Best AI tools for< Evaluate Model Performance >
20 - AI tool Sites
Encord
Encord is a leading data development platform designed for computer vision and multimodal AI teams. It offers a comprehensive suite of tools to manage, clean, and curate data, streamline labeling and workflow management, and evaluate AI model performance. With features like data indexing, annotation, and active model evaluation, Encord empowers users to accelerate their AI data workflows and build robust models efficiently.
Encord
Encord is a complete data development platform designed for AI applications, specifically tailored for computer vision and multimodal AI teams. It offers tools to intelligently manage, clean, and curate data, streamline labeling and workflow management, and evaluate model performance. Encord aims to unlock the potential of AI for organizations by simplifying data-centric AI pipelines, enabling the building of better models and deploying high-quality production AI faster.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
integrate.ai
integrate.ai is a platform that enables data and analytics providers to collaborate easily with enterprise data science teams without moving data. Powered by federated learning technology, the platform allows for efficient proof of concepts, data experimentation, infrastructure agnostic evaluations, collaborative data evaluations, and data governance controls. It supports various data science jobs such as match rate analysis, exploratory data analysis, correlation analysis, model performance analysis, feature importance & data influence, and model validation. The platform integrates with popular data science tools like Azure, Jupyter, Databricks, AWS, GCP, Snowflake, Pandas, PyTorch, MLflow, and scikit-learn.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.
Inedit
Inedit is an AI-powered editor widget that enhances webpage content editing instantly. It offers features like AI technology, manual editing, effortless editing of multiple elements, and the ability to inspect deeper structures of webpages. The tool is powered by OpenAI GPT Models, providing unparalleled flexibility and performance. Users can seamlessly edit, evaluate, and publish content, ensuring only approved content reaches the audience.
Arthur
Arthur is an industry-leading MLOps platform that simplifies deployment, monitoring, and management of traditional and generative AI models. It ensures scalability, security, compliance, and efficient enterprise use. Arthur's turnkey solutions enable companies to integrate the latest generative AI technologies into their operations, making informed, data-driven decisions. The platform offers open-source evaluation products, model-agnostic monitoring, deployment with leading data science tools, and model risk management capabilities. It emphasizes collaboration, security, and compliance with industry standards.
Vals AI
Vals AI is an advanced AI tool that provides benchmark reports and comparisons for various models in the fields of finance, coding, and law. The platform offers insights into the performance of different AI models across different tasks and industries. Vals AI aims to bridge the gap in model benchmarking and provide valuable information for users looking to evaluate and compare AI models for specific tasks.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.

Libera Global AI
Libera Global AI is an AI and blockchain solution provider for emerging market retail. The platform empowers small businesses and brands in emerging markets with AI-driven insights to enhance visibility, efficiency, and profitability. By harnessing the power of AI and blockchain, Libera aims to create a more connected and transparent retail ecosystem in regions like Asia, Africa, and beyond. The company offers innovative solutions such as Display AI, Receipt AI, Knowledge Graph API, and Large Vision Model to revolutionize market evaluation and decision-making processes. With a mission to bridge the gap in retail data challenges, Libera is shaping the future of retail by enabling businesses to make smarter decisions and drive growth.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
Prelaunch.com
Prelaunch.com is an AI-powered platform that provides bullet-proof insights from ready-to-buy customers for product development and market validation. It offers a range of features including performance dashboard, surveys, AI idea validation, AI market research, and next-gen focus groups. The platform helps businesses test and evaluate demand for products before production, ensuring optimal pricing, market positioning, and business model testing. Prelaunch.com leverages real-world audiences to gather genuine insights through surveys, interviews, and focus groups, enabling users to make informed decisions based on validated data.
