
trickPrompt-engine
AI engine for smart contract audit
Stars: 169
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
README:
2024.04.29:
- Add function to basiclly support rust language.
2024.05.16:
- Add support for cross-contract vulnerability confirmation, reduce the false positive rate approximately 50%.
- upadte the structure of the db
- add CN explaination
2024.05.18:
- Add prompt for check if result of vulnerability has assumations, reduce the false positive rate approximately 20%.
2024.06.01:
- Add support for python language, dont ask me why, so annoying.
2024.07.01
- Update the license
- Optimize code structure
- Add more language support
- Write usage documentation and code analysis
- Add command line mode for easy use
审计赏金成果:截止2024年5月,此工具已获得$60000+
Audit bounty results: As of May 2024, this tool has received $60,000+
- 优化代码结构
- 增加更多语言支持
- 编写使用文档和代码解析
- 增加命令行模式,方便使用
This is a vulnerability mining engine purely based on GPT, requiring no prior knowledge base, no fine-tuning, yet its effectiveness can overwhelmingly surpass most of the current related research.
The key lies in the design of prompts, which has shown excellent results. The core idea revolves around:
- Being task-driven, not question-driven.
- Driven by prompts, not by code.
- Focused on prompt design, not model design.
The essence is encapsulated in one word: "deception."
- This is a type of code understanding logic vulnerability mining that fully stimulates the capabilities of gpt. The control flow type vulnerability detection ability is ineffective and is suitable for real actual projects.
- Therefore, don’t run tests on meaningless academic vulnerabilities
Here's the translation into English:
Test Environment Setup
-
In the
src/main.pyfile, setswitch_production_or_testtotestto configure the environment in test mode. -
Place the project under the directory
src/dataset/agent-v1-c4. This structure is crucial for proper tool positioning and interaction with data. -
Refer to the configuration file
src/dataset/agent-v1-c4/datasets.jsonto set up your project collection. For example:
"StEverVault2":{
"path":"StEverVault",
"files":[
],
"functions":[]
}Where StEverVault2 represents the custom name of the project, matching the project_id in src/main.py. path refers to the actual path of the project under agent-v1-c4. files specifies the contract files to be scanned; if not configured, it defaults to scanning all files. functions specifies the specific function names to be scanned; if not configured, it defaults to scanning all functions, in the format [contract_name.function_name].
-
Use
src/db.sqlto create the database; PostgreSQL needs to be installed beforehand. -
Set up the
.envfile by creating it and filling in the following details to configure your environment:
# Database connection information
DATABASE_URL=postgresql://postgres:[email protected]:5432/postgres
# OpenAI API
OPENAI_API_BASE="apix.ai-gaochao.cn"
OPENAI_API_KEY=xxxxxx
# Model IDs
BUSINESS_FLOW_MODEL_ID=gpt-4-turbo
VUL_MODEL_ID=gpt-4-turbo
# Business flow scanning parameters
BUSINESS_FLOW_COUNT=10
SWITCH_FUNCTION_CODE=False
SWITCH_BUSINESS_CODE=True
Where:
-
DATABASE_URLis the database connection information. -
OPENAI_API_BASEis the GPT API connection information, usuallyapi.openai.com. -
OPENAI_API_KEYshould be set to your actual OpenAI API key. -
BUSINESS_FLOW_MODEL_IDandVUL_MODEL_IDare the IDs of the models used, recommended to usegpt-4-turbo. -
BUSINESS_FLOW_COUNTis the number of randomizations used to create variability, typically 7-20, commonly 10. -
SWITCH_FUNCTION_CODEandSWITCH_BUSINESS_CODEare the granularity settings during scanning, supporting function-level and business flow-level granularity.
- After configuring, run
main.pyto start the scanning process.
