
Awesome-Resource-Efficient-LLM-Papers
a curated list of high-quality papers on resource-efficient LLMs 🌱
Stars: 105

A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
README:

This is the GitHub repo for our survey paper Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models.
⭐ If you find our repo helpful, please consider starring ⭐ it—we’d really appreciate your support! ⭐
- Awesome Resource-Efficient LLM Papers
| Date | Keywords | Paper | Venue |
|---|---|---|---|
| 2025 | Mixed Precision Training | Towards Efficient Pre-training: Exploring FP4 Precision in Large Language Models | Arxiv |
| 2024 | Mixed Precision Training | FP8-LM: Training FP8 Large Language Models | Arxiv |
| 2022 | Mixed Precision Training | BLOOM: A 176B-Parameter Open-Access Multilingual Language Model | Arxiv |
| 2018 | Mixed Precision Training | Bert: Pre-training of deep bidirectional transformers for language understanding | ACL |
| 2017 | Mixed Precision Training | Mixed Precision Training | ICLR |
| Date | Keywords | Paper | Venue |
|---|---|---|---|
| 2024 | Data Augmentation | LLMRec: Large Language Models with Graph Augmentation for Recommendation | WSDM |
| 2024 | Data augmentation | LLM-DA: Data Augmentation via Large Language Models for Few-Shot Named Entity Recognition | Arxiv |
| 2023 | Data augmentation | MixGen: A New Multi-Modal Data Augmentation | WACV |
| 2023 | Data augmentation | Augmentation-Aware Self-Supervision for Data-Efficient GAN Training | NeurIPS |
| 2023 | Data augmentation | Improving End-to-End Speech Processing by Efficient Text Data Utilization with Latent Synthesis | EMNLP |
| 2023 | Data augmentation | FaMeSumm: Investigating and Improving Faithfulness of Medical Summarization | EMNLP |
| Date | Keywords | Paper | Venue |
|---|---|---|---|
| 2023 | Training objective | Challenges and Applications of Large Language Models | Arxiv |
| 2023 | Training objective | Efficient Data Learning for Open Information Extraction with Pre-trained Language Models | EMNLP |
| 2023 | Masked language-image modeling | Scaling Language-Image Pre-training via Masking | CVPR |
| 2022 | Masked image modeling | Masked Autoencoders Are Scalable Vision Learners | CVPR |
| 2019 | Masked language modeling | MASS: Masked Sequence to Sequence Pre-training for Language Generation | ICML |
| Date | Keywords | Paper | Venue |
|---|---|---|---|
| 2023 | Other Systems | Tabi: An Efficient Multi-Level Inference System for Large Language Models | EuroSys |
| 2023 | Other Systems | Near-Duplicate Sequence Search at Scale for Large Language Model Memorization Evaluation | PACMMOD |
| Metric | Description | Example Usage |
|---|---|---|
| FLOPs (Floating-point operations) | the number of arithmetic operations on floating-point numbers | [FLOPs] |
| Training Time | the total duration required for training, typically measured in wall-clock minutes, hours, or days |
[minutes, days] [hours] |
| Inference Time/Latency | the average time required to generate an output after receiving an input, typically measured in wall-clock time or CPU/GPU/TPU clock time in milliseconds or seconds |
[end-to-end latency in seconds] [next token generation latency in milliseconds] |
| Throughput | the rate of output tokens generation or tasks completion, typically measured in tokens per second (TPS) or queries per second (QPS) |
[tokens/s] [queries/s] |
| Speed-Up Ratio | the improvement in inference speed compared to a baseline model |
[inference time speed-up] [throughput speed-up] |
| Metric | Description | Example Usage |
|---|---|---|
| Number of Parameters | the number of adjustable variables in the LLM’s neural network | [number of parameters] |
| Model Size | the storage space required for storing the entire model | [peak memory usage in GB] |
| Metric | Description | Example Usage |
|---|---|---|
| Energy Consumption | the electrical power used during the LLM’s lifecycle | [kWh] |
| Carbon Emission | the greenhouse gas emissions associated with the model’s energy usage | [kgCO2eq] |
The following are available software packages designed for real-time tracking of energy consumption and carbon emissions.
