like AI, heuristic, and human grading evaluations, as well as production data observation | N/A |  |
| Patronus AI | An automated evaluation and benchmarking platform for LLMs, providing tools for testing, scoring, and evaluating LLMs in real-world scenarios | N/A | N/A |
| Autoblocks AI | A collaborative cloud-based workspace designed for rapid iteration on GenAI products, offering features like prompt management, observability, continuous evaluations, fine-tuning, prototyping, debugging, and scalable data ingestion & search, all in a provider-agnostic environment | N/A |  |
| Context AI | Tools for pre-launch LLM evaluations and post-launch analytics, with features such as testing, performance monitoring, user conversation analysis, and support for various models and libraries | N/A |  |
| E2b dev | Services to deploy, test, and monitor AI agents, including a sandbox with a secure, long-running cloud environment for various LLMs with features like internet access |  |
 |
| Agentops | Toolkit for evaluating and developing AI agents, providing tools for agent development, monitoring capabilities, and replay analytics |  |
 |
| Zenoml | AI evaluation platform that enables data visualization, model performance analysis, and the creation of interactive reports for various data types |  |
 |
| Baserun | Tools for model configuration, prompt playground, monitoring, and prototype workflow, as well as features for full visibility into LLM workflows and end-to-end testing |  |
 |
| WhyLabs | AI Observability platform for ML and GenAI including LLM monitoring, guardrails and security |  |
 |
| Log10 | AI-powered LLMOps platform that automatically optimizes prompts and models with built-in logging, debugging, metrics, feedback, evaluations and fine-tuning |
 |
 
|
| promptfoo | Open-source LLM eval framework with support for model/prompt/RAG eval, dataset generation, local models, and self-hosting. |  |
 (node/npm) (node/npm) |
| Parea AI | Platform and SDK for AI Engineers providing tools for LLM evaluation, observability, and a version-controlled enhanced prompt playground. | |
|
| Galileo | Galileo is a platform for evaluation, fine-tuning and real-time observability, powered by high-accuracy hallucination guardrails. | N/A | N/A |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| Guardrails AI | An open-source Python package for specifying structure and type, validating, and correcting the outputs of LLMs |  |
 |
| Rebuff | An open-source framework designed to detect and protect against prompt injection attacks in LLM apps |  |
 |
| Microsoft Guidance | A guidance language for controlling LLMs, providing a syntax for architecting LLM workflows |  |
 |
| LMQL | An open-source programming language and platform for language model interaction |  |
 |
| Outlines | A tool for helping developers guide text generation to build robust interfaces with external systems and guarantee that outputs match a regex or JSON schema |  |
 |
| LLM Guard | An open-source, comprehensive tool designed to fortify the security of Large Language Models (LLMs). |  |
