
lagent
A lightweight framework for building LLM-based agents
Stars: 2056

Lagent is a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents. It also provides some typical tools to augment LLM. The overview of our framework is shown below:
README:







👋 join us on 𝕏 (Twitter), Discord and WeChat
Install from source:
git clone https://github.com/InternLM/lagent.git
cd lagent
pip install -e .Lagent is inspired by the design philosophy of PyTorch. We expect that the analogy of neural network layers will make the workflow clearer and more intuitive, so users only need to focus on creating layers and defining message passing between them in a Pythonic way. This is a simple tutorial to get you quickly started with building multi-agent applications.
Agents use AgentMessage for communication.
from typing import Dict, List
from lagent.agents import Agent
from lagent.schema import AgentMessage
from lagent.llms import VllmModel, INTERNLM2_META
llm = VllmModel(
path='Qwen/Qwen2-7B-Instruct',
meta_template=INTERNLM2_META,
tp=1,
top_k=1,
temperature=1.0,
stop_words=['<|im_end|>'],
max_new_tokens=1024,
)
system_prompt = '你的回答只能从“典”、“孝”、“急”三个字中选一个。'
agent = Agent(llm, system_prompt)
user_msg = AgentMessage(sender='user', content='今天天气情况')
bot_msg = agent(user_msg)
print(bot_msg)content='急' sender='Agent' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
Both input and output messages will be added to the memory of Agent in each forward pass. This is performed in __call__ rather than forward. See the following pseudo code
def __call__(self, *message):
message = pre_hooks(message)
add_memory(message)
message = self.forward(*message)
add_memory(message)
message = post_hooks(message)
return messageInspect the memory in two ways
memory: List[AgentMessage] = agent.memory.get_memory()
print(memory)
print('-' * 120)
dumped_memory: Dict[str, List[dict]] = agent.state_dict()
print(dumped_memory['memory'])[AgentMessage(content='今天天气情况', sender='user', formatted=None, extra_info=None, type=None, receiver=None, stream_state=<AgentStatusCode.END: 0>), AgentMessage(content='急', sender='Agent', formatted=None, extra_info=None, type=None, receiver=None, stream_state=<AgentStatusCode.END: 0>)]
------------------------------------------------------------------------------------------------------------------------
[{'content': '今天天气情况', 'sender': 'user', 'formatted': None, 'extra_info': None, 'type': None, 'receiver': None, 'stream_state': <AgentStatusCode.END: 0>}, {'content': '急', 'sender': 'Agent', 'formatted': None, 'extra_info': None, 'type': None, 'receiver': None, 'stream_state': <AgentStatusCode.END: 0>}]
Clear the memory of this session(session_id=0 by default):
agent.reset()DefaultAggregator is called under the hood to assemble and convert AgentMessage to OpenAI message format.
def forward(self, *message: AgentMessage, session_id=0, **kwargs) -> Union[AgentMessage, str]:
formatted_messages = self.aggregator.aggregate(
self.memory.get(session_id),
self.name,
self.output_format,
self.template,
)
llm_response = self.llm.chat(formatted_messages, **kwargs)
...Implement a simple aggregator that can receive few-shots
from typing import List, Union
from lagent.memory import Memory
from lagent.prompts import StrParser
from lagent.agents.aggregator import DefaultAggregator
class FewshotAggregator(DefaultAggregator):
def __init__(self, few_shot: List[dict] = None):
self.few_shot = few_shot or []
def aggregate(self,
messages: Memory,
name: str,
parser: StrParser = None,
system_instruction: Union[str, dict, List[dict]] = None) -> List[dict]:
_message = []
if system_instruction:
_message.extend(
self.aggregate_system_intruction(system_instruction))
_message.extend(self.few_shot)
messages = messages.get_memory()
for message in messages:
if message.sender == name:
_message.append(
dict(role='assistant', content=str(message.content)))
else:
user_message = message.content
if len(_message) > 0 and _message[-1]['role'] == 'user':
_message[-1]['content'] += user_message
else:
_message.append(dict(role='user', content=user_message))
return _message
agent = Agent(
llm,
aggregator=FewshotAggregator(
[
{"role": "user", "content": "今天天气"},
{"role": "assistant", "content": "【晴】"},
]
)
)
user_msg = AgentMessage(sender='user', content='昨天天气')
bot_msg = agent(user_msg)
print(bot_msg)content='【多云转晴,夜间有轻微降温】' sender='Agent' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
In AgentMessage, formatted is reserved to store information parsed by output_format from the model output.