You might also find the following helpful for predicting the energy usage and carbon footprint before actual training or
| Metric | Description | Example Usage |
|---|---|---|
| Dollars per parameter | the total cost of training (or running) the LLM by the number of parameters |
| Metric | Description | Example Usage |
|---|---|---|
| Communication Volume | the total amount of data transmitted across the network during a specific LLM execution or training run | [communication volume in TB] |
| Metric | Description | Example Usage |
|---|---|---|
| Compression Ratio | the reduction in the size of the compressed model compared to the original model |
[compress rate] [percentage of weights remaining] |
| Loyalty/Fidelity | the resemblance between the teacher and student models in terms of both prediction consistency and predicted probability distributions alignment |
[loyalty] [fidelity] |
| Robustness | the resistance to adversarial attacks, where slight input modifications can potentially manipulate the model's output | [after-attack accuracy, query number] |
| Pareto Optimality | the optimal trade-offs between various competing factors |
[Pareto frontier (cost and accuracy)] [Pareto frontier (performance and FLOPs)] |
| Benchmark | Description | Paper |
|---|---|---|
| General NLP Benchmarks | an extensive collection of general NLP benchmarks such as GLUE, SuperGLUE, WMT, and SQuAD, etc. | A Comprehensive Overview of Large Language Models |
| Dynaboard | an open-source platform for evaluating NLP models in the cloud, offering real-time interaction and a holistic assessment of model quality with customizable Dynascore | Dynaboard: An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking |
| EfficientQA | an open-domain Question Answering (QA) challenge at NeurIPS 2020 that focuses on building accurate, memory-efficient QA systems | NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned |
| SustaiNLP 2020 Shared Task | a challenge for development of energy-efficient NLP models by assessing their performance across eight NLU tasks using SuperGLUE metrics and evaluating their energy consumption during inference | Overview of the SustaiNLP 2020 Shared Task |
| ELUE (Efficient Language Understanding Evaluation) | a benchmark platform for evaluating NLP model efficiency across various tasks, offering online metrics and requiring only a Python model definition file for submission | Towards Efficient NLP: A Standard Evaluation and A Strong Baseline |
| VLUE (Vision-Language Understanding Evaluation) | a comprehensive benchmark for assessing vision-language models across multiple tasks, offering an online platform for evaluation and comparison | VLUE: A Multi-Task Benchmark for Evaluating Vision-Language Models |
| Long Range Arena (LAG) | a benchmark suite evaluating efficient Transformer models on long-context tasks, spanning diverse modalities and reasoning types while allowing evaluations under controlled resource constraints, highlighting real-world efficiency | Long Range Arena: A Benchmark for Efficient Transformers |
| Efficiency-aware MS MARCO | an enhanced MS MARCO information retrieval benchmark that integrates efficiency metrics like per-query latency and cost alongside accuracy, facilitating a comprehensive evaluation of IR systems | Moving Beyond Downstream Task Accuracy for Information Retrieval Benchmarking |
If you find this paper list useful in your research, please consider citing:
@article{bai2024beyond,
title={Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models},
author={Bai, Guangji and Chai, Zheng and Ling, Chen and Wang, Shiyu and Lu, Jiaying and Zhang, Nan and Shi, Tingwei and Yu, Ziyang and Zhu, Mengdan and Zhang, Yifei and others},
journal={arXiv preprint arXiv:2401.00625},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-Resource-Efficient-LLM-Papers
Similar Open Source Tools
Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.