 |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| OpenAI | A company providing many leading LLMs, including the GPT-3.5 and GPT-4 families | N/A | |
| Anthropic | The developer of Claude, an AI assistant based on Anthropic’s research | N/A |  |
| Cohere AI | An LLM vendor with particular focus on embeddings for semantic search, topic clustering, and vertical applications | |
|
| LLM | A CLI utility and Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your own machine. |  |
 |
| Name (site) | Description | Github | Pip Installs |
|---|---|---|---|
| Hugging Face | A hub for open-source AI models and inference endpoints, including leading base LLMs and LoRAs/fine-tunes | ||
| Replicate | An AI hosting platform and model inference hub that allows software developers to integrate AI models into their apps |  |
 |
| Anyscale | An AI API and compute platform that allows developers to scale inference, training, and embedding computations with any model using Ray | |
|
| Ollama | Get up and running with large language models locally |  |
 |
| GPT4ALL | An ecosystem of open-source on-edge large language models. |  |
 |
| Name (site) | Description |
|---|---|
| Vercel | A cloud platform designed for front-end engineers, built with first-class support for LLM apps |
| Netlify | An enterprise cloud computing company that offers a development platform for web applications and dynamic websites |
| Steamship | An SDK and hosting platform for AI agents and tools, both a package manager and package hosting service for AI |
| Streamlit | An open-source Python library designed for creating and sharing custom web apps for ML and data science |
| Modal | A platform that enables running distributed applications using the modal Python package |
| Name (site) | Description |
|---|---|
| Amazon Web Services | A cloud computing platform, offering services from data centers globally |
| Google Cloud Platform | A cloud computing platform, offering services from data centers globally |
| Microsoft Azure | A cloud computing platform, offering services from data centers globally |
| CoreWeave | A specialized cloud provider that delivers GPUs on top of flexible deployment infrastructure |
| Name (site) | Description |
|---|---|
| Databricks (MosaicML) | Databricks acquired Mosaic ML in 2023, along with its tooling and platform for efficient pre-trainining, fine-tuning and inferencing LLMs |
| Anyscale | An AI compute platform that enables developers to scale inference, training, and embedding computations with any model using Ray |
| Modal | A platform that eables running distributed applications using the Modal Python package |
| Runpod | A cloud computing platform designed for AI and ML applications |
| OctoML | A compute service that allows users to run, tune, and scale generative models |
| Baseten | A inference service that allows users to deploy, serve, and scale custom and open-source models |
| E2B | Secure sandboxed cloud environments made for AI agents and AI apps |
