
FunClip
Open-source, accurate and easy-to-use video speech recognition & clipping tool, LLM based AI clipping intergrated.
Stars: 2125
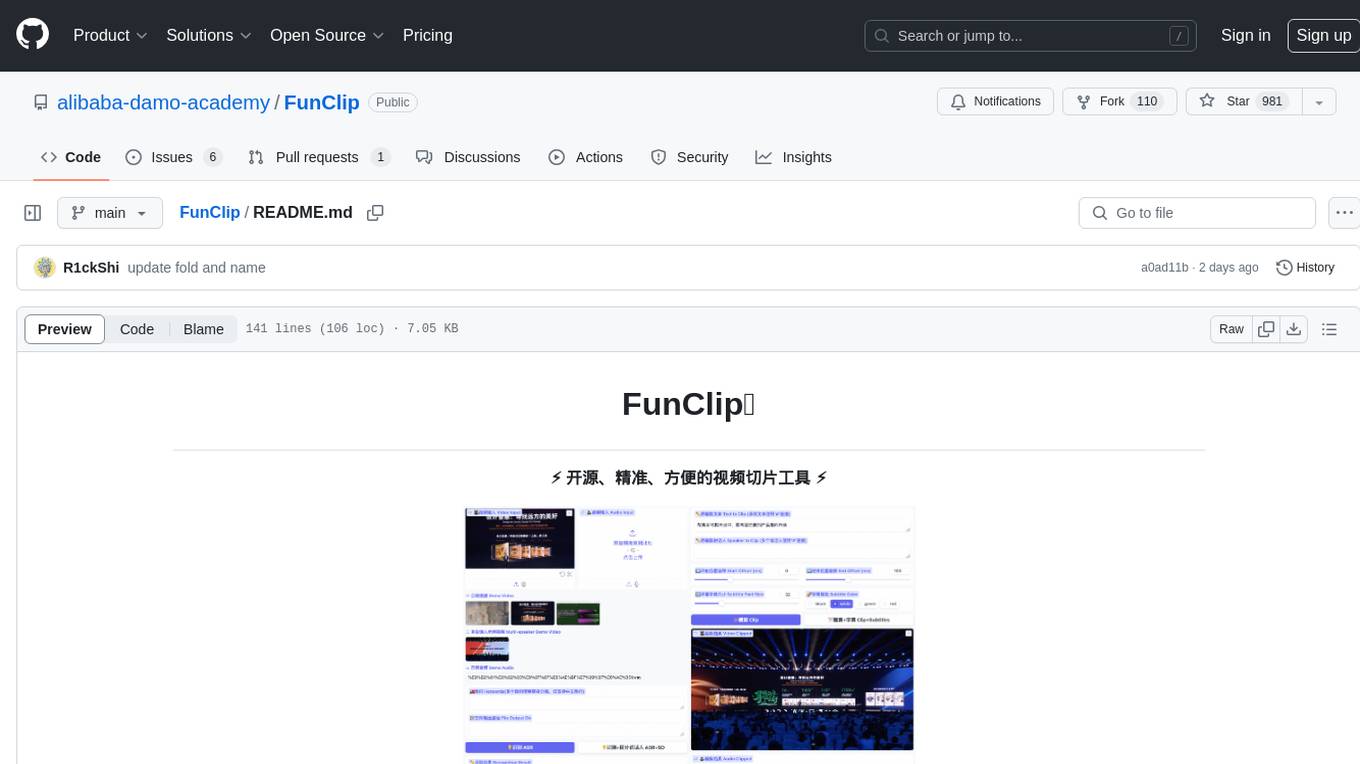
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.
README:
「简体中文 | English」
⚡ Open-source, accurate and easy-to-use video clipping tool
🧠 Explore LLM based video clipping with FunClip

What's New | On Going | Install | Usage | Community
FunClip is a fully open-source, locally deployed automated video clipping tool. It leverages Alibaba TONGYI speech lab's open-source FunASR Paraformer series models to perform speech recognition on videos. Then, users can freely choose text segments or speakers from the recognition results and click the clip button to obtain the video clip corresponding to the selected segments (Quick Experience Modelscope⭐ HuggingFace🤗).
- 🔥Try AI clipping using LLM in FunClip now.
