
hayhooks
Easily deploy Haystack pipelines as REST APIs and MCP Tools.
Stars: 136
Hayhooks is a tool that simplifies the deployment and serving of Haystack pipelines as REST APIs. It allows users to wrap their pipelines with custom logic and expose them via HTTP endpoints, including OpenAI-compatible chat completion endpoints. With Hayhooks, users can easily convert their Haystack pipelines into API services with minimal boilerplate code.
README:
Hayhooks makes it easy to deploy and serve Haystack Pipelines and Agents.
With Hayhooks, you can:
- 📦 Deploy your Haystack pipelines and agents as REST APIs with maximum flexibility and minimal boilerplate code.
- 🛠️ Expose your Haystack pipelines and agents over the MCP protocol, making them available as tools in AI dev environments like Cursor or Claude Desktop. Under the hood, Hayhooks runs as an MCP Server, exposing each pipeline and agent as an MCP Tool.
- 💬 Integrate your Haystack pipelines and agents with Open WebUI as OpenAI-compatible chat completion backends with streaming support.
- 🕹️ Control Hayhooks core API endpoints through chat - deploy, undeploy, list, or run Haystack pipelines and agents by chatting with Claude Desktop, Cursor, or any other MCP client.


![]()
![]()
📚 For detailed guides, examples, and API reference, check out our comprehensive documentation.
# Install Hayhooks
pip install hayhookshayhooks runCreate a minimal agent wrapper with streaming chat support and a simple HTTP POST API:
from typing import AsyncGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
from haystack.tools import Tool
from haystack.components.generators.chat import OpenAIChatGenerator
from hayhooks import BasePipelineWrapper, async_streaming_generator
# Define a Haystack Tool that provides weather information for a given location.
def weather_function(location):
return f"The weather in {location} is sunny."
weather_tool = Tool(
name="weather_tool",
description="Provides weather information for a given location.",
parameters={
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"],
},
function=weather_function,
)
class PipelineWrapper(BasePipelineWrapper):
def setup(self) -> None:
self.agent = Agent(
chat_generator=OpenAIChatGenerator(model="gpt-4o-mini"),
system_prompt="You're a helpful agent",
tools=[weather_tool],
)
# This will create a POST /my_agent/run endpoint
# `question` will be the input argument and will be auto-validated by a Pydantic model
async def run_api_async(self, question: str) -> str:
result = await self.agent.run_async({"messages": [ChatMessage.from_user(question)]})
return result["replies"][0].text
# This will create an OpenAI-compatible /chat/completions endpoint
async def run_chat_completion_async(
self, model: str, messages: list[dict], body: dict
) -> AsyncGenerator[str, None]:
chat_messages = [
ChatMessage.from_openai_dict_format(message) for message in messages
]
return async_streaming_generator(
pipeline=self.agent,
pipeline_run_args={
"messages": chat_messages,
},
)Save as my_agent_dir/pipeline_wrapper.py.
hayhooks pipeline deploy-files -n my_agent ./my_agent_dirCall the HTTP POST API (/my_agent/run):
curl -X POST http://localhost:1416/my_agent/run \
-H 'Content-Type: application/json' \
-d '{"question": "What can you do?"}'Call the OpenAI-compatible chat completion API (streaming enabled):
curl -X POST http://localhost:1416/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "my_agent",
"messages": [{"role": "user", "content": "What can you do?"}]
}'Or integrate it with Open WebUI and start chatting with it!
- Deploy Haystack pipelines and agents as REST APIs with minimal setup
- Support for both YAML-based and wrapper-based pipeline deployment
- Automatic OpenAI-compatible endpoint generation
- MCP Protocol: Expose pipelines as MCP tools for use in AI development environments
- Open WebUI Integration: Use Hayhooks as a backend for Open WebUI with streaming support
- OpenAI Compatibility: Seamless integration with OpenAI-compatible tools and frameworks
- CLI for easy pipeline management
- Flexible configuration options
- Comprehensive logging and debugging support
- Custom route and middleware support
- Built-in support for handling file uploads in pipelines
- Perfect for RAG systems and document processing
- Quick Start Guide - Get started with Hayhooks
- Installation - Install Hayhooks and dependencies
- Configuration - Configure Hayhooks for your needs
- Examples - Explore example implementations
- GitHub: deepset-ai/hayhooks
- Issues: GitHub Issues
- Documentation: Full Documentation
Hayhooks is actively maintained by the deepset team.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hayhooks
Similar Open Source Tools
hayhooks
Hayhooks is a tool that simplifies the deployment and serving of Haystack pipelines as REST APIs. It allows users to wrap their pipelines with custom logic and expose them via HTTP endpoints, including OpenAI-compatible chat completion endpoints. With Hayhooks, users can easily convert their Haystack pipelines into API services with minimal boilerplate code.

