
plants_disease_detection
AI Challenger 2018 农作物病害检测
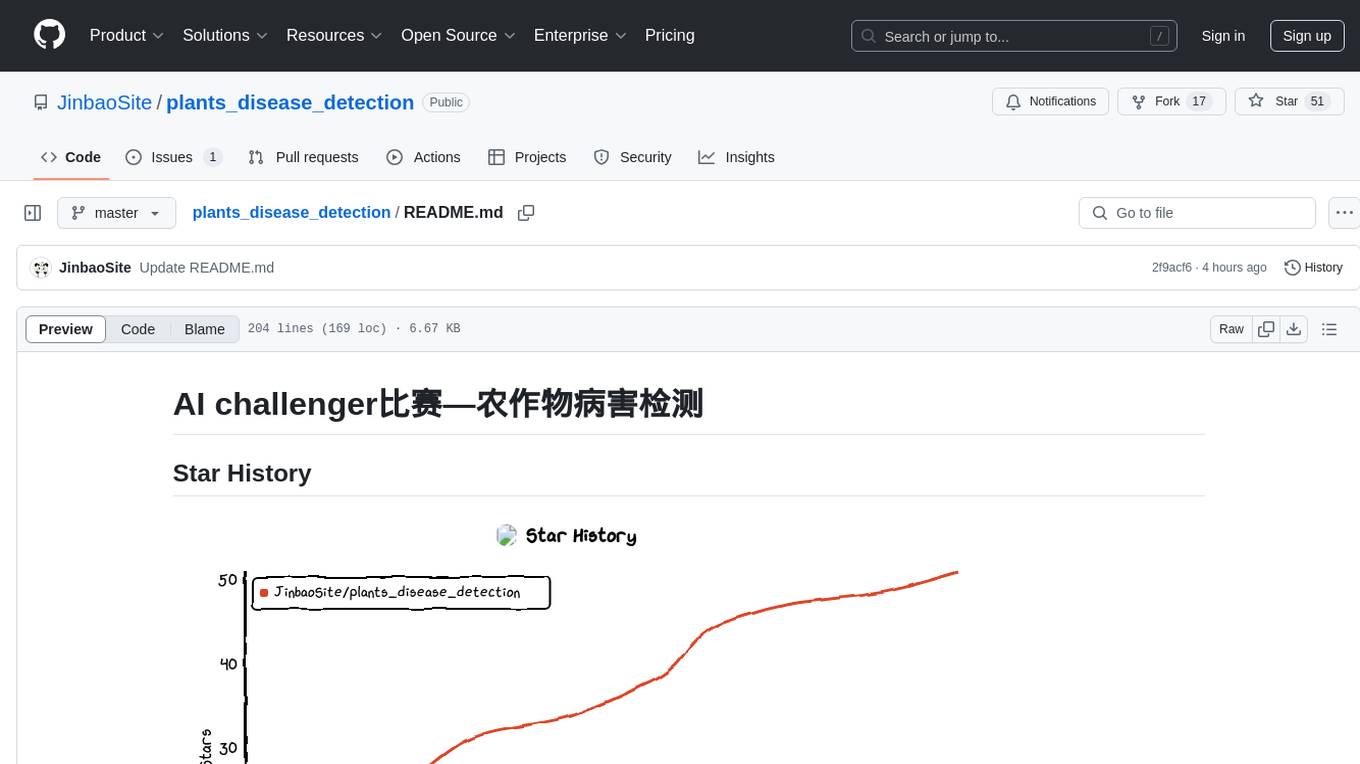
Stars: 51
This repository contains code for the AI challenger competition on plant disease detection. The goal is to classify nearly 50,000 plant leaf photos into 61 categories based on 'species-disease-severity'. The framework used is Keras with TensorFlow backend, implementing DenseNet for image classification. Data is uploaded to a private dataset on Kaggle for model training. The code includes data preparation, model training, and prediction steps.
