
LLM4Decompile
Reverse Engineering: Decompiling Binary Code with Large Language Models
Stars: 3010
LLM4Decompile is an open-source large language model dedicated to decompilation of Linux x86_64 binaries, supporting GCC's O0 to O3 optimization levels. It focuses on assessing re-executability of decompiled code through HumanEval-Decompile benchmark. The tool includes models with sizes ranging from 1.3 billion to 33 billion parameters, available on Hugging Face. Users can preprocess C code into binary and assembly instructions, then decompile assembly instructions into C using LLM4Decompile. Ongoing efforts aim to expand capabilities to support more architectures and configurations, integrate with decompilation tools like Ghidra and Rizin, and enhance performance with larger training datasets.
README:
📊 Results | 🤗 Models | 🚀 Quick Start | 📚 HumanEval-Decompile | 📎 Citation | 📝 Paper | 📝 Colab
Reverse Engineering: Decompiling Binary Code with Large Language Models
- [2024-10-17]: Release decompile-ghidra-100k, a subset of 100k training samples (25k per optimization level). We provide a training script that runs in ~3.5 hours on a single A100 40G GPU. It achieves a 0.26 re-executability rate, with a total cost of under $20 for quick replication of LLM4Decompile.
- [2024-09-26]: Update a Colab notebook to demonstrate the usage of the LLM4Decompile model, including examples for the LLM4Decompile-End and LLM4Decompile-Ref models.
- [2024-09-23]: Release LLM4Decompile-9B-v2, fine-tuned based on Yi-Coder-9B, achieved a re-executability rate of 0.6494 on the Decompile benchmark.
- [2024-06-19]: Release V2 series (LLM4Decompile-Ref). V2 (1.3B-22B), building upon Ghidra, are trained on 2 billion tokens to refine the decompiled pseudo-code from Ghidra. The 22B-V2 version outperforms the 6.7B-V1.5 by an additional 40.1%. Please check the ghidra folder for details.
- [2024-05-13]: Release V1.5 series (LLM4Decompile-End, directly decompile binary using LLM). V1.5 are trained with a larger dataset (15B tokens) and a maximum token length of 4,096, with remarkable performance (over 100% improvement) compared to the previous model.
- [2024-03-16]: Add llm4decompile-6.7b-uo model which is trained without prior knowledge of the optimization levels (O0~O3), the average re-executability is around 0.219, performs the best in our models.
- LLM4Decompile is the pioneering open-source large language model dedicated to decompilation. Its current version supports decompiling Linux x86_64 binaries, ranging from GCC's O0 to O3 optimization levels, into human-readable C source code. Our team is committed to expanding this tool's capabilities, with ongoing efforts to incorporate a broader range of architectures and configurations.
- LLM4Decompile-End focuses on decompiling the binary directly. LLM4Decompile-Ref refines the pseudo-code decompiled by Ghidra.

During compilation, the Preprocessor processes the source code (SRC) to eliminate comments and expand macros or includes. The cleaned code is then forwarded to the Compiler, which converts it into assembly code (ASM). This ASM is transformed into binary code (0s and 1s) by the Assembler. The Linker finalizes the process by linking function calls to create an executable file. Decompilation, on the other hand, involves converting binary code back into a source file. LLMs, being trained on text, lack the ability to process binary data directly. Therefore, binaries must be disassembled by Objdump into assembly language (ASM) first. It should be noted that binary and disassembled ASM are equivalent, they can be interconverted, and thus we refer to them interchangeably. Finally, the loss is computed between the decompiled code and source code to guide the training. To assess the quality of the decompiled code (SRC'), it is tested for its functionality through test assertions (re-executability).
- Re-executability evaluates whether the decompiled code can execute properly and pass all the predefined test cases.
- HumanEval-Decompile A collection of 164 C functions that exclusively rely on standard C libraries.
