
lighteval
Lighteval is your all-in-one toolkit for evaluating LLMs across multiple backends
Stars: 1957

LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
README:

Your go-to toolkit for lightning-fast, flexible LLM evaluation, from Hugging Face's Leaderboard and Evals Team.
![]()
![]()


Lighteval is your all-in-one toolkit for evaluating LLMs across multiple backends—whether your model is being served somewhere or already loaded in memory. Dive deep into your model's performance by saving and exploring detailed, sample-by-sample results to debug and see how your models stack-up.
Customization at your fingertips: letting you either browse all our existing tasks and metrics or effortlessly create your own custom task and custom metric, tailored to your needs.
Lighteval supports 7,000+ evaluation tasks across multiple domains and languages. Here's an overview of some popular benchmarks:
- General Knowledge: MMLU, MMLU-Pro, MMMU, BIG-Bench
- Question Answering: TriviaQA, Natural Questions, SimpleQA, Humanity's Last Exam (HLE)
- Specialized: GPQA, AGIEval
- Math Problems: GSM8K, GSM-Plus, MATH, MATH500
- Competition Math: AIME24, AIME25
- Multilingual Math: MGSM (Grade School Math in 10+ languages)
- Coding Benchmarks: LCB (LiveCodeBench)
- Instruction Following: IFEval, IFEval-fr
- Reasoning: MUSR, DROP (discrete reasoning)
- Long Context: RULER
- Dialogue: MT-Bench
- Holistic Evaluation: HELM, BIG-Bench
- Cross-lingual: XTREME, Flores200 (200 languages), XCOPA, XQuAD
-
Language-specific:
- Arabic: ArabicMMLU
- Filipino: FilBench
- French: IFEval-fr, GPQA-fr, BAC-fr
- German: German RAG Eval
- Serbian: Serbian LLM Benchmark, OZ Eval
- Turkic: TUMLU (9 Turkic languages)
- Chinese: CMMLU, CEval, AGIEval
- Russian: RUMMLU, Russian SQuAD
- And many more...
- NLU: GLUE, SuperGLUE, TriviaQA, Natural Questions
- Commonsense: HellaSwag, WinoGrande, ProtoQA
- Natural Language Inference: XNLI
- Reading Comprehension: SQuAD, XQuAD, MLQA, Belebele
Note: lighteval is currently completely untested on Windows, and we don't support it yet. (Should be fully functional on Mac/Linux)
pip install lightevalLighteval allows for many extras when installing, see here for a complete list.
If you want to push results to the Hugging Face Hub, add your access token as an environment variable:
huggingface-cli loginLighteval offers the following entry points for model evaluation:
-
lighteval accelerate: Evaluate models on CPU or one or more GPUs using 🤗 Accelerate -
lighteval nanotron: Evaluate models in distributed settings using ⚡️ Nanotron -
lighteval vllm: Evaluate models on one or more GPUs using 🚀 VLLM -
lighteval sglang: Evaluate models using SGLang as backend -
lighteval endpoint: Evaluate models using various endpoints as backend-
lighteval endpoint inference-endpoint: Evaluate models using Hugging Face's Inference Endpoints API -
lighteval endpoint tgi: Evaluate models using 🔗 Text Generation Inference running locally -
lighteval endpoint litellm: Evaluate models on any compatible API using LiteLLM -
lighteval endpoint inference-providers: Evaluate models using HuggingFace's inference providers as backend
-
Did not find what you need ? You can always make your custom model API by following this guide
-
lighteval custom: Evaluate custom models (can be anything)
Here's a quick command to evaluate using the Accelerate backend:
lighteval accelerate \
"model_name=gpt2" \
"leaderboard|truthfulqa:mc|0"Or use the Python API to run a model already loaded in memory!
from transformers import AutoModelForCausalLM
from lighteval.logging.evaluation_tracker import EvaluationTracker
from lighteval.models.transformers.transformers_model import TransformersModel, TransformersModelConfig
from lighteval.pipeline import ParallelismManager, Pipeline, PipelineParameters
MODEL_NAME = "meta-llama/Meta-Llama-3-8B-Instruct"
BENCHMARKS = "lighteval|gsm8k|0"
evaluation_tracker = EvaluationTracker(output_dir="./results")
pipeline_params = PipelineParameters(
launcher_type=ParallelismManager.NONE,
max_samples=2
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME, device_map="auto"
)
config = TransformersModelConfig(model_name=MODEL_NAME, batch_size=1)
model = TransformersModel.from_model(model, config)
pipeline = Pipeline(
model=model,
pipeline_parameters=pipeline_params,
evaluation_tracker=evaluation_tracker,
tasks=BENCHMARKS,
)
results = pipeline.evaluate()
pipeline.show_results()
results = pipeline.get_results()Lighteval took inspiration from the following amazing frameworks: Eleuther's AI Harness and Stanford's HELM. We are grateful to their teams for their pioneering work on LLM evaluations.
We'd also like to offer our thanks to all the community members who have contributed to the library, adding new features and reporting or fixing bugs.
Got ideas? Found a bug? Want to add a task or metric? Contributions are warmly welcomed!
If you're adding a new feature, please open an issue first.
If you open a PR, don't forget to run the styling!
pip install -e .[dev]
pre-commit install
pre-commit run --all-files@misc{lighteval,
author = {Habib, Nathan and Fourrier, Clémentine and Kydlíček, Hynek and Wolf, Thomas and Tunstall, Lewis},
title = {LightEval: A lightweight framework for LLM evaluation},
year = {2023},
version = {0.11.0},
url = {https://github.com/huggingface/lighteval}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for lighteval
Similar Open Source Tools
lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
ToolUniverse
ToolUniverse is a collection of 211 biomedical tools designed for Agentic AI, providing access to biomedical knowledge for solving therapeutic reasoning tasks. The tools cover various aspects of drugs and diseases, linked to trusted sources like US FDA-approved drugs since 1939, Open Targets, and Monarch Initiative.
rkllama
RKLLama is a server and client tool designed for running and interacting with LLM models optimized for Rockchip RK3588(S) and RK3576 platforms. It allows models to run on the NPU, with features such as running models on NPU, partial Ollama API compatibility, pulling models from Huggingface, API REST with documentation, dynamic loading/unloading of models, inference requests with streaming modes, simplified model naming, CPU model auto-detection, and optional debug mode. The tool supports Python 3.8 to 3.12 and has been tested on Orange Pi 5 Pro and Orange Pi 5 Plus with specific OS versions.
presenton
Presenton is an open-source AI presentation generator and API that allows users to create professional presentations locally on their devices. It offers complete control over the presentation workflow, including custom templates, AI template generation, flexible generation options, and export capabilities. Users can use their own API keys for various models, integrate with Ollama for local model running, and connect to OpenAI-compatible endpoints. The tool supports multiple providers for text and image generation, runs locally without cloud dependencies, and can be deployed as a Docker container with GPU support.
agentfield
AgentField is an open-source control plane designed for autonomous AI agents, providing infrastructure for agents to make decisions beyond chatbots. It offers features like scaling infrastructure, routing & discovery, async execution, durable state, observability, trust infrastructure with cryptographic identity, verifiable credentials, and policy enforcement. Users can write agents in Python, Go, TypeScript, or interact via REST APIs. The tool enables the creation of AI backends that reason autonomously within defined boundaries, offering predictability and flexibility. AgentField aims to bridge the gap between AI frameworks and production-ready infrastructure for AI agents.