README:
对近5万张按“物种-病害-程度”分成61类的植物叶片照片进行分类
我使用的是Keras,以TensorFlow为后端,手动实现了DenseNet用于图片分类 由于Kaggle现在可以免费使用GPU,所以采用将数据上传至Kaggle的私人Dataset上,在其上创建Kernel进行模型训练 (上传需要翻墙,有梯子最好)
def dense_block(x, blocks, name):
for i in range(blocks):
x = conv_block(x, 32, name=name + '_block' + str(i + 1))
return x
def transition_block(x, reduction, name):
bn_axis = 3
x = layers.BatchNormalization(axis=bn_axis, epsilon=1.001e-5,
name=name + '_bn')(x)
x = layers.Activation('relu', name=name + '_relu')(x)
x = layers.Conv2D(int(backend.int_shape(x)[bn_axis] * reduction), 1,
use_bias=False,
name=name + '_conv')(x)
x = layers.AveragePooling2D(2, strides=2, name=name + '_pool')(x)
return x
def conv_block(x, growth_rate, name):
bn_axis = 3
x1 = layers.BatchNormalization(axis=bn_axis,
epsilon=1.001e-5,
name=name + '_0_bn')(x)
x1 = layers.Activation('relu', name=name + '_0_relu')(x1)
x1 = layers.Conv2D(4 * growth_rate, 1,
use_bias=False,
name=name + '_1_conv')(x1)
x1 = layers.BatchNormalization(axis=bn_axis, epsilon=1.001e-5,
name=name + '_1_bn')(x1)
x1 = layers.Activation('relu', name=name + '_1_relu')(x1)
x1 = layers.Conv2D(growth_rate, 3,
padding='same',
use_bias=False,
name=name + '_2_conv')(x1)
x = layers.Concatenate(axis=bn_axis, name=name + '_concat')([x, x1])
return x
def DenseNet(blocks, input_shape=(150,150,3), classes=61):
img_input = Input(shape=input_shape)
bn_axis = 3
x = layers.ZeroPadding2D(padding=((3, 3), (3, 3)))(img_input)
x = layers.Conv2D(64, 7, strides=2, use_bias=False, name='conv1/conv')(x)
x = layers.BatchNormalization(
axis=bn_axis, epsilon=1.001e-5, name='conv1/bn')(x)
x = layers.Activation('relu', name='conv1/relu')(x)
x = layers.ZeroPadding2D(padding=((1, 1), (1, 1)))(x)
x = layers.MaxPooling2D(3, strides=2, name='pool1')(x)
x = dense_block(x, blocks[0], name='conv2')
x = transition_block(x, 0.5, name='pool2')
x = dense_block(x, blocks[1], name='conv3')
x = transition_block(x, 0.5, name='pool3')
x = dense_block(x, blocks[2], name='conv4')
x = transition_block(x, 0.5, name='pool4')
x = dense_block(x, blocks[3], name='conv5')
x = layers.BatchNormalization(axis=bn_axis, epsilon=1.001e-5, name='bn')(x)
x = layers.GlobalAveragePooling2D(name='avg_pool')(x)
x = Dense(512)(x)
x = BatchNormalization()(x)
x = PReLU()(x)
x = Dropout(0.5)(x)
x = Dense(classes, activation='softmax', name='fc61')(x)
inputs = img_input
model = Model(inputs, x, name='densenet')
return model
调用DenseNet函数即可创建
