
VILA
VILA is a family of state-of-the-art vision language models (VLMs) for diverse multimodal AI tasks across the edge, data center, and cloud.
Stars: 2965

VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.
README:
arXiv / Demo / Models / Subscribe
VILA is a family of open VLMs designed to optimize both efficiency and accuracy for efficient video understanding and multi-image understanding.
- [2025/1] As of January 6, 2025 VILA is now part of the new Cosmos Nemotron vision language models.
- [2024/12] We release NVILA (a.k.a VILA2.0) that explores the full stack efficiency of multi-modal design, achieving cheaper training, faster deployment and better performance.
- [2024/12] We release LongVILA that supports long video understanding, with long-context VLM with more than 1M context length and multi-modal sequence parallel system.
- [2024/10] VILA-M3, a SOTA medical VLM finetuned on VILA1.5 is released! VILA-M3 significantly outperforms Llava-Med and on par w/ Med-Gemini and is fully opensourced! code model
- [2024/10] We release VILA-U: a Unified foundation model that integrates Video, Image, Language understanding and generation.
- [2024/07] VILA1.5 also ranks 1st place (OSS model) on MLVU test leaderboard.
- [2024/06] VILA1.5 is now the best open sourced VLM on MMMU leaderboard and Video-MME leaderboard!
- [2024/05] We release VILA-1.5, which offers video understanding capability. VILA-1.5 comes with four model sizes: 3B/8B/13B/40B.
Click to show more news
