
open-model-database
An open and free database for AI models
Stars: 210
OpenModelDB is a community-driven database of AI upscaling models, providing a centralized platform for users to access and compare various models. The repository contains a collection of models and model metadata, facilitating easy exploration and evaluation of different AI upscaling solutions. With a focus on enhancing the accessibility and usability of AI models, OpenModelDB aims to streamline the process of finding and selecting the most suitable models for specific tasks or projects.
README:


This repo contains all models and model metadata for OpenModelDB.
OpenModelDB is a community-driven database of AI Upscaling models. We aim to provide a better way to find and compare models than existing sources.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for open-model-database
Similar Open Source Tools
open-model-database
OpenModelDB is a community-driven database of AI upscaling models, providing a centralized platform for users to access and compare various models. The repository contains a collection of models and model metadata, facilitating easy exploration and evaluation of different AI upscaling solutions. With a focus on enhancing the accessibility and usability of AI models, OpenModelDB aims to streamline the process of finding and selecting the most suitable models for specific tasks or projects.
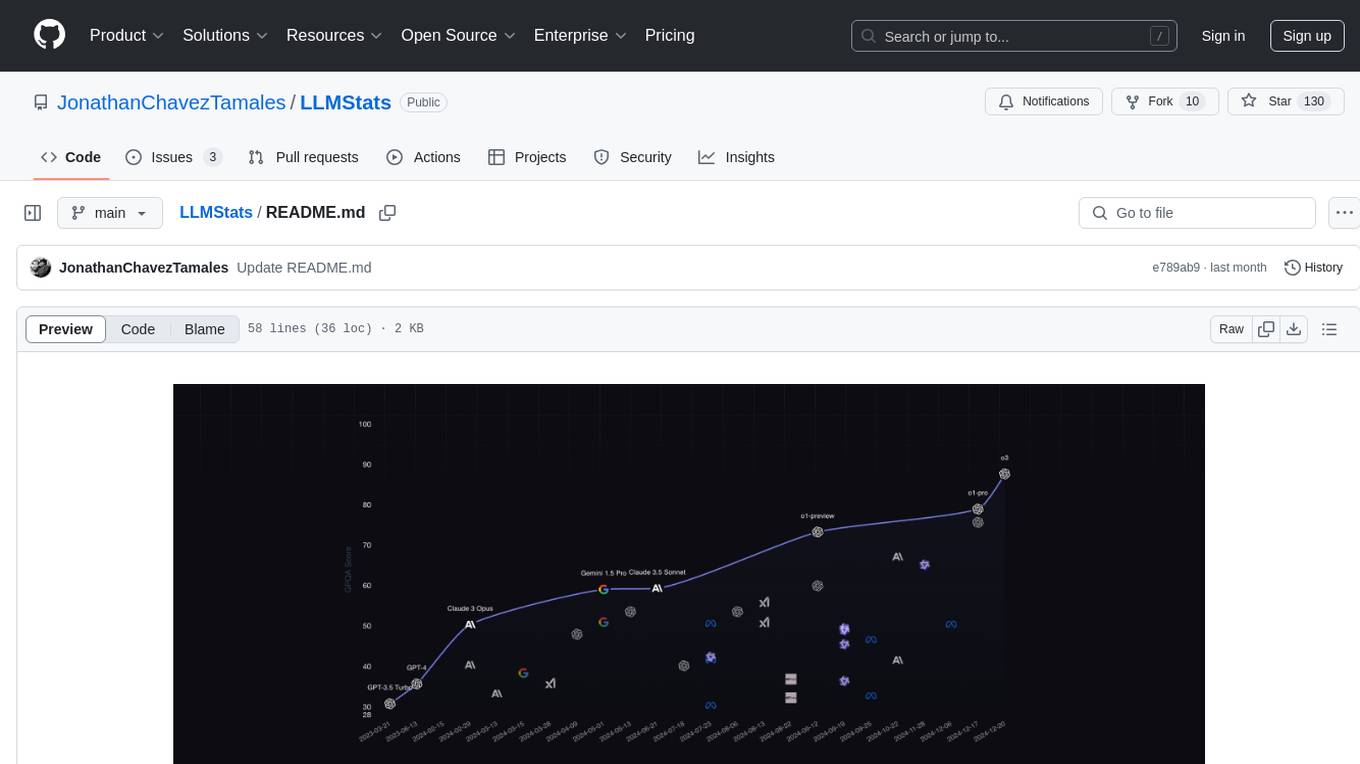
LLMStats
LLMStats is a community-driven repository providing detailed information on hundreds of Language Models (LLMs). Users can compare and explore LLMs through an interactive dashboard at llm-stats.com. The repository includes model parameters, context window sizes, licensing details, capabilities, provider pricing, performance metrics, and standardized benchmark results. Community contributions are welcome to maintain data accuracy. The platform prioritizes data quality through verifiable source links, community review processes, multiple source citations, and regular data validation. While not guaranteed to be 100% accurate, efforts are made to ensure the information is as reliable as possible.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
craftgen
Craftgen.ai is an innovative AI platform designed for both technical and non-technical users. It's built on a foundation of graph architecture for scalability and the Actor Model for efficient concurrent operations, tailored to both technical and non-technical users. A key aspect of Craftgen.ai is its modular AI approach, allowing users to assemble and customize AI components like building blocks to fit their specific needs. The platform's robustness is enhanced by its event-driven architecture, ensuring reliable data processing and featuring browser web technologies for universal access. Craftgen.ai excels in dynamic tool and workflow generation, with strong offline capabilities for secure environments and plans for desktop application integration. A unique and valuable feature of Craftgen.ai is its marketplace, where users can access a variety of pre-built AI solutions. This marketplace accelerates the deployment of AI tools but also fosters a community of sharing and innovation. Users can contribute to and leverage this repository of solutions, enhancing the platform's versatility and practicality. Craftgen.ai uses JSON schema for industry-standard alignment, enabling seamless integration with any API following the OpenAPI spec. This allows for a broad range of applications, from automating data analysis to streamlining content management. The platform is designed to bridge the gap between advanced AI technology and practical usability. It's a flexible, secure, and intuitive platform that empowers users, from developers seeking to create custom AI solutions to businesses looking to automate routine tasks. Craftgen.ai's goal is to make AI technology an integral, seamless part of everyday problem-solving and innovation, providing a platform where modular AI and a thriving marketplace converge to meet the diverse needs of its users.

