
qdrant
Qdrant - High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI. Also available in the cloud https://cloud.qdrant.io/
Stars: 28706

Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.
README:
![]()
Vector Search Engine for the next generation of AI applications



Qdrant (read: quadrant) is a vector similarity search engine and vector database. It provides a production-ready service with a convenient API to store, search, and manage points—vectors with an additional payload Qdrant is tailored to extended filtering support. It makes it useful for all sorts of neural-network or semantic-based matching, faceted search, and other applications.
Qdrant is written in Rust 🦀, which makes it fast and reliable even under high load. See benchmarks.
With Qdrant, embeddings or neural network encoders can be turned into full-fledged applications for matching, searching, recommending, and much more!
Qdrant is also available as a fully managed Qdrant Cloud ⛅ including a free tier.
Quick Start • Client Libraries • Demo Projects • Integrations • Contact
pip install qdrant-client
The python client offers a convenient way to start with Qdrant locally:
from qdrant_client import QdrantClient
qdrant = QdrantClient(":memory:") # Create in-memory Qdrant instance, for testing, CI/CD
# OR
client = QdrantClient(path="path/to/db") # Persists changes to disk, fast prototypingTo experience the full power of Qdrant locally, run the container with this command:
docker run -p 6333:6333 qdrant/qdrant[!CAUTION] Starts an insecure deployment without authentication open to all network interfaces. Please refer to secure your instance.
Now you can connect to this with any client, including Python:
qdrant = QdrantClient("http://localhost:6333") # Connect to existing Qdrant instanceBefore deploying Qdrant to production, be sure to read our installation and security guides.
Qdrant offers the following client libraries to help you integrate it into your application stack with ease:
- Official:
- Community:
- Quick Start Guide
- End to End Colab Notebook demo with SentenceBERT and Qdrant
- Detailed Documentation are great starting points
- Step-by-Step Tutorial to create your first neural network project with Qdrant
Unlock the power of semantic embeddings with Qdrant, transcending keyword-based search to find meaningful connections in short texts. Deploy a neural search in minutes using a pre-trained neural network, and experience the future of text search. Try it online!
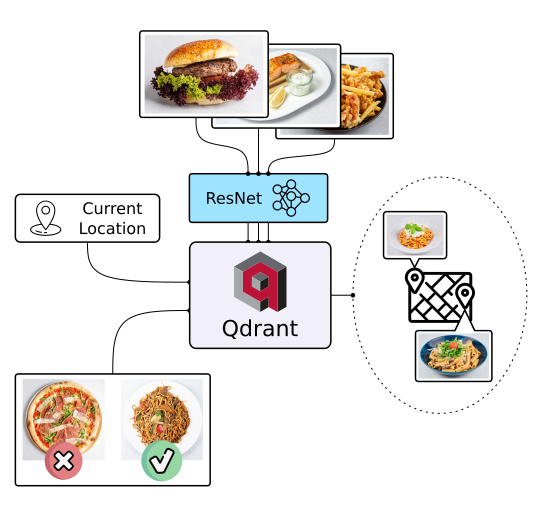
There's more to discovery than text search, especially when it comes to food. People often choose meals based on appearance rather than descriptions and ingredients. Let Qdrant help your users find their next delicious meal using visual search, even if they don't know the dish's name. Check it out!
Enter the cutting-edge realm of extreme classification, an emerging machine learning field tackling multi-class and multi-label problems with millions of labels. Harness the potential of similarity learning models, and see how a pre-trained transformer model and Qdrant can revolutionize e-commerce product categorization. Play with it online!
More solutions
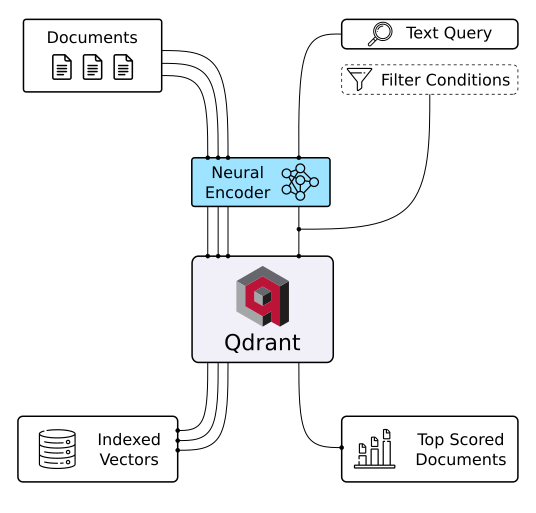
|
|
|
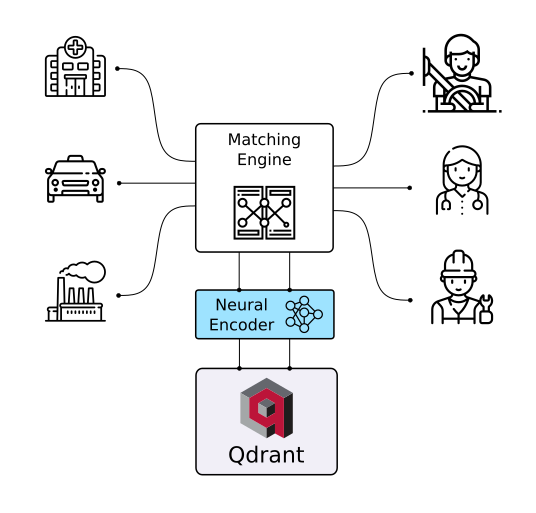
| Semantic Text Search | Similar Image Search | Recommendations |
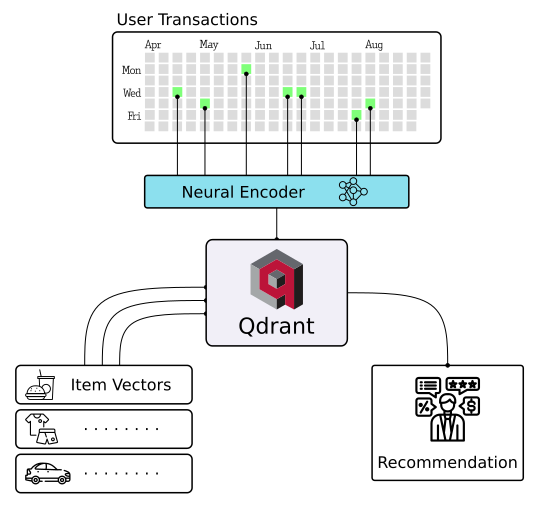
|
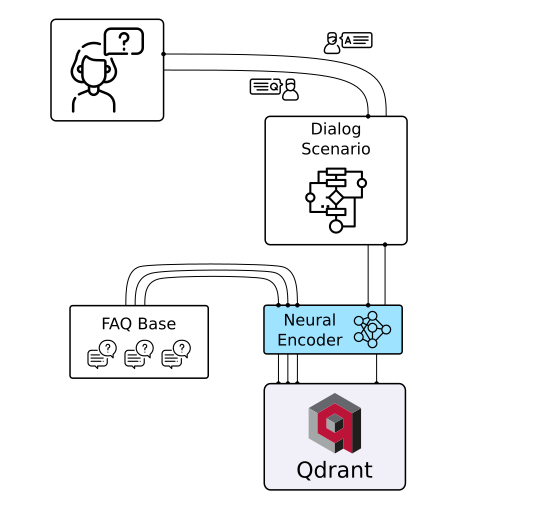
|