sdk-typescript
Strands Agents - TypeScript SDK is a lightweight and flexible SDK that takes a model-driven approach to building and running AI agents in TypeScript/JavaScript. It brings key features from the Python Strands framework to Node.js environments, enabling type-safe agent development for various applications. The SDK supports model agnostic development with first-class support for Amazon Bedrock and OpenAI, along with extensible architecture for custom providers. It also offers built-in MCP support, real-time response streaming, extensible hooks, and conversation management features. With tools for interaction with external systems and seamless integration with MCP servers, the SDK provides a comprehensive solution for developing AI agents.
CyberStrikeAI
CyberStrikeAI is an AI-native security testing platform built in Go that integrates 100+ security tools, an intelligent orchestration engine, role-based testing with predefined security roles, a skills system with specialized testing skills, and comprehensive lifecycle management capabilities. It enables end-to-end automation from conversational commands to vulnerability discovery, attack-chain analysis, knowledge retrieval, and result visualization, delivering an auditable, traceable, and collaborative testing environment for security teams. The platform features an AI decision engine with OpenAI-compatible models, native MCP implementation with various transports, prebuilt tool recipes, large-result pagination, attack-chain graph, password-protected web UI, knowledge base with vector search, vulnerability management, batch task management, role-based testing, and skills system.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
tingly-box
Tingly Box is a tool that helps in deciding which model to call, compressing context, and routing requests efficiently. It offers secure, reliable, and customizable functional extensions. With features like unified API, smart routing, context compression, auto API translation, blazing fast performance, flexible authentication, visual control panel, and client-side usage stats, Tingly Box provides a comprehensive solution for managing AI models and tokens. It supports integration with various IDEs, CLI tools, SDKs, and AI applications, making it versatile and easy to use. The tool also allows seamless integration with OAuth providers like Claude Code, enabling users to utilize existing quotas in OpenAI-compatible tools. Tingly Box aims to simplify AI model management and usage by providing a single endpoint for multiple providers with minimal configuration, promoting seamless integration with SDKs and CLI tools.
code_puppy
Code Puppy is an AI-powered code generation agent designed to understand programming tasks, generate high-quality code, and explain its reasoning. It supports multi-language code generation, interactive CLI, and detailed code explanations. The tool requires Python 3.9+ and API keys for various models like GPT, Google's Gemini, Cerebras, and Claude. It also integrates with MCP servers for advanced features like code search and documentation lookups. Users can create custom JSON agents for specialized tasks and access a variety of tools for file management, code execution, and reasoning sharing.
rag-chat
The `@upstash/rag-chat` package simplifies the development of retrieval-augmented generation (RAG) chat applications by providing Next.js compatibility with streaming support, built-in vector store, optional Redis compatibility for fast chat history management, rate limiting, and disableRag option. Users can easily set up the environment variables and initialize RAGChat to interact with AI models, manage knowledge base, chat history, and enable debugging features. Advanced configuration options allow customization of RAGChat instance with built-in rate limiting, observability via Helicone, and integration with Next.js route handlers and Vercel AI SDK. The package supports OpenAI models, Upstash-hosted models, and custom providers like TogetherAi and Replicate.
hyper-mcp
hyper-mcp is a fast and secure MCP server that extends its capabilities through WebAssembly plugins. It makes it easy to add AI capabilities to applications by allowing users to write plugins in any language that compiles to WebAssembly, distribute them via standard OCI registries, and run them anywhere from cloud to edge. The tool is built with a security-first mindset, offering sandboxed plugins, memory-safe execution, secure plugin distribution, and fine-grained access control for host functions. Users can deploy hyper-mcp anywhere, benefit from cross-platform compatibility, and prevent tool name collisions with the support tool name prefix feature.
inferable
Inferable is an open source platform that helps users build reliable LLM-powered agentic automations at scale. It offers a managed agent runtime, durable tool calling, zero network configuration, multiple language support, and is fully open source under the MIT license. Users can define functions, register them with Inferable, and create runs that utilize these functions to automate tasks. The platform supports Node.js/TypeScript, Go, .NET, and React, and provides SDKs, core services, and bootstrap templates for various languages.