def forward(self, *message: AgentMessage, session_id=0, **kwargs) -> Union[AgentMessage, str]:
...
llm_response = self.llm.chat(formatted_messages, **kwargs)
if self.output_format:
formatted_messages = self.output_format.parse_response(llm_response)
return AgentMessage(
sender=self.name,
content=llm_response,
formatted=formatted_messages,
)
...Use a tool parser as follows
from lagent.prompts.parsers import ToolParser
system_prompt = "逐步分析并编写Python代码解决以下问题。"
parser = ToolParser(tool_type='code interpreter', begin='```python\n', end='\n```\n')
llm.gen_params['stop_words'].append('\n```\n')
agent = Agent(llm, system_prompt, output_format=parser)
user_msg = AgentMessage(
sender='user',
content='Marie is thinking of a multiple of 63, while Jay is thinking of a '
'factor of 63. They happen to be thinking of the same number. There are '
'two possibilities for the number that each of them is thinking of, one '
'positive and one negative. Find the product of these two numbers.')
bot_msg = agent(user_msg)
print(bot_msg.model_dump_json(indent=4)){
"content": "首先,我们需要找出63的所有正因数和负因数。63的正因数可以通过分解63的质因数来找出,即\\(63 = 3^2 \\times 7\\)。因此,63的正因数包括1, 3, 7, 9, 21, 和 63。对于负因数,我们只需将上述正因数乘以-1。\n\n接下来,我们需要找出与63的正因数相乘的结果为63的数,以及与63的负因数相乘的结果为63的数。这可以通过将63除以每个正因数和负因数来实现。\n\n最后,我们将找到的两个数相乘得到最终答案。\n\n下面是Python代码实现:\n\n```python\ndef find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)",
"sender": "Agent",
"formatted": {
"tool_type": "code interpreter",
"thought": "首先,我们需要找出63的所有正因数和负因数。63的正因数可以通过分解63的质因数来找出,即\\(63 = 3^2 \\times 7\\)。因此,63的正因数包括1, 3, 7, 9, 21, 和 63。对于负因数,我们只需将上述正因数乘以-1。\n\n接下来,我们需要找出与63的正因数相乘的结果为63的数,以及与63的负因数相乘的结果为63的数。这可以通过将63除以每个正因数和负因数来实现。\n\n最后,我们将找到的两个数相乘得到最终答案。\n\n下面是Python代码实现:\n\n",
"action": "def find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)",
"status": 1
},
"extra_info": null,
"type": null,
"receiver": null,
"stream_state": 0
}
ActionExecutor uses the same communication data structure as Agent, but requires the content of input AgentMessage to be a dict containing:
-
name: tool name, e.g.'IPythonInterpreter','WebBrowser.search'. -
parameters: keyword arguments of the tool API, e.g.{'command': 'import math;math.sqrt(2)'},{'query': ['recent progress in AI']}.
You can register custom hooks for message conversion.
from lagent.hooks import Hook
from lagent.schema import ActionReturn, ActionStatusCode, AgentMessage
from lagent.actions import ActionExecutor, IPythonInteractive
class CodeProcessor(Hook):
def before_action(self, executor, message, session_id):
message = message.copy(deep=True)
message.content = dict(
name='IPythonInteractive', parameters={'command': message.formatted['action']}
)
return message
def after_action(self, executor, message, session_id):
action_return = message.content
if isinstance(action_return, ActionReturn):
if action_return.state == ActionStatusCode.SUCCESS:
response = action_return.format_result()
else:
response = action_return.errmsg
else:
response = action_return
message.content = response
return message
executor = ActionExecutor(actions=[IPythonInteractive()], hooks=[CodeProcessor()])
bot_msg = AgentMessage(
sender='Agent',
content='首先,我们需要...',
formatted={
'tool_type': 'code interpreter',
'thought': '首先,我们需要...',
'action': 'def find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)',
'status': 1
})
executor_msg = executor(bot_msg)
print(executor_msg)content='3969.0' sender='ActionExecutor' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
For convenience, Lagent provides InternLMActionProcessor which is adapted to messages formatted by ToolParser as mentioned above.
