
rageval
Evaluation tools for Retrieval-augmented Generation (RAG) methods.
Stars: 118
Rageval is an evaluation tool for Retrieval-augmented Generation (RAG) methods. It helps evaluate RAG systems by performing tasks such as query rewriting, document ranking, information compression, evidence verification, answer generation, and result validation. The tool provides metrics for answer correctness and answer groundedness, along with benchmark results for ASQA and ALCE datasets. Users can install and use Rageval to assess the performance of RAG models in question-answering tasks.
README:
Evaluation tools for Retrieval-augmented Generation (RAG) methods.
![]()
Rageval is a tool that helps you evaluate RAG system. The evaluation consists of six sub-tasks, including query rewriting, document ranking, information compression, evidence verify, answer generating, and result validating.
The generate task is to answer the question based on the contexts provided by retrieval modules in RAG. Typically, the context could be extracted/generated text snippets from the compressor, or relevant documents from the re-ranker. Here, we divide metrics used in the generate task into two categories, namely answer correctness and answer groundedness.
(1) Answer Correctness: this category of metrics is to evaluate the correctness by comparing the generated answer with the groundtruth answer. Here are some commonly used metrics:
- Answer F1 Correctness: is widely used in the paper (Jiang et al.), the paper (Yu et al.), the paper (Xu et al.), and others.
- Answer NLI Correctness: also known as claim recall in the paper (Tianyu et al.).
- Answer EM Correctness: also known as Exact Match as used in the paper (Ivan Stelmakh et al.).
- Answer Bleu Score: also known as Bleu as used in the paper (Kishore Papineni et al.).
- Answer Ter Score: also known as Translation Edit Rate as used in the paper (Snover et al.).
- Answer chrF Score: also known as character n-gram F-score as used in the paper (Popovic et al.).
- Answer Disambig-F1: also known as Disambig-F1 as used in the paper (Ivan Stelmakh et al.) and the paper (Zhengbao Jiang et al.).
- Answer Rouge Correctness: also known as Rouge as used in the paper (Chin-Yew Lin).
- Answer Accuracy: also known as Accuracy as used in the paper (Dan Hendrycks et al.).
- Answer LCS Ratio: also know as LCS(%) as used in the paper (Nashid et al.).
- Answer Edit Distance: also know as Edit distance as used in the paper (Nashid et al.).
(2) Answer Groundedness: this category of metrics is to evaluate the groundedness (also known as factual consistency) by comparing the generated answer with the provided contexts. Here are some commonly used metrics:
- Answer Citation Precision: also known as citation precision in the paper (Tianyu et al.).
- Answer Citation Recall: also known as citation recall in the paper (Tianyu et al.).
- Context Reject Rate: also known as reject rate in the paper (Wenhao Yu et al.).
The rewrite task is to reformulate user question into a set of queries, making them more friendly to the search module in RAG.
The search task is to retrieve relevant documents from the knowledge base.
(1) Context Adequacy: this category of metrics is to evaluate the adequacy by comparing the retrieved documents with the groundtruth contexts. Here are some commonly used metrics:
(2) Context Relevance: this category of metrics is to evaluate the relevance by comparing the retrieved documents with the groundtruth answers. Here are some commonly used metrics:
- Context Recall: also known as Context Recall in RAGAS framework.
Some metrics evaluations rely on LLMs as evaluators. You can either directly call OpenAI's API or deploy an open-source model as a RESTful API in the OpenAI format for evaluation.
- OpenAI
os.environ["OPENAI_API_KEY"] = "<your_openai_api_key>"- Open source LLMs
Please use vllm to setup the API server for open source LLMs. For example, use the following command to deploy a Llama-3-8B model hosted on HuggingFace:
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--tensor-parallel-size 8 \
--dtype auto \
--api-key sk-123456789 \
--gpu-memory-utilization 0.9 \
--port 5000ASQA dataset is a question-answering dataset that contains factoid questions and long-form answers. The benchmark evaluates the correctness of the answer in the dataset. All detailed results can be download from this repo. Besides, these results can be reproduced based on the script in this repo.
| Model | Retriever | Metric | |||
| String EM | Rouge L | Disambig F1 | D-R Score | ||
| gpt-3.5-turbo-instruct | no-retrieval | 33.8 | 30.2 | 30.7 | 30.5 |
| mistral-7b | no-retrieval | 20.6 | 31.1 | 26.6 | 28.7 |
| llama2-7b-chat | no-retrieval | 21.7 | 30.7 | 28.0 | 29.3 |
| llama3-8b-base | no-retrieval | 25.7 | 31.0 | 28.4 | 29.7 |
| llama3-8b-instruct | no-retrieval | 27.1 | 30.9 | 29.4 | 30.1 |
| solar-10.7b-instruct | no-retrieval | 23.0 | 24.9 | 28.1 | 26.5 |
ALCE is a benchmark for Automatic LLMs' Citation Evaluation. ALCE contains three datasets: ASQA, QAMPARI, and ELI5. All detailed results can be download from this repo. Besides, these results can be reproduced based on the script in this repo.