- ExeBench A collection of 2,621 functions drawn from real projects, each utilizing user-defined functions, structures, and macros.

Our LLM4Decompile includes models with sizes between 1.3 billion and 33 billion parameters, and we have made these models available on Hugging Face.
| Model | Checkpoint | Size | Re-executability | Note |
|---|---|---|---|---|
| llm4decompile-1.3b | 🤗 HF Link | 1.3B | 10.6% | - |
| llm4decompile-6.7b | 🤗 HF Link | 6.7B | 21.4% | - |
| llm4decompile-33b | 🤗 HF Link | 33B | 21.5% | - |
| llm4decompile-6.7b-nsp | 🤗 HF Link | 6.7B | 20.9% | Note 1 |
| llm4decompile-6.7b-uo | 🤗 HF Link | 6.7B | 21.9% | Note 2 |
| llm4decompile-1.3b-v1.5 | 🤗 HF Link | 1.3B | 27.3% | Note 3 |
| llm4decompile-6.7b-v1.5 | 🤗 HF Link | 6.7B | 45.4% | Note 3 |
| llm4decompile-1.3b-v2 | 🤗 HF Link | 1.3B | 46.0% | Note 4 |
| llm4decompile-6.7b-v2 | 🤗 HF Link | 6.7B | 52.7% | Note 4 |
| llm4decompile-9b-v2 | 🤗 HF Link | 9B | 64.9% | - |
| llm4decompile-22b-v2 | 🤗 HF Link | 22B | 63.6% | Note 4 |
Note 1: The NSP model is trained with assembly code, the average re-executability is around 0.17.
Note 2: The unified optimization (UO) model is trained without prior knowledge of the optimization levels (O0~O3), the average re-executability is around 0.21. The pre-processing of the UO model is slightly different (no prior knowledge of the On), please check the model page.
Note 3: V1.5 series are trained with a larger dataset (15B tokens) and a maximum token size of 4,096, with remarkable performance (over 100% improvement) compared to the previous model.
Note 4: V2 series are built upon Ghidra and trained on 2 billion tokens to refine the decompiled pseudo-code from Ghidra. Check ghidra folder for details.
Setup: Please use the script below to install the necessary environment.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
Here is an example of how to use our model (Revised for V1.5. For previous models, please check the corresponding model page at HF). Note: Replace the "func0" with the function name you want to decompile.
Preprocessing: Compile the C code into binary, and disassemble the binary into assembly instructions.
import subprocess
import os
func_name = 'func0'
OPT = ["O0", "O1", "O2", "O3"]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT:
output_file = fileName +'_' + opt_state
input_file = fileName+'.c'
compile_command = f'gcc -o {output_file}.o {input_file} -{opt_state} -lm'#compile the code with GCC on Linux
subprocess.run(compile_command, shell=True, check=True)
compile_command = f'objdump -d {output_file}.o > {output_file}.s'#disassemble the binary file into assembly instructions
subprocess.run(compile_command, shell=True, check=True)
input_asm = ''
with open(output_file+'.s') as f:#asm file
asm= f.read()
if '<'+func_name+'>:' not in asm: #IMPORTANT replace func0 with the function name
raise ValueError("compile fails")
asm = '<'+func_name+'>:' + asm.split('<'+func_name+'>:')[-1].split('\n\n')[0] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm.split("\n")
for tmp in asm_sp:
if len(tmp.split("\t"))<3 and '00' in tmp:
continue
idx = min(
len(tmp.split("\t")) - 1, 2
)
tmp_asm = "\t".join(tmp.split("\t")[idx:]) # remove the binary code
tmp_asm = tmp_asm.split("#")[0].strip() # remove the comments
asm_clean += tmp_asm + "\n"
input_asm = asm_clean.strip()
before = f"# This is the assembly code:\n"#prompt
after = "\n# What is the source code?\n"#prompt
input_asm_prompt = before+input_asm.strip()+after
with open(fileName +'_' + opt_state +'.asm','w',encoding='utf-8') as f:
f.write(input_asm_prompt)Assembly instructions should be in the format:
<FUNCTION_NAME>:\nOPERATIONS\nOPERATIONS\n
Typical assembly instructions may look like this:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
Decompilation: Use LLM4Decompile to translate the assembly instructions into C:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.bfloat16).cuda()
with open(fileName +'_' + OPT[0] +'.asm','r') as f:#optimization level O0
asm_func = f.read()
inputs = tokenizer(asm_func, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=2048)### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer.decode(outputs[0][len(inputs[0]):-1])
with open(fileName +'.c','r') as f:#original file