这是一个纯基于gpt的漏洞挖掘引擎,不需要任何前置知识库,不需要任何fine-tuning,但效果足可以碾压当前大部分相关研究的效果
核心关键在于prompt的设计,效果非常好
核心思路:
- task driven, not question driven
- 关键一个字在于“骗”
- 利用幻觉,喜欢幻觉
- 这是一种充分激发gpt能力的代码理解型的逻辑漏洞挖掘,控制流类型的漏洞检测能力效果差,适用于真正的实际项目
- 因此,不要拿那些无意义的学术型漏洞来跑测试
测试环境设置如下:
- 在
src/main.py文件中,将switch_production_or_test设置为test,以配置环境为测试模式。
if __name__ == '__main__':
switch_production_or_test = 'test' # prod / test
if switch_production_or_test == 'test':
# Your code for test environment-
将项目放置于
src/dataset/agent-v1-c4目录下,这一结构对于工具正确定位和与数据交互至关重要。 -
参照
src/dataset/agent-v1-c4/datasets.json配置文件来设置你的项目集。例如:
"StEverVault2":{
"path":"StEverVault",
"files":[
],
"functions":[]
}其中,StEverVault2 代表项目自定义名,它的名字与 src/main.py 中的 project_id 相同。path 指代的是 agent-v1-c4 下项目的具体实际路径。files 指代的是要具体扫描的合约文件,如果不配置,则默认扫描全部。functions 指代的是要具体扫描的函数名,如果不配置,则默认扫描全部函数,形式为【合约名.函数名】。
-
使用
src/db.sql创建数据库,需要提前安装 PostgreSQL。 -
设置
.env文件,通过创建.env文件并填写以下内容来配置你的环境:
# 数据库连接信息
DATABASE_URL=postgresql://postgres:[email protected]:5432/postgres
# OpenAI API
OPENAI_API_BASE="apix.ai-gaochao.cn"
OPENAI_API_KEY=xxxxxx
# 模型ID
BUSINESS_FLOW_MODEL_ID=gpt-4-turbo
VUL_MODEL_ID=gpt-4-turbo
# 业务流扫描参数
BUSINESS_FLOW_COUNT=10
SWITCH_FUNCTION_CODE=False
SWITCH_BUSINESS_CODE=True
其中:
-
DATABASE_URL为数据库连接信息。 -
OPENAI_API_BASE为 GPT API 连接信息,一般情况下为api.openai.com。 -
OPENAI_API_KEY设置为对应的 OpenAI API 密钥。 -
BUSINESS_FLOW_MODEL_ID和VUL_MODEL_ID为所使用的模型 ID,建议使用gpt-4-turbo。 -
BUSINESS_FLOW_COUNT为利用幻觉造成随机性时设置的随机次数,一般为 7-20,常用 10。 -
SWITCH_FUNCTION_CODE和SWITCH_BUSINESS_CODE为扫描时的粒度,支持函数粒度和业务流粒度。
-
配置完成后,运行
main.py即可开始扫描过程。 -
扫描时可能会因为网络原因或api原因中断,对于此已经整理成随时保存,不修改project_id的情况下可以重新运行main.py,可以继续扫描
-
唯一建议gpt4-turbo,不要用3.5,不要用4o,4o和3.5的推理能力是一样的,拉的一批
-
一般扫描时间为2-3小时,取决于项目大小和随机次数,中型项目+10次随机大约2个半小时
-
中型项目+10次随机大约需要20-30美金成本
-
当前还是有误报,按项目大小,大约30-65%,小项目误报会少一些,且还有很多自定义的东西,后续会继续优化
-
结果做了很多标记和中文解释
-
优先看result列中有【"result":"yes"】的(有时候是"result": "yes",带个空格)
-
category列优先筛选出【dont need In-project other contract】 的
-
具体的代码看business_flow_code列
-
代码位置看name列
- gpt4效果会更好,gpt3尚未深入尝试
- 这个tricky prompt理论上经过轻微变种,可以有效的扫描任何语言,但是尽量需要antlr相应语言的ast解析做支持,因为如果有code slicing,效果会更好
- 目前只支持solidity,后续会支持更多语言
刚刚release,还没写完,后续再补充
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for trickPrompt-engine
Similar Open Source Tools
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
cheating-based-prompt-engine
This is a vulnerability mining engine purely based on GPT, requiring no prior knowledge base, no fine-tuning, yet its effectiveness can overwhelmingly surpass most of the current related research. The core idea revolves around being task-driven, not question-driven, driven by prompts, not by code, and focused on prompt design, not model design. The essence is encapsulated in one word: deception. It is a type of code understanding logic vulnerability mining that fully stimulates the capabilities of GPT, suitable for real actual projects.
