
Open-Sora-Plan
This project aim to reproduce Sora (Open AI T2V model), we wish the open source community contribute to this project.
Stars: 11754

Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
README:
This project aims to create a simple and scalable repo, to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI" ). We wish the open-source community can contribute to this project. Pull requests are welcome! The current code supports complete training and inference using the Huawei Ascend AI computing system. Models trained on Huawei Ascend can also output video quality comparable to industry standards.
本项目希望通过开源社区的力量复现Sora,由北大-兔展AIGC联合实验室共同发起,当前版本离目标差距仍然较大,仍需持续完善和快速迭代,欢迎Pull request!目前代码同时支持使用国产AI计算系统(华为昇腾)进行完整的训练和推理。基于昇腾训练出的模型,也可输出持平业界的视频质量。









-
COMING SOON⚡️⚡️⚡️ For large model parallelisation training, TP & SP and more strategies are coming...近期将新增华为昇腾多模态MindSpeed-MM分支,借助华为MindSpeed-MM套件的能力支撑Open-Sora Plan参数的扩增,为更大参数规模的模型训练提供TP、SP等分布式训练能力。
-
[2024.12.03] ⚡️ We released our arxiv paper and WF-VAE paper for v1.3. The next more powerful version is coming soon.
-
[2024.10.16] 🎉 We released version 1.3.0, featuring: WFVAE, prompt refiner, data filtering strategy, sparse attention, and bucket training strategy. We also support 93x480p within 24G VRAM. More details can be found at our latest report.
-
[2024.08.13] 🎉 We are launching Open-Sora Plan v1.2.0 I2V model, which is based on Open-Sora Plan v1.2.0. The current version supports image-to-video generation and transition generation (the starting and ending frames conditions for video generation). Check out the Image-to-Video section in this report.
-
[2024.07.24] 🔥🔥🔥 v1.2.0 is here! Utilizing a 3D full attention architecture instead of 2+1D. We released a true 3D video diffusion model trained on 4s 720p. Check out our latest report.
-
[2024.05.27] 🎉 We are launching Open-Sora Plan v1.1.0, which significantly improves video quality and length, and is fully open source! Please check out our latest report. Thanks to ShareGPT4Video's capability to annotate long videos.
-
[2024.04.09] 🤝 Excited to share our latest exploration on metamorphic time-lapse video generation: MagicTime, which learns real-world physics knowledge from time-lapse videos.
-
[2024.04.07] 🎉🎉🎉 Today, we are thrilled to present Open-Sora-Plan v1.0.0, which significantly enhances video generation quality and text control capabilities. See our report. Thanks to HUAWEI NPU for supporting us.
-
[2024.03.27] 🚀🚀🚀 We release the report of VideoCausalVAE, which supports both images and videos. We present our reconstructed video in this demonstration as follows. The text-to-video model is on the way.
-
[2024.03.01] 🤗 We launched a plan to reproduce Sora, called Open-Sora Plan! Welcome to watch 👀 this repository for the latest updates.
Text & Image to Video Generation.
Open-Sora Plan shows excellent performance in video generation.
- High compression ratio with excellent performance, capable of compressing videos by 256 times (4×8×8). Causal convolution supports simultaneous inference of images and videos but only need 1 node to train.
- With a new sparse attention architecture instead of a 2+1D model, 3D attention can better capture joint spatial and temporal features.