LLM-KG4QA
LLM-KG4QA is a repository focused on the integration of Large Language Models (LLMs) and Knowledge Graphs (KGs) for Question Answering (QA). It covers various aspects such as using KGs as background knowledge, reasoning guideline, and refiner/filter. The repository provides detailed information on pre-training, fine-tuning, and Retrieval Augmented Generation (RAG) techniques for enhancing QA performance. It also explores complex QA tasks like Explainable QA, Multi-Modal QA, Multi-Document QA, Multi-Hop QA, Multi-run and Conversational QA, Temporal QA, Multi-domain and Multilingual QA, along with advanced topics like Optimization and Data Management. Additionally, it includes benchmark datasets, industrial and scientific applications, demos, and related surveys in the field.
LLM4EC
LLM4EC is an interdisciplinary research repository focusing on the intersection of Large Language Models (LLM) and Evolutionary Computation (EC). It provides a comprehensive collection of papers and resources exploring various applications, enhancements, and synergies between LLM and EC. The repository covers topics such as LLM-assisted optimization, EA-based LLM architecture search, and applications in code generation, software engineering, neural architecture search, and other generative tasks. The goal is to facilitate research and development in leveraging LLM and EC for innovative solutions in diverse domains.
Awesome-Model-Merging-Methods-Theories-Applications
A comprehensive repository focusing on 'Model Merging in LLMs, MLLMs, and Beyond', providing an exhaustive overview of model merging methods, theories, applications, and future research directions. The repository covers various advanced methods, applications in foundation models, different machine learning subfields, and tasks like pre-merging methods, architecture transformation, weight alignment, basic merging methods, and more.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
Awesome-Agent-Papers
This repository is a comprehensive collection of research papers on Large Language Model (LLM) agents, organized across key categories including agent construction, collaboration mechanisms, evolution, tools, security, benchmarks, and applications. The taxonomy provides a structured framework for understanding the field of LLM agents, bridging fragmented research threads by highlighting connections between agent design principles and emergent behaviors.
LLM4Opt
LLM4Opt is a collection of references and papers focusing on applying Large Language Models (LLMs) for diverse optimization tasks. The repository includes research papers, tutorials, workshops, competitions, and related collections related to LLMs in optimization. It covers a wide range of topics such as algorithm search, code generation, machine learning, science, industry, and more. The goal is to provide a comprehensive resource for researchers and practitioners interested in leveraging LLMs for optimization tasks.