NeMo
NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and PyTorch developers working on Large Language Models (LLMs), Multimodal Models (MMs), Automatic Speech Recognition (ASR), Text to Speech (TTS), and Computer Vision (CV) domains. It is designed to help you efficiently create, customize, and deploy new generative AI models by leveraging existing code and pre-trained model checkpoints.
applied-ai-engineering-samples
The Google Cloud Applied AI Engineering repository provides reference guides, blueprints, code samples, and hands-on labs developed by the Google Cloud Applied AI Engineering team. It contains resources for Generative AI on Vertex AI, including code samples and hands-on labs demonstrating the use of Generative AI models and tools in Vertex AI. Additionally, it offers reference guides and blueprints that compile best practices and prescriptive guidance for running large-scale AI/ML workloads on Google Cloud AI/ML infrastructure.

NeMo
NeMo Framework is a generative AI framework built for researchers and pytorch developers working on large language models (LLMs), multimodal models (MM), automatic speech recognition (ASR), and text-to-speech synthesis (TTS). The primary objective of NeMo is to provide a scalable framework for researchers and developers from industry and academia to more easily implement and design new generative AI models by being able to leverage existing code and pretrained models.
ten_framework
TEN Framework, short for Transformative Extensions Network, is the world's first real-time multimodal AI agent framework. It offers native support for high-performance, real-time multimodal interactions, supports multiple languages and platforms, enables edge-cloud integration, provides flexibility beyond model limitations, and allows for real-time agent state management. The framework facilitates the development of complex AI applications that transcend the limitations of large models by offering a drag-and-drop programming approach. It is suitable for scenarios like simultaneous interpretation, speech-to-text conversion, multilingual chat rooms, audio interaction, and audio-visual interaction.
AingDesk
AingDesk is a tool that allows users to deploy DeepSeek or other AI models on their computer with just one click. It features a user-friendly interface, multi-source knowledge base support, built-in chat interface, and the ability to share projects online. The tool is optimized for performance on both local and cloud environments, with a focus on hassle-free setup and extensibility through a modular architecture. The development plan includes support for third-party API integrations and local deployment of text-to-image hybrid models for creative workflows.
LabelLLM
LabelLLM is an open-source data annotation platform designed to optimize the data annotation process for LLM development. It offers flexible configuration, multimodal data support, comprehensive task management, and AI-assisted annotation. Users can access a suite of annotation tools, enjoy a user-friendly experience, and enhance efficiency. The platform allows real-time monitoring of annotation progress and quality control, ensuring data integrity and timeliness.
buildel
Buildel is an AI automation platform that empowers users to create versatile workflows without writing code. It supports multiple providers and interfaces, offers pre-built use cases, and allows users to bring their own API keys. Ideal for AI-powered document retrieval, conversational interfaces, and data integration. Users can get started at app.buildel.ai or run Buildel locally with Node.js, Elixir/Erlang, Docker, Git, and JQ installed. Join the community on Discord for support and discussions.

langchain
LangChain is a framework for building LLM-powered applications that simplifies AI application development by chaining together interoperable components and third-party integrations. It helps developers connect LLMs to diverse data sources, swap models easily, and future-proof decisions as technology evolves. LangChain's ecosystem includes tools like LangSmith for agent evals, LangGraph for complex task handling, and LangGraph Platform for deployment and scaling. Additional resources include tutorials, how-to guides, conceptual guides, a forum, API reference, and chat support.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.
kitops
KitOps is a CNCF open standards project for packaging, versioning, and securely sharing AI/ML projects. It provides a unified solution for packaging, versioning, and managing assets in security-conscious enterprises, governments, and cloud operators. KitOps elevates AI artifacts to first-class, governed assets through ModelKits, which are tamper-proof, signable, and compatible with major container registries. The tool simplifies collaboration between data scientists, developers, and SREs, ensuring reliable and repeatable workflows for both development and operations. KitOps supports packaging for various types of models, including large language models, computer vision models, multi-modal models, predictive models, and audio models. It also facilitates compliance with the EU AI Act by offering tamper-proof, signable, and auditable ModelKits.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
stochastic-rs
stochastic-rs is a high-performance Rust library for simulating and analyzing stochastic processes. It is designed for applications in quantitative finance, AI training, and statistical modeling, providing efficient tools to generate synthetic data and analyze complex stochastic systems. The library is actively developed and welcomes contributions such as bug reports, feature suggestions, and documentation improvements. It is licensed under the MIT License.