- FunClip integrates Alibaba's open-source industrial-grade model Paraformer-Large, which is one of the best-performing open-source Chinese ASR models available, with over 13 million downloads on Modelscope. It can also accurately predict timestamps in an integrated manner.
- FunClip incorporates the hotword customization feature of SeACo-Paraformer, allowing users to specify certain entity words, names, etc., as hotwords during the ASR process to enhance recognition results.
- FunClip integrates the CAM++ speaker recognition model, enabling users to use the auto-recognized speaker ID as the target for trimming, to clip segments from a specific speaker.
- The functionalities are realized through Gradio interaction, offering simple installation and ease of use. It can also be deployed on a server and accessed via a browser.
- FunClip supports multi-segment free clipping and automatically returns full video SRT subtitles and target segment SRT subtitles, offering a simple and convenient user experience.
- 🔥2024/05/13 FunClip v2.0.0 now supports smart clipping with large language models, integrating models from the qwen series, GPT series, etc., providing default prompts. You can also explore and share tips for setting prompts, the usage is as follows:
- After the recognition, select the name of the large model and configure your own apikey;
- Click on the 'LLM Smart Paragraph Selection' button, and FunClip will automatically combine two prompts with the video's srt subtitles;
- Click on the 'LLM Smart Clipping' button, and based on the output results of the large language model from the previous step, FunClip will extract the timestamps for clipping;
- You can try changing the prompt to leverage the capabilities of the large language models to get the results you want;
- 2024/05/09 FunClip updated to v1.1.0, including the following updates and fixes:
- Support configuration of output file directory, saving ASR intermediate results and video clipping intermediate files;
- UI upgrade (see guide picture below), video and audio cropping function are on the same page now, button position adjustment;
- Fixed a bug introduced due to FunASR interface upgrade, which has caused some serious clipping errors;
- Support configuring different start and end time offsets for each paragraph;
- Code update, etc;
- 2024/03/06 Fix bugs in using FunClip with command line.
- 2024/02/28 FunASR is updated to 1.0 version, use FunASR1.0 and SeACo-Paraformer to conduct ASR with hotword customization.
- 2023/10/17 Fix bugs in multiple periods chosen, used to return video with wrong length.
- 2023/10/10 FunClipper now supports recognizing with speaker diarization ability, choose 'yes' button in 'Recognize Speakers' and you will get recognition results with speaker id for each sentence. And then you can clip out the periods of one or some speakers (e.g. 'spk0' or 'spk0#spk3') using FunClipper.
- [ ] FunClip will support Whisper model for English users, coming soon.
- [x] FunClip will further explore the abilities of large langage model based AI clipping, welcome to discuss about prompt setting and clipping, etc.
- [ ] Reverse periods choosing while clipping.
- [ ] Removing silence periods.
FunClip basic functions rely on a python environment only.
# clone funclip repo
git clone https://github.com/alibaba-damo-academy/FunClip.git
cd FunClip
# install Python requirments
pip install -r ./requirements.txtIf you want to clip video file with embedded subtitles
- ffmpeg and imagemagick is required
- On Ubuntu
apt-get -y update && apt-get -y install ffmpeg imagemagick
sed -i 's/none/read,write/g' /etc/ImageMagick-6/policy.xml- On MacOS
brew install imagemagick
sed -i 's/none/read,write/g' /usr/local/Cellar/imagemagick/7.1.1-8_1/etc/ImageMagick-7/policy.xml - On Windows
Download and install imagemagick https://imagemagick.org/script/download.php#windows
Find your python install path and change the IMAGEMAGICK_BINARY to your imagemagick install path in file site-packages\moviepy\config_defaults.py
- Download font file to funclip/font
wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ClipVideo/STHeitiMedium.ttc -O font/STHeitiMedium.ttcYou can establish your own FunClip service which is same as Modelscope Space as follow:
python funclip/launch.pythen visit localhost:7860 you will get a Gradio service like below and you can use FunClip following the steps:
- Step1: Upload your video file (or try the example videos below)
- Step2: Copy the text segments you need to 'Text to Clip'
- Step3: Adjust subtitle settings (if needed)
- Step4: Click 'Clip' or 'Clip and Generate Subtitles'

Follow the guide below to explore LLM based clipping:

FunClip supports you to recognize and clip with commands:
# step1: Recognize
python funclip/videoclipper.py --stage 1 \
--file examples/2022云栖大会_片段.mp4 \
--output_dir ./output
# now you can find recognition results and entire SRT file in ./output/
# step2: Clip
python funclip/videoclipper.py --stage 2 \
--file examples/2022云栖大会_片段.mp4 \
--output_dir ./output \
--dest_text '我们把它跟乡村振兴去结合起来,利用我们的设计的能力' \
--start_ost 0 \
--end_ost 100 \
--output_file './output/res.mp4'FunClip is firstly open-sourced bu FunASR team, any useful PR is welcomed.