oh-my-pi
oh-my-pi is an AI coding agent for the terminal, providing tools for interactive coding, AI-powered git commits, Python code execution, LSP integration, time-traveling streamed rules, interactive code review, task management, interactive questioning, custom TypeScript slash commands, universal config discovery, MCP & plugin system, web search & fetch, SSH tool, Cursor provider integration, multi-credential support, image generation, TUI overhaul, edit fuzzy matching, and more. It offers a modern terminal interface with smart session management, supports multiple AI providers, and includes various tools for coding, task management, code review, and interactive questioning.
llxprt-code
LLxprt Code is an AI-powered coding assistant that works with any LLM provider, offering a command-line interface for querying and editing codebases, generating applications, and automating development workflows. It supports various subscriptions, provider flexibility, top open models, local model support, and a privacy-first approach. Users can interact with LLxprt Code in both interactive and non-interactive modes, leveraging features like subscription OAuth, multi-account failover, load balancer profiles, and extensive provider support. The tool also allows for the creation of advanced subagents for specialized tasks and integrates with the Zed editor for in-editor chat and code selection.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
trpc-agent-go
A powerful Go framework for building intelligent agent systems with large language models (LLMs), hierarchical planners, memory, telemetry, and a rich tool ecosystem. tRPC-Agent-Go enables the creation of autonomous or semi-autonomous agents that reason, call tools, collaborate with sub-agents, and maintain long-term state. The framework provides detailed documentation, examples, and tools for accelerating the development of AI applications.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
human
AI-powered 3D Face Detection & Rotation Tracking, Face Description & Recognition, Body Pose Tracking, 3D Hand & Finger Tracking, Iris Analysis, Age & Gender & Emotion Prediction, Gaze Tracking, Gesture Recognition, Body Segmentation

TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.

layra
LAYRA is the world's first visual-native AI automation engine that sees documents like a human, preserves layout and graphical elements, and executes arbitrarily complex workflows with full Python control. It empowers users to build next-generation intelligent systems with no limits or compromises. Built for Enterprise-Grade deployment, LAYRA features a modern frontend, high-performance backend, decoupled service architecture, visual-native multimodal document understanding, and a powerful workflow engine.
evi-run
evi-run is a powerful, production-ready multi-agent AI system built on Python using the OpenAI Agents SDK. It offers instant deployment, ultimate flexibility, built-in analytics, Telegram integration, and scalable architecture. The system features memory management, knowledge integration, task scheduling, multi-agent orchestration, custom agent creation, deep research, web intelligence, document processing, image generation, DEX analytics, and Solana token swap. It supports flexible usage modes like private, free, and pay mode, with upcoming features including NSFW mode, task scheduler, and automatic limit orders. The technology stack includes Python 3.11, OpenAI Agents SDK, Telegram Bot API, PostgreSQL, Redis, and Docker & Docker Compose for deployment.
For similar tasks

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.
lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
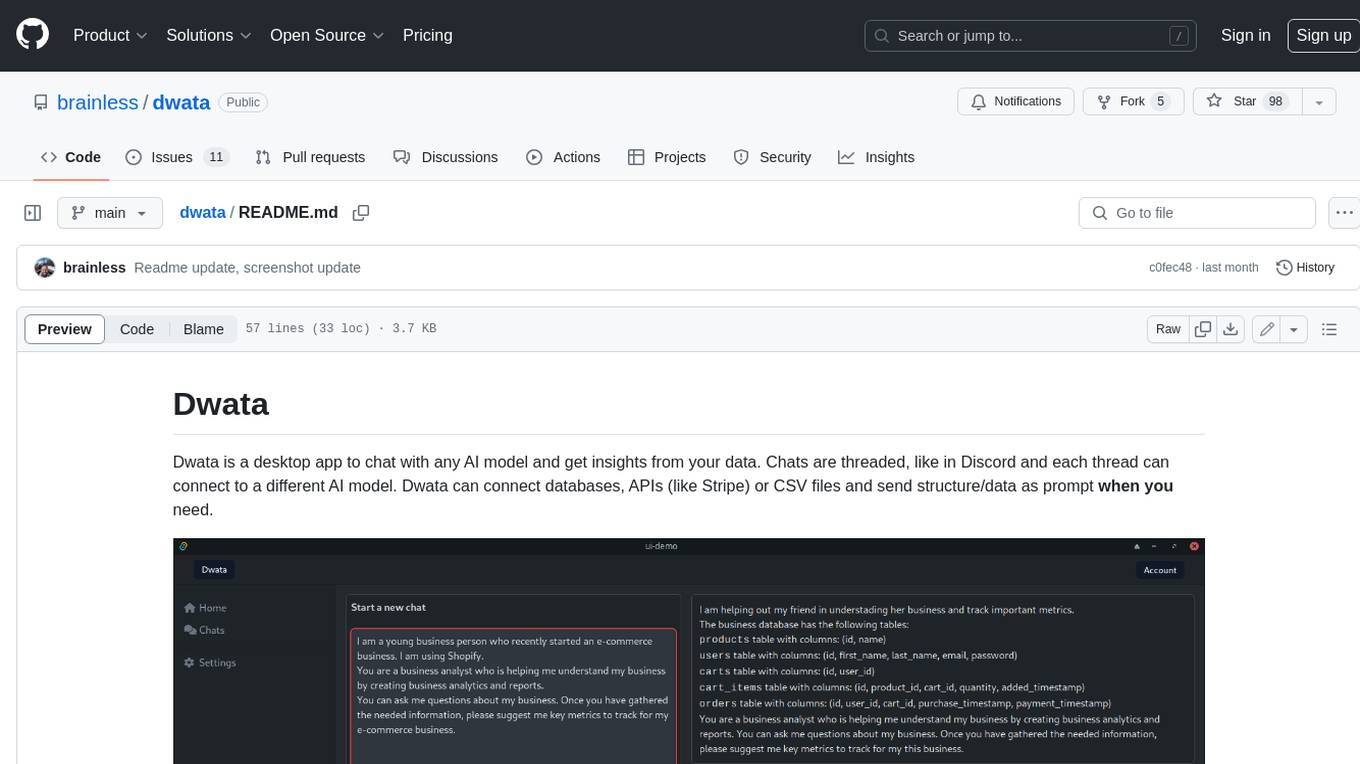
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.
For similar jobs
lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!