func = f.read()
print(f'original function:\n{func}')# Note we only decompile one function, where the original file may contain multiple functions
print(f'decompiled function:\n{c_func_decompile}')Data are stored in llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json, using JSON list format. There are 164*4 (O0, O1, O2, O3) samples, each with five keys:
-
task_id: indicates the ID of the problem. -
type: the optimization stage, is one of [O0, O1, O2, O3]. -
c_func: C solution for HumanEval problem. -
c_test: C test assertions. -
input_asm_prompt: assembly instructions with prompts, can be derived as in our preprocessing example.
Please check the evaluation scripts.
- Larger training dataset with the cleaning process. (done:2024.05.13)
- Support for popular languages/platforms and settings.
- Support for executable binaries. (done:2024.05.13)
- Integration with decompilation tools (e.g., Ghidra, Rizin)
This code repository is licensed under the MIT and DeepSeek License.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM4Decompile
Similar Open Source Tools
LLM4Decompile
LLM4Decompile is an open-source large language model dedicated to decompilation of Linux x86_64 binaries, supporting GCC's O0 to O3 optimization levels. It focuses on assessing re-executability of decompiled code through HumanEval-Decompile benchmark. The tool includes models with sizes ranging from 1.3 billion to 33 billion parameters, available on Hugging Face. Users can preprocess C code into binary and assembly instructions, then decompile assembly instructions into C using LLM4Decompile. Ongoing efforts aim to expand capabilities to support more architectures and configurations, integrate with decompilation tools like Ghidra and Rizin, and enhance performance with larger training datasets.
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.
honey
Bee is an ORM framework that provides easy and high-efficiency database operations, allowing developers to focus on business logic development. It supports various databases and features like automatic filtering, partial field queries, pagination, and JSON format results. Bee also offers advanced functionalities like sharding, transactions, complex queries, and MongoDB ORM. The tool is designed for rapid application development in Java, offering faster development for Java Web and Spring Cloud microservices. The Enterprise Edition provides additional features like financial computing support, automatic value insertion, desensitization, dictionary value conversion, multi-tenancy, and more.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.
MarkLLM
MarkLLM is an open-source toolkit designed for watermarking technologies within large language models (LLMs). It simplifies access, understanding, and assessment of watermarking technologies, supporting various algorithms, visualization tools, and evaluation modules. The toolkit aids researchers and the community in ensuring the authenticity and origin of machine-generated text.
HuatuoGPT-o1
HuatuoGPT-o1 is a medical language model designed for advanced medical reasoning. It can identify mistakes, explore alternative strategies, and refine answers. The model leverages verifiable medical problems and a specialized medical verifier to guide complex reasoning trajectories and enhance reasoning through reinforcement learning. The repository provides access to models, data, and code for HuatuoGPT-o1, allowing users to deploy the model for medical reasoning tasks.
bee
Bee is an easy and high efficiency ORM framework that simplifies database operations by providing a simple interface and eliminating the need to write separate DAO code. It supports various features such as automatic filtering of properties, partial field queries, native statement pagination, JSON format results, sharding, multiple database support, and more. Bee also offers powerful functionalities like dynamic query conditions, transactions, complex queries, MongoDB ORM, cache management, and additional tools for generating distributed primary keys, reading Excel files, and more. The newest versions introduce enhancements like placeholder precompilation, default date sharding, ElasticSearch ORM support, and improved query capabilities.
