
LLM-Travel
欢迎来到 "LLM-travel" 仓库!探索大语言模型(LLM)的奥秘 🚀。致力于深入理解、探讨以及实现与大模型相关的各种技术、原理和应用。
Stars: 227
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
README:
欢迎来到 "LLM-travel" 仓库!探索大语言模型(LLM)的奥秘 🚀。致力于深入理解、探讨以及实现与大模型相关的各种技术、原理和应用。 文章在知乎:https://www.zhihu.com/people/allenvery/posts
-
技术讲解: 通过清晰且深入的文章,尽力揭示大语言模型的相关技术,探讨其背后的数学、算法和架构,帮助您理解它们的运作机制。
-
实用代码实现: 每篇实践性技术文章会配置相应的实践代码,帮助更好的理解和实现。
-
解答疑问与讨论: 欢迎提出问题、分享想法,以及想看到哪些内容,一起探讨大语言模型!
搭乘 "LLM-travel" 列车,一起探索大语言模型的奇妙世界!
| Date | Title(知乎链接) | Code | Note |
|---|---|---|---|
| 2024-06-23 | LLM大模型之Hallucination幻觉 | 无 | LLM大模型之Hallucination幻觉 |
| 2024-06-03 | LLM大模型之分布式训练小结 | 无 | LLM大模型之分布式训练小结 |
| 2024-05-10 | LLM大模型之训练优化方法 | 无 | LLM大模型之训练优化方法 |
| 2024-04-09 | Transformer实践 | Transformer_torch | Transformer实践 |
| 2023-12-16 | LLM之Deepspeed实践 | 无 | Deepspeed实践 |
| 2023-11-11 | LLM之数据质量 | quality_hash.ipynb | LLM大模型之大规模数据文本质量(Text Quality)实践一 |
| 2023-11-04 | LLM之Trainer | 无 | LLM大模型之Trainer以及训练参数 |
| 2023-10-14 | LLM之数据处理二 | 无 | LLM大模型之大规模数据处理工具篇Hadoop-Spark集群安装 |
| 2023-10-10 | LLM之开源数据整理 | LLM_Pretrain_Datasets | 开源的可用于LLM Pretrain数据集 |
| 2023-10-10 | LLM之数据处理一 | 无 | LLM大模型之大规模数据处理工具篇Hadoop-Spark集群介绍 |
| 2023-09-30 | LLM之显存占用 | memory_precision.ipynb | 不同精度下显存占用与相互转换实践 |
| 2023-09-29 | LLM之精度问题详解 | precision.ipynb | 精度问题(FP16,FP32,BF16)详解与实践 |
| 2023-09-24 | LLM之Embedding初始化 | embedding_init.ipynb | 扩充词表后Embedding和LM_head层的初始化 |
| 2023-09-23 | LLM之扩充词表 | sentencepiece.ipynb | 基于SentencePiece扩充LLaMa中文词表实践 |
| 2023-09-16 | LLM之Generate参数详解 | generate_parameter.ipynb | Generate/Inference(生成/推理)中参数与解码策略原理及其代码实现 |
| 2023-09-09 | LLM之Tokenization分词方法 | tokenization.ipynb | WordPiece,Byte-Pair Encoding (BPE),Byte-level BPE(BBPE)原理及其代码实现 |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-Travel
Similar Open Source Tools
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
llm-course
The llm-course repository is a collection of resources and materials for a course on Legal and Legislative Drafting. It includes lecture notes, assignments, readings, and other educational materials to help students understand the principles and practices of drafting legal documents. The course covers topics such as statutory interpretation, legal drafting techniques, and the role of legislation in the legal system. Whether you are a law student, legal professional, or someone interested in understanding the intricacies of legal language, this repository provides valuable insights and resources to enhance your knowledge and skills in legal drafting.
comfyui_prompt_assistant
ComfyUI Prompt Assistant is a plugin that enables prompt word translation, expansion, preset tag insertion, image reverse prompt words, and history record functions without adding nodes. It offers features like UI optimization, avoiding scroll bar overlap, tag popup window scrollbar fix, and more. Users can manually install the latest version from the Releases section. The tool supports various functionalities like image reverse, Kontext presets, translation nodes, and custom rules. It also provides features for tag insertion, LLM expansion, translation switching between Baidu and LLM, and history management.
