
ST-LLM
[ECCV 2024🔥] Official implementation of the paper "ST-LLM: Large Language Models Are Effective Temporal Learners"
Stars: 99
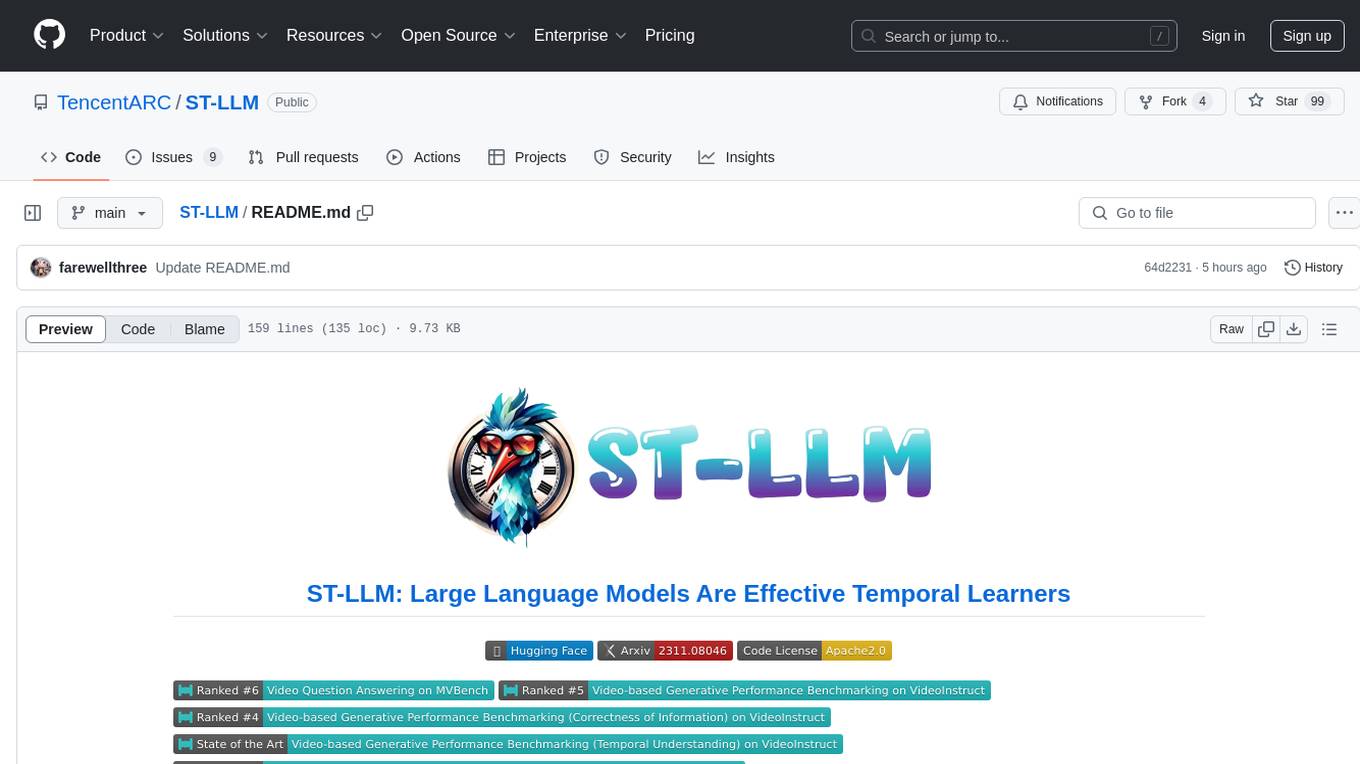
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.
README:
![]()
- [2024/3/28] All codes and weights are available now! Welcome to watch this repository for the latest updates.
-
ST-LLM is a temporal-sensitive video large language model. Our model incorporates three key architectural:
- (1) Joint spatial-temporal modeling within large language models for effective video understanding.
- (2) Dynamic masking strategy and mask video modeling for efficiency and robustness.
- (3) Global-local input module for long video understanding.
- ST-LLM has established new state-of-the-art results on MVBench, VideoChatGPT Bench and VideoQA Bench:
| Method | MVBench | VcgBench | VideoQABench | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Avg | Correct | Detail | Context | Temporal | Consist | MSVD | MSRVTT | ANet | ||
| VideoLLaMA | 34.1 | 1.96 | 2.18 | 2.16 | 1.82 | 1.79 | 1.98 | 51.6 | 29.6 | 12.4 |
| LLaMA-Adapter | 31.7 | 2.03 | 2.32 | 2.30 | 1.98 | 2.15 | 2.16 | 54.9 | 43.8 | 34.2 |
| VideoChat | 35.5 | 2.23 | 2.50 | 2.53 | 1.94 | 2.24 | 2.29 | 56.3 | 45.0 | 26.5 |
| VideoChatGPT | 32.7 | 2.38 | 2.40 | 2.52 | 2.62 | 1.98 | 2.37 | 64.9 | 49.3 | 35.7 |
| MovieChat | - | 2.76 | 2.93 | 3.01 | 2.24 | 2.42 | 2.67 | 74.2 | 52.7 | 45.7 |
| Vista-LLaMA | - | 2.44 | 2.64 | 3.18 | 2.26 | 2.31 | 2.57 | 65.3 | 60.5 | 48.3 |
| LLaMA-VID | - | 2.89 | 2.96 | 3.00 | 3.53 | 2.46 | 2.51 | 69.7 | 57.7 | 47.4 |
| Chat-UniVi | - | 2.99 | 2.89 | 2.91 | 3.46 | 2.89 | 2.81 | 65.0 | 54.6 | 45.8 |
| VideoChat2 | 51.1 | 2.98 | 3.02 | 2.88 | 3.51 | 2.66 | 2.81 | 70.0 | 54.1 | 49.1 |
| ST-LLM | 54.9 | 3.15 | 3.23 | 3.05 | 3.74 | 2.93 | 2.81 | 74.6 | 63.2 | 50.9 |
Please download the conversation weights from here and follow the instructions in installation first. Then, run the gradio demo:
CUDA_VISIBLE_DEVICES=0 python3 demo_gradio.py --ckpt-path /path/to/STLLM_conversation_weight
We have also prepared local scripts that are easy to modify:demo.py