Highly recommend trying out our web demo by the following command.
python -m opensora.serve.gradio_web_server --model_path "path/to/model" \
--ae WFVAEModel_D8_4x8x8 --ae_path "path/to/vae" \
--caption_refiner "path/to/refiner" \
--text_encoder_name_1 "path/to/text_enc" --rescale_betas_zero_snrComing soon...
| Version | Architecture | Diffusion Model | CausalVideoVAE | Data | Prompt Refiner |
|---|---|---|---|---|---|
| v1.3.0 [4] | Skiparse 3D | Anysize in 93x640x640[3], Anysize in 93x640x640_i2v[3] | Anysize | prompt_refiner | checkpoint |
| v1.2.0 | Dense 3D | 93x720p, 29x720p[1], 93x480p[1,2], 29x480p, 1x480p, 93x480p_i2v | Anysize | Annotations | - |
| v1.1.0 | 2+1D | 221x512x512, 65x512x512 | Anysize | Data and Annotations | - |
| v1.0.0 | 2+1D | 65x512x512, 65x256x256, 17x256x256 | Anysize | Data and Annotations | - |
[1] Please note that the weights for v1.2.0 29×720p and 93×480p were trained on Panda70M and have not undergone final high-quality data fine-tuning, so they may produce watermarks.
[2] We fine-tuned 3.5k steps from 93×720p to get 93×480p for community research use.
[3] The model is trained arbitrarily on stride=32. So keep the resolution of the inference a multiple of 32. Frames need to be 4n+1, e.g. 93, 77, 61, 45, 29, 1 (image).
[4] Model weights are also available at OpenMind and WiseModel.
[!Warning]
🚨 For version 1.2.0, we no longer support 2+1D models.
- Clone this repository and navigate to Open-Sora-Plan folder
git clone https://github.com/PKU-YuanGroup/Open-Sora-Plan
cd Open-Sora-Plan
- Install required packages We recommend the requirements as follows.
- Python >= 3.8
- Pytorch >= 2.1.0
conda create -n opensora python=3.8 -y
conda activate opensora
pip install -e .
pip install torch_npu==2.1.0.post6
# ref https://github.com/dmlc/decord
git clone --recursive https://github.com/dmlc/decord
mkdir build && cd build
cmake .. -DUSE_CUDA=0 -DCMAKE_BUILD_TYPE=Release -DFFMPEG_DIR=/usr/local/ffmpeg
make
cd ../python
pwd=$PWD
echo "PYTHONPATH=$PYTHONPATH:$pwd" >> ~/.bashrc
source ~/.bashrc
python3 setup.py install --user
- Install optional requirements such as static type checking:
pip install -e '.[dev]'
The data preparation, training, inferencing and evaluation can be found here
The data preparation, training, inferencing can be found here
The data preparation, training and inferencing can be found here
The data preparation, training and inferencing can be found here
During training, the entire EMA model remains in VRAM. You can enable --offload_ema or disable --use_ema. Additionally, VAE tiling is disabled by default, but you can pass --enable_tiling or disable --vae_fp32. Finally, a temporary but extreme saving memory option is enable --extra_save_mem to offload the text encoder and VAE to the CPU when not in use, though this will significantly slow down performance.
We currently have two plans: one is to continue using the Deepspeed/FSDP approach, sharding the EMA and text encoder across ranks with Zero3, which is sufficient for training 10-15B models. The other is to adopt MindSpeed for various parallel strategies, enabling us to scale the model up to 30B.
Please first ensure that you understand how to inference. Refer to the inference instructions in Text-to-Video.
Simply specify --save_memory, and during inference, enable_model_cpu_offload(), enable_sequential_cpu_offload(), and vae.vae.enable_tiling() will be automatically activated.
We greatly appreciate your contributions to the Open-Sora Plan open-source community and helping us make it even better than it is now!
For more details, please refer to the Contribution Guidelines
- Allegro: Allegro is a powerful text-to-video model that generates high-quality videos up to 6 seconds at 15 FPS and 720p resolution from simple text input based on our Open-Sora Plan. The significance of open-source is becoming increasingly tangible.
- Latte: It is a wonderful 2+1D video generation model.
- PixArt-alpha: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis.
- ShareGPT4Video: Improving Video Understanding and Generation with Better Captions.
- VideoGPT: Video Generation using VQ-VAE and Transformers.
- DiT: Scalable Diffusion Models with Transformers.
- FiT: Flexible Vision Transformer for Diffusion Model.
- Positional Interpolation: Extending Context Window of Large Language Models via Positional Interpolation.
- See LICENSE for details.
@article{lin2024open,
title={Open-Sora Plan: Open-Source Large Video Generation Model},
author={Lin, Bin and Ge, Yunyang and Cheng, Xinhua and Li, Zongjian and Zhu, Bin and Wang, Shaodong and He, Xianyi and Ye, Yang and Yuan, Shenghai and Chen, Liuhan and others},
journal={arXiv preprint arXiv:2412.00131},
year={2024}
}@article{li2024wf,
title={WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model},
author={Li, Zongjian and Lin, Bin and Ye, Yang and Chen, Liuhan and Cheng, Xinhua and Yuan, Shenghai and Yuan, Li},
journal={arXiv preprint arXiv:2411.17459},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Open-Sora-Plan
Similar Open Source Tools
Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.