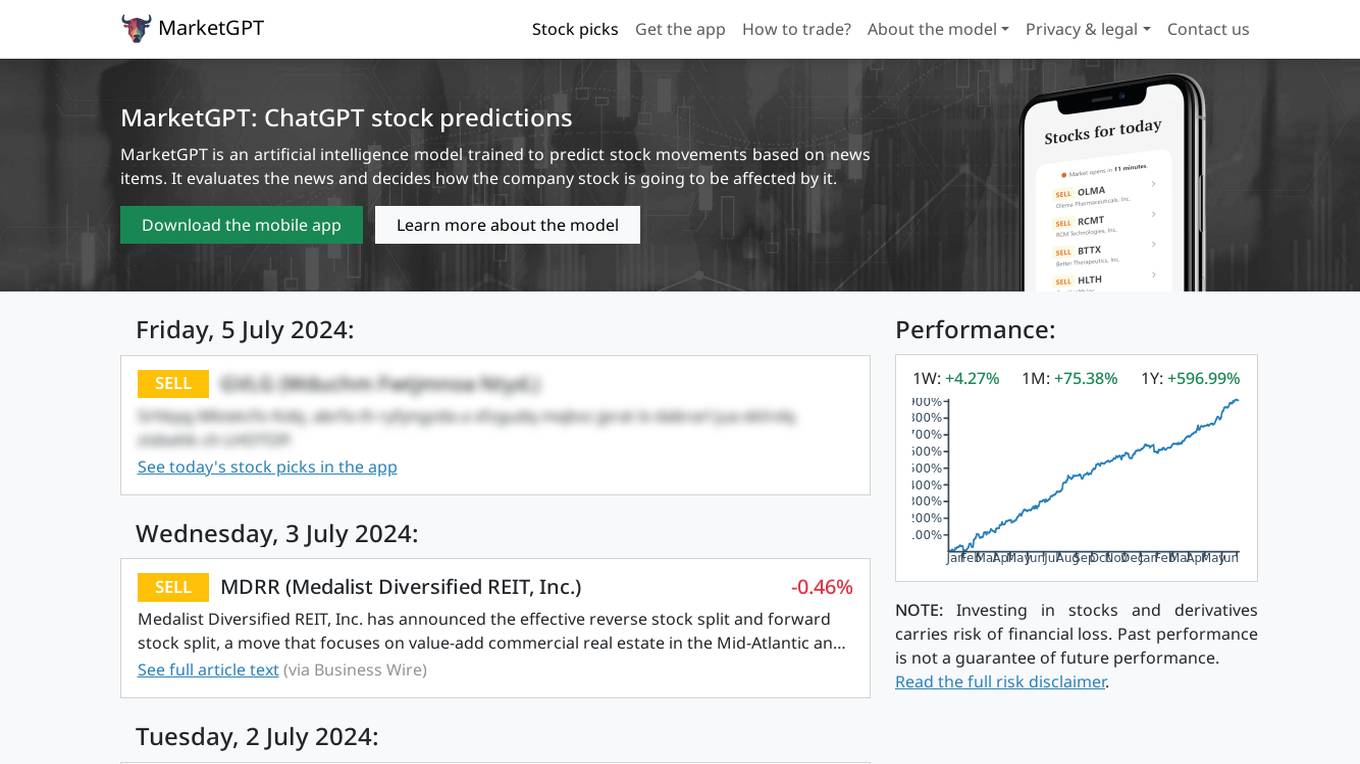
MarketGPT
MarketGPT is an artificial intelligence model trained to predict stock movements based on news items. It evaluates the news and decides how the company stock is going to be affected by it. Users can access the model through the MarketGPT website or mobile app to get stock predictions and picks. The model's performance can be viewed for different time frames such as 1 week, 1 month, and 1 year. However, users are advised that investing in stocks and derivatives carries a risk of financial loss, and past performance is not a guarantee of future performance. MarketGPT is designed to assist users in making informed decisions in the stock market.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
49 - Open Source AI Tools

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.

UMOE-Scaling-Unified-Multimodal-LLMs
Uni-MoE is a MoE-based unified multimodal model that can handle diverse modalities including audio, speech, image, text, and video. The project focuses on scaling Unified Multimodal LLMs with a Mixture of Experts framework. It offers enhanced functionality for training across multiple nodes and GPUs, as well as parallel processing at both the expert and modality levels. The model architecture involves three training stages: building connectors for multimodal understanding, developing modality-specific experts, and incorporating multiple trained experts into LLMs using the LoRA technique on mixed multimodal data. The tool provides instructions for installation, weights organization, inference, training, and evaluation on various datasets.

AnglE
AnglE is a library for training state-of-the-art BERT/LLM-based sentence embeddings with just a few lines of code. It also serves as a general sentence embedding inference framework, allowing for inferring a variety of transformer-based sentence embeddings. The library supports various loss functions such as AnglE loss, Contrastive loss, CoSENT loss, and Espresso loss. It provides backbones like BERT-based models, LLM-based models, and Bi-directional LLM-based models for training on single or multi-GPU setups. AnglE has achieved significant performance on various benchmarks and offers official pretrained models for both BERT-based and LLM-based models.
Awesome-LWMs
Awesome Large Weather Models (LWMs) is a curated collection of articles and resources related to large weather models used in AI for Earth and AI for Science. It includes information on various cutting-edge weather forecasting models, benchmark datasets, and research papers. The repository serves as a hub for researchers and enthusiasts to explore the latest advancements in weather modeling and forecasting.
seismometer
Seismometer is a suite of tools designed to evaluate AI model performance in healthcare settings. It helps healthcare organizations assess the accuracy of AI models and ensure equitable care for diverse patient populations. The tool allows users to validate model performance using standardized evaluation criteria based on local data and workflows. It includes templates for analyzing statistical performance, fairness across different cohorts, and the impact of interventions on outcomes. Seismometer is continuously evolving to incorporate new validation and analysis techniques.
Phi-3CookBook
Phi-3CookBook is a manual on how to use the Microsoft Phi-3 family, which consists of open AI models developed by Microsoft. The Phi-3 models are highly capable and cost-effective small language models, outperforming models of similar and larger sizes across various language, reasoning, coding, and math benchmarks. The repository provides detailed information on different Phi-3 models, their performance, availability, and usage scenarios across different platforms like Azure AI Studio, Hugging Face, and Ollama. It also covers topics such as fine-tuning, evaluation, and end-to-end samples for Phi-3-mini and Phi-3-vision models, along with labs, workshops, and contributing guidelines.
