
fasttrackml
Experiment tracking server focused on speed and scalability
Stars: 97

FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
README:

FastTrackML is an API for logging parameters and metrics when running machine learning code, and it is a UI for visualizing the result. The API is a drop-in replacement for MLflow's tracking server, and it ships with the visualization UI of both MLflow and Aim.
As the name implies, the emphasis is on speed -- fast logging, fast retrieval.
[!NOTE] For the full guide, see our quickstart guide.
FastTrackML can be installed and run with pip:
pip install fasttrackml
fml serverAlternatively, you can run it within a container with Docker:
docker run --rm -p 5000:5000 -ti gresearch/fasttrackmlVerify that you can see the UI by navigating to http://localhost:5000/.
For more info, --help is your friend!
Install the MLflow Python package:
pip install mlflow-skinnyHere is an elementary example Python script:
import mlflow
import random
# Set the tracking URI to the FastTrackML server
mlflow.set_tracking_uri("http://localhost:5000")
# Set the experiment name
mlflow.set_experiment("my-first-experiment")
# Start a new run
with mlflow.start_run():
# Log a parameter
mlflow.log_param("param1", random.randint(0, 100))
# Log a metric
mlflow.log_metric("foo", random.random())
# metrics can be updated throughout the run
mlflow.log_metric("foo", random.random() + 1)
mlflow.log_metric("foo", random.random() + 2)FastTrackML can be built and tested within a dev container. This is the recommended way as the whole environment comes preconfigured with all the dependencies (Go SDK, Postgres, Minio, etc.) and settings (formatting, linting, extensions, etc.) to get started instantly.
If you have a GitHub account, you can simply open FastTrackML in a new GitHub Codespace by clicking on the green "Code" button at the top of this page.
You can build, run, and attach the debugger by simply pressing F5. The unit
tests can be run from the Test Explorer on the left. There are also many targets
within the Makefile that can be used (e.g. build, run, test-go-unit).
If you want to work locally in Visual Studio Code, all you need is to have Docker and the Dev Containers extension installed.
Simply open up your copy of FastTrackML in VS Code and click "Reopen in container" when prompted. Once the project has been opened, you can follow the GitHub Codespaces instructions above.
[!IMPORTANT] Note that on MacOS, port 5000 is already occupied, so some adjustments are necessary.
If the CLI is how you roll, then you can install the Dev Container CLI tool and follow the instruction below.
CLI instructions
[!WARNING] This setup is not recommended or supported. Here be dragons!
You will need to edit the .devcontainer/docker-compose.yml file and uncomment
the services.db.ports section to expose the ports to the host. You will also
need to add FML_LISTEN_ADDRESS=:5000 to .devcontainer/.env.
You can then issue the following command in your copy of FastTrackML to get up and running:
devcontainer upAssuming you cloned the repo into a directory named fasttrackml and did not
fiddle with the dev container config, you can enter the dev container with:
docker compose --project-name fasttrackml_devcontainer exec --user vscode --workdir /workspaces/fasttrackml app zshIf any of these is not true, here is how to render a command tailored to your
setup (it requires jq to be
installed):
devcontainer up | tail -n1 | jq -r '"docker compose --project-name \(.composeProjectName) exec --user \(.remoteUser) --workdir \(.remoteWorkspaceFolder) app zsh"'Once in the dev container, use your favorite text editor and Makefile targets:
vscode ➜ /workspaces/fasttrackml (main) $ vi main.go
vscode ➜ /workspaces/fasttrackml (main) $ emacs .
vscode ➜ /workspaces/fasttrackml (main) $ make runCopyright 2022-2023 G-Research
Copyright 2019-2022 Aimhub, Inc.
Copyright 2018 Databricks, Inc.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use these files except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for fasttrackml
Similar Open Source Tools
fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

llamafile
llamafile is a tool that enables users to distribute and run Large Language Models (LLMs) with a single file. It combines llama.cpp with Cosmopolitan Libc to create a framework that simplifies the complexity of LLMs into a single-file executable called a 'llamafile'. Users can run these executable files locally on most computers without the need for installation, making open LLMs more accessible to developers and end users. llamafile also provides example llamafiles for various LLM models, allowing users to try out different LLMs locally. The tool supports multiple CPU microarchitectures, CPU architectures, and operating systems, making it versatile and easy to use.
aiarena-web
aiarena-web is a website designed for running the aiarena.net infrastructure. It consists of different modules such as core functionality, web API endpoints, frontend templates, and a module for linking users to their Patreon accounts. The website serves as a platform for obtaining new matches, reporting results, featuring match replays, and connecting with Patreon supporters. The project is licensed under GPLv3 in 2019.