- [2024/05] We release AWQ-quantized 4bit VILA-1.5 models. VILA-1.5 is efficiently deployable on diverse NVIDIA GPUs (A100, 4090, 4070 Laptop, Orin, Orin Nano) by TinyChat and TensorRT-LLM backends.
- [2024/03] VILA has been accepted by CVPR 2024!
- [2024/02] We release AWQ-quantized 4bit VILA models, deployable on Jetson Orin and laptops through TinyChat and TinyChatEngine.
- [2024/02] VILA is released. We propose interleaved image-text pretraining that enables multi-image VLM. VILA comes with impressive in-context learning capabilities. We open source everything: including training code, evaluation code, datasets, model ckpts.
- [2023/12] Paper is on Arxiv!
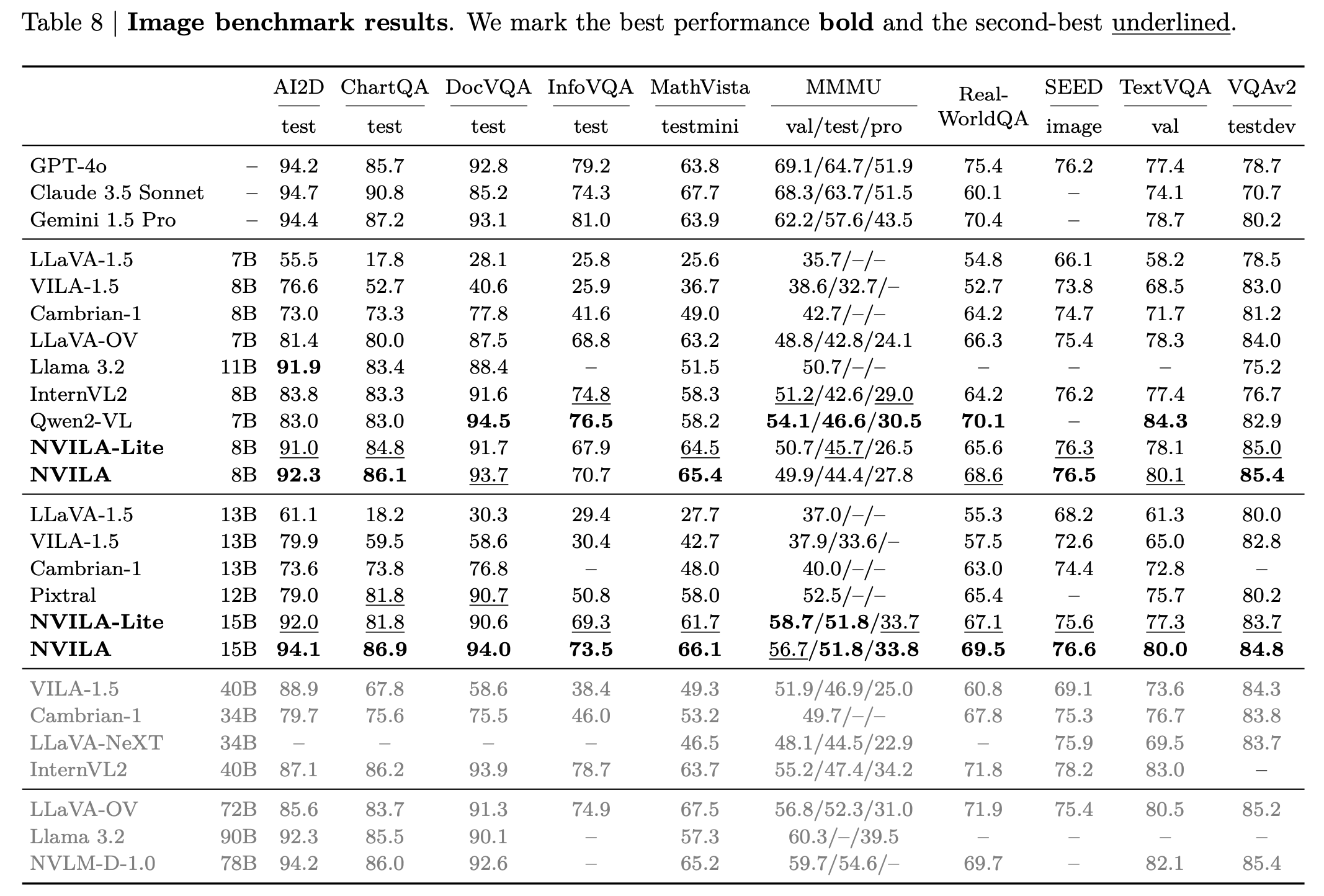
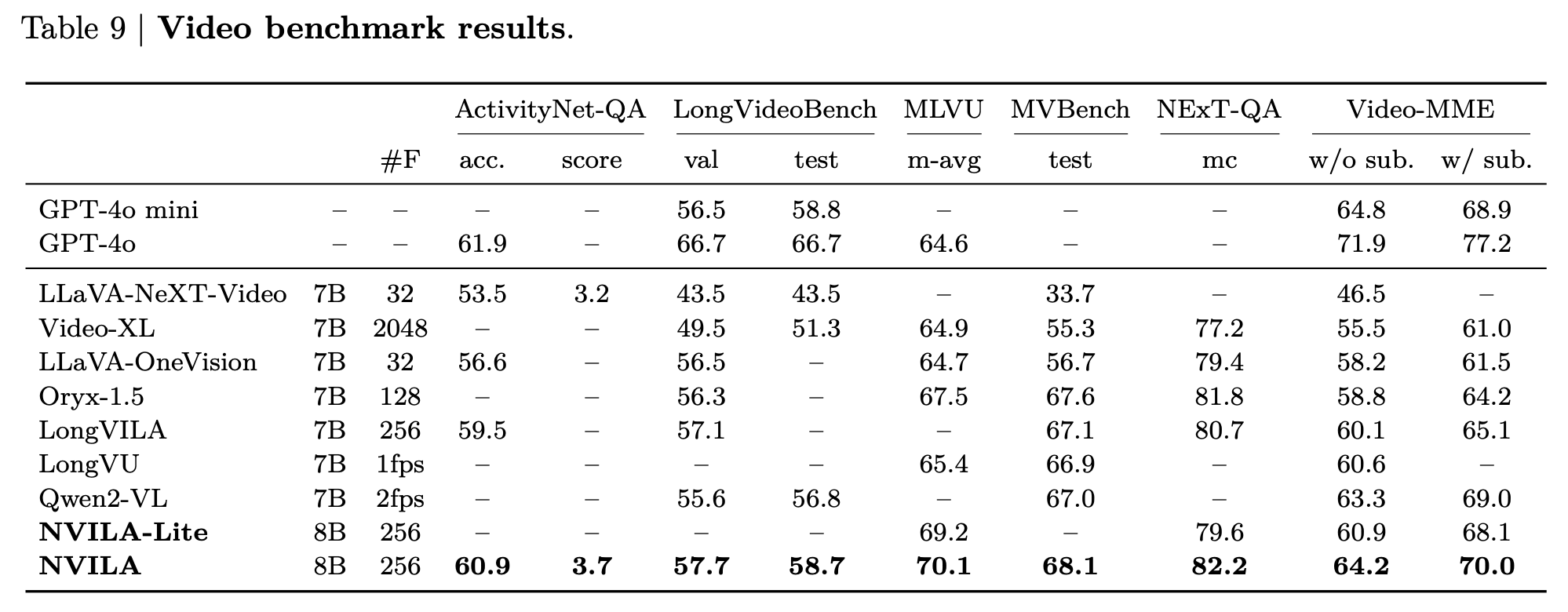
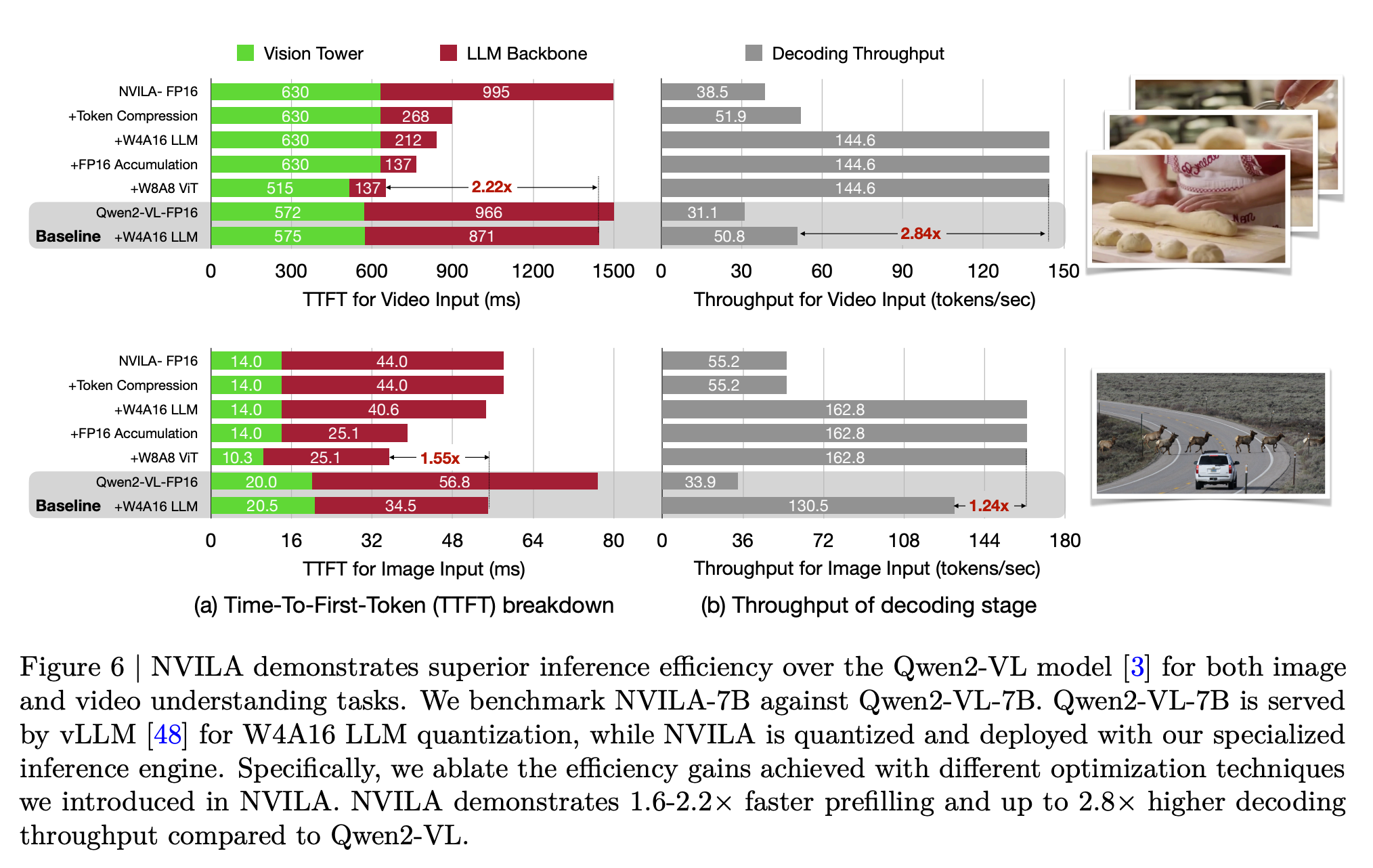
NOTE: Measured using the TinyChat backend at batch size = 1.