models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. It aims to replicate the best-known performance of target model/dataset combinations in optimally-configured hardware environments. The repository will be deprecated upon the publication of v3.2.0 and will no longer be maintained or published.
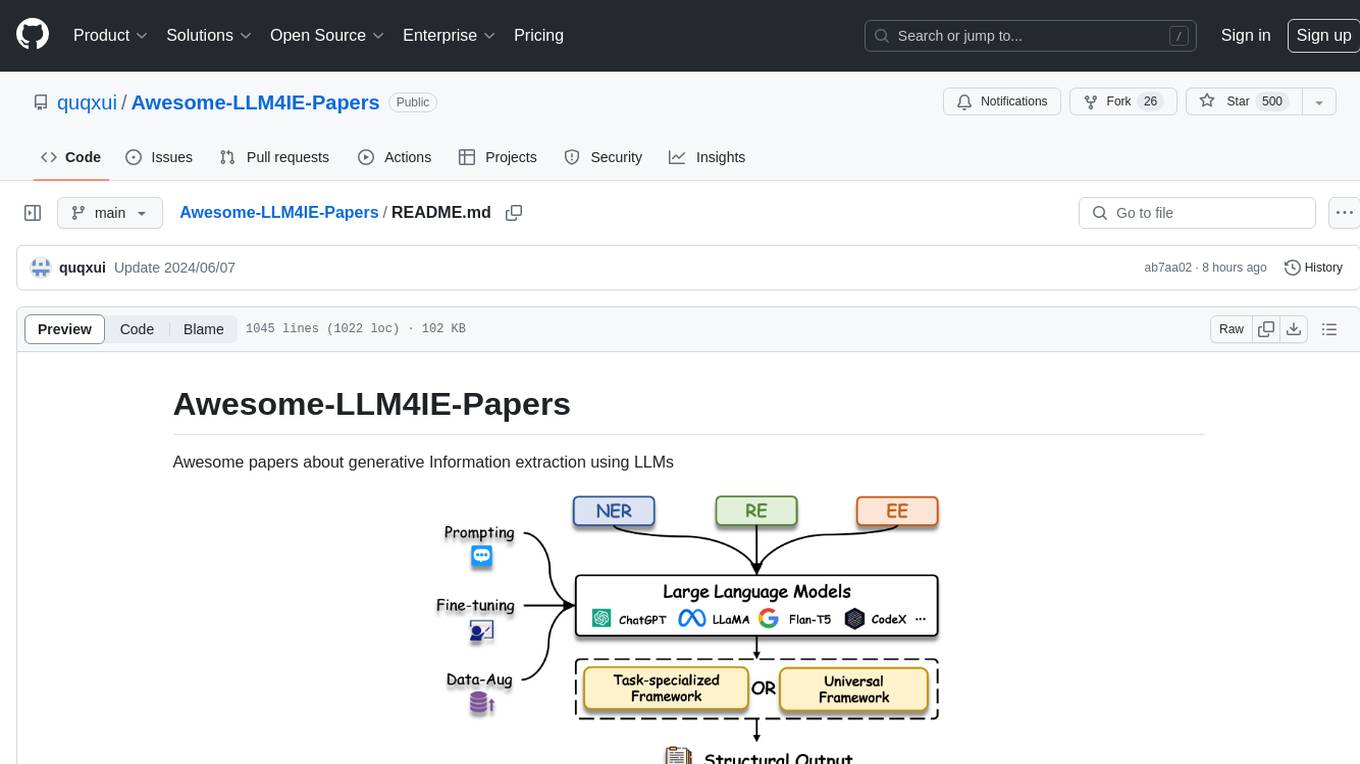

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.
Model-References
The 'Model-References' repository contains examples for training and inference using Intel Gaudi AI Accelerator. It includes models for computer vision, natural language processing, audio, generative models, MLPerf™ training, and MLPerf™ inference. The repository provides performance data and model validation information for various frameworks like PyTorch. Users can find examples of popular models like ResNet, BERT, and Stable Diffusion optimized for Intel Gaudi AI accelerator.
ai-reference-models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. The purpose is to quickly replicate complete software environments showcasing the AI capabilities of Intel platforms. It includes optimizations for popular deep learning frameworks like TensorFlow and PyTorch, with additional plugins/extensions for improved performance. The repository is licensed under Apache License Version 2.0.
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
For similar tasks
Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
awesome-ai-efficiency
Awesome AI Efficiency is a curated list of resources dedicated to enhancing efficiency in AI systems. The repository covers various topics essential for optimizing AI models and processes, aiming to make AI faster, cheaper, smaller, and greener. It includes topics like quantization, pruning, caching, distillation, factorization, compilation, parameter-efficient fine-tuning, speculative decoding, hardware optimization, training techniques, inference optimization, sustainability strategies, and scalability approaches.

unified-cache-management
Unified Cache Manager (UCM) is a tool designed to persist the LLM KVCache and replace redundant computations through various retrieval mechanisms. It supports prefix caching and offers training-free sparse attention retrieval methods, enhancing performance for long sequence inference tasks. UCM also provides a PD disaggregation solution based on a storage-compute separation architecture, enabling easier management of heterogeneous computing resources. When integrated with vLLM, UCM significantly reduces inference latency in scenarios like multi-turn dialogue and long-context reasoning tasks.
InferenceMAX
InferenceMAX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks and models. It runs a suite of benchmarks every night to capture progress in near real-time, providing a live indicator of inference performance. The tool addresses the challenge of rapidly evolving software ecosystems by benchmarking the latest software packages, ensuring that benchmarks do not go stale. InferenceMAX™ is supported by industry leaders and contributors, providing transparent and reproducible benchmarks that help the ML community make informed decisions about hardware and software performance.