We were able to partialy automate this - particularly finding Github and PyPI links - using this Perplexity search prompt. It worked roughly ~75% of the time and could handle ~3 projects at a time, pulling data from 20-30 sources in each iteration.
Once you have the data you would like to add, if you don't want deal with the markdown formatting here, it is easy to correctly format using a tool like Cursor.
See the prompt below that works as an inline edit, just make sure you highlight 4-5 previous examples so Cursor can infer the format itself:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-app-stack
Similar Open Source Tools
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
awesome-open-data-annotation
At ZenML, we believe in the importance of annotation and labeling workflows in the machine learning lifecycle. This repository showcases a curated list of open-source data annotation and labeling tools that are actively maintained and fit for purpose. The tools cover various domains such as multi-modal, text, images, audio, video, time series, and other data types. Users can contribute to the list and discover tools for tasks like named entity recognition, data annotation for machine learning, image and video annotation, text classification, sequence labeling, object detection, and more. The repository aims to help users enhance their data-centric workflows by leveraging these tools.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.

AstrBot
AstrBot is an open-source one-stop Agentic chatbot platform and development framework. It supports large model conversations, multiple messaging platforms, Agent capabilities, plugin extensions, and WebUI for visual configuration and management of the chatbot.

awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
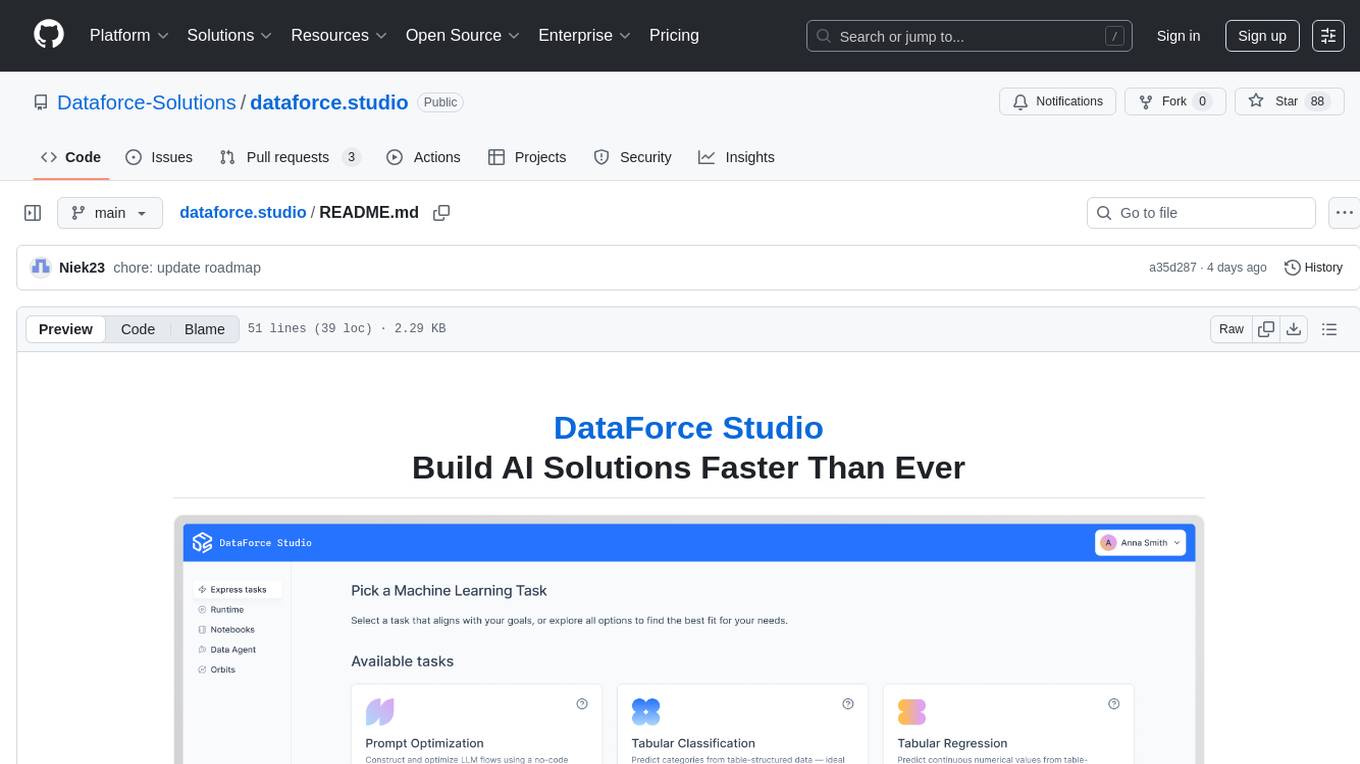
dataforce.studio
DataForce Studio is an open-source MLOps platform designed to help build, manage, and deploy AI/ML models with ease. It supports the entire model lifecycle, from creation to deployment and monitoring, within a user-friendly interface. The platform is in active early development, aiming to provide features like post-deployment monitoring, model deployment, data science agent, experiment snapshots, model cards, Python SDK, model registry, notebooks, in-browser runtime, and express tasks for prompt optimization and tabular data.

unstract
Unstract is a no-code platform that enables users to launch APIs and ETL pipelines to structure unstructured documents. With Unstract, users can go beyond co-pilots by enabling machine-to-machine automation. Unstract's Prompt Studio provides a simple, no-code approach to creating prompts for LLMs, vector databases, embedding models, and text extractors. Users can then configure Prompt Studio projects as API deployments or ETL pipelines to automate critical business processes that involve complex documents. Unstract supports a wide range of LLM providers, vector databases, embeddings, text extractors, ETL sources, and ETL destinations, providing users with the flexibility to choose the best tools for their needs.