| $~~~~~~$ | A100 | 4090 | Orin |
|---|---|---|---|
| NVILA-3B-Baseline | 140.6 | 190.5 | 42.7 |
| NVILA-3B-TinyChat | 184.3 | 230.5 | 45.0 |
| NVILA-Lite-3B-Baseline | 142.3 | 190.0 | 41.3 |
| NVILA-Lite-3B-TinyChat | 186.0 | 233.9 | 44.9 |
| NVILA-8B-Baseline | 82.1 | 61.9 | 11.6 |
| NVILA-8B-TinyChat | 186.8 | 162.7 | 28.1 |
| NVILA-Lite-8B-Baseline | 84.0 | 62.0 | 11.6 |
| NVILA-Lite-8B-TinyChat | 181.8 | 167.5 | 32.8 |
| NVILA-Video-8B-Baseline * | 73.2 | 58.4 | 10.9 |
| NVILA-Video-8B-TinyChat * | 151.8 | 145.0 | 32.3 |
| $~~~~~~$ | A100 | 4090 | Orin |
|---|---|---|---|
| NVILA-3B-Baseline | 0.0329 | 0.0269 | 0.1173 |
| NVILA-3B-TinyChat | 0.0260 | 0.0188 | 0.1359 |
| NVILA-Lite-3B-Baseline | 0.0318 | 0.0274 | 0.1195 |
| NVILA-Lite-3B-TinyChat | 0.0314 | 0.0191 | 0.1241 |
| NVILA-8B-Baseline | 0.0434 | 0.0573 | 0.4222 |
| NVILA-8B-TinyChat | 0.0452 | 0.0356 | 0.2748 |
| NVILA-Lite-8B-Baseline | 0.0446 | 0.0458 | 0.2507 |
| NVILA-Lite-8B-TinyChat | 0.0391 | 0.0297 | 0.2097 |
| NVILA-Video-8B-Baseline * | 0.7190 | 0.8840 | 5.8236 |
| NVILA-Video-8B-TinyChat * | 0.6692 | 0.6815 | 5.8425 |
NOTE: Measured using the TinyChat backend at batch size = 1, dynamic_s2 disabled, and num_video_frames = 64. We use W4A16 LLM and W8A8 Vision Tower for Tinychat and the baseline precision is FP16. *: Measured with video captioning task. Otherwise, measured with image captioning task.
https://github.com/Efficient-Large-Model/VILA/assets/156256291/c9520943-2478-4f97-bc95-121d625018a6
Prompt: Elaborate on the visual and narrative elements of the video in detail.
Caption: The video shows a person's hands working on a white surface. They are folding a piece of fabric with a checkered pattern in shades of blue and white. The fabric is being folded into a smaller, more compact shape. The person's fingernails are painted red, and they are wearing a black and red garment. There are also a ruler and a pencil on the surface, suggesting that measurements and precision are involved in the process.