model = DenseNet(blocks=[6, 12, 48, 32], input_shape=(150,150,3),classes=61)
model.summary()
1、训练集、验证集生产器 这里对图片进行图像预处理,增加图片归一化、适度旋转、随机缩放、上下翻转
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
rotation_range=20,
zoom_range=0.2,
horizontal_flip=True)
val_datagen = ImageDataGenerator(rescale=1. / 255)
2、读取数据 从目录中读取数据
img_width, img_height = 150, 150
train_data_dir = '../input/train/train'
validation_data_dir = '../input/val/val'
batch_size = 64
classes = 61
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical') #多分类
validation_generator = val_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical') #多分类
1、先对模型进行预编译
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001),
metrics=['accuracy'])
2、训练模型 增加自动更新学习率和保存在验证集最后的模型参数
learning_rate_reduction = ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1,factor=0.5, min_lr=0.000001)
checkpoint = ModelCheckpoint(model_name, monitor='val_acc', save_best_only=True)
history = model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=30,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=[checkpoint, learning_rate_reduction])
训练次数由于受Kaggle中Kernel的使用时间受限,只能训练6小时,所以只能暂时训练30,不过可以多次迭代训练。
由于文件夹存放顺序跟window上不一样,所以实际上文件夹在Kaggle上Dataset上的存放顺序如下
rr = [0,
1,10,11,12,13,14,15,16,17,18,19,
2,20,21,22,23,24,25,26,27,28,29,
3,30,31,32,33,34,35,36,37,38,39,
4,40,41,42,43,44,45,46,47,48,49,
5,50,51,52,53,54,55,56,57,58,59,
6,60,
7,
8,
9]
images = os.listdir('../input/ai-challenger-pdr2018/testa/testA')
result = []
for img1 in images:
image_path = '../input/ai-challenger-pdr2018/testa/testA/' + img1
img = image.load_img(image_path, target_size=(150, 150))
x = image.img_to_array(img)/255.0
x = np.expand_dims(x, axis=0)
preds = model.predict(x)
tmp = dict()
tmp['image_id'] = img1
tmp['disease_class']=rr[int(np.argmax(preds))]
result.append(tmp)
最后保存为json
import json
json2 = json.dumps(result)
f = open('result.json','w',encoding='utf-8')
f.write(json2)
f.close()
最终的结果是0.87395的成绩

DenseNet模型训练 plants_disease_detection
如果你觉得我写的不错,请给我一下Star(^_^),谢谢!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for plants_disease_detection
Similar Open Source Tools
plants_disease_detection
This repository contains code for the AI challenger competition on plant disease detection. The goal is to classify nearly 50,000 plant leaf photos into 61 categories based on 'species-disease-severity'. The framework used is Keras with TensorFlow backend, implementing DenseNet for image classification. Data is uploaded to a private dataset on Kaggle for model training. The code includes data preparation, model training, and prediction steps.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