WindowsAgentArena
Windows Agent Arena (WAA) is a scalable Windows AI agent platform designed for testing and benchmarking multi-modal, desktop AI agents. It provides researchers and developers with a reproducible and realistic Windows OS environment for AI research, enabling testing of agentic AI workflows across various tasks. WAA supports deploying agents at scale using Azure ML cloud infrastructure, allowing parallel running of multiple agents and delivering quick benchmark results for hundreds of tasks in minutes.

bia-bob
BIA `bob` is a Jupyter-based assistant for interacting with data using large language models to generate Python code. It can utilize OpenAI's chatGPT, Google's Gemini, Helmholtz' blablador, and Ollama. Users need respective accounts to access these services. Bob can assist in code generation, bug fixing, code documentation, GPU-acceleration, and offers a no-code custom Jupyter Kernel. It provides example notebooks for various tasks like bio-image analysis, model selection, and bug fixing. Installation is recommended via conda/mamba environment. Custom endpoints like blablador and ollama can be used. Google Cloud AI API integration is also supported. The tool is extensible for Python libraries to enhance Bob's functionality.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.
seer
Seer is a service that provides AI capabilities to Sentry by running inference on Sentry issues and providing user insights. It is currently in early development and not yet compatible with self-hosted Sentry instances. The tool requires access to internal Sentry resources and is intended for internal Sentry employees. Users can set up the environment, download model artifacts, integrate with local Sentry, run evaluations for Autofix AI agent, and deploy to a sandbox staging environment. Development commands include applying database migrations, creating new migrations, running tests, and more. The tool also supports VCRs for recording and replaying HTTP requests.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
CLI
Bito CLI provides a command line interface to the Bito AI chat functionality, allowing users to interact with the AI through commands. It supports complex automation and workflows, with features like long prompts and slash commands. Users can install Bito CLI on Mac, Linux, and Windows systems using various methods. The tool also offers configuration options for AI model type, access key management, and output language customization. Bito CLI is designed to enhance user experience in querying AI models and automating tasks through the command line interface.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.