You can also scan the following DingTalk group or WeChat group QR code to join the community group for communication.
| DingTalk group | WeChat group |
|---|---|
 |
 |
FunASR hopes to build a bridge between academic research and industrial applications on speech recognition. By supporting the training & finetuning of the industrial-grade speech recognition model released on ModelScope, researchers and developers can conduct research and production of speech recognition models more conveniently, and promote the development of speech recognition ecology. ASR for Fun!
📚FunASR Paper:
📚SeACo-Paraformer Paper:
🌟Support FunASR:

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FunClip
Similar Open Source Tools
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.

FunClip
FunClip is an open-source, locally deployed automated video clipping tool that leverages Alibaba TONGYI speech lab's FunASR Paraformer series models for speech recognition on videos. Users can select text segments or speakers from recognition results to obtain corresponding video clips. It integrates industrial-grade models for accurate predictions and offers hotword customization and speaker recognition features. The tool is user-friendly with Gradio interaction, supporting multi-segment clipping and providing full video and target segment subtitles. FunClip is suitable for users looking to automate video clipping tasks with advanced AI capabilities.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
LLPlayer
LLPlayer is a specialized media player designed for language learning, offering unique features such as dual subtitles, AI-generated subtitles, real-time OCR, real-time translation, word lookup, and more. It supports multiple languages, online video playback, customizable settings, and integration with browser extensions. Written in C#/WPF, LLPlayer is free, open-source, and aims to enhance the language learning experience through innovative functionalities.
open-source-slack-ai
This repository provides a ready-to-run basic Slack AI solution that allows users to summarize threads and channels using OpenAI. Users can generate thread summaries, channel overviews, channel summaries since a specific time, and full channel summaries. The tool is powered by GPT-3.5-Turbo and an ensemble of NLP models. It requires Python 3.8 or higher, an OpenAI API key, Slack App with associated API tokens, Poetry package manager, and ngrok for local development. Users can customize channel and thread summaries, run tests with coverage using pytest, and contribute to the project for future enhancements.