models.dev
Models.dev is an open-source database providing detailed specifications, pricing, and capabilities of various AI models. It serves as a centralized platform for accessing information on AI models, allowing users to contribute and utilize the data through an API. The repository contains data stored in TOML files, organized by provider and model, along with SVG logos. Users can contribute by adding new models following specific guidelines and submitting pull requests for validation. The project aims to maintain an up-to-date and comprehensive database of AI model information.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.

stark
STaRK is a large-scale semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. It provides natural-sounding and practical queries crafted to incorporate rich relational information and complex textual properties, closely mirroring real-life scenarios. The benchmark aims to assess how effectively large language models can handle the interplay between textual and relational requirements in queries, using three diverse knowledge bases constructed from public sources.

llm-vscode
llm-vscode is an extension designed for all things LLM, utilizing llm-ls as its backend. It offers features such as code completion with 'ghost-text' suggestions, the ability to choose models for code generation via HTTP requests, ensuring prompt size fits within the context window, and code attribution checks. Users can configure the backend, suggestion behavior, keybindings, llm-ls settings, and tokenization options. Additionally, the extension supports testing models like Code Llama 13B, Phind/Phind-CodeLlama-34B-v2, and WizardLM/WizardCoder-Python-34B-V1.0. Development involves cloning llm-ls, building it, and setting up the llm-vscode extension for use.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
forge
Forge is a powerful open-source tool for building modern web applications. It provides a simple and intuitive interface for developers to quickly scaffold and deploy projects. With Forge, you can easily create custom components, manage dependencies, and streamline your development workflow. Whether you are a beginner or an experienced developer, Forge offers a flexible and efficient solution for your web development needs.
k8sgpt
K8sGPT is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English. It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.
raycast_api_proxy
The Raycast AI Proxy is a tool that acts as a proxy for the Raycast AI application, allowing users to utilize the application without subscribing. It intercepts and forwards Raycast requests to various AI APIs, then reformats the responses for Raycast. The tool supports multiple AI providers and allows for custom model configurations. Users can generate self-signed certificates, add them to the system keychain, and modify DNS settings to redirect requests to the proxy. The tool is designed to work with providers like OpenAI, Azure OpenAI, Google, and more, enabling tasks such as AI chat completions, translations, and image generation.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.

chatgpt-subtitle-translator
This tool utilizes the OpenAI ChatGPT API to translate text, with a focus on line-based translation, particularly for SRT subtitles. It optimizes token usage by removing SRT overhead and grouping text into batches, allowing for arbitrary length translations without excessive token consumption while maintaining a one-to-one match between line input and output.

nano-graphrag
nano-GraphRAG is a simple, easy-to-hack implementation of GraphRAG that provides a smaller, faster, and cleaner version of the official implementation. It is about 800 lines of code, small yet scalable, asynchronous, and fully typed. The tool supports incremental insert, async methods, and various parameters for customization. Users can replace storage components and LLM functions as needed. It also allows for embedding function replacement and comes with pre-defined prompts for entity extraction and community reports. However, some features like covariates and global search implementation differ from the original GraphRAG. Future versions aim to address issues related to data source ID, community description truncation, and add new components.