For more evaluation results, please view the benchmark's README: ALCE-ASQA and ALCE-ELI5.
| Dataset | Model | Method | Metric | |||||
| retriever | prompt | MAUVE | EM Recall | Claim Recall | Citation Recall | Citation Precision | ||
| ASQA | llama2-7b-chat | GTR | vanilla(5-psg) | - | 33.3 | - | 55.9 | 80.0 |
| DPR | vanilla(5-psg) | - | 29.2 | - | 49.2 | 81.0 | ||
| Oracle | vanilla(5-psg) | - | 41.7 | - | 58.1 | 78.9 | ||
| ELI5 | llama2-7b-chat | BM25 | vanilla(5-psg) | - | - | 11.5 | 26.6 | 74.5 |
| Oracle | vanilla(5-psg) | - | - | 17.8 | 34.0 | 75.6 | ||
git clone https://github.com/gomate-community/rageval.git
cd rageval
python setup.py install
Take F1 as an example.
from datasets import Dataset
import rageval as rl
sample = {
"answers": [
"Democrat rick kriseman won the 2016 mayoral election, while re- publican former mayor rick baker did so in the 2017 mayoral election."
],
"gt_answers": [
[
"Kriseman",
"Rick Kriseman"
]
]
}
dataset = Dataset.from_dict(sample)
metric = rl.metrics.AnswerF1Correctness()
score, dataset = metric.compute(dataset)
Benchmarks can be run directly using scripts (Take ALCE-ELI5 as an example).
bash benchmarks/ALCE/ELI5/run.sh
Please make sure to read the Contributing Guide before creating a pull request.
This project is currently at its preliminary stage.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rageval
Similar Open Source Tools
rageval
Rageval is an evaluation tool for Retrieval-augmented Generation (RAG) methods. It helps evaluate RAG systems by performing tasks such as query rewriting, document ranking, information compression, evidence verification, answer generation, and result validation. The tool provides metrics for answer correctness and answer groundedness, along with benchmark results for ASQA and ALCE datasets. Users can install and use Rageval to assess the performance of RAG models in question-answering tasks.
PURE
PURE (Process-sUpervised Reinforcement lEarning) is a framework that trains a Process Reward Model (PRM) on a dataset and fine-tunes a language model to achieve state-of-the-art mathematical reasoning capabilities. It uses a novel credit assignment method to calculate return and supports multiple reward types. The final model outperforms existing methods with minimal RL data or compute resources, achieving high accuracy on various benchmarks. The tool addresses reward hacking issues and aims to enhance long-range decision-making and reasoning tasks using large language models.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.

CodeGeeX4
CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.
buffer-of-thought-llm
Buffer of Thoughts (BoT) is a thought-augmented reasoning framework designed to enhance the accuracy, efficiency, and robustness of large language models (LLMs). It introduces a meta-buffer to store high-level thought-templates distilled from problem-solving processes, enabling adaptive reasoning for efficient problem-solving. The framework includes a buffer-manager to dynamically update the meta-buffer, ensuring scalability and stability. BoT achieves significant performance improvements on reasoning-intensive tasks and demonstrates superior generalization ability and robustness while being cost-effective compared to other methods.
RLHF-Reward-Modeling
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.