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.
mem0
Mem0 is a tool that provides a smart, self-improving memory layer for Large Language Models, enabling personalized AI experiences across applications. It offers persistent memory for users, sessions, and agents, self-improving personalization, a simple API for easy integration, and cross-platform consistency. Users can store memories, retrieve memories, search for related memories, update memories, get the history of a memory, and delete memories using Mem0. It is designed to enhance AI experiences by enabling long-term memory storage and retrieval.
Scrapling
Scrapling is a high-performance, intelligent web scraping library for Python that automatically adapts to website changes while significantly outperforming popular alternatives. For both beginners and experts, Scrapling provides powerful features while maintaining simplicity. It offers features like fast and stealthy HTTP requests, adaptive scraping with smart element tracking and flexible selection, high performance with lightning-fast speed and memory efficiency, and developer-friendly navigation API and rich text processing. It also includes advanced parsing features like smart navigation, content-based selection, handling structural changes, and finding similar elements. Scrapling is designed to handle anti-bot protections and website changes effectively, making it a versatile tool for web scraping tasks.

gpustack
GPUStack is an open-source GPU cluster manager designed for running large language models (LLMs). It supports a wide variety of hardware, scales with GPU inventory, offers lightweight Python package with minimal dependencies, provides OpenAI-compatible APIs, simplifies user and API key management, enables GPU metrics monitoring, and facilitates token usage and rate metrics tracking. The tool is suitable for managing GPU clusters efficiently and effectively.
CrackSQL
CrackSQL is a powerful SQL dialect translation tool that integrates rule-based strategies with large language models (LLMs) for high accuracy. It enables seamless conversion between dialects (e.g., PostgreSQL → MySQL) with flexible access through Python API, command line, and web interface. The tool supports extensive dialect compatibility, precision & advanced processing, and versatile access & integration. It offers three modes for dialect translation and demonstrates high translation accuracy over collected benchmarks. Users can deploy CrackSQL using PyPI package installation or source code installation methods. The tool can be extended to support additional syntax, new dialects, and improve translation efficiency. The project is actively maintained and welcomes contributions from the community.

DB-GPT
DB-GPT is a personal database administrator that can solve database problems by reading documents, using various tools, and writing analysis reports. It is currently undergoing an upgrade. **Features:** * **Online Demo:** * Import documents into the knowledge base * Utilize the knowledge base for well-founded Q&A and diagnosis analysis of abnormal alarms * Send feedbacks to refine the intermediate diagnosis results * Edit the diagnosis result * Browse all historical diagnosis results, used metrics, and detailed diagnosis processes * **Language Support:** * English (default) * Chinese (add "language: zh" in config.yaml) * **New Frontend:** * Knowledgebase + Chat Q&A + Diagnosis + Report Replay * **Extreme Speed Version for localized llms:** * 4-bit quantized LLM (reducing inference time by 1/3) * vllm for fast inference (qwen) * Tiny LLM * **Multi-path extraction of document knowledge:** * Vector database (ChromaDB) * RESTful Search Engine (Elasticsearch) * **Expert prompt generation using document knowledge** * **Upgrade the LLM-based diagnosis mechanism:** * Task Dispatching -> Concurrent Diagnosis -> Cross Review -> Report Generation * Synchronous Concurrency Mechanism during LLM inference * **Support monitoring and optimization tools in multiple levels:** * Monitoring metrics (Prometheus) * Flame graph in code level * Diagnosis knowledge retrieval (dbmind) * Logical query transformations (Calcite) * Index optimization algorithms (for PostgreSQL) * Physical operator hints (for PostgreSQL) * Backup and Point-in-time Recovery (Pigsty) * **Continuously updated papers and experimental reports** This project is constantly evolving with new features. Don't forget to star ⭐ and watch 👀 to stay up to date.