|
| Chat Bots | Matching Engines | Anomaly Detection |
Online OpenAPI 3.0 documentation is available here. OpenAPI makes it easy to generate a client for virtually any framework or programming language.
You can also download raw OpenAPI definitions.
For faster production-tier searches, Qdrant also provides a gRPC interface. You can find gRPC documentation here.
Qdrant can attach any JSON payloads to vectors, allowing for both the storage and filtering of data based on the values in these payloads. Payload supports a wide range of data types and query conditions, including keyword matching, full-text filtering, numerical ranges, geo-locations, and more.
Filtering conditions can be combined in various ways, including should, must, and must_not clauses,
ensuring that you can implement any desired business logic on top of similarity matching.
To address the limitations of vector embeddings when searching for specific keywords, Qdrant introduces support for sparse vectors in addition to the regular dense ones.
Sparse vectors can be viewed as an generalization of BM25 or TF-IDF ranking. They enable you to harness the capabilities of transformer-based neural networks to weigh individual tokens effectively.
Qdrant provides multiple options to make vector search cheaper and more resource-efficient. Built-in vector quantization reduces RAM usage by up to 97% and dynamically manages the trade-off between search speed and precision.
Qdrant offers comprehensive horizontal scaling support through two key mechanisms:
- Size expansion via sharding and throughput enhancement via replication
- Zero-downtime rolling updates and seamless dynamic scaling of the collections
- Query Planning and Payload Indexes - leverages stored payload information to optimize query execution strategy.
- SIMD Hardware Acceleration - utilizes modern CPU x86-x64 and Neon architectures to deliver better performance.
-
Async I/O - uses
io_uringto maximize disk throughput utilization even on a network-attached storage. - Write-Ahead Logging - ensures data persistence with update confirmation, even during power outages.
Examples and/or documentation of Qdrant integrations:
- Cohere (blogpost on building a QA app with Cohere and Qdrant) - Use Cohere embeddings with Qdrant
- DocArray - Use Qdrant as a document store in DocArray
- Haystack - Use Qdrant as a document store with Haystack (blogpost).
- LangChain (blogpost) - Use Qdrant as a memory backend for LangChain.
- LlamaIndex - Use Qdrant as a Vector Store with LlamaIndex.
- OpenAI - ChatGPT retrieval plugin - Use Qdrant as a memory backend for ChatGPT
- Microsoft Semantic Kernel - Use Qdrant as persistent memory with Semantic Kernel
- Have questions? Join our Discord channel or mention @qdrant_engine on Twitter
- Want to stay in touch with latest releases? Subscribe to our Newsletters
- Looking for a managed cloud? Check pricing, need something personalised? We're at [email protected]
Qdrant is licensed under the Apache License, Version 2.0. View a copy of the License file.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for qdrant
Similar Open Source Tools
qdrant
Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.