- Video Description: for high-difficulty videos with complex scene changes, ST-LLM can accurately describe all the contents.


- Action Identification: ST-LLM can accurately and comprehensively describe the actions occurring in the video.






-
Reasoning: for the challenging open-ended reasoning questions, STLLM can also provide reasonable answers.


Git clone our repository, creating a Python environment and activate it via the following command
git clone https://github.com/farewellthree/ST-LLM.git
cd ST-LLM
conda create --name stllm python=3.10
conda activate stllm
pip install -r requirement.txtThe instructions of data, training and evaluating can be found in trainval.md.
- Video-ChatGPT and MVBench Great job contributing video LLM benchmark.
- InstuctBLIP and MiniGPT4 The codebase and the basic image LLM we built upon.
If you find the code and paper useful for your research, please consider staring this repo and citing our paper:
@article{liu2023one,
title={One for all: Video conversation is feasible without video instruction tuning},
author={Liu, Ruyang and Li, Chen and Ge, Yixiao and Shan, Ying and Li, Thomas H and Li, Ge},
journal={arXiv preprint arXiv:2309.15785},
year={2023}
}
@article{liu2023one,
title={ST-LLM: Large Language Models Are Effective Temporal Learners},
author={Liu, Ruyang and Li, Chen and Tang, Haoran and Ge, Yixiao and Shan, Ying and Li, Ge},
journal={https://arxiv.org/abs/2404.00308},
year={2023}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ST-LLM
Similar Open Source Tools
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.

VideoRefer
VideoRefer Suite is a tool designed to enhance the fine-grained spatial-temporal understanding capabilities of Video Large Language Models (Video LLMs). It consists of three primary components: Model (VideoRefer) for perceiving, reasoning, and retrieval for user-defined regions at any specified timestamps, Dataset (VideoRefer-700K) for high-quality object-level video instruction data, and Benchmark (VideoRefer-Bench) to evaluate object-level video understanding capabilities. The tool can understand any object within a video.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.

lmdeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features: * **Efficient Inference** : LMDeploy delivers up to 1.8x higher request throughput than vLLM, by introducing key features like persistent batch(a.k.a. continuous batching), blocked KV cache, dynamic split&fuse, tensor parallelism, high-performance CUDA kernels and so on. * **Effective Quantization** : LMDeploy supports weight-only and k/v quantization, and the 4-bit inference performance is 2.4x higher than FP16. The quantization quality has been confirmed via OpenCompass evaluation. * **Effortless Distribution Server** : Leveraging the request distribution service, LMDeploy facilitates an easy and efficient deployment of multi-model services across multiple machines and cards. * **Interactive Inference Mode** : By caching the k/v of attention during multi-round dialogue processes, the engine remembers dialogue history, thus avoiding repetitive processing of historical sessions.
sglang
SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with LLMs faster and more controllable by co-designing the frontend language and the runtime system. The core features of SGLang include: - **A Flexible Front-End Language**: This allows for easy programming of LLM applications with multiple chained generation calls, advanced prompting techniques, control flow, multiple modalities, parallelism, and external interaction. - **A High-Performance Runtime with RadixAttention**: This feature significantly accelerates the execution of complex LLM programs by automatic KV cache reuse across multiple calls. It also supports other common techniques like continuous batching and tensor parallelism.
Tutorial-of-AI-Kit-with-Raspberry-Pi-From-Zero-to-Hero
This course is designed to teach you how to harness the power of AI on the Raspberry Pi, with a focus on using an AI kit for computer vision tasks. Learn to integrate AI into IoT applications, from object detection to visual recognition. Suitable for hobbyists, students, and professionals to bring AI-driven solutions to life on resource-constrained devices like the Raspberry Pi.
big-AGI
big-AGI is an AI suite designed for professionals seeking function, form, simplicity, and speed. It offers best-in-class Chats, Beams, and Calls with AI personas, visualizations, coding, drawing, side-by-side chatting, and more, all wrapped in a polished UX. The tool is powered by the latest models from 12 vendors and open-source servers, providing users with advanced AI capabilities and a seamless user experience. With continuous updates and enhancements, big-AGI aims to stay ahead of the curve in the AI landscape, catering to the needs of both developers and AI enthusiasts.

pro-chat
ProChat is a components library focused on quickly building large language model chat interfaces. It empowers developers to create rich, dynamic, and intuitive chat interfaces with features like automatic chat caching, streamlined conversations, message editing tools, auto-rendered Markdown, and programmatic controls. The tool also includes design evolution plans such as customized dialogue rendering, enhanced request parameters, personalized error handling, expanded documentation, and atomic component design.
PPTAgent
PPTAgent is an innovative system that automatically generates presentations from documents. It employs a two-step process for quality assurance and introduces PPTEval for comprehensive evaluation. With dynamic content generation, smart reference learning, and quality assessment, PPTAgent aims to streamline presentation creation. The tool follows an analysis phase to learn from reference presentations and a generation phase to develop structured outlines and cohesive slides. PPTEval evaluates presentations based on content accuracy, visual appeal, and logical coherence.
KB-Builder
KB Builder is an open-source knowledge base generation system based on the LLM large language model. It utilizes the RAG (Retrieval-Augmented Generation) data generation enhancement method to provide users with the ability to enhance knowledge generation and quickly build knowledge bases based on RAG. It aims to be the central hub for knowledge construction in enterprises, offering platform-based intelligent dialogue services and document knowledge base management functionality. Users can upload docx, pdf, txt, and md format documents and generate high-quality knowledge base question-answer pairs by invoking large models through the 'Parse Document' feature.

GraphGen
GraphGen is a framework for synthetic data generation guided by knowledge graphs. It enhances supervised fine-tuning for large language models (LLMs) by generating synthetic data based on a fine-grained knowledge graph. The tool identifies knowledge gaps in LLMs, prioritizes generating QA pairs targeting high-value knowledge, incorporates multi-hop neighborhood sampling, and employs style-controlled generation to diversify QA data. Users can use LLaMA-Factory and xtuner for fine-tuning LLMs after data generation.
Imagine_AI
IMAGINE - AI is a groundbreaking image generator tool that leverages the power of OpenAI's DALL-E 2 API library to create extraordinary visuals. Developed using Node.js and Express, this tool offers a transformative way to unleash artistic creativity and imagination by generating unique and captivating images through simple prompts or keywords.
ten-framework
TEN is an open-source ecosystem for creating, customizing, and deploying real-time conversational AI agents with multimodal capabilities including voice, vision, and avatar interactions. It includes various components like TEN Framework, TEN Turn Detection, TEN VAD, TEN Agent, TMAN Designer, and TEN Portal. Users can follow the provided guidelines to set up and customize their agents using TMAN Designer, run them locally or in Codespace, and deploy them with Docker or other cloud services. The ecosystem also offers community channels for developers to connect, contribute, and get support.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.
note-gen
Note-gen is a simple tool for generating notes automatically based on user input. It uses natural language processing techniques to analyze text and extract key information to create structured notes. The tool is designed to save time and effort for users who need to summarize large amounts of text or generate notes quickly. With note-gen, users can easily create organized and concise notes for study, research, or any other purpose.
Eridanus
Eridanus is a powerful data visualization tool designed to help users create interactive and insightful visualizations from their datasets. With a user-friendly interface and a wide range of customization options, Eridanus makes it easy for users to explore and analyze their data in a meaningful way. Whether you are a data scientist, business analyst, or student, Eridanus provides the tools you need to communicate your findings effectively and make data-driven decisions.
For similar tasks
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.

VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.

zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.