AI-LLM-ML-CS-Quant-Review
This repository provides an in-depth review of industry trends in AI, Large Language Models (LLMs), Machine Learning, Computer Science, and Quantitative Finance. It covers various topics such as NVIDIA GTC conferences, DeepSeek theory and applications, LangGraph & Cursor AI, LLM essentials, system design, computer systems, big data and AI in finance, C++ design patterns, high-frequency finance, machine learning for algorithmic trading, stochastic volatility modeling, and quant job interview questions.
awesome-cuda-tensorrt-fpga
Okay, here is a JSON object with the requested information about the awesome-cuda-tensorrt-fpga repository:
Awesome-Efficient-Agents
This repository, Awesome Efficient Agents, is a curated collection of papers focusing on memory, tool learning, and planning in agentic systems. It provides a comprehensive survey of efficient agent design, emphasizing memory construction, tool learning, and planning strategies. The repository categorizes papers based on memory processes, tool selection, tool calling, tool-integrated reasoning, and planning efficiency. It aims to help readers quickly access representative work in the field of efficient agent design.
bookmark-summary
The 'bookmark-summary' repository reads bookmarks from 'bookmark-collection', extracts text content using Jina Reader, and then summarizes the text using LLM. The detailed implementation can be found in 'process_changes.py'. It needs to be used together with the Github Action in 'bookmark-collection'.


AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.
Plug-play-modules
Plug-play-modules is a comprehensive collection of plug-and-play modules for AI, deep learning, and computer vision applications. It includes various convolution variants, latest attention mechanisms, feature fusion modules, up-sampling/down-sampling modules, suitable for tasks like image classification, object detection, instance segmentation, semantic segmentation, single object tracking (SOT), multi-object tracking (MOT), infrared object tracking (RGBT), image de-raining, de-fogging, de-blurring, super-resolution, and more. The modules are designed to enhance model performance and feature extraction capabilities across various tasks.
For similar tasks
LLM-Travel
LLM-Travel is a repository dedicated to exploring the mysteries of Large Language Models (LLM). It provides in-depth technical explanations, practical code implementations, and a platform for discussions and questions related to LLM. Join the journey to explore the fascinating world of large language models with LLM-Travel.
open-model-database
OpenModelDB is a community-driven database of AI upscaling models, providing a centralized platform for users to access and compare various models. The repository contains a collection of models and model metadata, facilitating easy exploration and evaluation of different AI upscaling solutions. With a focus on enhancing the accessibility and usability of AI models, OpenModelDB aims to streamline the process of finding and selecting the most suitable models for specific tasks or projects.
vscode-ai-toolkit
AI Toolkit for Visual Studio Code simplifies generative AI app development by bringing together cutting-edge AI development tools and models from Azure AI Studio Catalog and other catalogs like Hugging Face. Users can browse the AI models catalog, download them locally, fine-tune, test, and deploy them to the cloud. The toolkit offers actions such as finding supported models, testing model inference, fine-tuning models locally or remotely, and deploying fine-tuned models to the cloud. It also provides optimized AI models for Windows and a Q&A section for common issues and resolutions.