cosdata
Cosdata is a cutting-edge AI data platform designed to power the next generation search pipelines. It features immutability, version control, and excels in semantic search, structured knowledge graphs, hybrid search capabilities, real-time search at scale, and ML pipeline integration. The platform is customizable, scalable, efficient, enterprise-grade, easy to use, and can manage multi-modal data. It offers high performance, indexing, low latency, and high requests per second. Cosdata is designed to meet the demands of modern search applications, empowering businesses to harness the full potential of their data.

reductstore
ReductStore is a high-performance time series database designed for storing and managing large amounts of unstructured blob data. It offers features such as real-time querying, batching data, and HTTP(S) API for edge computing, computer vision, and IoT applications. The database ensures data integrity, implements retention policies, and provides efficient data access, making it a cost-effective solution for applications requiring unstructured data storage and access at specific time intervals.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.
saga-reader
Saga Reader is an AI-driven think tank-style reader that automatically retrieves information from the internet based on user-specified topics and preferences. It uses cloud or local large models to summarize and provide guidance, and it includes an AI-driven interactive companion reading function, allowing you to discuss and exchange ideas with AI about the content you've read. Saga Reader is completely free and open-source, meaning all data is securely stored on your own computer and is not controlled by third-party service providers. Additionally, you can manage your subscription keywords based on your interests and preferences without being disturbed by advertisements and commercialized content.
nexent
Nexent is a powerful tool for analyzing and visualizing network traffic data. It provides comprehensive insights into network behavior, helping users to identify patterns, anomalies, and potential security threats. With its user-friendly interface and advanced features, Nexent is suitable for network administrators, cybersecurity professionals, and anyone looking to gain a deeper understanding of their network infrastructure.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.