https://github.com/Efficient-Large-Model/VILA/assets/7783214/6079374c-0787-4bc4-b9c6-e1524b4c9dc4
https://github.com/Efficient-Large-Model/VILA/assets/7783214/80c47742-e873-4080-ad7d-d17c4700539f
-
Install Anaconda Distribution.
-
Install the necessary Python packages in the environment.
./environment_setup.sh vila
-
(Optional) If you are an NVIDIA employee with a wandb account, install onelogger and enable it by setting
training_args.use_one_loggertoTrueinllava/train/args.py.pip install --index-url=https://sc-hw-artf.nvidia.com/artifactory/api/pypi/hwinf-mlwfo-pypi/simple --upgrade one-logger-utils
-
Activate a conda environment.
conda activate vila
VILA training contains three steps, for specific hyperparameters, please check out the scripts/v1_5 folder:
We utilize LLaVA-CC3M-Pretrain-595K dataset to align the textual and visual modalities.
The stage 1 script takes in two parameters and it can run on a single 8xA100 node.
bash scripts/NVILA-Lite/align.sh Efficient-Large-Model/Qwen2-VL-7B-Instruct <alias to data>and the trained models will be saved to runs/train/nvila-8b-align.
bash scripts/NVILA-Lite/stage15.sh runs/train/nvila-8b-align/model <alias to data>and the trained models will be saved to runs/train/nvila-8b-align-1.5.
We use MMC4 and Coyo dataset to train VLM with interleaved image-text pairs.
bash scripts/NVILA-Lite/pretrain.sh runs/train/nvila-8b-align-1.5 <alias to data>and the trained models will be saved to runs/train/nvila-8b-pretraining.
This is the last stage of VILA training, in which we tune the model to follow multimodal instructions on a subset of M3IT, FLAN and ShareGPT4V. This stage runs on a 8xA100 node.
bash scripts/NVILA-Lite/sft.sh runs/train/nvila-8b-pretraining <alias to data>and the trained models will be saved to runs/train/nvila-8b-SFT.
We have introduce vila-eval command to simplify the evaluation. Once the data is prepared, the evaluation can be launched via
MODEL_NAME=NVILA-15B
MODEL_ID=Efficient-Large-Model/$MODEL_NAME
huggingface-cli download $MODEL_ID
vila-eval \
--model-name $MODEL_NAME \
--model-path $MODEL_ID \
--conv-mode auto \
--tags-include localit will launch all evaluations and return a summarized result.
We provide vila-infer for quick inference with user prompts and images.
# image description
vila-infer \
--model-path Efficient-Large-Model/NVILA-15B \
--conv-mode auto \
--text "Please describe the image" \
--media demo_images/demo_img.png
# video description
vila-infer \
--model-path Efficient-Large-Model/NVILA-15B \
--conv-mode auto \
--text "Please describe the video" \
--media https://huggingface.co/datasets/Efficient-Large-Model/VILA-inference-demos/resolve/main/OAI-sora-tokyo-walk.mp4vila-infer is also compatible with VILA-1.5 models. For example:
vila-infer \
--model-path Efficient-Large-Model/VILA1.5-3b \
--conv-mode vicuna_v1 \
--text "Please describe the image" \
--media demo_images/demo_img.png
vila-infer \
--model-path Efficient-Large-Model/VILA1.5-3b \
--conv-mode vicuna_v1 \
--text "Please describe the video" \
--media https://huggingface.co/datasets/Efficient-Large-Model/VILA-inference-demos/resolve/main/OAI-sora-tokyo-walk.mp4
vila-infer \
--model-path Efficient-Large-Model/NVILA-15B \
--conv-mode auto \
--text "Please describe the video" \
--media https://huggingface.co/datasets/Efficient-Large-Model/VILA-inference-demos/resolve/main/OAI-sora-tokyo-walk.mp4Our VILA models are quantized by AWQ into 4 bits for efficient inference on the edge. We provide a push-the-button script to quantize VILA with AWQ.
We support AWQ-quantized 4bit VILA on GPU platforms via TinyChat. We provide a tutorial to run the model with TinyChat after quantization. We also provide an instruction to launch a Gradio server (powered by TinyChat and AWQ) to serve 4-bit quantized VILA models.
We further support our AWQ-quantized 4bit VILA models on various CPU platforms with both x86 and ARM architectures with our TinyChatEngine. We also provide a detailed tutorial to help the users deploy VILA on different CPUs.
A simple API server has been provided to serve VILA models. The server is built on top of FastAPI and Huggingface Transformers. The server can be run with the following command:
python -W ignore server.py \
--port 8000 \
--model-path Efficient-Large-Model/NVILA-15B \
--conv-mode autodocker build -t vila-server:latest .
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
-v ./hub:/root/.cache/huggingface/hub \
-it --rm -p 8000:8000 \
-e VILA_MODEL_PATH=Efficient-Large-Model/NVILA-15B \
-e VILA_CONV_MODE=auto \
vila-server:latestThen you can call the endpoint with the OpenAI SDK as follows:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000",
api_key="fake-key",
)
response = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://blog.logomyway.com/wp-content/uploads/2022/01/NVIDIA-logo.jpg",
# Or you can pass in a base64 encoded image
# "url": "data:image/png;base64,<base64_encoded_image>",
},
},
],
}
],
model="NVILA-15B",
)
print(response.choices[0].message.content)NOTE: This API server is intended for evaluation purposes only and has not been optimized for production use. SGLang support is coming on the way.
We release the following models:
- NVILA-8B / NVILA-8B-Lite
- NVILA-15B / NVILA-15B-Lite
- The code is released under the Apache 2.0 license as found in the LICENSE file.
- The pretrained weights are released under the CC-BY-NC-SA-4.0 license.
- The service is a research preview intended for non-commercial use only, and is subject to the following licenses and terms:
- Model License of LLaMA. For LLAMA3-VILA checkpoints terms of use, please refer to the LLAMA3 License for additional details.
- Terms of Use of the data generated by OpenAI
- Dataset Licenses for each one used during training.
NVILA Core contributors: Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vishwesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, Yao Lu
LongVILA contributors: Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, Ethan He, Hongxu Yin, Pavlo Molchanov, Jan Kautz, Linxi Fan, Yuke Zhu, Yao Lu, Song Han
VILA-1.5 contributors
*Yao Lu: Nvidia, *Hongxu Yin: Nvidia, *Ji Lin: OpenAI (work done at Nvidia and MIT), Wei Ping: Nvidia, Pavlo Molchanov: Nvidia, Andrew Tao: Nvidia, Haotian Tang: MIT, Shang Yang: MIT, Ligeng Zhu: Nvidia, MIT, Wei-Chen Wang: MIT, Fuzhao Xue: Nvidia, NUS, Yunhao Fang: Nvidia, UCSD, Yukang Chen: Nvidia, Zhuoyang Zhang: Nvidia, Yue Shen: Nvidia, Wei-Ming Chen: Nvidia, Huizi Mao: Nvidia, Baifeng Shi: Nvidia, UC Berkeley, Jan Kautz: Nvidia, Mohammad Shoeybi: Nvidia, Song Han: Nvidia, MIT
@misc{liu2024nvila,
title={NVILA: Efficient Frontier Visual Language Models},
author={Zhijian Liu and Ligeng Zhu and Baifeng Shi and Zhuoyang Zhang and Yuming Lou and Shang Yang and Haocheng Xi and Shiyi Cao and Yuxian Gu and Dacheng Li and Xiuyu Li and Yunhao Fang and Yukang Chen and Cheng-Yu Hsieh and De-An Huang and An-Chieh Cheng and Vishwesh Nath and Jinyi Hu and Sifei Liu and Ranjay Krishna and Daguang Xu and Xiaolong Wang and Pavlo Molchanov and Jan Kautz and Hongxu Yin and Song Han and Yao Lu},
year={2024},
eprint={2412.04468},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.04468},
}
@misc{chen2024longvila,
title={LongVILA: Scaling Long-Context Visual Language Models for Long Videos},
author={Yukang Chen and Fuzhao Xue and Dacheng Li and Qinghao Hu and Ligeng Zhu and Xiuyu Li and Yunhao Fang and Haotian Tang and Shang Yang and Zhijian Liu and Ethan He and Hongxu Yin and Pavlo Molchanov and Jan Kautz and Linxi Fan and Yuke Zhu and Yao Lu and Song Han},
year={2024},
eprint={2408.10188},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{lin2023vila,
title={VILA: On Pre-training for Visual Language Models},
author={Ji Lin and Hongxu Yin and Wei Ping and Yao Lu and Pavlo Molchanov and Andrew Tao and Huizi Mao and Jan Kautz and Mohammad Shoeybi and Song Han},
year={2023},
eprint={2312.07533},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
- LLaVA: the codebase we built upon. Thanks for their wonderful work.