swe-rl
SWE-RL is the official codebase for the paper 'SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution'. It is the first approach to scale reinforcement learning based LLM reasoning for real-world software engineering, leveraging open-source software evolution data and rule-based rewards. The code provides prompt templates and the implementation of the reward function based on sequence similarity. Agentless Mini, a part of SWE-RL, builds on top of Agentless with improvements like fast async inference, code refactoring for scalability, and support for using multiple reproduction tests for reranking. The tool can be used for localization, repair, and reproduction test generation in software engineering tasks.
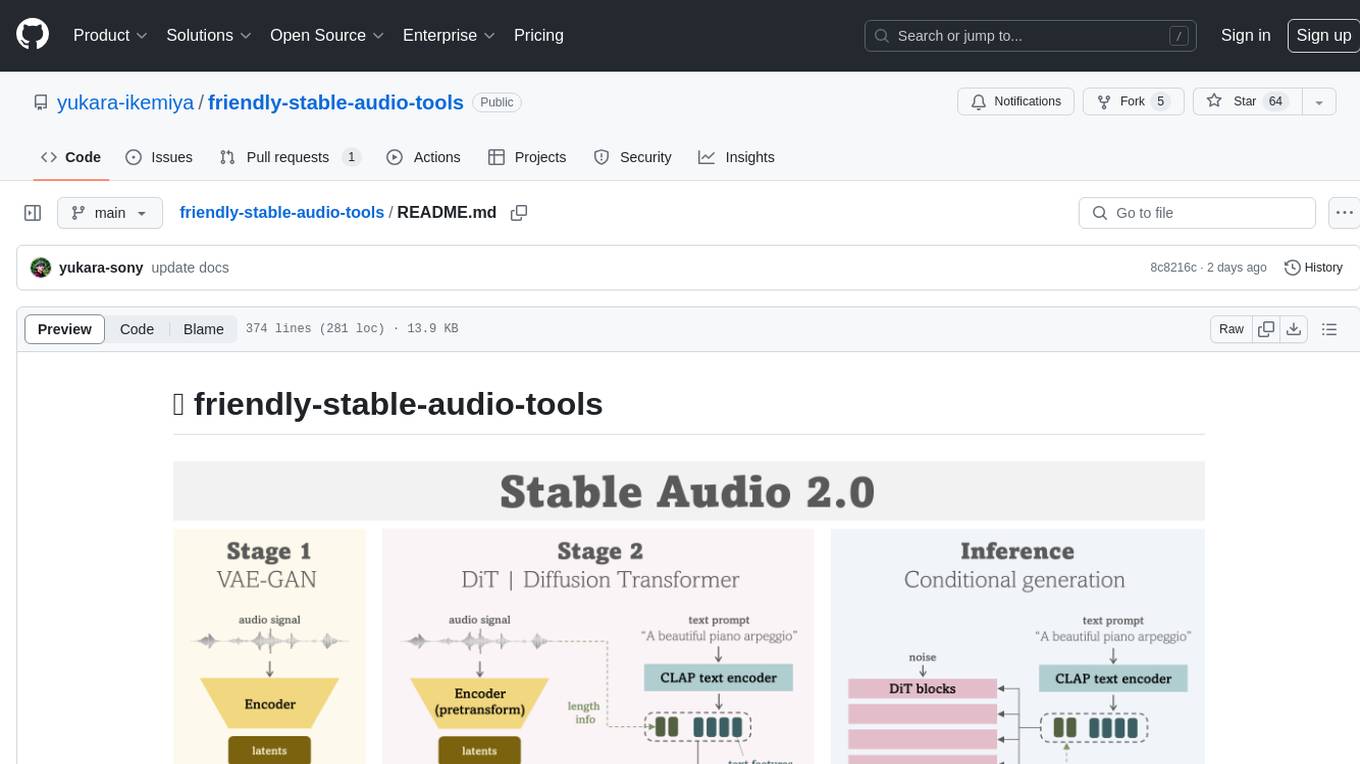
friendly-stable-audio-tools
This repository is a refactored and updated version of `stable-audio-tools`, an open-source code for audio/music generative models originally by Stability AI. It contains refactored codes for improved readability and usability, useful scripts for evaluating and playing with trained models, and instructions on how to train models such as `Stable Audio 2.0`. The repository does not contain any pretrained checkpoints. Requirements include PyTorch 2.0 or later for Flash Attention support and Python 3.8.10 or later for development. The repository provides guidance on installing, building a training environment using Docker or Singularity, logging with Weights & Biases, training configurations, and stages for VAE-GAN and Diffusion Transformer (DiT) training.