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.
evidently
Evidently is an open-source Python library designed for evaluating, testing, and monitoring machine learning (ML) and large language model (LLM) powered systems. It offers a wide range of functionalities, including working with tabular, text data, and embeddings, supporting predictive and generative systems, providing over 100 built-in metrics for data drift detection and LLM evaluation, allowing for custom metrics and tests, enabling both offline evaluations and live monitoring, and offering an open architecture for easy data export and integration with existing tools. Users can utilize Evidently for one-off evaluations using Reports or Test Suites in Python, or opt for real-time monitoring through the Dashboard service.
parea-sdk-py
Parea AI provides a SDK to evaluate & monitor AI applications. It allows users to test, evaluate, and monitor their AI models by defining and running experiments. The SDK also enables logging and observability for AI applications, as well as deploying prompts to facilitate collaboration between engineers and subject-matter experts. Users can automatically log calls to OpenAI and Anthropic, create hierarchical traces of their applications, and deploy prompts for integration into their applications.
GPTQModel
GPTQModel is an easy-to-use LLM quantization and inference toolkit based on the GPTQ algorithm. It provides support for weight-only quantization and offers features such as dynamic per layer/module flexible quantization, sharding support, and auto-heal quantization errors. The toolkit aims to ensure inference compatibility with HF Transformers, vLLM, and SGLang. It offers various model supports, faster quant inference, better quality quants, and security features like hash check of model weights. GPTQModel also focuses on faster quantization, improved quant quality as measured by PPL, and backports bug fixes from AutoGPTQ.
west
WeST is a Speech Recognition/Transcript tool developed in 300 lines of code, inspired by SLAM-ASR and LLaMA 3.1. The model includes a Language Model (LLM), a Speech Encoder, and a trainable Projector. It requires training data in jsonl format with 'wav' and 'txt' entries. WeST can be used for training and decoding speech recognition models.
Transformers_And_LLM_Are_What_You_Dont_Need
Transformers_And_LLM_Are_What_You_Dont_Need is a repository that explores the limitations of transformers in time series forecasting. It contains a collection of papers, articles, and theses discussing the effectiveness of transformers and LLMs in this domain. The repository aims to provide insights into why transformers may not be the best choice for time series forecasting tasks.

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.
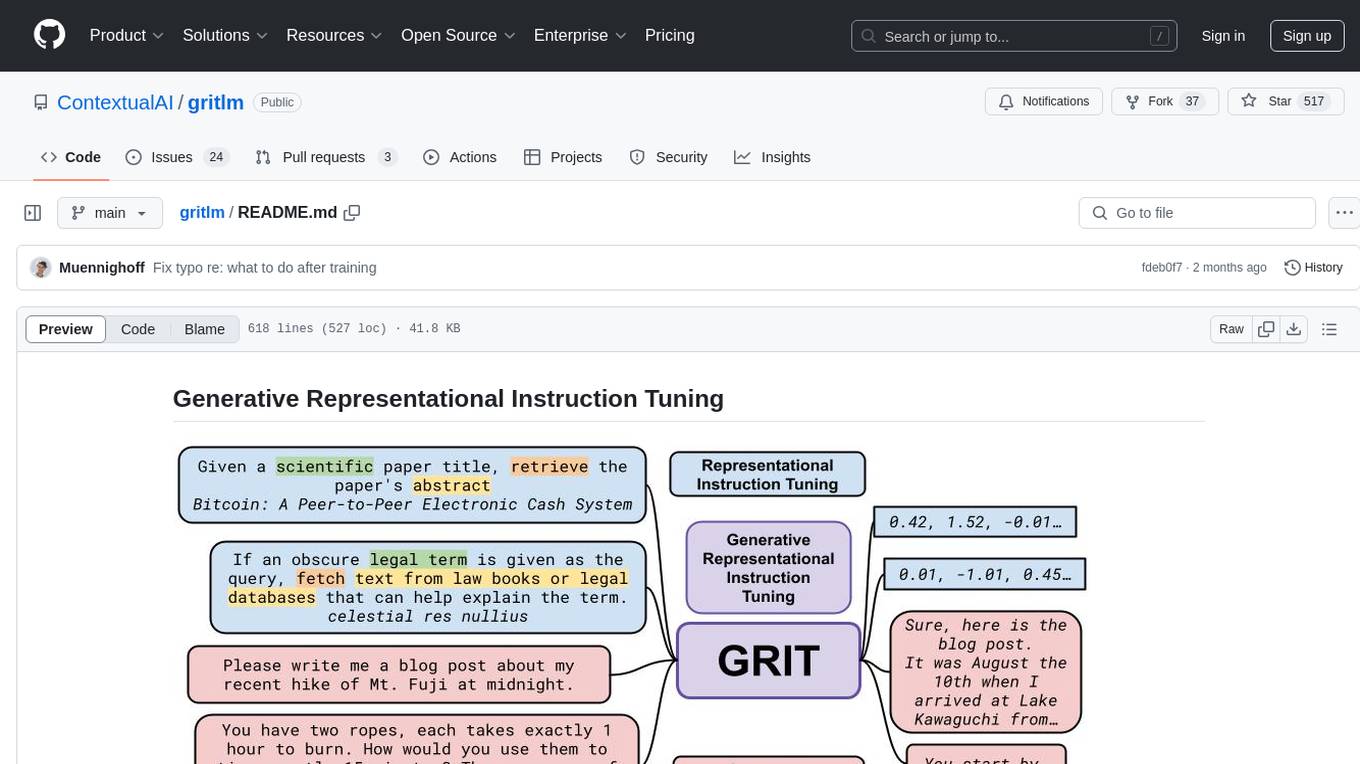
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.
