
RLHF-Reward-Modeling
Recipes to train reward model for RLHF.
Stars: 568
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.
README:
Our models and codes have contributed to many academic research projects, e.g.,
- Xu Zhangchen, et al. "Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing."
- Chen, Lichang, et al. "OPTune: Efficient Online Preference Tuning."
- Xie, Tengyang, et al. "Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF." arXiv preprint arXiv:2405.21046 (2024).
- Zhong, Han, et al. "Dpo meets ppo: Reinforced token optimization for rlhf." arXiv preprint arXiv:2404.18922 (2024).
- Zheng, Chujie, et al. "Weak-to-strong extrapolation expedites alignment." arXiv preprint arXiv:2404.16792 (2024).
- Ye, Chenlu, et al. "A theoretical analysis of nash learning from human feedback under general kl-regularized preference." arXiv preprint arXiv:2402.07314 (2024).
- Chen, Ruijun, et al. "Self-Evolution Fine-Tuning for Policy Optimization"
- Li Bolian, et al., Cascade Reward Sampling for Efficient Decoding-Time Alignment
- Zhang, Yuheng, et al. "Iterative Nash Policy Optimization: Aligning LLMs with General Preferences via No-Regret Learning"
- Lin Tzu-Han, et al., "DogeRM: Equipping Reward Models with Domain Knowledge through Model Merging",
- Yang Rui, et al., "Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs"
- Junsoo Park, et al., "OffsetBias: Leveraging Debiased Data for Tuning Evaluators"
- Meng Yu, et al., "SimPO: Simple Preference Optimization with a Reference-Free Reward"
- Song Yifan, et al., "The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism"
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
🚀 Our ArmoRM is the Rank #1 8B model on RewardBench!
🚀 The top-3 open-source 8B reward models on RewardBench (ArmoRM, Pair Pref. Model, BT RM) are all trained with this repo!
🚀 The pairwise preference model training code is available (pair-pm/)!
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
-
Tech Report
-
Models:
- Absolute-Rating Multi-Objective Reward Model (ArmoRM): ArmoRM-Llama3-8B-v0.1
- Pairwise Preference Reward Model: pair-preference-model-LLaMA3-8B
- Bradley-Terry Reward Model: FsfairX-LLaMA3-RM-v0.1
-
Architectures
- Bradley-Terry (BT) Reward Model and Pairwise Preference Model

- Absolute-Rating Multi-Objective Reward Model (ArmoRM)