Lagent adopts dual interface design, where almost every component(LLMs, actions, action executors...) has the corresponding asynchronous variant by prefixing its identifier with 'Async'. It is recommended to use synchronous agents for debugging and asynchronous ones for large-scale inference to make the most of idle CPU and GPU resources.
However, make sure the internal consistency of agents, i.e. asynchronous agents should be equipped with asynchronous LLMs and asynchronous action executors that drive asynchronous tools.
from lagent.llms import VllmModel, AsyncVllmModel, LMDeployPipeline, AsyncLMDeployPipeline
from lagent.actions import ActionExecutor, AsyncActionExecutor, WebBrowser, AsyncWebBrowser
from lagent.agents import Agent, AsyncAgent, AgentForInternLM, AsyncAgentForInternLM- Try to implement
forwardinstead of__call__of subclasses unless necessary. - Always include the
session_idargument explicitly, which is designed for isolation of memory, LLM requests and tool invocation(e.g. maintain multiple independent IPython environments) in concurrency.
Math agents that solve problems by programming
from lagent.agents.aggregator import InternLMToolAggregator
class Coder(Agent):
def __init__(self, model_path, system_prompt, max_turn=3):
super().__init__()
llm = VllmModel(
path=model_path,
meta_template=INTERNLM2_META,
tp=1,
top_k=1,
temperature=1.0,
stop_words=['\n```\n', '<|im_end|>'],
max_new_tokens=1024,
)
self.agent = Agent(
llm,
system_prompt,
output_format=ToolParser(
tool_type='code interpreter', begin='```python\n', end='\n```\n'
),
# `InternLMToolAggregator` is adapted to `ToolParser` for aggregating
# messages with tool invocations and execution results
aggregator=InternLMToolAggregator(),
)
self.executor = ActionExecutor([IPythonInteractive()], hooks=[CodeProcessor()])
self.max_turn = max_turn
def forward(self, message: AgentMessage, session_id=0) -> AgentMessage:
for _ in range(self.max_turn):
message = self.agent(message, session_id=session_id)
if message.formatted['tool_type'] is None:
return message
message = self.executor(message, session_id=session_id)
return message
coder = Coder('Qwen/Qwen2-7B-Instruct', 'Solve the problem step by step with assistance of Python code')
query = AgentMessage(
sender='user',
content='Find the projection of $\\mathbf{a}$ onto $\\mathbf{b} = '
'\\begin{pmatrix} 1 \\\\ -3 \\end{pmatrix}$ if $\\mathbf{a} \\cdot \\mathbf{b} = 2.$'
)
answer = coder(query)
print(answer.content)
print('-' * 120)
for msg in coder.state_dict()['agent.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')Asynchronous blogging agents that improve writing quality by self-refinement (original AutoGen example)
import asyncio
import os
from lagent.llms import AsyncGPTAPI
from lagent.agents import AsyncAgent
os.environ['OPENAI_API_KEY'] = 'YOUR_API_KEY'
class PrefixedMessageHook(Hook):
def __init__(self, prefix: str, senders: list = None):
self.prefix = prefix
self.senders = senders or []
def before_agent(self, agent, messages, session_id):
for message in messages:
if message.sender in self.senders:
message.content = self.prefix + message.content
class AsyncBlogger(AsyncAgent):
def __init__(self, model_path, writer_prompt, critic_prompt, critic_prefix='', max_turn=3):
super().__init__()
llm = AsyncGPTAPI(model_type=model_path, retry=5, max_new_tokens=2048)
self.writer = AsyncAgent(llm, writer_prompt, name='writer')
self.critic = AsyncAgent(
llm, critic_prompt, name='critic', hooks=[PrefixedMessageHook(critic_prefix, ['writer'])]
)
self.max_turn = max_turn
async def forward(self, message: AgentMessage, session_id=0) -> AgentMessage:
for _ in range(self.max_turn):
message = await self.writer(message, session_id=session_id)
message = await self.critic(message, session_id=session_id)
return await self.writer(message, session_id=session_id)
blogger = AsyncBlogger(
'gpt-4o-2024-05-13',
writer_prompt="You are an writing assistant tasked to write engaging blogpost. You try to generate the best blogpost possible for the user's request. "
"If the user provides critique, then respond with a revised version of your previous attempts",
critic_prompt="Generate critique and recommendations on the writing. Provide detailed recommendations, including requests for length, depth, style, etc..",
critic_prefix='Reflect and provide critique on the following writing. \n\n',
)
user_prompt = (
"Write an engaging blogpost on the recent updates in {topic}. "
"The blogpost should be engaging and understandable for general audience. "
"Should have more than 3 paragraphes but no longer than 1000 words.")