awesome-generative-ai-data-scientist
A curated list of 50+ resources to help you become a Generative AI Data Scientist. This repository includes resources on building GenAI applications with Large Language Models (LLMs), and deploying LLMs and GenAI with Cloud-based solutions.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
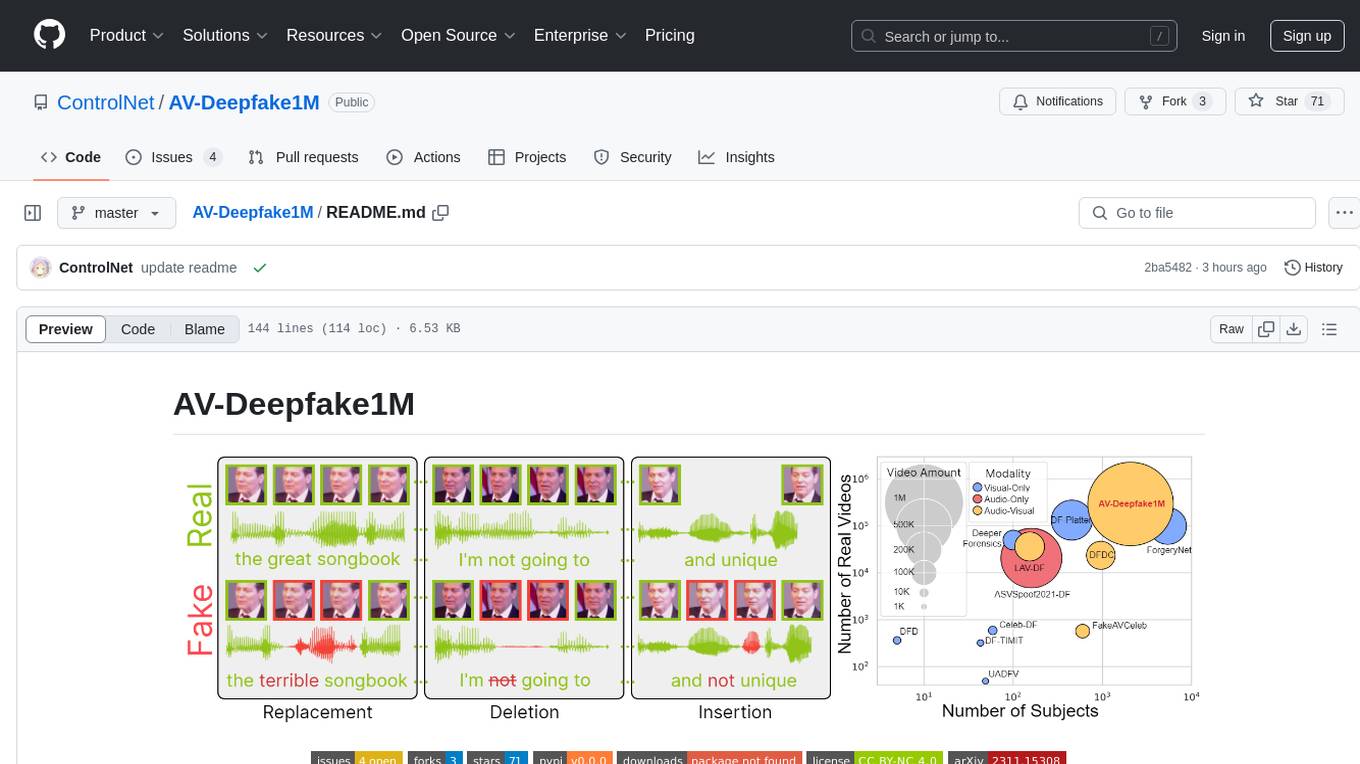
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.
Topu-ai
TOPU Md is a simple WhatsApp user bot created by Topu Tech. It offers various features such as multi-device support, AI photo enhancement, downloader commands, hidden NSFW commands, logo commands, anime commands, economy menu, various games, and audio/video editor commands. Users can fork the repo, get a session ID by pairing code, and deploy on Heroku. The bot requires Node version 18.x or higher for optimal performance. Contributions to TOPU-MD are welcome, and the tool is safe for use on WhatsApp and Heroku. The tool is licensed under the MIT License and is designed to enhance the WhatsApp experience with diverse features.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.
For similar tasks

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
dataengineering-roadmap
A repository providing basic concepts, technical challenges, and resources on data engineering in Spanish. It is a curated list of free, Spanish-language materials found on the internet to facilitate the study of data engineering enthusiasts. The repository covers programming fundamentals, programming languages like Python, version control with Git, database fundamentals, SQL, design concepts, Big Data, analytics, cloud computing, data processing, and job search tips in the IT field.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.