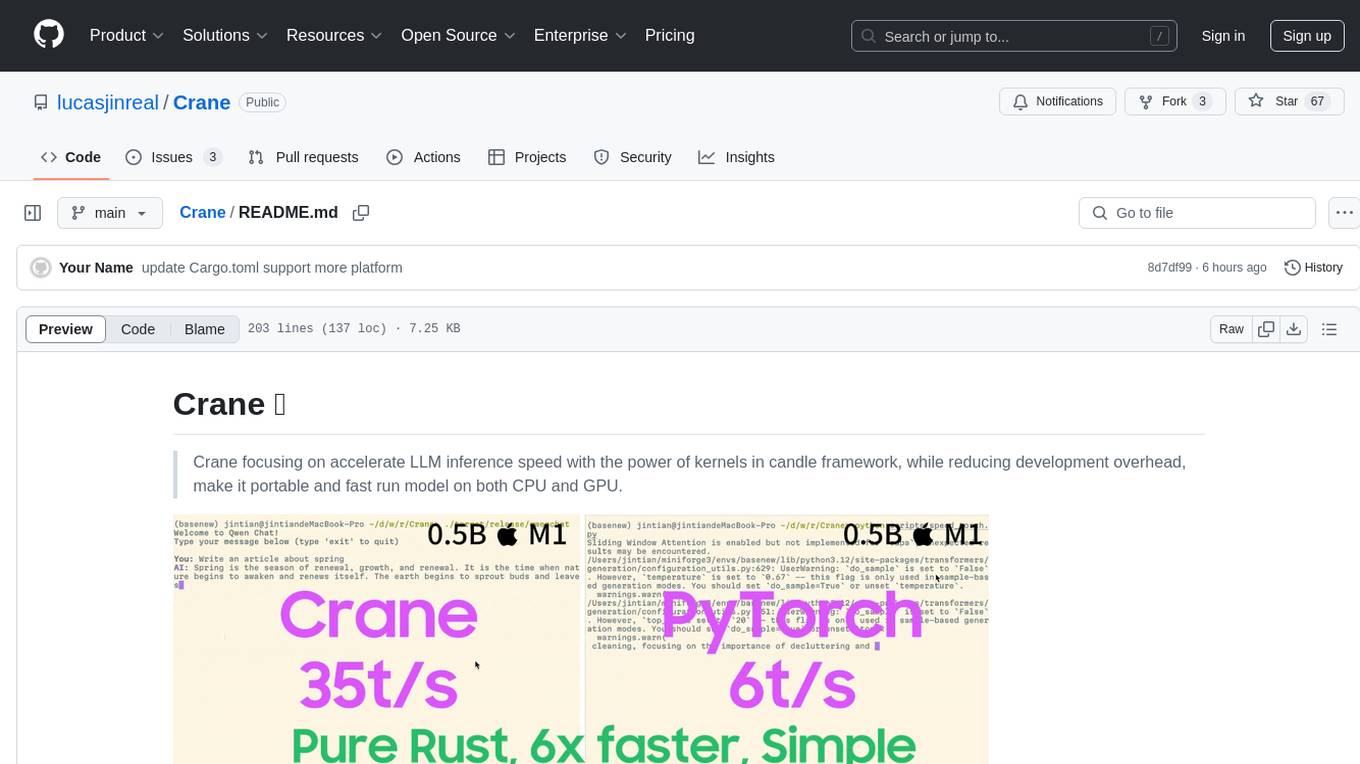
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.
For similar tasks
LLM4Decompile
LLM4Decompile is an open-source large language model dedicated to decompilation of Linux x86_64 binaries, supporting GCC's O0 to O3 optimization levels. It focuses on assessing re-executability of decompiled code through HumanEval-Decompile benchmark. The tool includes models with sizes ranging from 1.3 billion to 33 billion parameters, available on Hugging Face. Users can preprocess C code into binary and assembly instructions, then decompile assembly instructions into C using LLM4Decompile. Ongoing efforts aim to expand capabilities to support more architectures and configurations, integrate with decompilation tools like Ghidra and Rizin, and enhance performance with larger training datasets.