MaskLLM
MaskLLM is a learnable pruning method that establishes Semi-structured Sparsity in Large Language Models (LLMs) to reduce computational overhead during inference. It is scalable and benefits from larger training datasets. The tool provides examples for running MaskLLM with Megatron-LM, preparing LLaMA checkpoints, pre-tokenizing C4 data for Megatron, generating prior masks, training MaskLLM, and evaluating the model. It also includes instructions for exporting sparse models to Huggingface.
evaluation-guidebook
The LLM Evaluation guidebook provides comprehensive guidance on evaluating language model performance, including different evaluation methods, designing evaluations, and practical tips. It caters to both beginners and advanced users, offering insights on model inference, tokenization, and troubleshooting. The guide covers automatic benchmarks, human evaluation, LLM-as-a-judge scenarios, troubleshooting practicalities, and general knowledge on LLM basics. It also includes planned articles on automated benchmarks, evaluation importance, task-building considerations, and model comparison challenges. The resource is enriched with recommended links and acknowledgments to contributors and inspirations.

pycm
PyCM is a Python library for multi-class confusion matrices, providing support for input data vectors and direct matrices. It is a comprehensive tool for post-classification model evaluation, offering a wide range of metrics for predictive models and accurate evaluation of various classifiers. PyCM is designed for data scientists who require diverse metrics for their models.