zig-aio
zig-aio is a library that provides an io_uring-like asynchronous API and coroutine-powered IO tasks for the Zig programming language. It offers support for different operating systems and backends, such as io_uring, iocp, and posix. The library aims to provide efficient IO operations by leveraging coroutines and async IO mechanisms. Users can create servers and clients with ease using the provided API functions for socket operations, sending and receiving data, and managing connections.

lagent
Lagent is a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents. It also provides some typical tools to augment LLM. The overview of our framework is shown below:
aigcpanel
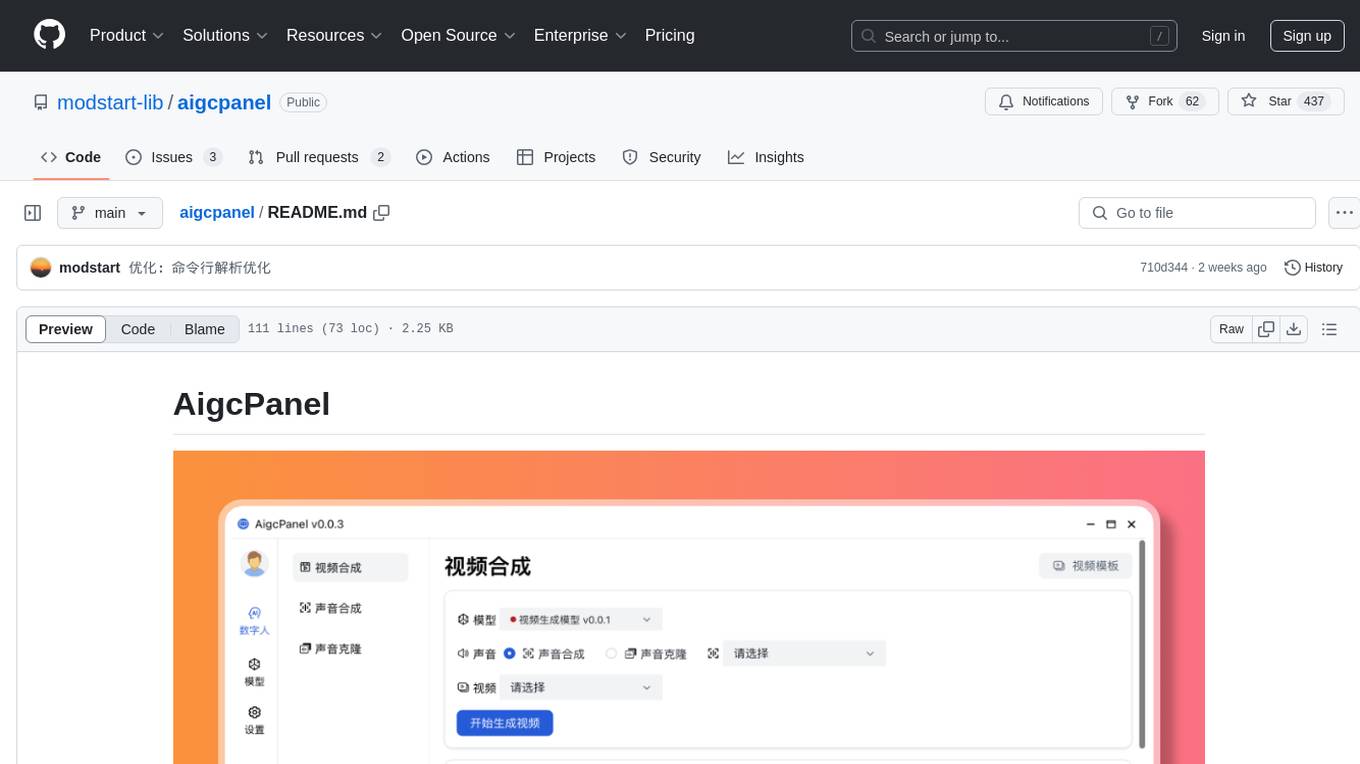
AigcPanel is a simple and easy-to-use all-in-one AI digital human system that even beginners can use. It supports video synthesis, voice synthesis, voice cloning, simplifies local model management, and allows one-click import and use of AI models. It prohibits the use of this product for illegal activities and users must comply with the laws and regulations of the People's Republic of China.
cntext
cntext is a text analysis package that provides semantic distance and semantic projection based on word embedding models. Additionally, cntext offers traditional methods such as word count statistics, readability, document similarity, sentiment analysis, etc. It includes modules for text statistics, sentiment analysis, dictionary construction, similarity calculations, and text-to-mind cognitive analysis.
LLaVA-OneVision-1.5
LLaVA-OneVision 1.5 is a fully open framework for democratized multimodal training, introducing a novel family of large multimodal models achieving state-of-the-art performance at lower cost through training on native resolution images. It offers superior performance across multiple benchmarks, high-quality data at scale with concept-balanced and diverse caption data, and an ultra-efficient training framework with support for MoE, FP8, and long sequence parallelization. The framework is fully open for community access and reproducibility, providing high-quality pre-training & SFT data, complete training framework & code, training recipes & configurations, and comprehensive training logs & metrics.