crewAI
CrewAI is a cutting-edge framework designed to orchestrate role-playing autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It enables AI agents to assume roles, share goals, and operate in a cohesive unit, much like a well-oiled crew. Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions. With features like role-based agent design, autonomous inter-agent delegation, flexible task management, and support for various LLMs, CrewAI offers a dynamic and adaptable solution for both development and production workflows.

radicalbit-ai-monitoring
The Radicalbit AI Monitoring Platform provides a comprehensive solution for monitoring Machine Learning and Large Language models in production. It helps proactively identify and address potential performance issues by analyzing data quality, model quality, and model drift. The repository contains files and projects for running the platform, including UI, API, SDK, and Spark components. Installation using Docker compose is provided, allowing deployment with a K3s cluster and interaction with a k9s container. The platform documentation includes a step-by-step guide for installation and creating dashboards. Community engagement is encouraged through a Discord server. The roadmap includes adding functionalities for batch and real-time workloads, covering various model types and tasks.
bionic-gpt
BionicGPT is an on-premise replacement for ChatGPT, offering the advantages of Generative AI while maintaining strict data confidentiality. BionicGPT can run on your laptop or scale into the data center.

draive
draive is an open-source Python library designed to simplify and accelerate the development of LLM-based applications. It offers abstract building blocks for connecting functionalities with large language models, flexible integration with various AI solutions, and a user-friendly framework for building scalable data processing pipelines. The library follows a function-oriented design, allowing users to represent complex programs as simple functions. It also provides tools for measuring and debugging functionalities, ensuring type safety and efficient asynchronous operations for modern Python apps.
Conversation-Knowledge-Mining-Solution-Accelerator
The Conversation Knowledge Mining Solution Accelerator enables customers to leverage intelligence to uncover insights, relationships, and patterns from conversational data. It empowers users to gain valuable knowledge and drive targeted business impact by utilizing Azure AI Foundry, Azure OpenAI, Microsoft Fabric, and Azure Search for topic modeling, key phrase extraction, speech-to-text transcription, and interactive chat experiences.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.
For similar tasks

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

lollms
LoLLMs Server is a text generation server based on large language models. It provides a Flask-based API for generating text using various pre-trained language models. This server is designed to be easy to install and use, allowing developers to integrate powerful text generation capabilities into their applications.

LlamaIndexTS
LlamaIndex.TS is a data framework for your LLM application. Use your own data with large language models (LLMs, OpenAI ChatGPT and others) in Typescript and Javascript.

semantic-kernel
Semantic Kernel is an SDK that integrates Large Language Models (LLMs) like OpenAI, Azure OpenAI, and Hugging Face with conventional programming languages like C#, Python, and Java. Semantic Kernel achieves this by allowing you to define plugins that can be chained together in just a few lines of code. What makes Semantic Kernel _special_ , however, is its ability to _automatically_ orchestrate plugins with AI. With Semantic Kernel planners, you can ask an LLM to generate a plan that achieves a user's unique goal. Afterwards, Semantic Kernel will execute the plan for the user.

botpress
Botpress is a platform for building next-generation chatbots and assistants powered by OpenAI. It provides a range of tools and integrations to help developers quickly and easily create and deploy chatbots for various use cases.
BotSharp
BotSharp is an open-source machine learning framework for building AI bot platforms. It provides a comprehensive set of tools and components for developing and deploying intelligent virtual assistants. BotSharp is designed to be modular and extensible, allowing developers to easily integrate it with their existing systems and applications. With BotSharp, you can quickly and easily create AI-powered chatbots, virtual assistants, and other conversational AI applications.
qdrant
Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.