LLM-Drop
LLM-Drop is an official implementation of the paper 'What Matters in Transformers? Not All Attention is Needed'. The tool investigates redundancy in transformer-based Large Language Models (LLMs) by analyzing the architecture of Blocks, Attention layers, and MLP layers. It reveals that dropping certain Attention layers can enhance computational and memory efficiency without compromising performance. The tool provides a pipeline for Block Drop and Layer Drop based on LLaMA-Factory, and implements quantization using AutoAWQ and AutoGPTQ.

LightRAG
LightRAG is a repository hosting the code for LightRAG, a system that supports seamless integration of custom knowledge graphs, Oracle Database 23ai, Neo4J for storage, and multiple file types. It includes features like entity deletion, batch insert, incremental insert, and graph visualization. LightRAG provides an API server implementation for RESTful API access to RAG operations, allowing users to interact with it through HTTP requests. The repository also includes evaluation scripts, code for reproducing results, and a comprehensive code structure.
Graph-Reasoning-LLM
This repository, GraphWiz, focuses on developing an instruction-following Language Model (LLM) for solving graph problems. It includes GraphWiz LLMs with strong graph problem-solving abilities, GraphInstruct dataset with over 72.5k training samples across nine graph problem tasks, and models like GPT-4 and Mistral-7B for comparison. The project aims to map textual descriptions of graphs and structures to solve various graph problems explicitly in natural language.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