ray-llm
RayLLM (formerly known as Aviary) is an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs, built on Ray Serve. It provides an extensive suite of pre-configured open source LLMs, with defaults that work out of the box. RayLLM supports Transformer models hosted on Hugging Face Hub or present on local disk. It simplifies the deployment of multiple LLMs, the addition of new LLMs, and offers unique autoscaling support, including scale-to-zero. RayLLM fully supports multi-GPU & multi-node model deployments and offers high performance features like continuous batching, quantization and streaming. It provides a REST API that is similar to OpenAI's to make it easy to migrate and cross test them. RayLLM supports multiple LLM backends out of the box, including vLLM and TensorRT-LLM.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.
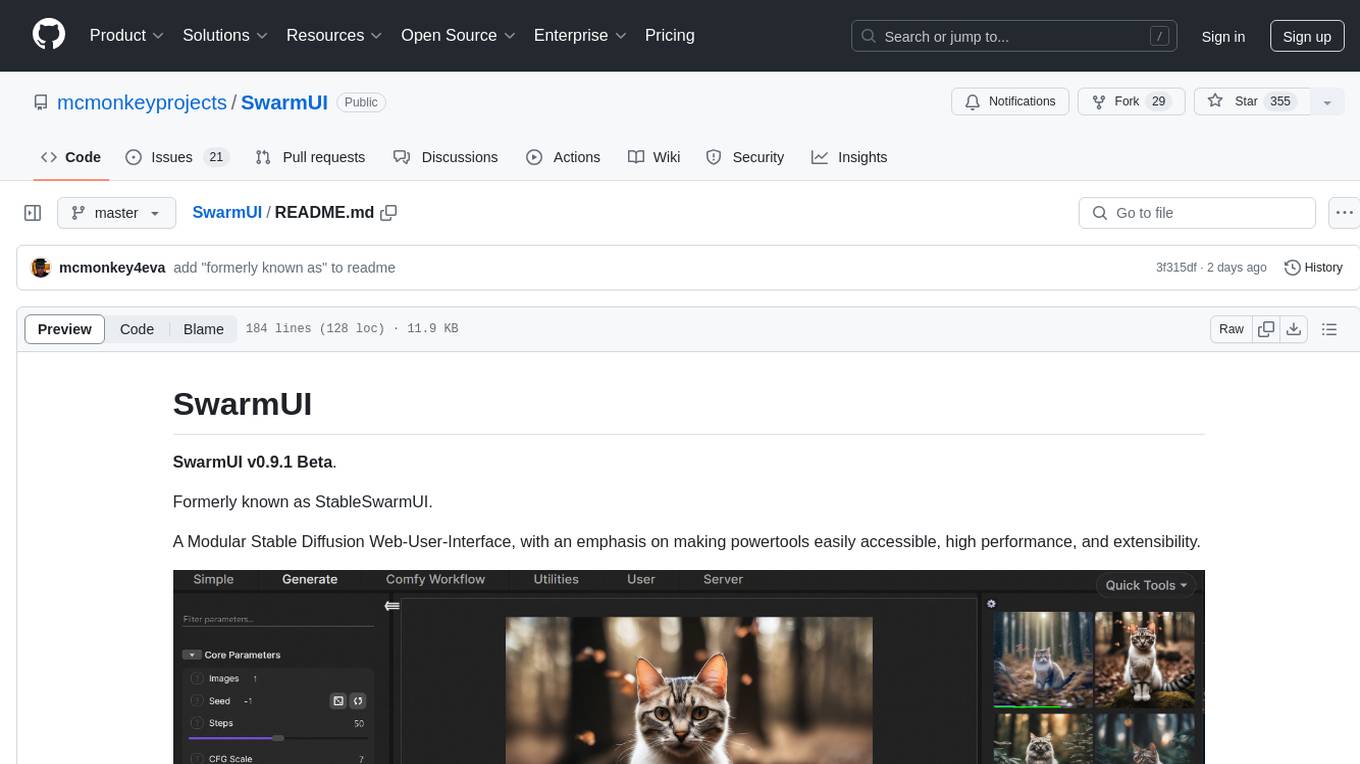
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.
For similar tasks
fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.
code-a2z
Code A2Z - Project Blog is a collaborative platform for developers and writers to create, manage, and share content. It offers structured environment, role-based access, SEO optimization, and community discussions to enhance collaboration and global visibility. Users can contribute projects, update them, and improve the platform. Key features include Markdown support, submodule integration, customizable templates, project contribution workflow, global visibility, community discussions, full ownership, SEO optimization, and role-based dashboard.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
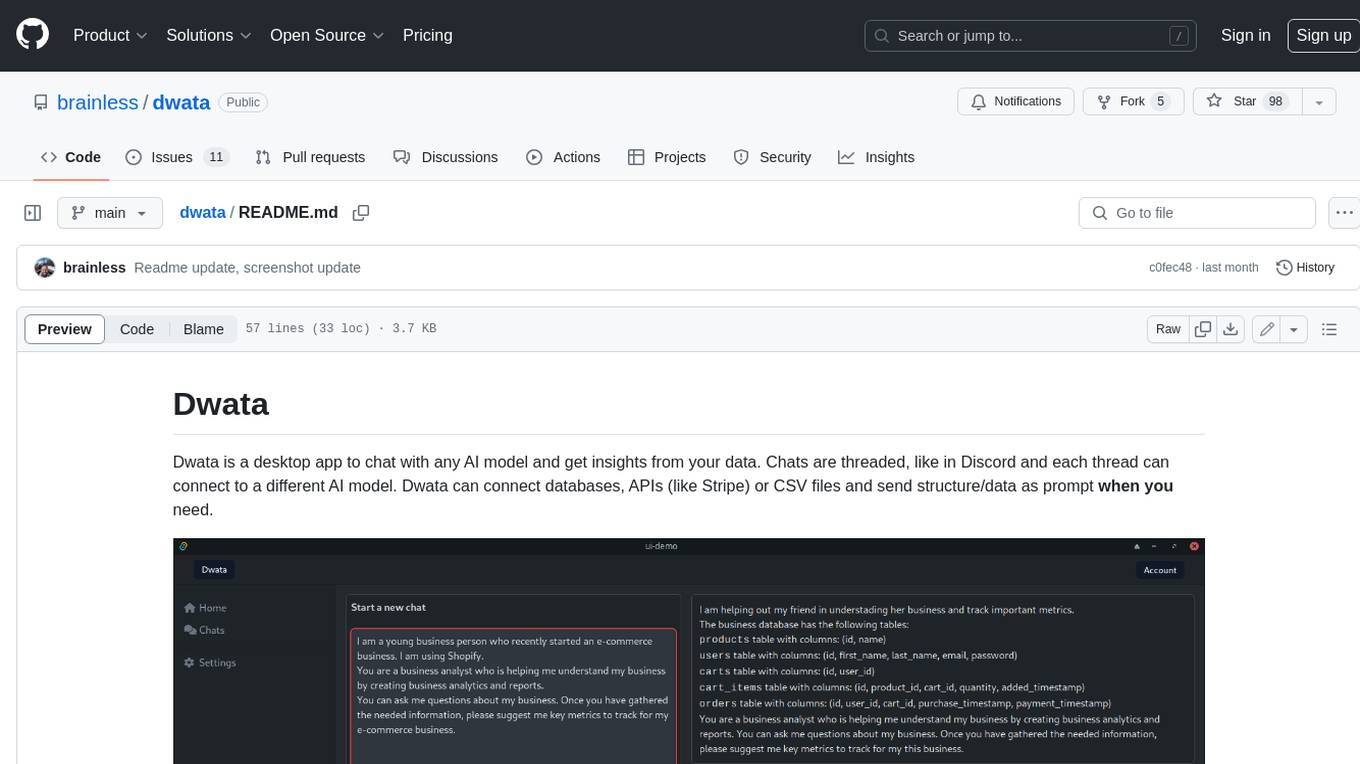
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.