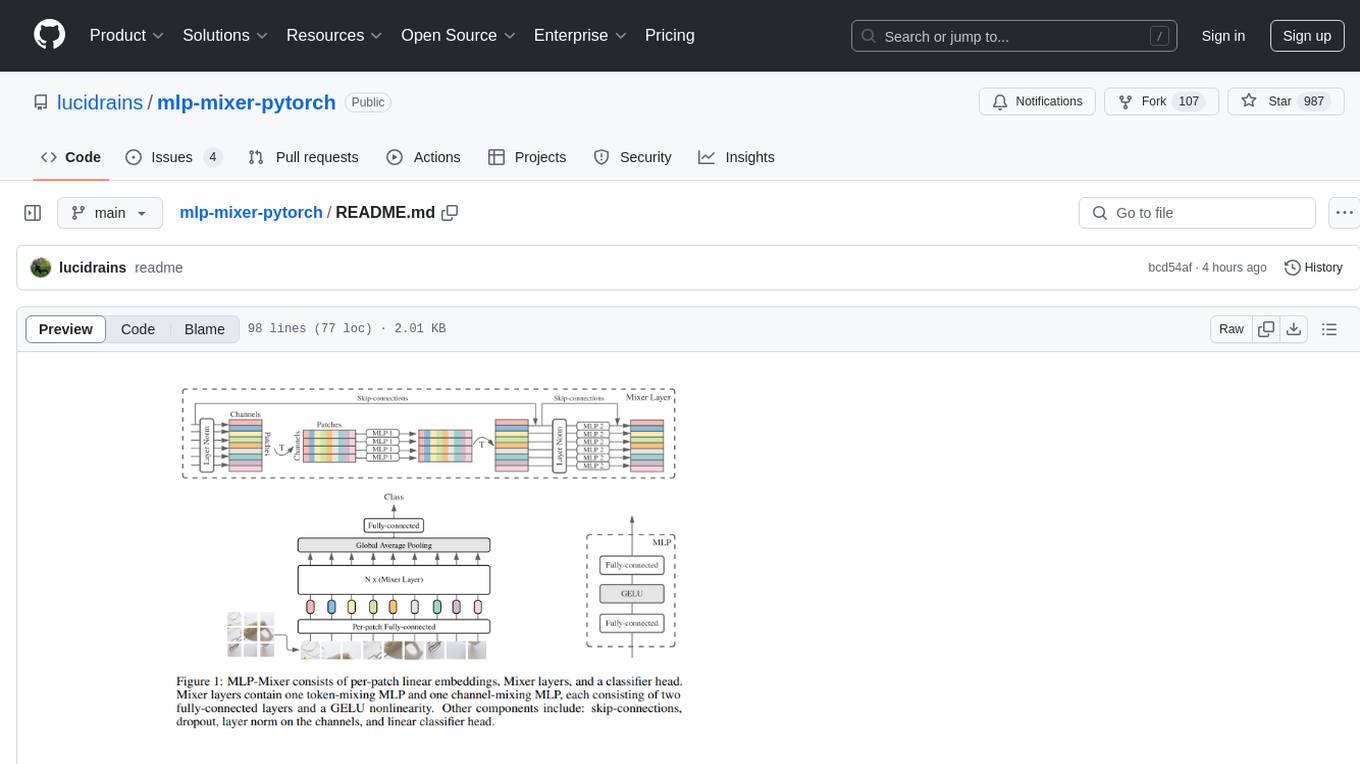
mlp-mixer-pytorch
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.
zenu
ZeNu is a high-performance deep learning framework implemented in pure Rust, featuring a pure Rust implementation for safety and performance, GPU performance comparable to PyTorch with CUDA support, a simple and intuitive API, and a modular design for easy extension. It supports various layers like Linear, Convolution 2D, LSTM, and optimizers such as SGD and Adam. ZeNu also provides device support for CPU and CUDA (NVIDIA GPU) with CUDA 12.3 and cuDNN 9. The project structure includes main library, automatic differentiation engine, neural network layers, matrix operations, optimization algorithms, CUDA implementation, and other support crates. Users can find detailed implementations like MNIST classification, CIFAR10 classification, and ResNet implementation in the examples directory. Contributions to ZeNu are welcome under the MIT License.
langchain-rust
LangChain Rust is a library for building applications with Large Language Models (LLMs) through composability. It provides a set of tools and components that can be used to create conversational agents, document loaders, and other applications that leverage LLMs. LangChain Rust supports a variety of LLMs, including OpenAI, Azure OpenAI, Ollama, and Anthropic Claude. It also supports a variety of embeddings, vector stores, and document loaders. LangChain Rust is designed to be easy to use and extensible, making it a great choice for developers who want to build applications with LLMs.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
MateChat
MateChat is a UI library for intelligent scenarios in front-end development, allowing easy construction of AI applications. It has been used in the intelligent transformation of multiple applications within Huawei and has supported the development of intelligent assistants such as CodeArts and InsCode AI IDE. The library offers components tailored for intelligent scenarios, out-of-the-box functionality, support for multiple scenarios and themes, and continuous evolution of features.