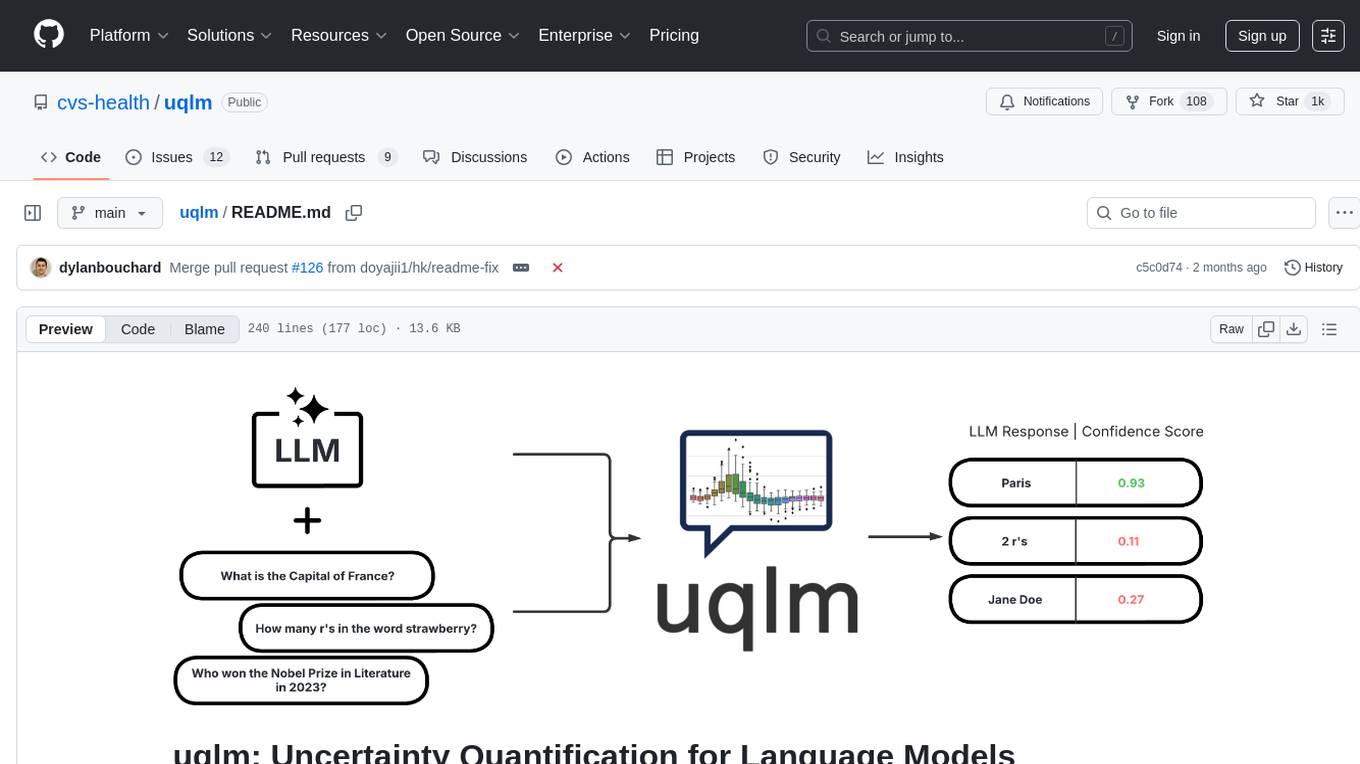
uqlm
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques. It provides response-level scorers for quantifying uncertainty of LLM outputs, categorized into four main types: Black-Box Scorers, White-Box Scorers, LLM-as-a-Judge Scorers, and Ensemble Scorers. Users can leverage different scorers to assess uncertainty in generated responses, with options for off-the-shelf usage or customization. The library offers illustrative code snippets and detailed information on available scorers for each type, along with example usage for conducting hallucination detection. Additionally, UQLM includes documentation, example notebooks, and associated research for further exploration and understanding.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.

evedel
Evedel is an Emacs package designed to streamline the interaction with LLMs during programming. It aims to reduce manual code writing by creating detailed instruction annotations in the source files for LLM models. The tool leverages overlays to track instructions, categorize references with tags, and provide a seamless workflow for managing and processing directives. Evedel offers features like saving instruction overlays, complex query expressions for directives, and easy navigation through instruction overlays across all buffers. It is versatile and can be used in various types of buffers beyond just programming buffers.
SciCode
SciCode is a challenging benchmark designed to evaluate the capabilities of language models (LMs) in generating code for solving realistic scientific research problems. It contains 338 subproblems decomposed from 80 challenging main problems across 16 subdomains from 6 domains. The benchmark offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. SciCode demonstrates a realistic workflow of identifying critical science concepts and facts and transforming them into computation and simulation code, aiming to help showcase LLMs' progress towards assisting scientists and contribute to the future building and evaluation of scientific AI.
For similar tasks
rageval
Rageval is an evaluation tool for Retrieval-augmented Generation (RAG) methods. It helps evaluate RAG systems by performing tasks such as query rewriting, document ranking, information compression, evidence verification, answer generation, and result validation. The tool provides metrics for answer correctness and answer groundedness, along with benchmark results for ASQA and ALCE datasets. Users can install and use Rageval to assess the performance of RAG models in question-answering tasks.
FedLLM-Bench
FedLLM-Bench is a realistic benchmark for the Federated Learning of Large Language Models community. It includes datasets for federated instruction tuning and preference alignment tasks, exhibiting diversities in language, quality, quantity, instruction, sequence length, embedding, and preference. The repository provides training scripts and code for open-ended evaluation, aiming to facilitate research and development in federated learning of large language models.
EuroEval
EuroEval is a robust European language model benchmark tool, formerly known as ScandEval. It provides a platform to benchmark pretrained models on various tasks across different languages. Users can evaluate models, datasets, and metrics both online and offline. The tool supports benchmarking from the command line, script, and Docker. Additionally, users can reproduce datasets used in the project using provided scripts. EuroEval welcomes contributions and offers guidelines for general contributions and adding new datasets.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.