- InternVL: for open-sourcing InternViT (used in VILA1.5-40b) and the InternVL-SFT data blend (inspired by LLaVA-1.6) used in all VILA1.5 models.
- Vicuna: the amazing open-sourced large language model!
- Video-ChatGPT: we borrowed video evaluation script from this repository.
- MMC4, COYO-700M, M3IT, OpenORCA/FLAN, ShareGPT4V, WIT, GSM8K-ScRel, VisualGenome, VCR, ScienceQA, Shot2Story, Youcook2, Vatex, ShareGPT-Video for providing datasets used in this research.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VILA
Similar Open Source Tools
VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.

AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.
aichat
Aichat is an AI-powered CLI chat and copilot tool that seamlessly integrates with over 10 leading AI platforms, providing a powerful combination of chat-based interaction, context-aware conversations, and AI-assisted shell capabilities, all within a customizable and user-friendly environment.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.
star-vector
StarVector is a multimodal vision-language model for Scalable Vector Graphics (SVG) generation. It can be used to perform image2SVG and text2SVG generation. StarVector works directly in the SVG code space, leveraging visual understanding to apply accurate SVG primitives. It achieves state-of-the-art performance in producing compact and semantically rich SVGs. The tool provides Hugging Face model checkpoints for image2SVG vectorization, with models like StarVector-8B and StarVector-1B. It also offers datasets like SVG-Stack, SVG-Fonts, SVG-Icons, SVG-Emoji, and SVG-Diagrams for evaluation. StarVector can be trained using Deepspeed or FSDP for tasks like Image2SVG and Text2SVG generation. The tool provides a demo with options for HuggingFace generation or VLLM backend for faster generation speed.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

ERNIE
ERNIE 4.5 is a family of large-scale multimodal models with 10 distinct variants, including Mixture-of-Experts (MoE) models with 47B and 3B active parameters. The models feature a novel heterogeneous modality structure supporting parameter sharing across modalities while allowing dedicated parameters for each individual modality. Trained with optimal efficiency using PaddlePaddle deep learning framework, ERNIE 4.5 models achieve state-of-the-art performance across text and multimodal benchmarks, enhancing multimodal understanding without compromising performance on text-related tasks. The open-source development toolkits for ERNIE 4.5 offer industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.
RLHF-Reward-Modeling
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.
For similar tasks
VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.
mark
Mark is a CLI tool that allows users to interact with large language models (LLMs) using Markdown format. It enables users to seamlessly integrate GPT responses into Markdown files, supports image recognition, scraping of local and remote links, and image generation. Mark focuses on using Markdown as both a prompt and response medium for LLMs, offering a unique and flexible way to interact with language models for various use cases in development and documentation processes.
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.
inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
cortex
Nitro is a high-efficiency C++ inference engine for edge computing, powering Jan. It is lightweight and embeddable, ideal for product integration. The binary of nitro after zipped is only ~3mb in size with none to minimal dependencies (if you use a GPU need CUDA for example) make it desirable for any edge/server deployment.
ort
Ort is an unofficial ONNX Runtime 1.17 wrapper for Rust based on the now inactive onnxruntime-rs. ONNX Runtime accelerates ML inference on both CPU and GPU.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.