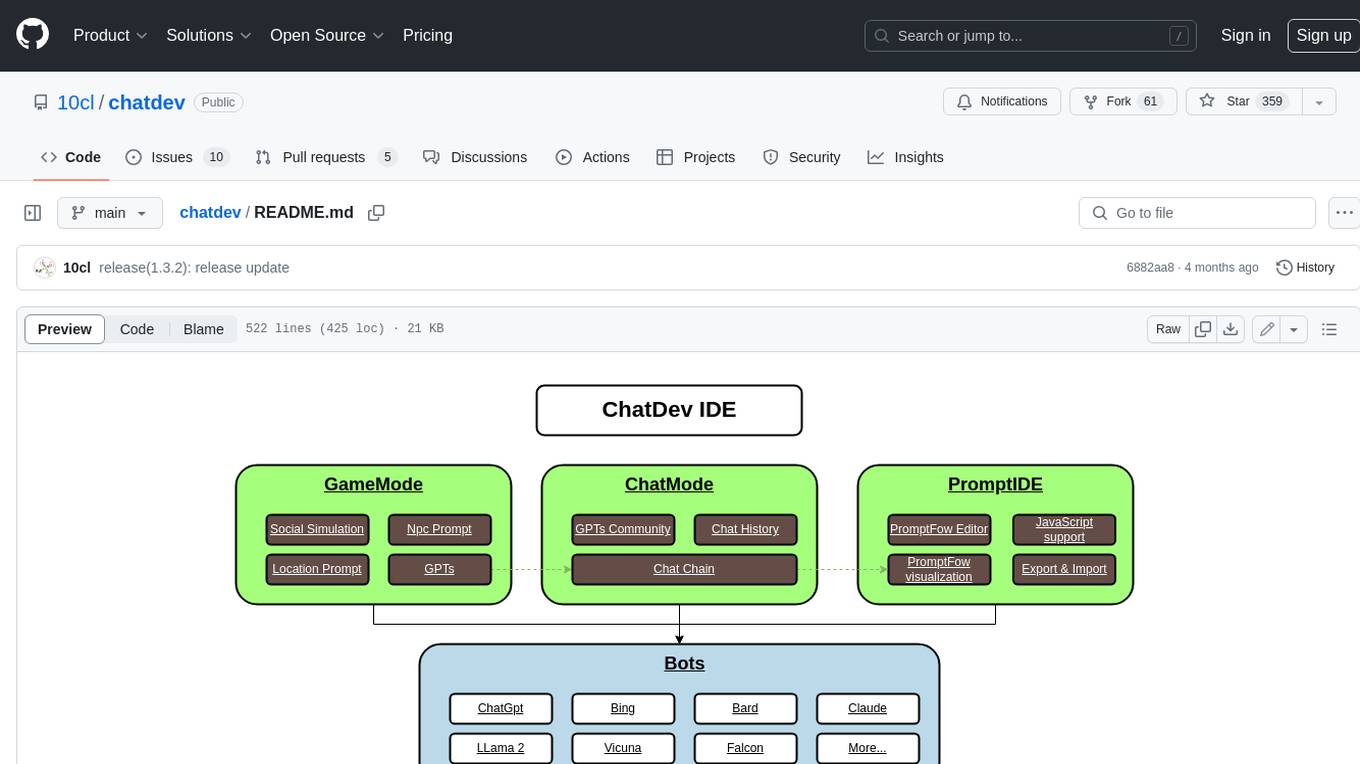
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.
letmedoit
LetMeDoIt AI is a virtual assistant designed to revolutionize the way you work. It goes beyond being a mere chatbot by offering a unique and powerful capability - the ability to execute commands and perform computing tasks on your behalf. With LetMeDoIt AI, you can access OpenAI ChatGPT-4, Google Gemini Pro, and Microsoft AutoGen, local LLMs, all in one place, to enhance your productivity.
vector_companion
Vector Companion is an AI tool designed to act as a virtual companion on your computer. It consists of two personalities, Axiom and Axis, who can engage in conversations based on what is happening on the screen. The tool can transcribe audio output and user microphone input, take screenshots, and read text via OCR to create lifelike interactions. It requires specific prerequisites to run on Windows and uses VB Cable to capture audio. Users can interact with Axiom and Axis by running the main script after installation and configuration.

QodeAssist
QodeAssist is an AI-powered coding assistant plugin for Qt Creator, offering intelligent code completion and suggestions for C++ and QML. It leverages large language models like Ollama to enhance coding productivity with context-aware AI assistance directly in the Qt development environment. The plugin supports multiple LLM providers, extensive model-specific templates, and easy configuration for enhanced coding experience.
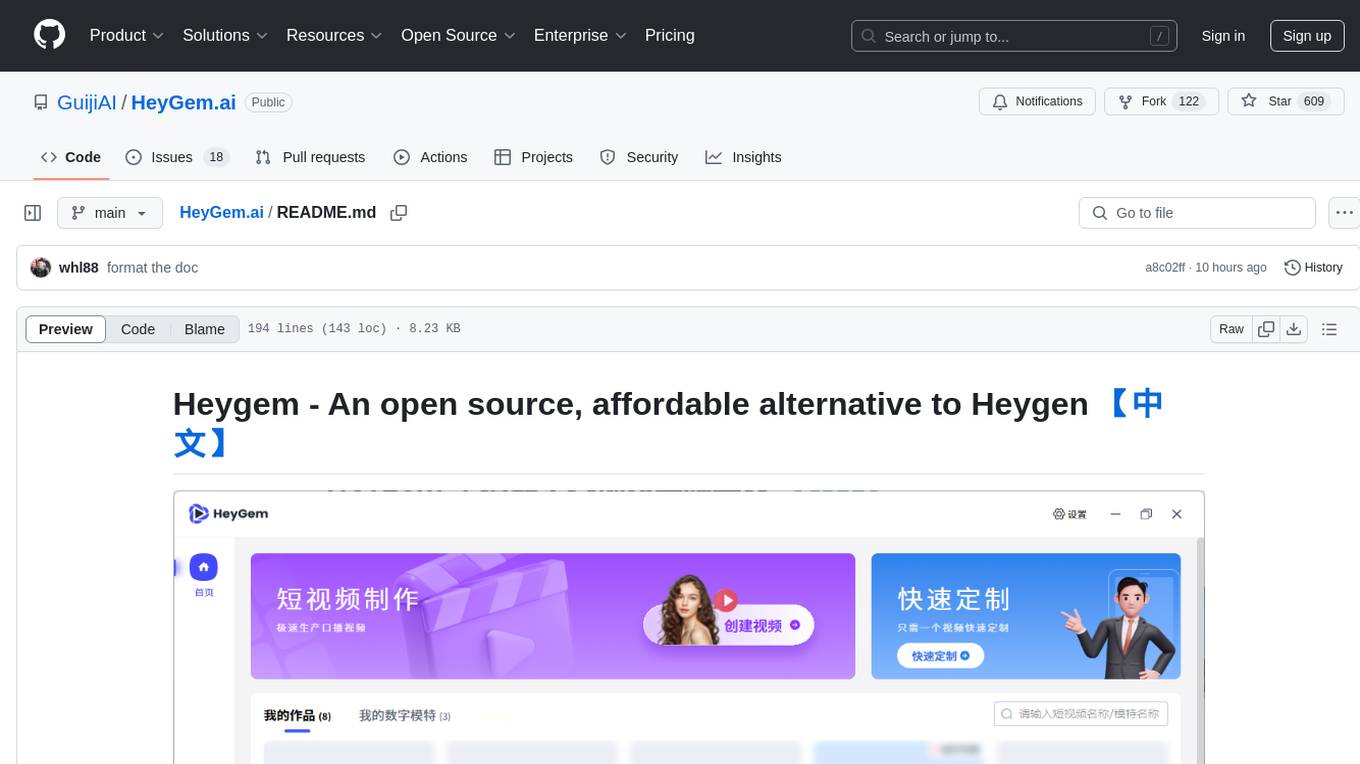
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.

PanelCleaner
Panel Cleaner is a tool that uses machine learning to find text in images and generate masks to cover it up with high accuracy. It is designed to clean text bubbles without leaving artifacts, avoiding painting over non-text parts, and inpainting bubbles that can't be masked out. The tool offers various customization options, detailed analytics on the cleaning process, supports batch processing, and can run OCR on pages. It supports CUDA acceleration, multiple themes, and can handle bubbles on any solid grayscale background color. Panel Cleaner is aimed at saving time for cleaners by automating monotonous work and providing precise cleaning of text bubbles.