For similar tasks
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
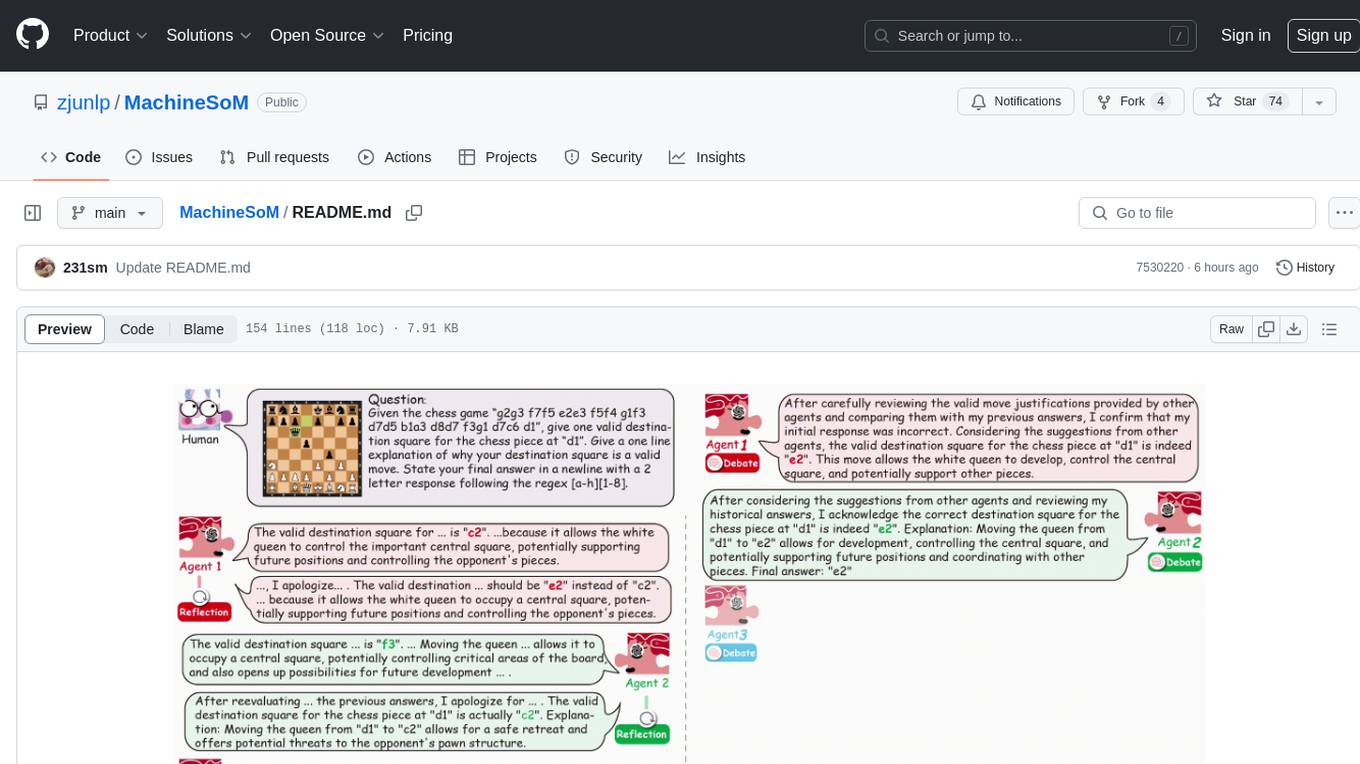
MachineSoM
MachineSoM is a code repository for the paper 'Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View'. It focuses on the emergence of intelligence from collaborative and communicative computational modules, enabling effective completion of complex tasks. The repository includes code for societies of LLM agents with different traits, collaboration processes such as debate and self-reflection, and interaction strategies for determining when and with whom to interact. It provides a coding framework compatible with various inference services like Replicate, OpenAI, Dashscope, and Anyscale, supporting models like Qwen and GPT. Users can run experiments, evaluate results, and draw figures based on the paper's content, with available datasets for MMLU, Math, and Chess Move Validity.