orra
Orra is a tool for building production-ready multi-agent applications that handle complex real-world interactions. It coordinates tasks across existing stack, agents, and tools run as services using intelligent reasoning. With features like smart pre-evaluated execution plans, domain grounding, durable execution, and automatic service health monitoring, Orra enables users to go fast with tools as services and revert state to handle failures. It provides real-time status tracking and webhook result delivery, making it ideal for developers looking to move beyond simple crews and agents.
g4f.dev
G4f.dev is the official documentation hub for GPT4Free, a free and convenient AI tool with endpoints that can be integrated directly into apps, scripts, and web browsers. The documentation provides clear overviews, quick examples, and deeper insights into the major features of GPT4Free, including text and image generation. Users can choose between Python and JavaScript for installation and setup, and can access various API endpoints, providers, models, and client options for different tasks.

InsForge
InsForge is a backend development platform designed for AI coding agents and AI code editors. It serves as a semantic layer that enables agents to interact with backend primitives such as databases, authentication, storage, and functions in a meaningful way. The platform allows agents to fetch backend context, configure primitives, and inspect backend state through structured schemas. InsForge facilitates backend context engineering for AI coding agents to understand, operate, and monitor backend systems effectively.
rigging
Rigging is a lightweight LLM framework designed to simplify the usage of language models in production code. It offers structured Pydantic models for text output, supports various models like LiteLLM and transformers, and provides features such as defining prompts as python functions, simple tool use, storing models as connection strings, async batching for large scale generation, and modern Python support with type hints and async capabilities. Rigging is developed by dreadnode and is suitable for tasks like building chat pipelines, running completions, tracking behavior with tracing, playing with generation parameters, and scaling up with iterating and batching.
llamactl
llamactl is a tool for unified management and routing of llama.cpp, MLX, and vLLM models with a web dashboard. It offers easy model management with built-in model downloader, dynamic multi-model instances, smart resource management, and a modern React UI dashboard. It provides flexible integration with API compatibility for OpenAI chat completions and resources endpoints, multi-backend support, and Docker readiness. The tool supports distributed deployment with remote instances and central management. Users can quickly start by installing a backend, downloading llamactl, creating an instance, and starting inferencing.
codemie-code
Unified AI Coding Assistant CLI for managing multiple AI agents like Claude Code, Google Gemini, OpenCode, and custom AI agents. Supports OpenAI, Azure OpenAI, AWS Bedrock, LiteLLM, Ollama, and Enterprise SSO. Features built-in LangGraph agent with file operations, command execution, and planning tools. Cross-platform support for Windows, Linux, and macOS. Ideal for developers seeking a powerful alternative to GitHub Copilot or Cursor.

chat
deco.chat is an open-source foundation for building AI-native software, providing developers, engineers, and AI enthusiasts with robust tools to rapidly prototype, develop, and deploy AI-powered applications. It empowers Vibecoders to prototype ideas and Agentic engineers to deploy scalable, secure, and sustainable production systems. The core capabilities include an open-source runtime for composing tools and workflows, MCP Mesh for secure integration of models and APIs, a unified TypeScript stack for backend logic and custom frontends, global modular infrastructure built on Cloudflare, and a visual workspace for building agents and orchestrating everything in code.