Transtation-KMP
Transtation is an easy-to-use and powerful translation software for Android/Desktop based on Kotlin Multiplatform + Compose Multiplatform. It allows users to translate one item using multiple engines simultaneously, utilize advanced Large Language Models for translation, chat with LLMs for translation, translate long text, support plugin development, image translation, and screen translation. The application is designed for Chinese users and serves as a reference for learning Jetpack Compose or Compose Multiplatform. It features Kotlin Multiplatform, Compose Multiplatform, MVVM, Kotlin Coroutine, Flow, SqlDelight, synchronized translation with multiple engines, plugin development, and makes use of Kotlin language features like lazy loading, Coroutine, sealed classes, and reflection. The application gradually adapts to Android13 with features like setting application language separately and supporting Monet icon.
For similar tasks
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.
FunClip
FunClip is an open-source, locally deployed automated video clipping tool that leverages Alibaba TONGYI speech lab's FunASR Paraformer series models for speech recognition on videos. Users can select text segments or speakers from recognition results to obtain corresponding video clips. It integrates industrial-grade models for accurate predictions and offers hotword customization and speaker recognition features. The tool is user-friendly with Gradio interaction, supporting multi-segment clipping and providing full video and target segment subtitles. FunClip is suitable for users looking to automate video clipping tasks with advanced AI capabilities.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
Rewind-AI-Main
Rewind AI is a free and open-source AI-powered video editing tool that allows users to easily create and edit videos. It features a user-friendly interface, a wide range of editing tools, and support for a variety of video formats. Rewind AI is perfect for beginners and experienced video editors alike.