comfyui
ComfyUI is a highly-configurable, cloud-first AI-Dock container that allows users to run ComfyUI without bundled models or third-party configurations. Users can configure the container using provisioning scripts. The Docker image supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with version tags for different configurations. Additional environment variables and Python environments are provided for customization. ComfyUI service runs on port 8188 and can be managed using supervisorctl. The tool also includes an API wrapper service and pre-configured templates for Vast.ai. The author may receive compensation for services linked in the documentation.

pyrfuniverse
pyrfuniverse is a python package used to interact with RFUniverse simulation environment. It is developed with reference to ML-Agents and produce new features. The package allows users to work with RFUniverse for simulation purposes, providing tools and functionalities to interact with the environment and create new features.
intentkit
IntentKit is an autonomous agent framework that enables the creation and management of AI agents with capabilities including blockchain interactions, social media management, and custom skill integration. It supports multiple agents, autonomous agent management, blockchain integration, social media integration, extensible skill system, and plugin system. The project is in alpha stage and not recommended for production use. It provides quick start guides for Docker and local development, integrations with Twitter and Coinbase, configuration options using environment variables or AWS Secrets Manager, project structure with core application code, entry points, configuration management, database models, skills, skill sets, and utility functions. Developers can add new skills by creating, implementing, and registering them in the skill directory.
pear-landing-page
PearAI Landing Page is an open-source AI-powered code editor managed by Nang and Pan. It is built with Next.js, Vercel, Tailwind CSS, and TypeScript. The project requires setting up environment variables for proper configuration. Users can run the project locally by starting the development server and visiting the specified URL in the browser. Recommended extensions include Prettier, ESLint, and JavaScript and TypeScript Nightly. Contributions to the project are welcomed and appreciated.
webapp-starter
webapp-starter is a modern full-stack application template built with Turborepo, featuring a Hono + Bun API backend and Next.js frontend. It provides an easy way to build a SaaS product. The backend utilizes technologies like Bun, Drizzle ORM, and Supabase, while the frontend is built with Next.js, Tailwind CSS, Shadcn/ui, and Clerk. Deployment can be done using Vercel and Render. The project structure includes separate directories for API backend and Next.js frontend, along with shared packages for the main database. Setup involves installing dependencies, configuring environment variables, and setting up services like Bun, Supabase, and Clerk. Development can be done using 'turbo dev' command, and deployment instructions are provided for Vercel and Render. Contributions are welcome through pull requests.
hayhooks
Hayhooks is a tool that simplifies the deployment and serving of Haystack pipelines as REST APIs. It allows users to wrap their pipelines with custom logic and expose them via HTTP endpoints, including OpenAI-compatible chat completion endpoints. With Hayhooks, users can easily convert their Haystack pipelines into API services with minimal boilerplate code.
For similar jobs
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
LLM4Decompile
LLM4Decompile is an open-source large language model dedicated to decompilation of Linux x86_64 binaries, supporting GCC's O0 to O3 optimization levels. It focuses on assessing re-executability of decompiled code through HumanEval-Decompile benchmark. The tool includes models with sizes ranging from 1.3 billion to 33 billion parameters, available on Hugging Face. Users can preprocess C code into binary and assembly instructions, then decompile assembly instructions into C using LLM4Decompile. Ongoing efforts aim to expand capabilities to support more architectures and configurations, integrate with decompilation tools like Ghidra and Rizin, and enhance performance with larger training datasets.