For similar tasks
open-model-database
OpenModelDB is a community-driven database of AI upscaling models, providing a centralized platform for users to access and compare various models. The repository contains a collection of models and model metadata, facilitating easy exploration and evaluation of different AI upscaling solutions. With a focus on enhancing the accessibility and usability of AI models, OpenModelDB aims to streamline the process of finding and selecting the most suitable models for specific tasks or projects.
exo
Run your own AI cluster at home with everyday devices. Exo is experimental software that unifies existing devices into a powerful GPU, supporting wide model compatibility, dynamic model partitioning, automatic device discovery, ChatGPT-compatible API, and device equality. It does not use a master-worker architecture, allowing devices to connect peer-to-peer. Exo supports different partitioning strategies like ring memory weighted partitioning. Installation is recommended from source. Documentation includes example usage on multiple MacOS devices and information on inference engines and networking modules. Known issues include the iOS implementation lagging behind Python.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
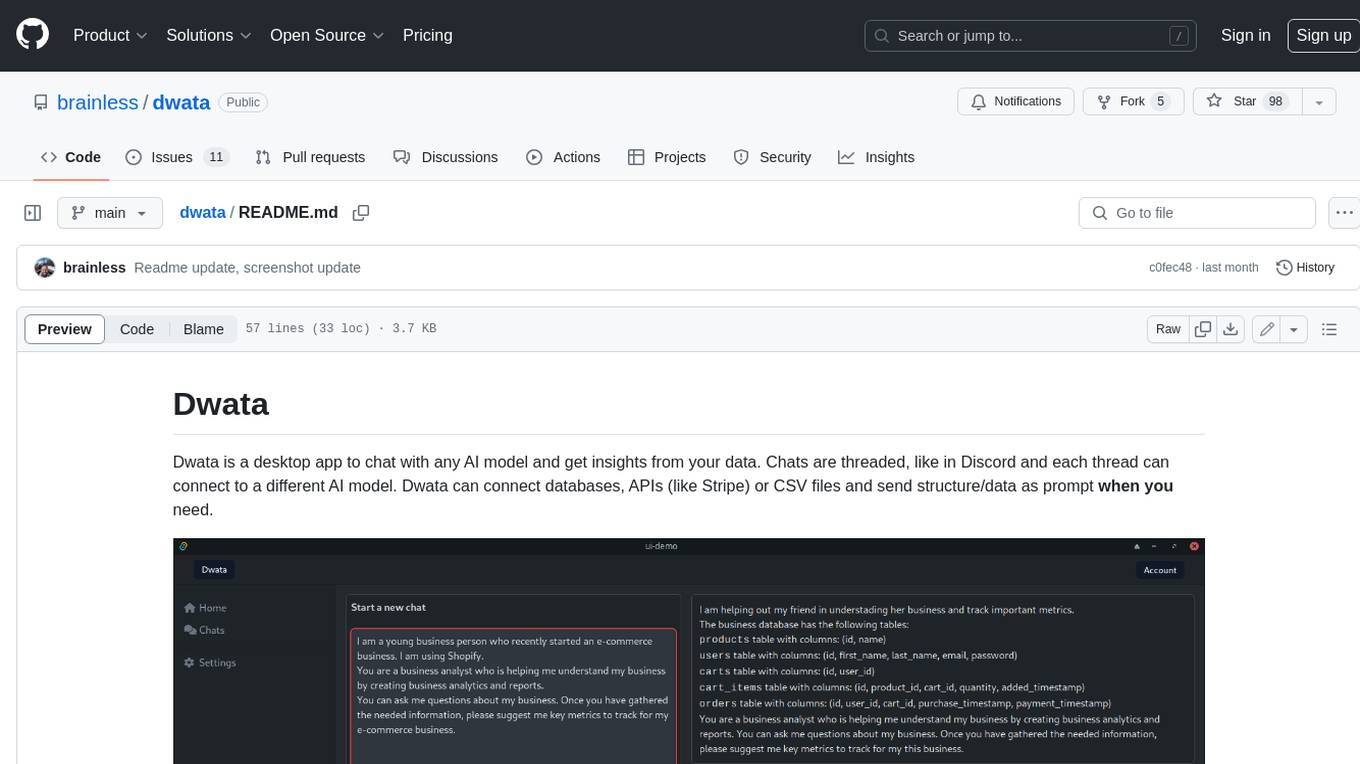
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.
PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.