bot_msgs = asyncio.get_event_loop().run_until_complete(
asyncio.gather(
*[
blogger(AgentMessage(sender='user', content=user_prompt.format(topic=topic)), session_id=i)
for i, topic in enumerate(['AI', 'Biotechnology', 'New Energy', 'Video Games', 'Pop Music'])
]
)
)
print(bot_msgs[0].content)
print('-' * 120)
for msg in blogger.state_dict(session_id=0)['writer.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')
print('-' * 120)
for msg in blogger.state_dict(session_id=0)['critic.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')A multi-agent workflow that performs information retrieval, data collection and chart plotting (original LangGraph example)
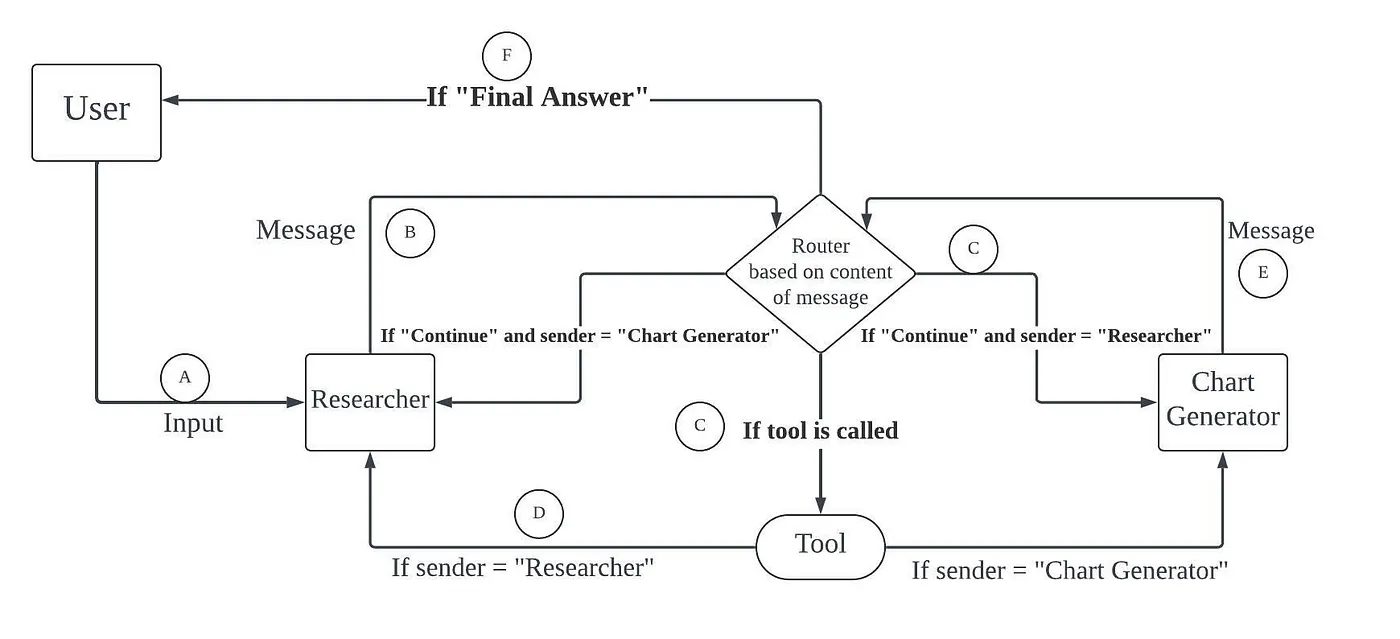
import json
from lagent.actions import IPythonInterpreter, WebBrowser, ActionExecutor
from lagent.agents.stream import get_plugin_prompt
from lagent.llms import GPTAPI
from lagent.hooks import InternLMActionProcessor
TOOL_TEMPLATE = (
"You are a helpful AI assistant, collaborating with other assistants. Use the provided tools to progress"
" towards answering the question. If you are unable to fully answer, that's OK, another assistant with"
" different tools will help where you left off. Execute what you can to make progress. If you or any of"
" the other assistants have the final answer or deliverable, prefix your response with {finish_pattern}"
" so the team knows to stop. You have access to the following tools:\n{tool_description}\nPlease provide"
" your thought process when you need to use a tool, followed by the call statement in this format:"
"\n{invocation_format}\\\\n**{system_prompt}**"
)
class DataVisualizer(Agent):
def __init__(self, model_path, research_prompt, chart_prompt, finish_pattern="Final Answer", max_turn=10):
super().__init__()
llm = GPTAPI(model_path, key='YOUR_OPENAI_API_KEY', retry=5, max_new_tokens=1024, stop_words=["```\n"])
interpreter, browser = IPythonInterpreter(), WebBrowser("BingSearch", api_key="YOUR_BING_API_KEY")
self.researcher = Agent(