ddddocr
ddddocr is a Rust version of a simple OCR API server that provides easy deployment for captcha recognition without relying on the OpenCV library. It offers a user-friendly general-purpose captcha recognition Rust library. The tool supports recognizing various types of captchas, including single-line text, transparent black PNG images, target detection, and slider matching algorithms. Users can also import custom OCR training models and utilize the OCR API server for flexible OCR result control and range limitation. The tool is cross-platform and can be easily deployed.

herc.ai
Herc.ai is a powerful library for interacting with the Herc.ai API. It offers free access to users and supports all languages. Users can benefit from Herc.ai's features unlimitedly with a one-time subscription and API key. The tool provides functionalities for question answering and text-to-image generation, with support for various models and customization options. Herc.ai can be easily integrated into CLI, CommonJS, TypeScript, and supports beta models for advanced usage. Developed by FiveSoBes and Luppux Development.
openai-scala-client
This is a no-nonsense async Scala client for OpenAI API supporting all the available endpoints and params including streaming, chat completion, vision, and voice routines. It provides a single service called OpenAIService that supports various calls such as Models, Completions, Chat Completions, Edits, Images, Embeddings, Batches, Audio, Files, Fine-tunes, Moderations, Assistants, Threads, Thread Messages, Runs, Run Steps, Vector Stores, Vector Store Files, and Vector Store File Batches. The library aims to be self-contained with minimal dependencies and supports API-compatible providers like Azure OpenAI, Azure AI, Anthropic, Google Vertex AI, Groq, Grok, Fireworks AI, OctoAI, TogetherAI, Cerebras, Mistral, Deepseek, Ollama, FastChat, and more.
For similar tasks
plants_disease_detection
This repository contains code for the AI challenger competition on plant disease detection. The goal is to classify nearly 50,000 plant leaf photos into 61 categories based on 'species-disease-severity'. The framework used is Keras with TensorFlow backend, implementing DenseNet for image classification. Data is uploaded to a private dataset on Kaggle for model training. The code includes data preparation, model training, and prediction steps.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.
For similar jobs
AgroTech-AI
AgroTech AI platform is a comprehensive web-based tool where users can access various machine learning models for making accurate predictions related to agriculture. It offers solutions for crop management, soil health assessment, pest control, and more. The platform implements machine learning algorithms to provide functionalities like fertilizer prediction, crop prediction, soil quality prediction, yield prediction, and mushroom edibility prediction.
plants_disease_detection
This repository contains code for the AI challenger competition on plant disease detection. The goal is to classify nearly 50,000 plant leaf photos into 61 categories based on 'species-disease-severity'. The framework used is Keras with TensorFlow backend, implementing DenseNet for image classification. Data is uploaded to a private dataset on Kaggle for model training. The code includes data preparation, model training, and prediction steps.
AgriTech
AgriTech is an AI-powered smart agriculture platform designed to assist farmers with crop recommendations, yield prediction, plant disease detection, and community-driven collaboration—enabling sustainable and data-driven farming practices. It offers AI-driven decision support for modern agriculture, early-stage plant disease detection, crop yield forecasting using machine learning models, and a collaborative ecosystem for farmers and stakeholders. The platform includes features like crop recommendation, yield prediction, disease detection, an AI chatbot for platform guidance and agriculture support, a farmer community, and shopkeeper listings. AgriTech's AI chatbot provides comprehensive support for farmers with features like platform guidance, agriculture support, decision making, image analysis, and 24/7 support. The tech stack includes frontend technologies like HTML5, CSS3, JavaScript, backend technologies like Python (Flask) and optional Node.js, machine learning libraries like TensorFlow, Scikit-learn, OpenCV, and database & DevOps tools like MySQL, MongoDB, Firebase, Docker, and GitHub Actions.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.