- Bradley-Terry (BT) Reward Model and Pairwise Preference Model
-
Model Base Model Method Score Chat Chat Hard Safety Reasoning Prior Sets (0.5 weight) ArmoRM-Llama3-8B-v0.1 (Ours) Llama-3 8B ArmoRM + MoE 89.0 96.9 76.8 92.2 97.3 74.3 Cohere May 2024 Unknown Unknown 88.2 96.4 71.3 92.7 97.7 78.2 pair-preference-model (Ours) Llama-3 8B SliC-HF 85.7 98.3 65.8 89.7 94.7 74.6 GPT-4 Turbo (0125 version) GPT-4 Turbo LLM-as-a-Judge 84.3 95.3 74.3 87.2 86.9 70.9 FsfairX-LLaMA3-RM-v0.1 (Ours) Llama-3 8B Bradley-Terry 83.6 99.4 65.1 87.8 86.4 74.9 Starling-RM-34B Yi-34B Bradley-Terry 81.4 96.9 57.2 88.2 88.5 71.4 -
Evaluation Results (from RLHF Workflow)
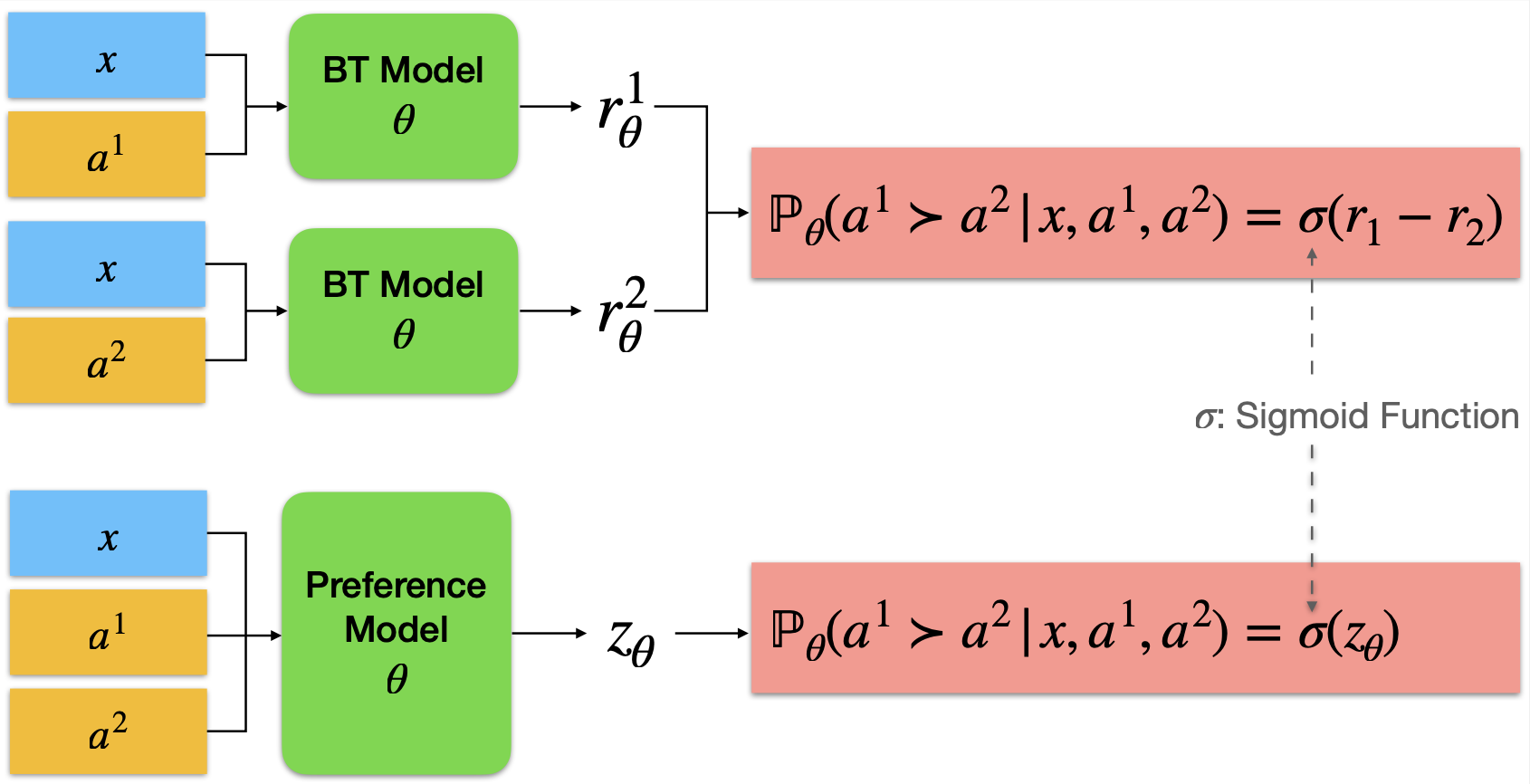
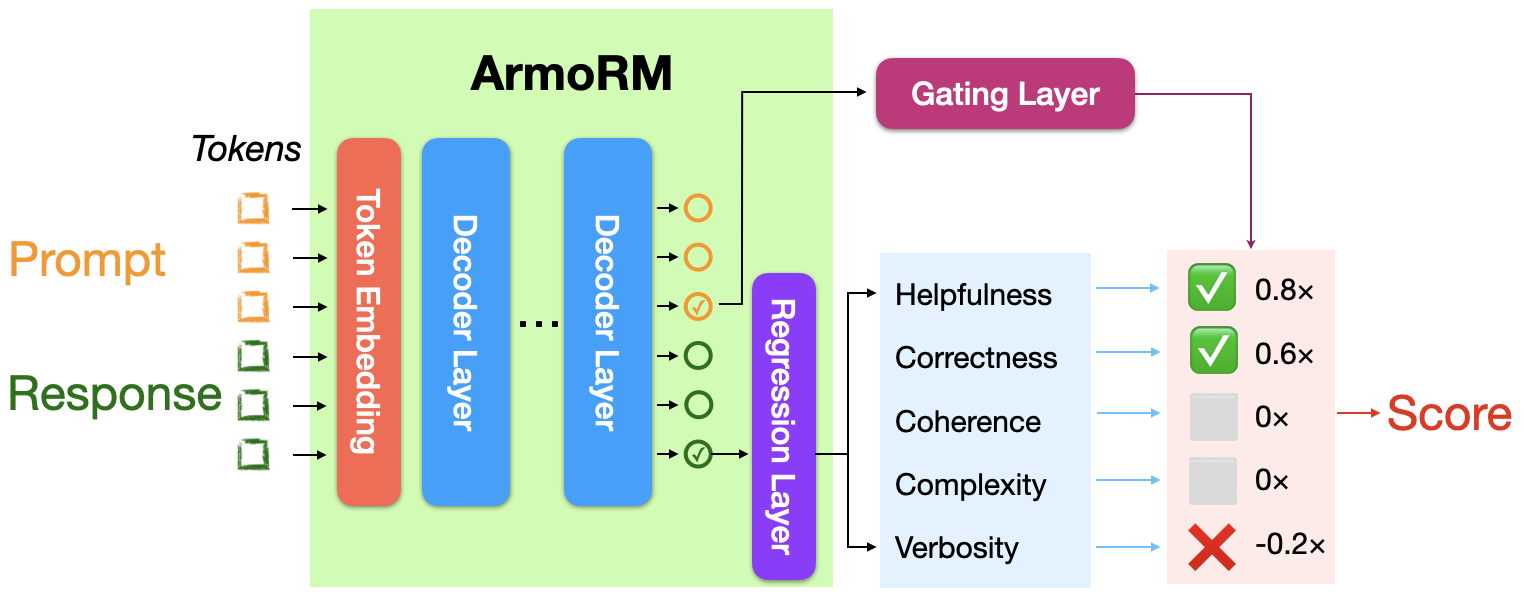
TL;DL: this is a repo for training the reward/preference model for DRL-based RLHF (PPO), Iterative SFT (Rejection sampling fine-tuning), and iterative DPO.
- 4 x A40 48G: we can train Gemma-7B-it with max_length 4096 by Deepspeed Zero-3 + gradient checkpoint;
- 4 x A100 80G: we can train Gemma-7B-it with max_length 4096 by gradient checkpoint;
- The resulting reward models achieve SOTA performance as open-source RMs in the leaderboard of RewardBench.
- Check out our blog post!
It is recommeded to create separate environmnets for the Bradley-Terry reward model and pair wise preference model. The installation instructions are provided in the corresponding folders.
The dataset should be preprocessed as the standard format, where each of the sample consists of two conversations 'chosen' and 'rejected' and they share the same prompt. Here is an example of the rejected sample in the comparison pair.
[
{ "content": "Please identify the top 5 rarest animals in the world.", "role": "user" },
{ "content": "Do you mean animals that are really rare, or rare relative to the size of the human population?", "role": "assistant" },
{ "content": "The ones that are really rare.", "role": "user" },
{ "content": "Alright, here’s what I found:", "role": "assistant" },
]We preprocess many open-source preference datasets into the standard format and upload them to the hugginface hub. You can find them HERE. We have also searched and founda that some of the following mixture of preference dataset useful.
- weqweasdas/preference_dataset_mix2
- weqweasdas/preference_dataset_mixture2_and_safe_pku
- hendrydong/preference_700K where the details can be found in the dataset card.