llm,
TOOL_TEMPLATE.format(
finish_pattern=finish_pattern,
tool_description=get_plugin_prompt(browser),
invocation_format='```json\n{"name": {{tool name}}, "parameters": {{keyword arguments}}}\n```\n',
system_prompt=research_prompt,
),
output_format=ToolParser(
"browser",
begin="```json\n",
end="\n```\n",
validate=lambda x: json.loads(x.rstrip('`')),
),
aggregator=InternLMToolAggregator(),
name="researcher",
)
self.charter = Agent(
llm,
TOOL_TEMPLATE.format(
finish_pattern=finish_pattern,
tool_description=interpreter.name,
invocation_format='```python\n{{code}}\n```\n',
system_prompt=chart_prompt,
),
output_format=ToolParser(
"interpreter",
begin="```python\n",
end="\n```\n",
validate=lambda x: x.rstrip('`'),
),
aggregator=InternLMToolAggregator(),
name="charter",
)
self.executor = ActionExecutor([interpreter, browser], hooks=[InternLMActionProcessor()])
self.finish_pattern = finish_pattern
self.max_turn = max_turn
def forward(self, message, session_id=0):
for _ in range(self.max_turn):
message = self.researcher(message, session_id=session_id, stop_words=["```\n", "```python"]) # override llm stop words
while message.formatted["tool_type"]:
message = self.executor(message, session_id=session_id)
message = self.researcher(message, session_id=session_id, stop_words=["```\n", "```python"])
if self.finish_pattern in message.content:
return message
message = self.charter(message)
while message.formatted["tool_type"]:
message = self.executor(message, session_id=session_id)
message = self.charter(message, session_id=session_id)
if self.finish_pattern in message.content:
return message
return message
visualizer = DataVisualizer(
"gpt-4o-2024-05-13",
research_prompt="You should provide accurate data for the chart generator to use.",
chart_prompt="Any charts you display will be visible by the user.",
)
user_msg = AgentMessage(
sender='user',
content="Fetch the China's GDP over the past 5 years, then draw a line graph of it. Once you code it up, finish.")