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
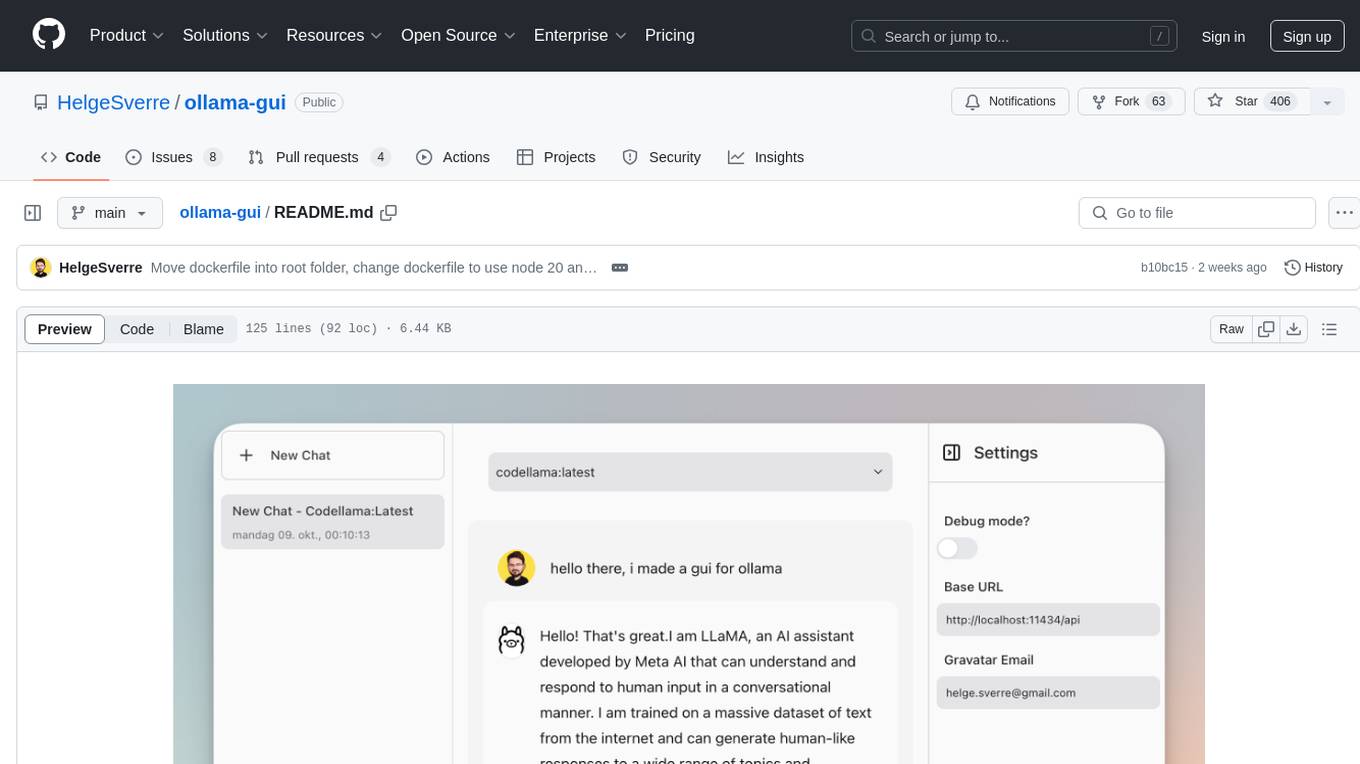
ollama-gui
Ollama GUI is a web interface for ollama.ai, a tool that enables running Large Language Models (LLMs) on your local machine. It provides a user-friendly platform for chatting with LLMs and accessing various models for text generation. Users can easily interact with different models, manage chat history, and explore available models through the web interface. The tool is built with Vue.js, Vite, and Tailwind CSS, offering a modern and responsive design for seamless user experience.