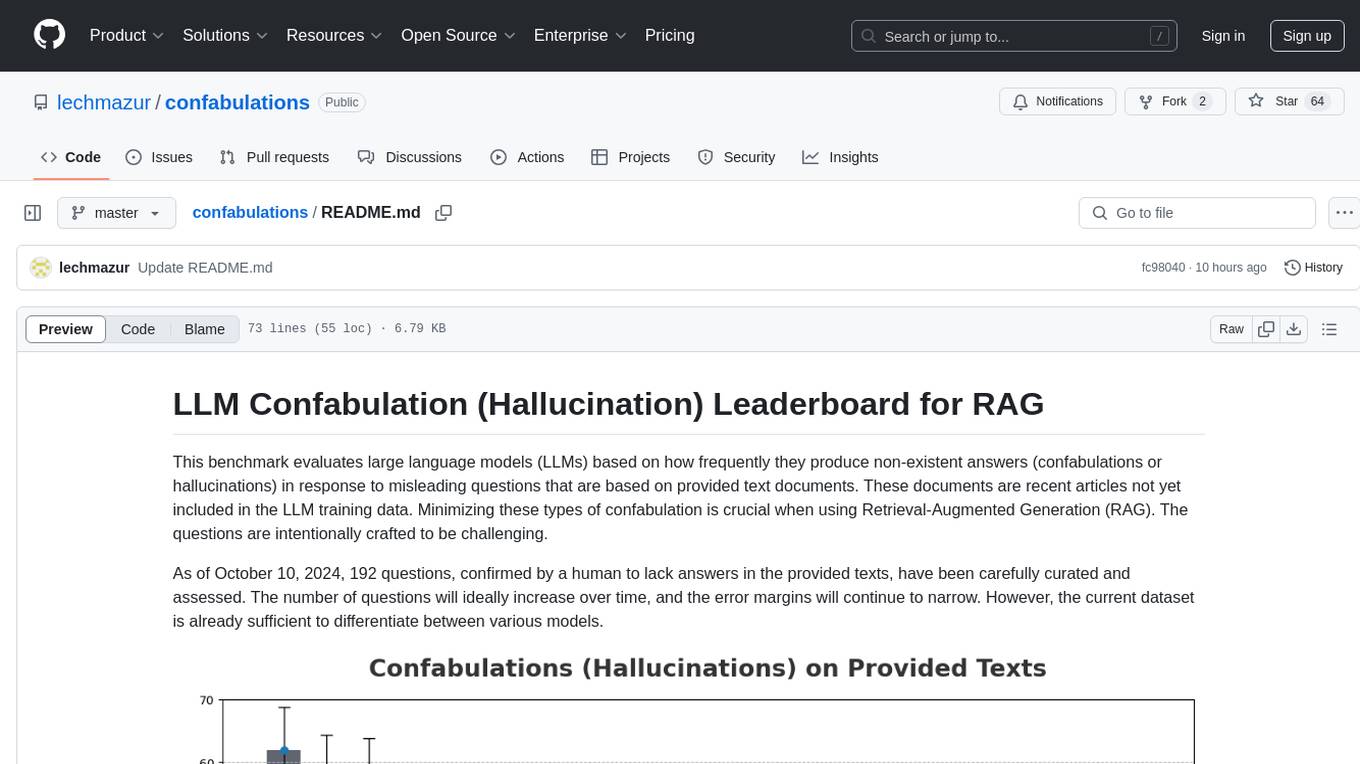
confabulations
LLM Confabulation Leaderboard evaluates large language models based on confabulations and non-response rates to challenging questions. It includes carefully curated questions with no answers in provided texts, aiming to differentiate between various models. The benchmark combines confabulation and non-response rates for comprehensive ranking, offering insights into model performance and tendencies. Additional notes highlight the meticulous human verification process, challenges faced by LLMs in generating valid responses, and the use of temperature settings. Updates and other benchmarks are also mentioned, providing a holistic view of the evaluation landscape.
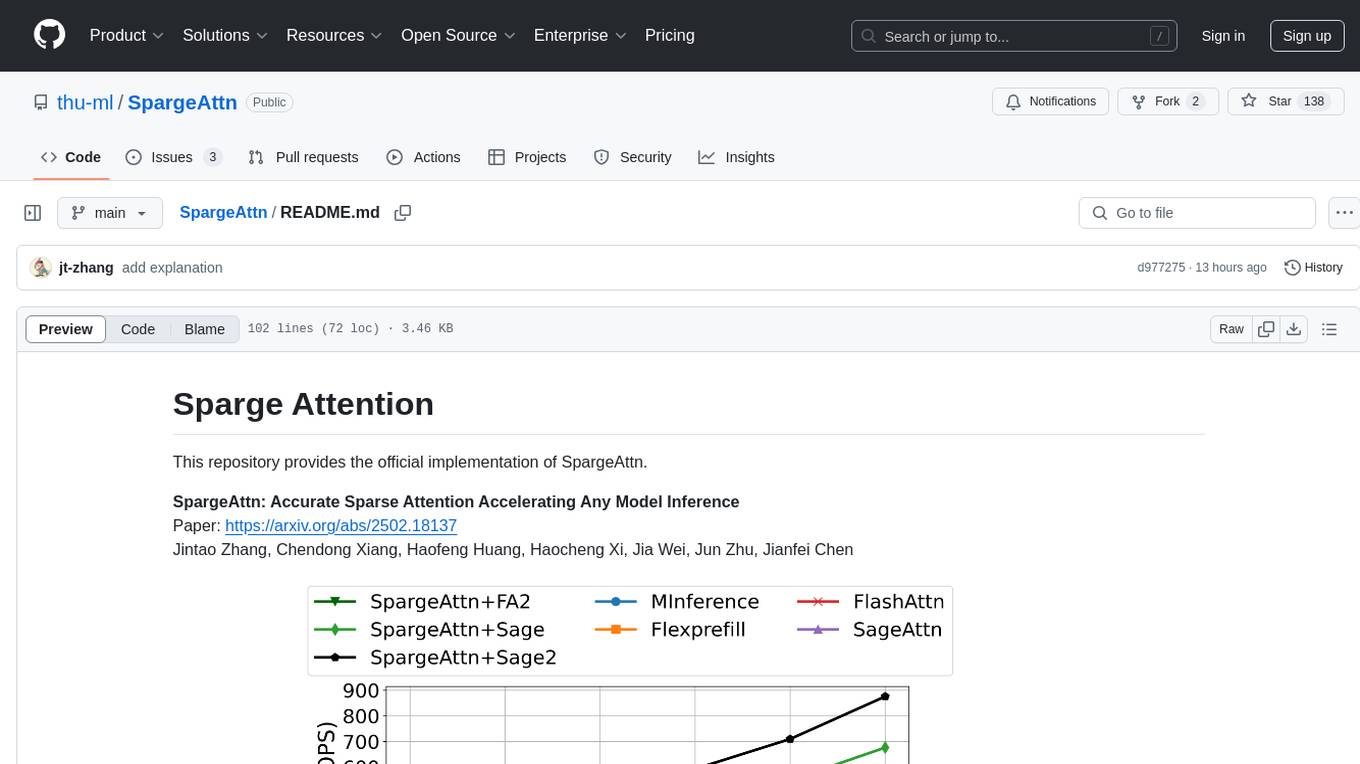
SpargeAttn
SpargeAttn is an official implementation designed for accelerating any model inference by providing accurate sparse attention. It offers a significant speedup in model performance while maintaining quality. The tool is based on SageAttention and SageAttention2, providing options for different levels of optimization. Users can easily install the package and utilize the available APIs for their specific needs. SpargeAttn is particularly useful for tasks requiring efficient attention mechanisms in deep learning models.
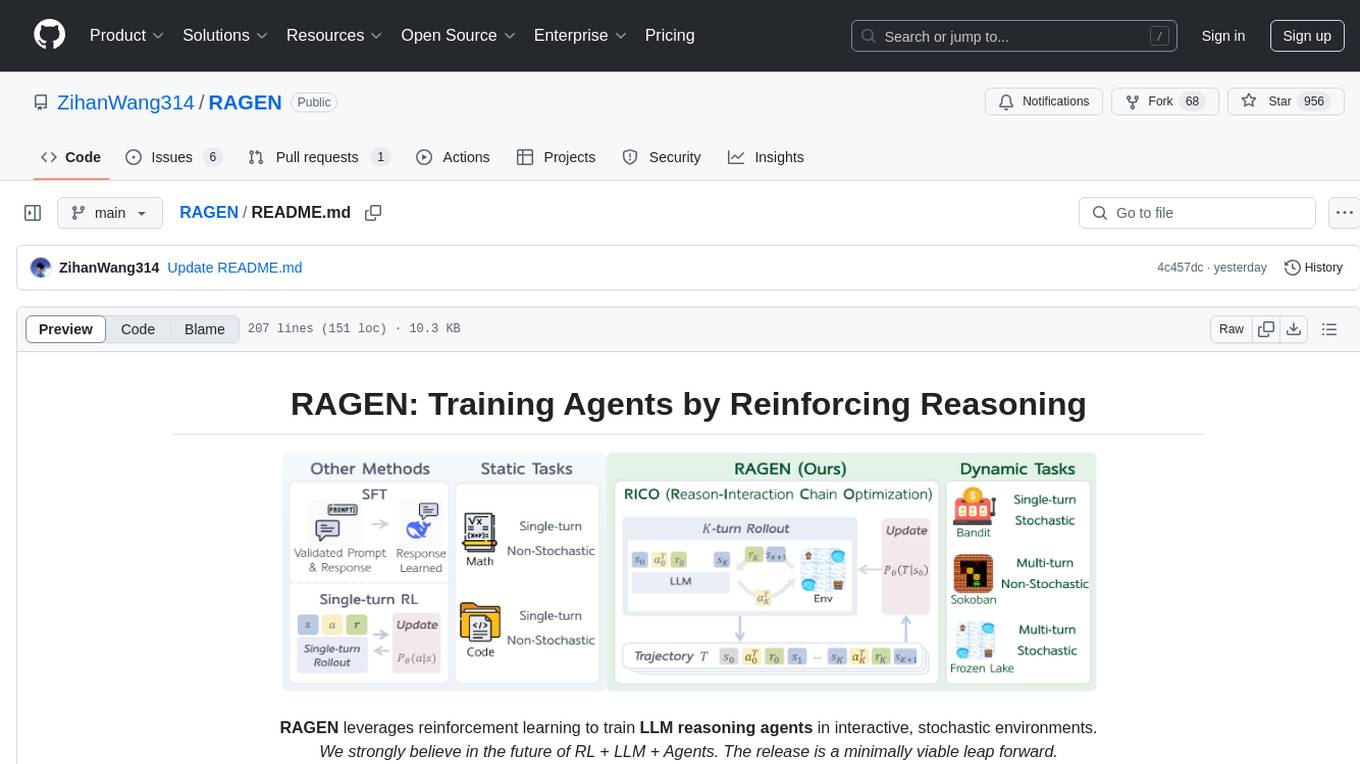
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.