For similar jobs
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
LLM4Decompile
LLM4Decompile is an open-source large language model dedicated to decompilation of Linux x86_64 binaries, supporting GCC's O0 to O3 optimization levels. It focuses on assessing re-executability of decompiled code through HumanEval-Decompile benchmark. The tool includes models with sizes ranging from 1.3 billion to 33 billion parameters, available on Hugging Face. Users can preprocess C code into binary and assembly instructions, then decompile assembly instructions into C using LLM4Decompile. Ongoing efforts aim to expand capabilities to support more architectures and configurations, integrate with decompilation tools like Ghidra and Rizin, and enhance performance with larger training datasets.

mcp
Semgrep MCP Server is a beta server under active development for using Semgrep to scan code for security vulnerabilities. It provides a Model Context Protocol (MCP) for various coding tools to get specialized help in tasks. Users can connect to Semgrep AppSec Platform, scan code for vulnerabilities, customize Semgrep rules, analyze and filter scan results, and compare results. The tool is published on PyPI as semgrep-mcp and can be installed using pip, pipx, uv, poetry, or other methods. It supports CLI and Docker environments for running the server. Integration with VS Code is also available for quick installation. The project welcomes contributions and is inspired by core technologies like Semgrep and MCP, as well as related community projects and tools.
hound
Hound is a security audit automation pipeline for AI-assisted code review that mirrors how expert auditors think, learn, and collaborate. It features graph-driven analysis, sessionized audits, provider-agnostic models, belief system and hypotheses, precise code grounding, and adaptive planning. The system employs a senior/junior auditor pattern where the Scout actively navigates the codebase and annotates knowledge graphs while the Strategist handles high-level planning and vulnerability analysis. Hound is optimized for small-to-medium sized projects like smart contract applications and is language-agnostic.
Mirror-Flowers
Mirror Flowers is an out-of-the-box code security auditing tool that integrates local static scanning (line-level taint tracking + AST) with AI verification to help quickly discover and locate high-risk issues, providing repair suggestions. It supports multiple languages such as PHP, Python, JavaScript/TypeScript, and Java. The tool offers both single-file and project modes, with features like concurrent acceleration, integrated UI for visual results, and compatibility with multiple OpenAI interface providers. Users can configure the tool through environment variables or API, and can utilize it through a web UI or HTTP API for tasks like single-file auditing or project auditing.
Auditor
TheAuditor is an offline-first, AI-centric SAST & code intelligence platform designed to find security vulnerabilities, track data flow, analyze architecture, detect refactoring issues, run industry-standard tools, and produce AI-ready reports. It is specifically tailored for AI-assisted development workflows, providing verifiable ground truth for developers and AI assistants. The tool orchestrates verifiable data, focuses on AI consumption, and is extensible to support Python and Node.js ecosystems. The comprehensive analysis pipeline includes stages for foundation, concurrent analysis, and final aggregation, offering features like refactoring detection, dependency graph visualization, and optional insights analysis. The tool interacts with antivirus software to identify vulnerabilities, triggers performance impacts, and provides transparent information on common issues and troubleshooting. TheAuditor aims to address the lack of ground truth in AI development workflows and make AI development trustworthy by providing accurate security analysis and code verification.

autogen
AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
llama-recipes
The llama-recipes repository provides a scalable library for fine-tuning Llama 2, along with example scripts and notebooks to quickly get started with using the Llama 2 models in a variety of use-cases, including fine-tuning for domain adaptation and building LLM-based applications with Llama 2 and other tools in the LLM ecosystem. The examples here showcase how to run Llama 2 locally, in the cloud, and on-prem.