mcp
Semgrep MCP Server is a beta server under active development for using Semgrep to scan code for security vulnerabilities. It provides a Model Context Protocol (MCP) for various coding tools to get specialized help in tasks. Users can connect to Semgrep AppSec Platform, scan code for vulnerabilities, customize Semgrep rules, analyze and filter scan results, and compare results. The tool is published on PyPI as semgrep-mcp and can be installed using pip, pipx, uv, poetry, or other methods. It supports CLI and Docker environments for running the server. Integration with VS Code is also available for quick installation. The project welcomes contributions and is inspired by core technologies like Semgrep and MCP, as well as related community projects and tools.
hound
Hound is a security audit automation pipeline for AI-assisted code review that mirrors how expert auditors think, learn, and collaborate. It features graph-driven analysis, sessionized audits, provider-agnostic models, belief system and hypotheses, precise code grounding, and adaptive planning. The system employs a senior/junior auditor pattern where the Scout actively navigates the codebase and annotates knowledge graphs while the Strategist handles high-level planning and vulnerability analysis. Hound is optimized for small-to-medium sized projects like smart contract applications and is language-agnostic.
Mirror-Flowers
Mirror Flowers is an out-of-the-box code security auditing tool that integrates local static scanning (line-level taint tracking + AST) with AI verification to help quickly discover and locate high-risk issues, providing repair suggestions. It supports multiple languages such as PHP, Python, JavaScript/TypeScript, and Java. The tool offers both single-file and project modes, with features like concurrent acceleration, integrated UI for visual results, and compatibility with multiple OpenAI interface providers. Users can configure the tool through environment variables or API, and can utilize it through a web UI or HTTP API for tasks like single-file auditing or project auditing.
Auditor
TheAuditor is an offline-first, AI-centric SAST & code intelligence platform designed to find security vulnerabilities, track data flow, analyze architecture, detect refactoring issues, run industry-standard tools, and produce AI-ready reports. It is specifically tailored for AI-assisted development workflows, providing verifiable ground truth for developers and AI assistants. The tool orchestrates verifiable data, focuses on AI consumption, and is extensible to support Python and Node.js ecosystems. The comprehensive analysis pipeline includes stages for foundation, concurrent analysis, and final aggregation, offering features like refactoring detection, dependency graph visualization, and optional insights analysis. The tool interacts with antivirus software to identify vulnerabilities, triggers performance impacts, and provides transparent information on common issues and troubleshooting. TheAuditor aims to address the lack of ground truth in AI development workflows and make AI development trustworthy by providing accurate security analysis and code verification.
hackingBuddyGPT
hackingBuddyGPT is a framework for testing LLM-based agents for security testing. It aims to create common ground truth by creating common security testbeds and benchmarks, evaluating multiple LLMs and techniques against those, and publishing prototypes and findings as open-source/open-access reports. The initial focus is on evaluating the efficiency of LLMs for Linux privilege escalation attacks, but the framework is being expanded to evaluate the use of LLMs for web penetration-testing and web API testing. hackingBuddyGPT is released as open-source to level the playing field for blue teams against APTs that have access to more sophisticated resources.
aio-proxy
This script automates setting up TUIC, hysteria and other proxy-related tools in Linux. It features setting domains, getting SSL certification, setting up a simple web page, SmartSNI by Bepass, Chisel Tunnel, Hysteria V2, Tuic, Hiddify Reality Scanner, SSH, Telegram Proxy, Reverse TLS Tunnel, different panels, installing, disabling, and enabling Warp, Sing Box 4-in-1 script, showing ports in use and their corresponding processes, and an Android script to use Chisel tunnel.