nacos
Nacos is an easy-to-use platform designed for dynamic service discovery and configuration and service management. It helps build cloud native applications and microservices platform easily. Nacos provides functions like service discovery, health check, dynamic configuration management, dynamic DNS service, and service metadata management.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.
Imagine_AI
IMAGINE - AI is a groundbreaking image generator tool that leverages the power of OpenAI's DALL-E 2 API library to create extraordinary visuals. Developed using Node.js and Express, this tool offers a transformative way to unleash artistic creativity and imagination by generating unique and captivating images through simple prompts or keywords.
big-AGI
big-AGI is an AI suite designed for professionals seeking function, form, simplicity, and speed. It offers best-in-class Chats, Beams, and Calls with AI personas, visualizations, coding, drawing, side-by-side chatting, and more, all wrapped in a polished UX. The tool is powered by the latest models from 12 vendors and open-source servers, providing users with advanced AI capabilities and a seamless user experience. With continuous updates and enhancements, big-AGI aims to stay ahead of the curve in the AI landscape, catering to the needs of both developers and AI enthusiasts.
RAG-Driven-Generative-AI
RAG-Driven Generative AI provides a roadmap for building effective LLM, computer vision, and generative AI systems that balance performance and costs. This book offers a detailed exploration of RAG and how to design, manage, and control multimodal AI pipelines. By connecting outputs to traceable source documents, RAG improves output accuracy and contextual relevance, offering a dynamic approach to managing large volumes of information. This AI book also shows you how to build a RAG framework, providing practical knowledge on vector stores, chunking, indexing, and ranking. You'll discover techniques to optimize your project's performance and better understand your data, including using adaptive RAG and human feedback to refine retrieval accuracy, balancing RAG with fine-tuning, implementing dynamic RAG to enhance real-time decision-making, and visualizing complex data with knowledge graphs. You'll be exposed to a hands-on blend of frameworks like LlamaIndex and Deep Lake, vector databases such as Pinecone and Chroma, and models from Hugging Face and OpenAI. By the end of this book, you will have acquired the skills to implement intelligent solutions, keeping you competitive in fields ranging from production to customer service across any project.
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.

Scrapegraph-ai
ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.

screenpipe
24/7 Screen & Audio Capture Library to build personalized AI powered by what you've seen, said, or heard. Works with Ollama. Alternative to Rewind.ai. Open. Secure. You own your data. Rust. We are shipping daily, make suggestions, post bugs, give feedback. Building a reliable stream of audio and screenshot data, simplifying life for developers by solving non-trivial problems. Multiple installation options available. Experimental tool with various integrations and features for screen and audio capture, OCR, STT, and more. Open source project focused on enabling tooling & infrastructure for a wide range of applications.
ten-framework
TEN is an open-source ecosystem for creating, customizing, and deploying real-time conversational AI agents with multimodal capabilities including voice, vision, and avatar interactions. It includes various components like TEN Framework, TEN Turn Detection, TEN VAD, TEN Agent, TMAN Designer, and TEN Portal. Users can follow the provided guidelines to set up and customize their agents using TMAN Designer, run them locally or in Codespace, and deploy them with Docker or other cloud services. The ecosystem also offers community channels for developers to connect, contribute, and get support.
TEN-Agent
TEN Agent is an open-source multimodal agent powered by the world’s first real-time multimodal framework, TEN Framework. It offers high-performance real-time multimodal interactions, multi-language and multi-platform support, edge-cloud integration, flexibility beyond model limitations, and real-time agent state management. Users can easily build complex AI applications through drag-and-drop programming, integrating audio-visual tools, databases, RAG, and more.

autogen
AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
ai-toolkit
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.
For similar tasks