bot_msg = visualizer(user_msg)
print(bot_msg.content)
json.dump(visualizer.state_dict(), open('visualizer.json', 'w'), ensure_ascii=False, indent=4)If you find this project useful in your research, please consider cite:
@misc{lagent2023,
title={{Lagent: InternLM} a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents},
author={Lagent Developer Team},
howpublished = {\url{https://github.com/InternLM/lagent}},
year={2023}
}This project is released under the Apache 2.0 license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for lagent
Similar Open Source Tools
lagent
Lagent is a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents. It also provides some typical tools to augment LLM. The overview of our framework is shown below:

acte
Acte is a framework designed to build GUI-like tools for AI Agents. It aims to address the issues of cognitive load and freedom degrees when interacting with multiple APIs in complex scenarios. By providing a graphical user interface (GUI) for Agents, Acte helps reduce cognitive load and constraints interaction, similar to how humans interact with computers through GUIs. The tool offers APIs for starting new sessions, executing actions, and displaying screens, accessible via HTTP requests or the SessionManager class.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.
aioaws
Aioaws is an asyncio SDK for some AWS services, providing clean, secure, and easily debuggable access to services like S3, SES, and SNS. It is written from scratch without dependencies on boto or boto3, formatted with black, and includes complete type hints. The library supports various functionalities such as listing, deleting, and generating signed URLs for S3 files, sending emails with attachments and multipart content via SES, and receiving notifications about mail delivery from SES. It also offers AWS Signature Version 4 authentication and has minimal dependencies like aiofiles, cryptography, httpx, and pydantic.
dingllm.nvim
dingllm.nvim is a lightweight configuration for Neovim that provides scripts for invoking various AI models for text generation. It offers functionalities to interact with APIs from OpenAI, Groq, and Anthropic for generating text completions. The configuration is designed to be simple and easy to understand, allowing users to quickly set up and use the provided AI models for text generation tasks.
llm.nvim
llm.nvim is a neovim plugin designed for LLM-assisted programming. It provides a no-frills approach to integrating language model assistance into the coding workflow. Users can configure the plugin to interact with various AI services such as GROQ, OpenAI, and Anthropics. The plugin offers functions to trigger the LLM assistant, create new prompt files, and customize key bindings for seamless interaction. With a focus on simplicity and efficiency, llm.nvim aims to enhance the coding experience by leveraging AI capabilities within the neovim environment.

ai00_server
AI00 RWKV Server is an inference API server for the RWKV language model based upon the web-rwkv inference engine. It supports VULKAN parallel and concurrent batched inference and can run on all GPUs that support VULKAN. No need for Nvidia cards!!! AMD cards and even integrated graphics can be accelerated!!! No need for bulky pytorch, CUDA and other runtime environments, it's compact and ready to use out of the box! Compatible with OpenAI's ChatGPT API interface. 100% open source and commercially usable, under the MIT license. If you are looking for a fast, efficient, and easy-to-use LLM API server, then AI00 RWKV Server is your best choice. It can be used for various tasks, including chatbots, text generation, translation, and Q&A.
orch
orch is a library for building language model powered applications and agents for the Rust programming language. It can be used for tasks such as text generation, streaming text generation, structured data generation, and embedding generation. The library provides functionalities for executing various language model tasks and can be integrated into different applications and contexts. It offers flexibility for developers to create language model-powered features and applications in Rust.
aiotdlib
aiotdlib is a Python asyncio Telegram client based on TDLib. It provides automatic generation of types and functions from tl schema, validation, good IDE type hinting, and high-level API methods for simpler work with tdlib. The package includes prebuilt TDLib binaries for macOS (arm64) and Debian Bullseye (amd64). Users can use their own binary by passing `library_path` argument to `Client` class constructor. Compatibility with other versions of the library is not guaranteed. The tool requires Python 3.9+ and users need to get their `api_id` and `api_hash` from Telegram docs for installation and usage.
openai-scala-client
This is a no-nonsense async Scala client for OpenAI API supporting all the available endpoints and params including streaming, chat completion, vision, and voice routines. It provides a single service called OpenAIService that supports various calls such as Models, Completions, Chat Completions, Edits, Images, Embeddings, Batches, Audio, Files, Fine-tunes, Moderations, Assistants, Threads, Thread Messages, Runs, Run Steps, Vector Stores, Vector Store Files, and Vector Store File Batches. The library aims to be self-contained with minimal dependencies and supports API-compatible providers like Azure OpenAI, Azure AI, Anthropic, Google Vertex AI, Groq, Grok, Fireworks AI, OctoAI, TogetherAI, Cerebras, Mistral, Deepseek, Ollama, FastChat, and more.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.