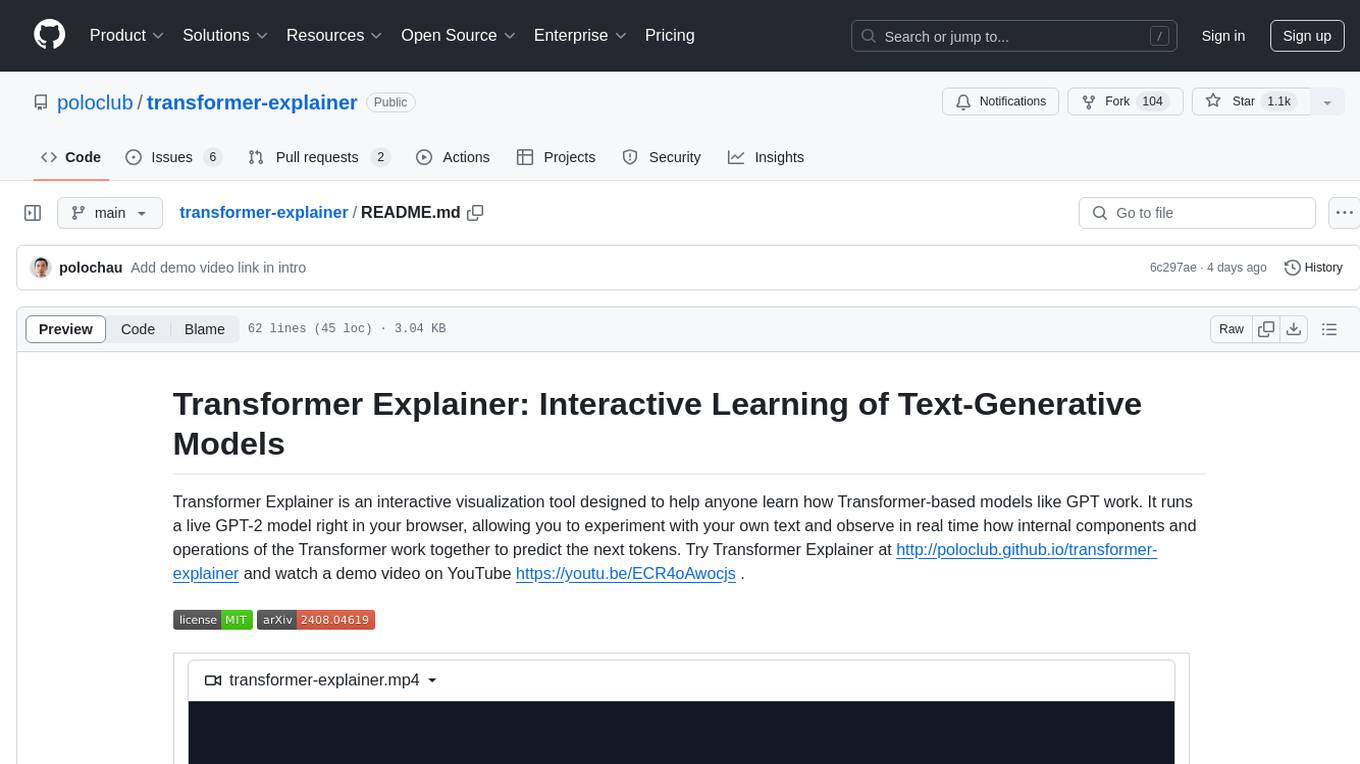
transformer-explainer
Transformer Explainer is an interactive visualization tool to help users learn how Transformer-based models like GPT work. It allows users to experiment with text and observe how internal components of the Transformer predict next tokens in real time. The tool runs a live GPT-2 model in the browser, providing an educational experience on text-generative models.
MetricsMLNotebooks
MetricsMLNotebooks is a repository containing applied causal ML notebooks. It provides a collection of notebooks for users to explore and run causal machine learning models. The repository includes both Python and R notebooks, with a focus on generating .Rmd files through a Github Action. Users can easily install the required packages by running 'pip install -r requirements.txt'. Note that any changes to .Rmd files will be overwritten by the corresponding .irnb files during the Github Action process. Additionally, all notebooks and R Markdown files are stripped from their outputs when pushed to the main branch, so users are advised to strip the notebooks before pushing to the repository.
ai-dev-gallery
The AI Dev Gallery is an app designed to help Windows developers integrate AI capabilities within their own apps and projects. It contains over 25 interactive samples powered by local AI models, allows users to explore, download, and run models from Hugging Face and GitHub, and provides the ability to view the C# source code and export a standalone Visual Studio project for each sample. The app is open-source and welcomes contributions and suggestions from the community.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.