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.
Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
comflowyspace
Comflowyspace is an open-source AI image and video generation tool that aims to provide a more user-friendly and accessible experience than existing tools like SDWebUI and ComfyUI. It simplifies the installation, usage, and workflow management of AI image and video generation, making it easier for users to create and explore AI-generated content. Comflowyspace offers features such as one-click installation, workflow management, multi-tab functionality, workflow templates, and an improved user interface. It also provides tutorials and documentation to lower the learning curve for users. The tool is designed to make AI image and video generation more accessible and enjoyable for a wider range of users.
Rewind-AI-Main
Rewind AI is a free and open-source AI-powered video editing tool that allows users to easily create and edit videos. It features a user-friendly interface, a wide range of editing tools, and support for a variety of video formats. Rewind AI is perfect for beginners and experienced video editors alike.
MoneyPrinterTurbo
MoneyPrinterTurbo is a tool that can automatically generate video content based on a provided theme or keyword. It can create video scripts, materials, subtitles, and background music, and then compile them into a high-definition short video. The tool features a web interface and an API interface, supporting AI-generated video scripts, customizable scripts, multiple HD video sizes, batch video generation, customizable video segment duration, multilingual video scripts, multiple voice synthesis options, subtitle generation with font customization, background music selection, access to high-definition and copyright-free video materials, and integration with various AI models like OpenAI, moonshot, Azure, and more. The tool aims to simplify the video creation process and offers future plans to enhance voice synthesis, add video transition effects, provide more video material sources, offer video length options, include free network proxies, enable real-time voice and music previews, support additional voice synthesis services, and facilitate automatic uploads to YouTube platform.
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.
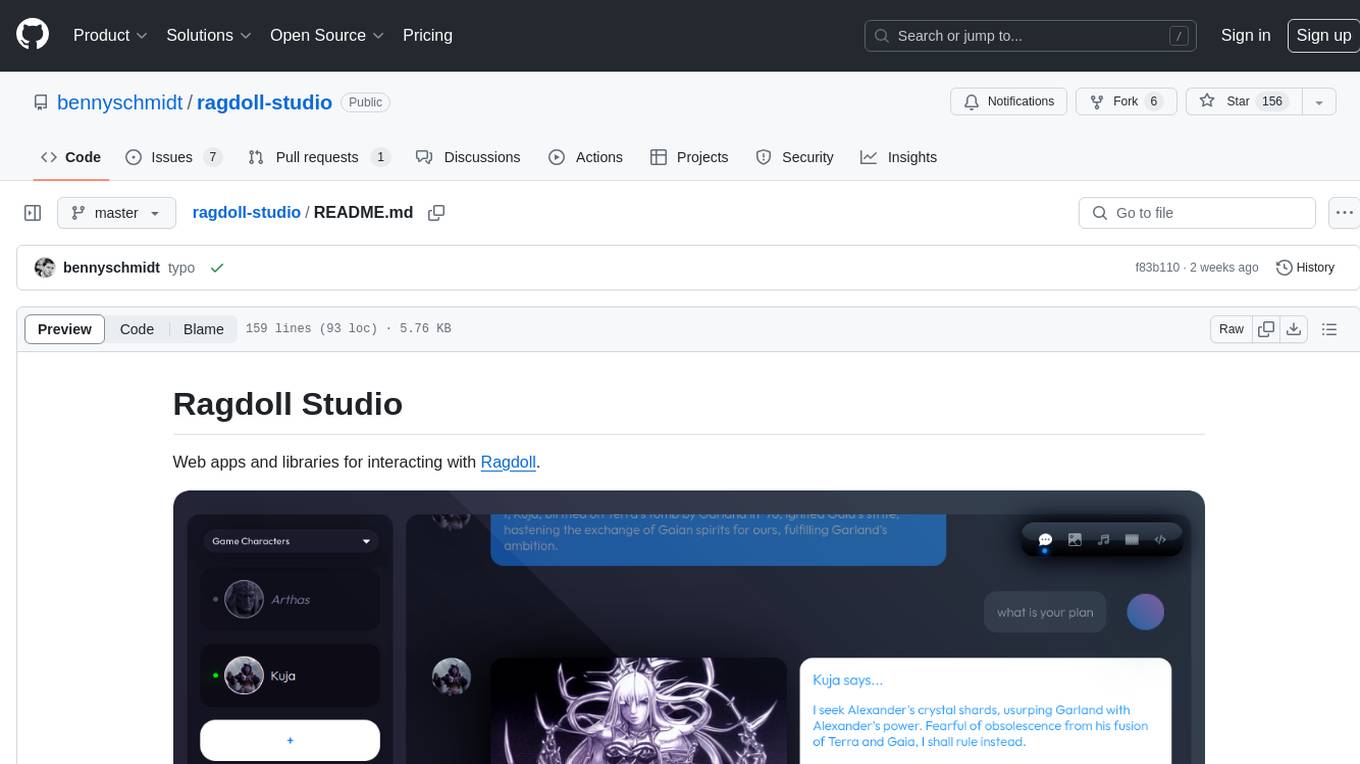
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.
For similar jobs
Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.