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.
HighPerfLLMs2024
High Performance LLMs 2024 is a comprehensive course focused on building a high-performance Large Language Model (LLM) from scratch using Jax. The course covers various aspects such as training, inference, roofline analysis, compilation, sharding, profiling, and optimization techniques. Participants will gain a deep understanding of Jax and learn how to design high-performance computing systems that operate close to their physical limits.
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
llm-inference-solutions
A collection of available inference solutions for Large Language Models (LLMs) including high-throughput engines, optimization libraries, deployment toolkits, and deep learning frameworks for production environments.
For similar jobs
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
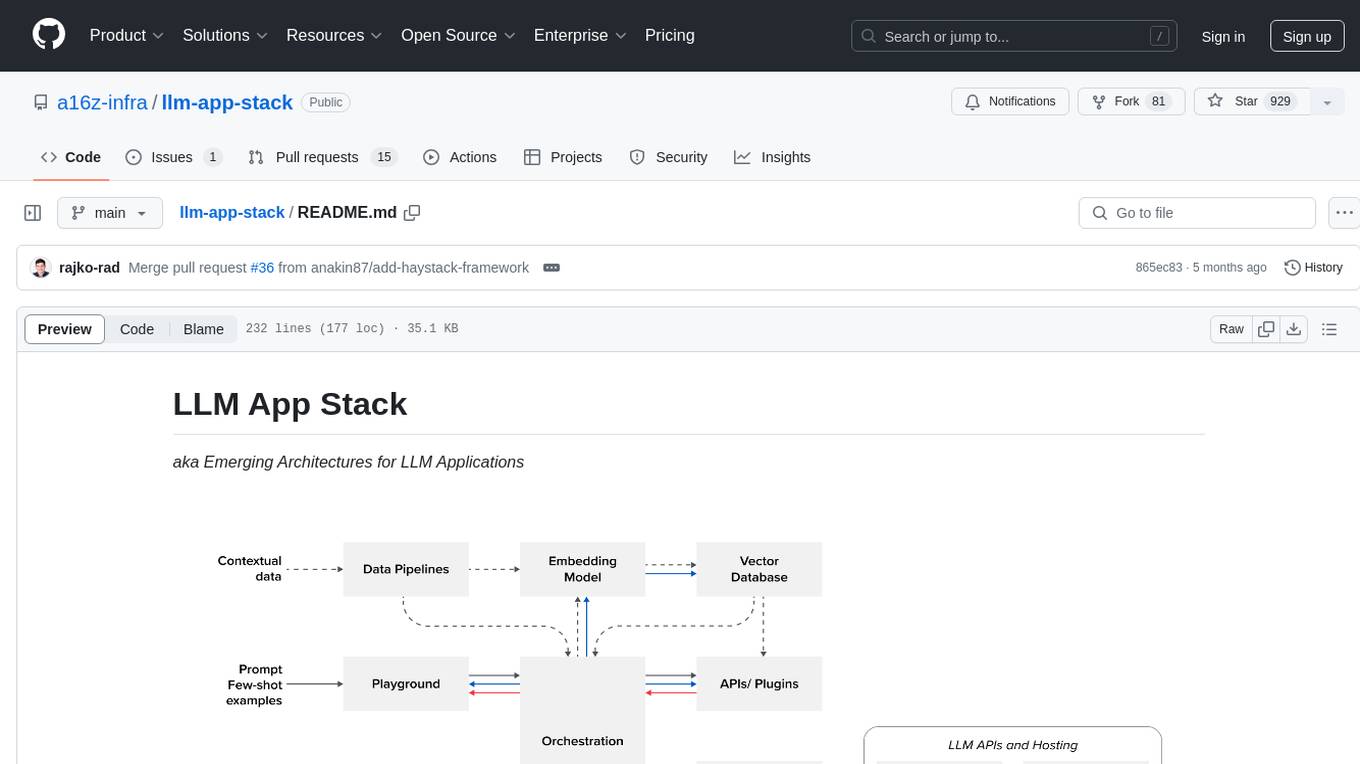
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
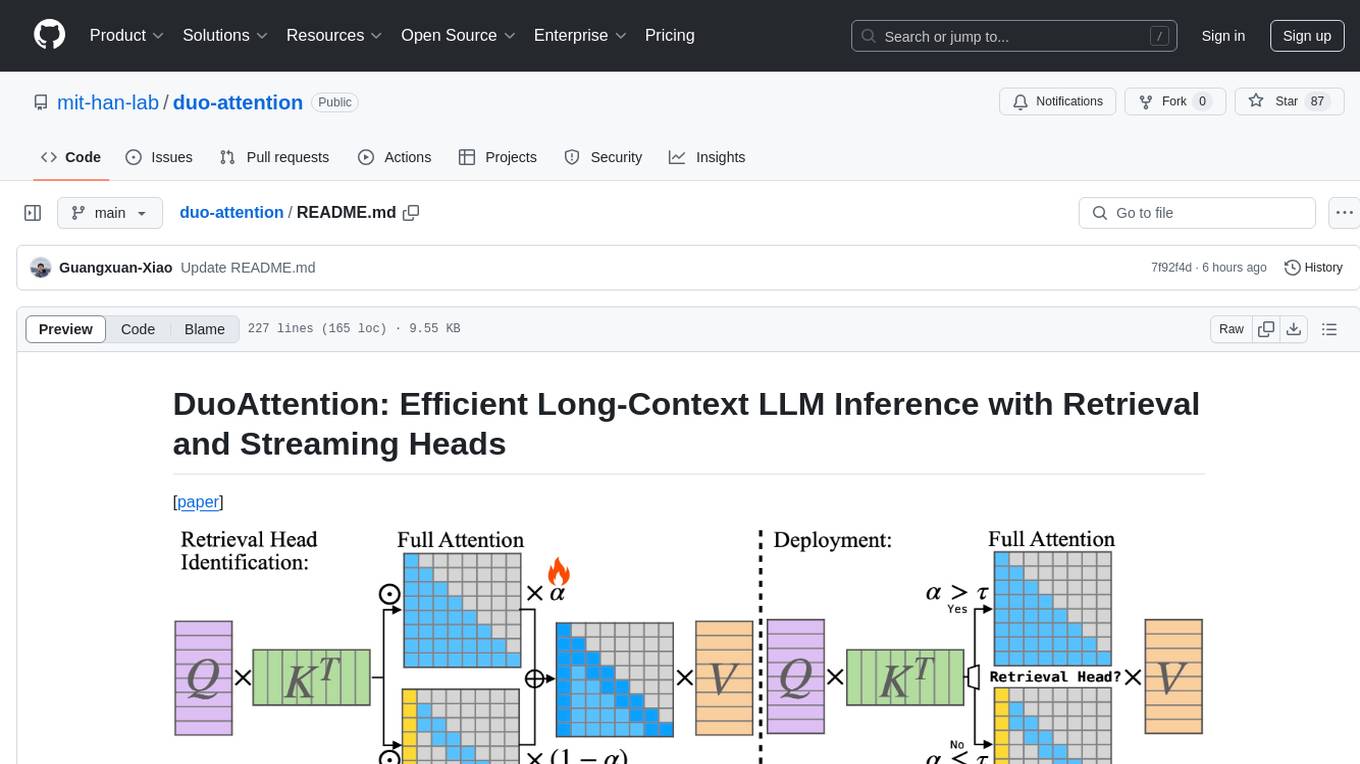
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
llm_note
LLM notes repository contains detailed analysis on transformer models, language model compression, inference and deployment, high-performance computing, and system optimization methods. It includes discussions on various algorithms, frameworks, and performance analysis related to large language models and high-performance computing. The repository serves as a comprehensive resource for understanding and optimizing language models and computing systems.
Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.