AReaL
AReaL (Ant Reasoning RL) is an open-source reinforcement learning system developed at the RL Lab, Ant Research. It is designed for training Large Reasoning Models (LRMs) in a fully open and inclusive manner. AReaL provides reproducible experiments for 1.5B and 7B LRMs, showcasing its scalability and performance across diverse computational budgets. The system follows an iterative training process to enhance model performance, with a focus on mathematical reasoning tasks. AReaL is equipped to adapt to different computational resource settings, enabling users to easily configure and launch training trials. Future plans include support for advanced models, optimizations for distributed training, and exploring research topics to enhance LRMs' reasoning capabilities.
plants_disease_detection
This repository contains code for the AI challenger competition on plant disease detection. The goal is to classify nearly 50,000 plant leaf photos into 61 categories based on 'species-disease-severity'. The framework used is Keras with TensorFlow backend, implementing DenseNet for image classification. Data is uploaded to a private dataset on Kaggle for model training. The code includes data preparation, model training, and prediction steps.
understand-r1-zero
The 'understand-r1-zero' repository focuses on understanding R1-Zero-like training from a critical perspective. It provides insights into base models and reinforcement learning components, highlighting findings and proposing solutions for biased optimization. The repository offers a minimalist recipe for R1-Zero training, detailing the RL-tuning process and achieving state-of-the-art performance with minimal compute resources. It includes codebase, models, and paper related to R1-Zero training implemented with the Oat framework, emphasizing research-friendly and efficient LLM RL techniques.

agent-lightning
Agent Lightning is a lightweight and efficient tool for automating repetitive tasks in the field of data analysis and machine learning. It provides a user-friendly interface to create and manage automated workflows, allowing users to easily schedule and execute data processing, model training, and evaluation tasks. With its intuitive design and powerful features, Agent Lightning streamlines the process of building and deploying machine learning models, making it ideal for data scientists, machine learning engineers, and AI enthusiasts looking to boost their productivity and efficiency in their projects.
FAI-PEP
Facebook AI Performance Evaluation Platform is a framework and backend agnostic benchmarking platform to compare machine learning inferencing runtime metrics on a set of models and on a variety of backends. It provides a means to check performance regressions on each commit. The platform supports various performance metrics such as delay, error, energy/power, and user-provided metrics. It aims to easily evaluate the runtime performance of models and backends across different frameworks and platforms. The platform uses a centralized model/benchmark specification, fair input comparison, distributed benchmark execution, and centralized data consumption to reduce variation and provide a one-stop solution for performance comparison. Supported frameworks include Caffe2 and TFLite, while backends include CPU, GPU, DSP, Android, iOS, and Linux based systems. The platform also offers performance regression detection using A/B testing methodology to compare runtime differences between commits.
mlforpublicpolicylab
The Machine Learning for Public Policy Lab is a project-based course focused on solving real-world problems using machine learning in the context of public policy and social good. Students will gain hands-on experience building end-to-end machine learning systems, developing skills in problem formulation, working with messy data, communicating with non-technical stakeholders, model interpretability, and understanding algorithmic bias & disparities. The course covers topics such as project scoping, data acquisition, feature engineering, model evaluation, bias and fairness, and model interpretability. Students will work in small groups on policy projects, with graded components including project proposals, presentations, and final reports.
llm-benchmark
LLM SQL Generation Benchmark is a tool for evaluating different Large Language Models (LLMs) on their ability to generate accurate analytical SQL queries for Tinybird. It measures SQL query correctness, execution success, performance metrics, error handling, and recovery. The benchmark includes an automated retry mechanism for error correction. It supports various providers and models through OpenRouter and can be extended to other models. The benchmark is based on a GitHub dataset with 200M rows, where each LLM must produce SQL from 50 natural language prompts. Results are stored in JSON files and presented in a web application. Users can benchmark new models by following provided instructions.
easy-learn-ai
Easy AI is a modern web application platform focused on AI education, aiming to help users understand complex artificial intelligence concepts through a concise and intuitive approach. The platform integrates multiple learning modules, providing a comprehensive AI knowledge system from basic concepts to practical applications.
Drag-and-Drop-LLMs
Drag-and-Drop LLMs (DnD) is a prompt-conditioned parameter generator that eliminates per-task training by mapping task prompts directly to LoRA weight updates. It uses a lightweight text encoder to distill prompt batches into condition embeddings, transformed by a cascaded hyper convolutional decoder into LoRA matrices. DnD offers up to 12,000× lower overhead than full fine-tuning, gains up to 30% in performance over strong LoRAs on various tasks, and shows robust cross-domain generalization. It provides a rapid way to specialize large language models without gradient-based adaptation.