You can evaluate the resulting reward model with the dataset provided by benchmark by the following command.
CUDA_VISIBLE_DEVICES=1 python ./useful_code/eval_reward_bench_bt.py --reward_name_or_path ./models/gemma_2b_mixture2_last_checkpoint --record_dir ./bench_mark_eval.txt- [x] Bradley-Terry Reward Model
- [x] Preference model
- [x] Multi-Objective Reward Model
- [ ] LLM-as-a-judge
The repo was part of the iterative rejection sampling fine-tuning and iterative DPO. If you find the content of this repo useful in your work, please consider citing:
@article{dong2024rlhf,
title={RLHF Workflow: From Reward Modeling to Online RLHF},
author={Dong, Hanze and Xiong, Wei and Pang, Bo and Wang, Haoxiang and Zhao, Han and Zhou, Yingbo and Jiang, Nan and Sahoo, Doyen and Xiong, Caiming and Zhang, Tong},
journal={arXiv preprint arXiv:2405.07863},
year={2024}
}
@article{ArmoRM,
title={Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts},
author={Haoxiang Wang and Wei Xiong and Tengyang Xie and Han Zhao and Tong Zhang},
journal={arXiv preprint arXiv:2406.12845},
}
@article{dong2023raft,
title={{RAFT}: Reward rAnked FineTuning for Generative Foundation Model Alignment},
author={Hanze Dong and Wei Xiong and Deepanshu Goyal and Yihan Zhang and Winnie Chow and Rui Pan and Shizhe Diao and Jipeng Zhang and KaShun SHUM and Tong Zhang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2023},
url={https://openreview.net/forum?id=m7p5O7zblY},
}
@article{xiong2024iterative,
title={Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint},
author={Wei Xiong and Hanze Dong and Chenlu Ye and Ziqi Wang and Han Zhong and Heng Ji and Nan Jiang and Tong Zhang},
year={2024},
journal={ICML}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RLHF-Reward-Modeling
Similar Open Source Tools
RLHF-Reward-Modeling
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.
PURE
PURE (Process-sUpervised Reinforcement lEarning) is a framework that trains a Process Reward Model (PRM) on a dataset and fine-tunes a language model to achieve state-of-the-art mathematical reasoning capabilities. It uses a novel credit assignment method to calculate return and supports multiple reward types. The final model outperforms existing methods with minimal RL data or compute resources, achieving high accuracy on various benchmarks. The tool addresses reward hacking issues and aims to enhance long-range decision-making and reasoning tasks using large language models.