For similar tasks
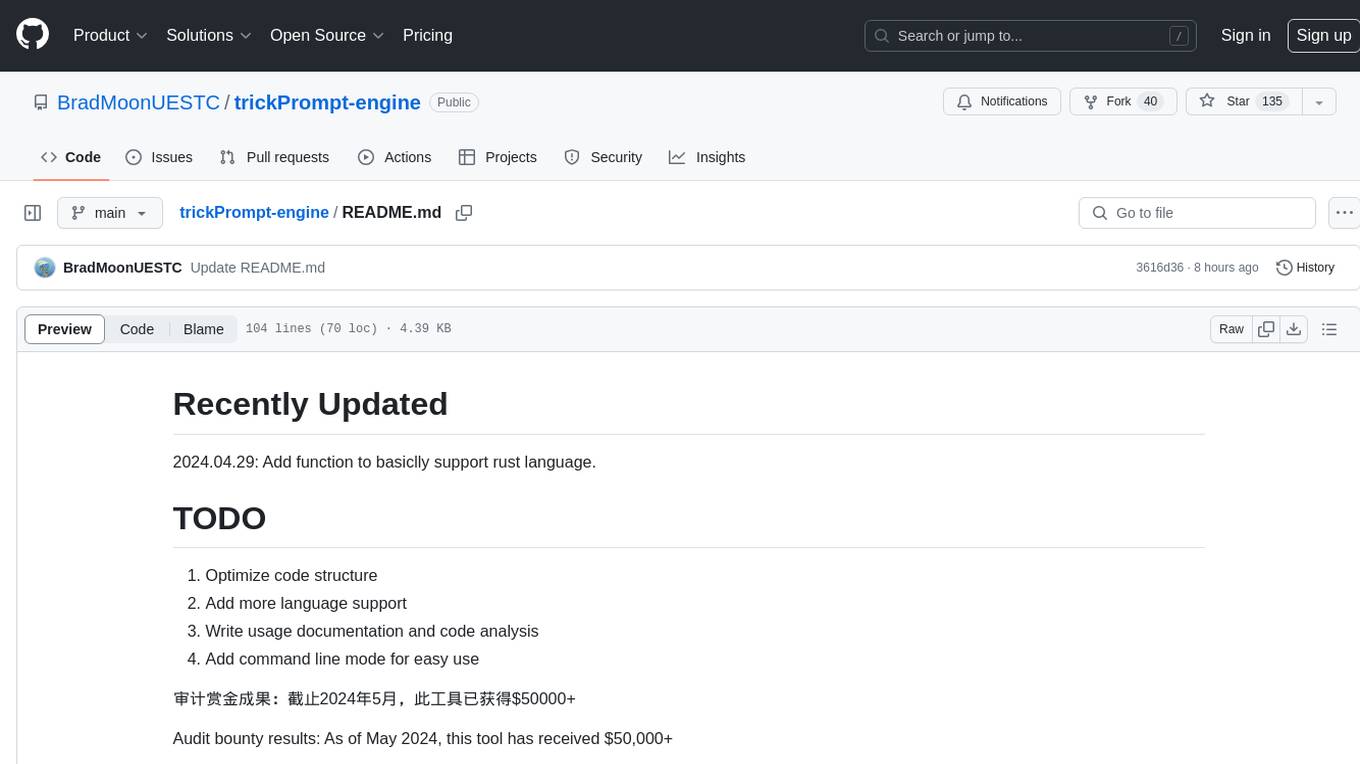
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
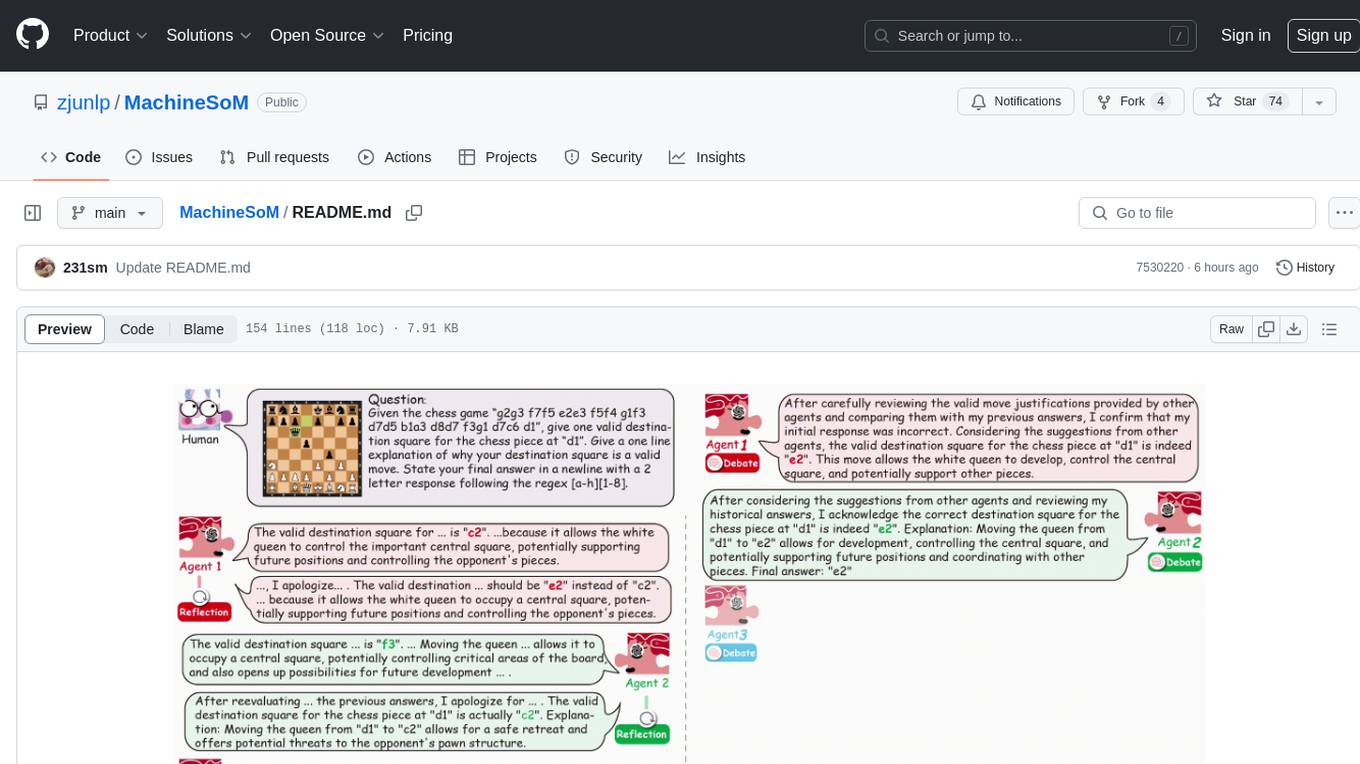
MachineSoM
MachineSoM is a code repository for the paper 'Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View'. It focuses on the emergence of intelligence from collaborative and communicative computational modules, enabling effective completion of complex tasks. The repository includes code for societies of LLM agents with different traits, collaboration processes such as debate and self-reflection, and interaction strategies for determining when and with whom to interact. It provides a coding framework compatible with various inference services like Replicate, OpenAI, Dashscope, and Anyscale, supporting models like Qwen and GPT. Users can run experiments, evaluate results, and draw figures based on the paper's content, with available datasets for MMLU, Math, and Chess Move Validity.
comfyui
ComfyUI is a highly-configurable, cloud-first AI-Dock container that allows users to run ComfyUI without bundled models or third-party configurations. Users can configure the container using provisioning scripts. The Docker image supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with version tags for different configurations. Additional environment variables and Python environments are provided for customization. ComfyUI service runs on port 8188 and can be managed using supervisorctl. The tool also includes an API wrapper service and pre-configured templates for Vast.ai. The author may receive compensation for services linked in the documentation.

pyrfuniverse
pyrfuniverse is a python package used to interact with RFUniverse simulation environment. It is developed with reference to ML-Agents and produce new features. The package allows users to work with RFUniverse for simulation purposes, providing tools and functionalities to interact with the environment and create new features.
intentkit