langchain-rust
LangChain Rust is a library for building applications with Large Language Models (LLMs) through composability. It provides a set of tools and components that can be used to create conversational agents, document loaders, and other applications that leverage LLMs. LangChain Rust supports a variety of LLMs, including OpenAI, Azure OpenAI, Ollama, and Anthropic Claude. It also supports a variety of embeddings, vector stores, and document loaders. LangChain Rust is designed to be easy to use and extensible, making it a great choice for developers who want to build applications with LLMs.
ai
The Vercel AI SDK is a library for building AI-powered streaming text and chat UIs. It provides React, Svelte, Vue, and Solid helpers for streaming text responses and building chat and completion UIs. The SDK also includes a React Server Components API for streaming Generative UI and first-class support for various AI providers such as OpenAI, Anthropic, Mistral, Perplexity, AWS Bedrock, Azure, Google Gemini, Hugging Face, Fireworks, Cohere, LangChain, Replicate, Ollama, and more. Additionally, it offers Node.js, Serverless, and Edge Runtime support, as well as lifecycle callbacks for saving completed streaming responses to a database in the same request.
openapi
The `@samchon/openapi` repository is a collection of OpenAPI types and converters for various versions of OpenAPI specifications. It includes an 'emended' OpenAPI v3.1 specification that enhances clarity by removing ambiguous and duplicated expressions. The repository also provides an application composer for LLM (Large Language Model) function calling from OpenAPI documents, allowing users to easily perform LLM function calls based on the Swagger document. Conversions to different versions of OpenAPI documents are also supported, all based on the emended OpenAPI v3.1 specification. Users can validate their OpenAPI documents using the `typia` library with `@samchon/openapi` types, ensuring compliance with standard specifications.

mLLMCelltype
mLLMCelltype is a multi-LLM consensus framework for automated cell type annotation in single-cell RNA sequencing (scRNA-seq) data. The tool integrates multiple large language models to improve annotation accuracy through consensus-based predictions. It offers advantages over single-model approaches by combining predictions from models like OpenAI GPT-5.2, Anthropic Claude-4.6/4.5, Google Gemini-3, and others. Researchers can incorporate mLLMCelltype into existing workflows without the need for reference datasets.
For similar tasks

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

lollms
LoLLMs Server is a text generation server based on large language models. It provides a Flask-based API for generating text using various pre-trained language models. This server is designed to be easy to install and use, allowing developers to integrate powerful text generation capabilities into their applications.

LlamaIndexTS
LlamaIndex.TS is a data framework for your LLM application. Use your own data with large language models (LLMs, OpenAI ChatGPT and others) in Typescript and Javascript.

semantic-kernel
Semantic Kernel is an SDK that integrates Large Language Models (LLMs) like OpenAI, Azure OpenAI, and Hugging Face with conventional programming languages like C#, Python, and Java. Semantic Kernel achieves this by allowing you to define plugins that can be chained together in just a few lines of code. What makes Semantic Kernel _special_ , however, is its ability to _automatically_ orchestrate plugins with AI. With Semantic Kernel planners, you can ask an LLM to generate a plan that achieves a user's unique goal. Afterwards, Semantic Kernel will execute the plan for the user.

botpress
Botpress is a platform for building next-generation chatbots and assistants powered by OpenAI. It provides a range of tools and integrations to help developers quickly and easily create and deploy chatbots for various use cases.
BotSharp
BotSharp is an open-source machine learning framework for building AI bot platforms. It provides a comprehensive set of tools and components for developing and deploying intelligent virtual assistants. BotSharp is designed to be modular and extensible, allowing developers to easily integrate it with their existing systems and applications. With BotSharp, you can quickly and easily create AI-powered chatbots, virtual assistants, and other conversational AI applications.

qdrant
Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.