CodeGeeX4
CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.
buffer-of-thought-llm
Buffer of Thoughts (BoT) is a thought-augmented reasoning framework designed to enhance the accuracy, efficiency, and robustness of large language models (LLMs). It introduces a meta-buffer to store high-level thought-templates distilled from problem-solving processes, enabling adaptive reasoning for efficient problem-solving. The framework includes a buffer-manager to dynamically update the meta-buffer, ensuring scalability and stability. BoT achieves significant performance improvements on reasoning-intensive tasks and demonstrates superior generalization ability and robustness while being cost-effective compared to other methods.

AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

BitBLAS
BitBLAS is a library for mixed-precision BLAS operations on GPUs, for example, the $W_{wdtype}A_{adtype}$ mixed-precision matrix multiplication where $C_{cdtype}[M, N] = A_{adtype}[M, K] \times W_{wdtype}[N, K]$. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the $W_{wdtype}A_{adtype}$ quantization in large language models (LLMs), for example, the $W_{UINT4}A_{FP16}$ in GPTQ, the $W_{INT2}A_{FP16}$ in BitDistiller, the $W_{INT2}A_{INT8}$ in BitNet-b1.58. BitBLAS is based on techniques from our accepted submission at OSDI'24.

llm4ad
LLM4AD is an open-source Python-based platform leveraging Large Language Models (LLMs) for Automatic Algorithm Design (AD). It provides unified interfaces for methods, tasks, and LLMs, along with features like evaluation acceleration, secure evaluation, logs, GUI support, and more. The platform was originally developed for optimization tasks but is versatile enough to be used in other areas such as machine learning, science discovery, game theory, and engineering design. It offers various search methods and algorithm design tasks across different domains. LLM4AD supports remote LLM API, local HuggingFace LLM deployment, and custom LLM interfaces. The project is licensed under the MIT License and welcomes contributions, collaborations, and issue reports.
Odyssey
Odyssey is a framework designed to empower agents with open-world skills in Minecraft. It provides an interactive agent with a skill library, a fine-tuned LLaMA-3 model, and an open-world benchmark for evaluating agent capabilities. The framework enables agents to explore diverse gameplay opportunities in the vast Minecraft world by offering primitive and compositional skills, extensive training data, and various long-term planning tasks. Odyssey aims to advance research on autonomous agent solutions by providing datasets, model weights, and code for public use.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
For similar tasks
RLHF-Reward-Modeling
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.

MathEval
MathEval is a benchmark designed for evaluating the mathematical capabilities of large models. It includes over 20 evaluation datasets covering various mathematical domains with more than 30,000 math problems. The goal is to assess the performance of large models across different difficulty levels and mathematical subfields. MathEval serves as a reliable reference for comparing mathematical abilities among large models and offers guidance on enhancing their mathematical capabilities in the future.
AIGC_text_detector
AIGC_text_detector is a repository containing the official codes for the paper 'Multiscale Positive-Unlabeled Detection of AI-Generated Texts'. It includes detector models for both English and Chinese texts, along with stronger detectors developed with enhanced training strategies. The repository provides links to download the detector models, datasets, and necessary preprocessing tools. Users can train RoBERTa and BERT models on the HC3-English dataset using the provided scripts.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.
AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.