IntentKit is an autonomous agent framework that enables the creation and management of AI agents with capabilities including blockchain interactions, social media management, and custom skill integration. It supports multiple agents, autonomous agent management, blockchain integration, social media integration, extensible skill system, and plugin system. The project is in alpha stage and not recommended for production use. It provides quick start guides for Docker and local development, integrations with Twitter and Coinbase, configuration options using environment variables or AWS Secrets Manager, project structure with core application code, entry points, configuration management, database models, skills, skill sets, and utility functions. Developers can add new skills by creating, implementing, and registering them in the skill directory.
pear-landing-page
PearAI Landing Page is an open-source AI-powered code editor managed by Nang and Pan. It is built with Next.js, Vercel, Tailwind CSS, and TypeScript. The project requires setting up environment variables for proper configuration. Users can run the project locally by starting the development server and visiting the specified URL in the browser. Recommended extensions include Prettier, ESLint, and JavaScript and TypeScript Nightly. Contributions to the project are welcomed and appreciated.
webapp-starter
webapp-starter is a modern full-stack application template built with Turborepo, featuring a Hono + Bun API backend and Next.js frontend. It provides an easy way to build a SaaS product. The backend utilizes technologies like Bun, Drizzle ORM, and Supabase, while the frontend is built with Next.js, Tailwind CSS, Shadcn/ui, and Clerk. Deployment can be done using Vercel and Render. The project structure includes separate directories for API backend and Next.js frontend, along with shared packages for the main database. Setup involves installing dependencies, configuring environment variables, and setting up services like Bun, Supabase, and Clerk. Development can be done using 'turbo dev' command, and deployment instructions are provided for Vercel and Render. Contributions are welcome through pull requests.
hayhooks
Hayhooks is a tool that simplifies the deployment and serving of Haystack pipelines as REST APIs. It allows users to wrap their pipelines with custom logic and expose them via HTTP endpoints, including OpenAI-compatible chat completion endpoints. With Hayhooks, users can easily convert their Haystack pipelines into API services with minimal boilerplate code.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.