terraform-provider-airbyte
Programatically control Airbyte Cloud through an API. Developers can create an API Key within the Developer Portal to make API requests. The provider allows for integration building by showing network request information and API usage details. It offers resources and data sources for various destinations and sources, enabling users to manage data flow between different services.
For similar jobs
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
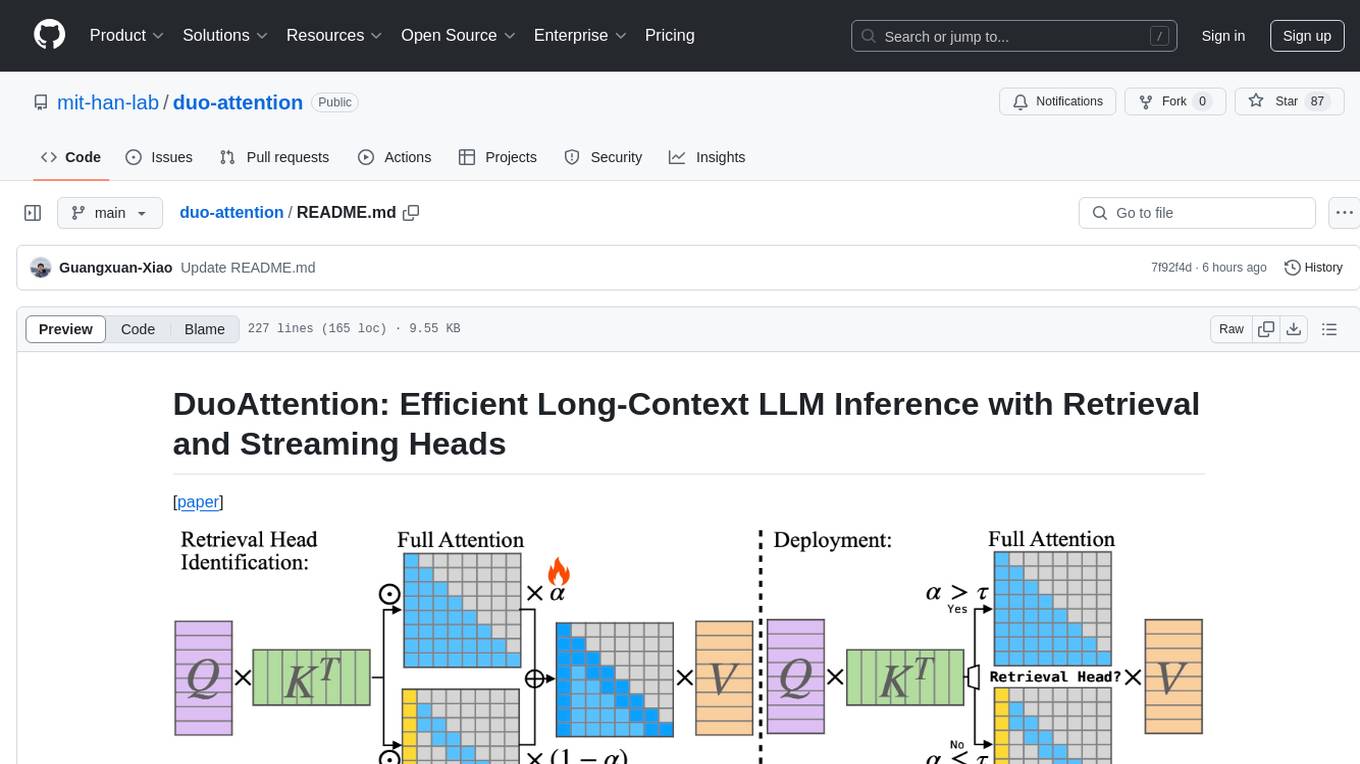
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
llm_note
LLM notes repository contains detailed analysis on transformer models, language model compression, inference and deployment, high-performance computing, and system optimization methods. It includes discussions on various algorithms, frameworks, and performance analysis related to large language models and high-performance computing. The repository serves as a comprehensive resource for understanding and optimizing language models and computing systems.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.