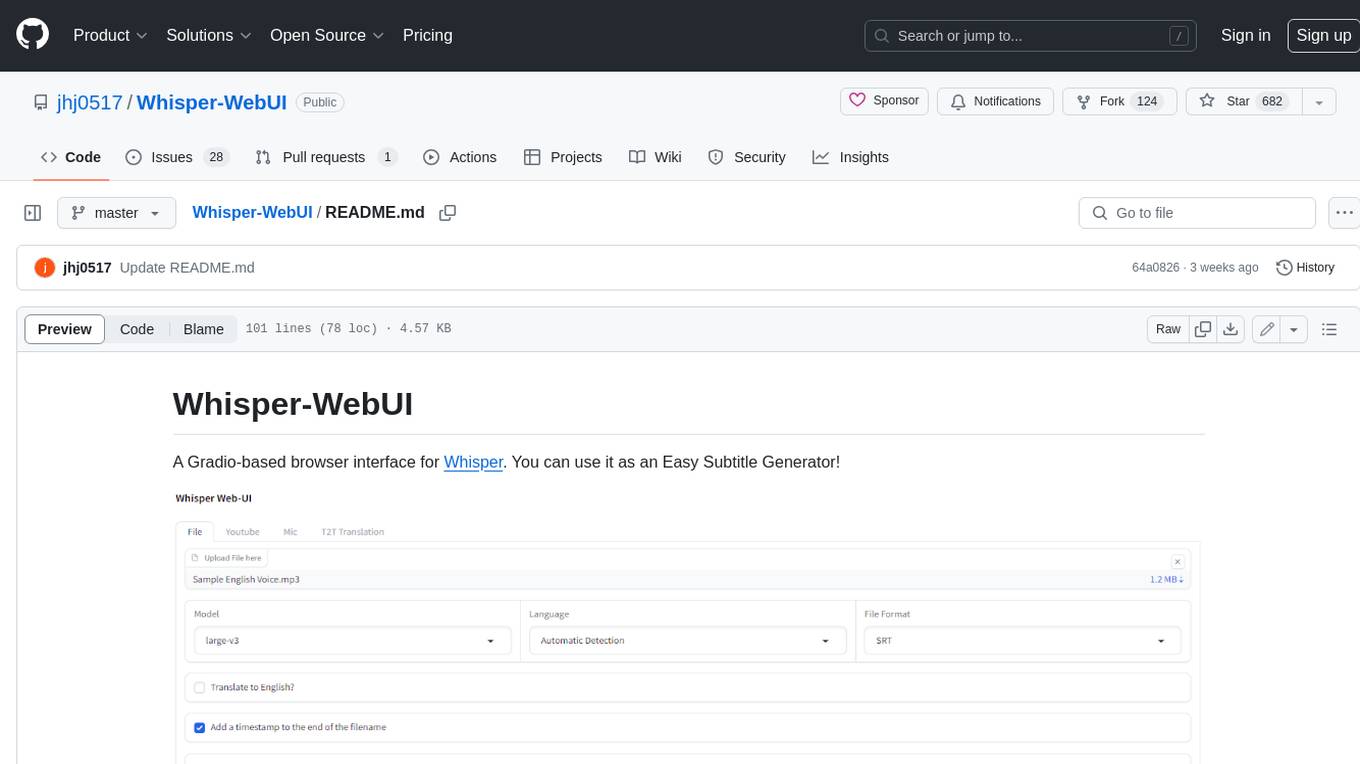
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.

CushyStudio
CushyStudio is a generative AI platform designed for creatives of any level to effortlessly create stunning images, videos, and 3D models. It offers CushyApps, a collection of visual tools tailored for different artistic tasks, and CushyKit, an extensive toolkit for custom apps development and task automation. Users can dive into the AI revolution, unleash their creativity, share projects, and connect with a vibrant community. The platform aims to simplify the AI art creation process and provide a user-friendly environment for designing interfaces, adding custom logic, and accessing various tools.
ChopperBot
A multifunctional, intelligent, personalized, scalable, easy to build, and fully automated multi platform intelligent live video editing and publishing robot. ChopperBot is a comprehensive AI tool that automatically analyzes and slices the most interesting clips from popular live streaming platforms, generates and publishes content, and manages accounts. It supports plugin DIY development and hot swapping functionality, making it easy to customize and expand. With ChopperBot, users can quickly build their own live video editing platform without the need to install any software, thanks to its visual management interface.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.