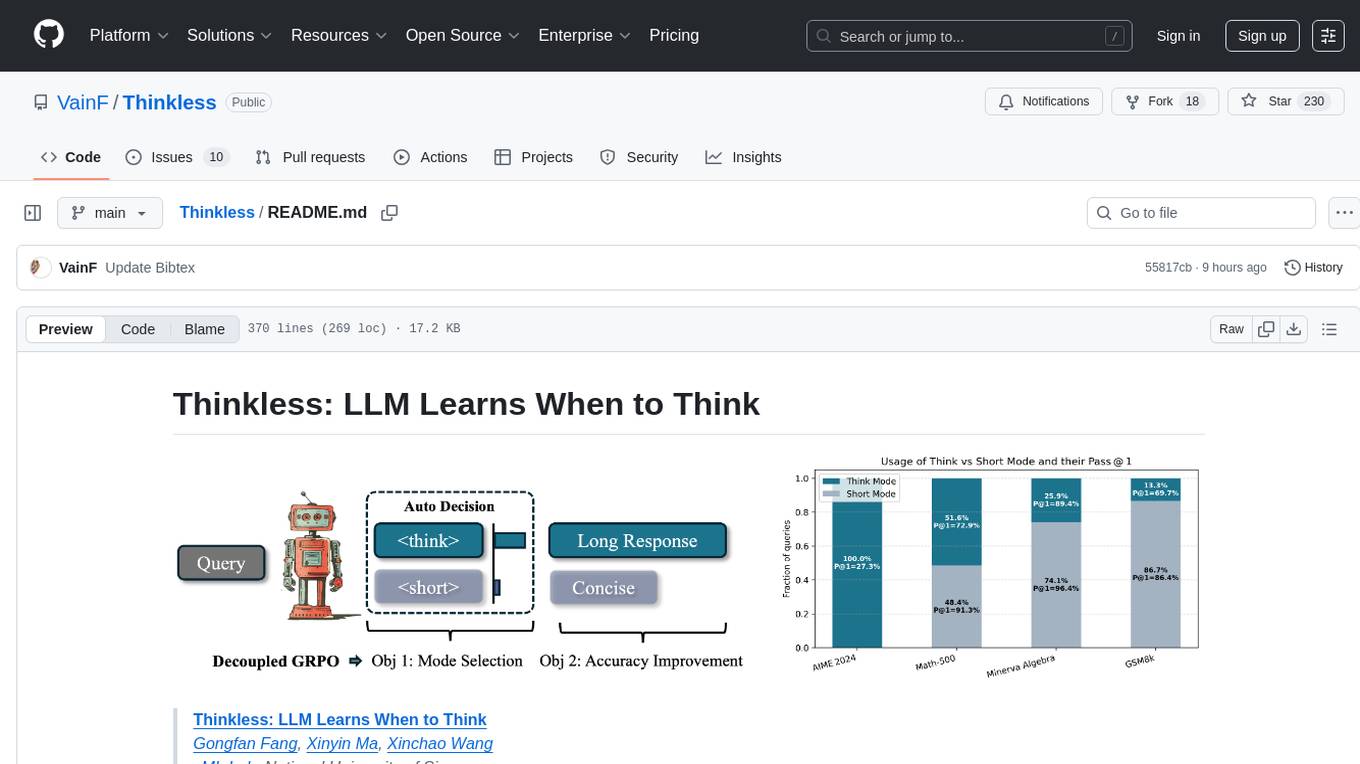
Thinkless
Thinkless is a learnable framework that empowers a Language and Reasoning Model (LLM) to adaptively select between short-form and long-form reasoning based on task complexity and model's ability. It is trained under a reinforcement learning paradigm and employs control tokens for concise responses and detailed reasoning. The core method uses a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm to govern reasoning mode selection and improve answer accuracy, reducing long-chain thinking by 50% - 90% on benchmarks like Minerva Algebra and MATH-500. Thinkless enhances computational efficiency of Reasoning Language Models.
fastapi-langgraph-agent-production-ready-template
A production-ready FastAPI template for building AI agent applications with LangGraph integration. This template provides a robust foundation for building scalable, secure, and maintainable AI agent services. It includes features like FastAPI for high-performance async API endpoints, LangGraph integration, structured logging, rate limiting, PostgreSQL for data persistence, Docker support, security measures like JWT-based authentication and input sanitization, developer-friendly features like environment-specific configuration and type hints, a model evaluation framework with automated metric-based evaluation and detailed JSON reports, and a configuration system with environment-specific settings.
20 - OpenAI Gpts

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model
Business Model Advisor
Business model expert, create detailed reports based on business ideas.
Startup Critic
Apply gold-standard startup valuation and assessment methods to identify risks and gaps in your business model and product ideas.

Startup Advisor
Startup advisor guiding founders through detailed idea evaluation, product-market-fit, business model, GTM, and scaling.
Face Rating GPT 😐
Evaluates faces and rates them out of 10 ⭐ Provides valuable feedback to improving your attractiveness!



Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub

GPT Architect
Expert in designing GPT models and translating user needs into technical specs.
GPT Designer
A creative aide for designing new GPT models, skilled in ideation and prompting.

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch