
comfyui
ComfyUI docker images for use in GPU cloud and local environments. Includes AI-Dock base for authentication and improved user experience.
Stars: 434
ComfyUI is a highly-configurable, cloud-first AI-Dock container that allows users to run ComfyUI without bundled models or third-party configurations. Users can configure the container using provisioning scripts. The Docker image supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with version tags for different configurations. Additional environment variables and Python environments are provided for customization. ComfyUI service runs on port 8188 and can be managed using supervisorctl. The tool also includes an API wrapper service and pre-configured templates for Vast.ai. The author may receive compensation for services linked in the documentation.
README:
![]()
Run ComfyUI in a highly-configurable, cloud-first AI-Dock container.
[!NOTE] These images do not bundle models or third-party configurations. You should use a provisioning script to automatically configure your container. You can find examples in
config/provisioning.
All AI-Dock containers share a common base which is designed to make running on cloud services such as vast.ai as straightforward and user friendly as possible.
Common features and options are documented in the base wiki but any additional features unique to this image will be detailed below.
The :latest tag points to :latest-cuda and will relate to a stable and tested version. There may be more recent builds
Tags follow these patterns:
:cuda-[x.x.x-base|runtime]-[ubuntu-version]
:rocm-[x.x.x-runtime]-[ubuntu-version]
:cpu-[ubuntu-version]
Browse ghcr.io for an image suitable for your target environment. Alternatively, view a select range of CUDA and ROCm builds at DockerHub.
Supported Platforms: NVIDIA CUDA, AMD ROCm, CPU
| Variable | Description |
|---|---|
AUTO_UPDATE |
Update ComfyUI on startup (default false) |
CIVITAI_TOKEN |
Authenticate download requests from Civitai - Required for gated models |
COMFYUI_BRANCH |
ComfyUI branch/commit hash for auto update (default master) |
COMFYUI_ARGS |
Startup flags. eg. --gpu-only --highvram
|
COMFYUI_PORT_HOST |
ComfyUI interface port (default 8188) |
COMFYUI_URL |
Override $DIRECT_ADDRESS:port with URL for ComfyUI |
HF_TOKEN |
Authenticate download requests from HuggingFace - Required for gated models (SD3, FLUX, etc.) |
See the base environment variables here for more configuration options.
| Environment | Packages |
|---|---|
comfyui |
ComfyUI and dependencies |
api |
ComfyUI API wrapper and dependencies |
The comfyui environment will be activated on shell login.
See the base micromamba environments here.
The following services will be launched alongside the default services provided by the base image.
The service will launch on port 8188 unless you have specified an override with COMFYUI_PORT_HOST.
You can set startup flags by using variable COMFYUI_ARGS.
To manage this service you can use supervisorctl [start|stop|restart] comfyui.
This service is available on port 8188 and is a work-in-progress to replace previous serverless handlers which have been depreciated; Old Docker images and sources remain available should you need them.
You can access the api directly at /ai-dock/api/ or you can use the Swager/openAPI playground at /ai-dock/api/docs.
[!NOTE] All services are password protected by default. See the security and environment variables documentation for more information.
Vast.ai
The author (@robballantyne) may be compensated if you sign up to services linked in this document. Testing multiple variants of GPU images in many different environments is both costly and time-consuming; This helps to offset costs
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for comfyui
Similar Open Source Tools
comfyui
ComfyUI is a highly-configurable, cloud-first AI-Dock container that allows users to run ComfyUI without bundled models or third-party configurations. Users can configure the container using provisioning scripts. The Docker image supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with version tags for different configurations. Additional environment variables and Python environments are provided for customization. ComfyUI service runs on port 8188 and can be managed using supervisorctl. The tool also includes an API wrapper service and pre-configured templates for Vast.ai. The author may receive compensation for services linked in the documentation.
stable-diffusion-webui
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
llm2sh
llm2sh is a command-line utility that leverages Large Language Models (LLMs) to translate plain-language requests into shell commands. It provides a convenient way to interact with your system using natural language. The tool supports multiple LLMs for command generation, offers a customizable configuration file, YOLO mode for running commands without confirmation, and is easily extensible with new LLMs and system prompts. Users can set up API keys for OpenAI, Claude, Groq, and Cerebras to use the tool effectively. llm2sh does not store user data or command history, and it does not record or send telemetry by itself, but the LLM APIs may collect and store requests and responses for their purposes.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.

agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.
moly
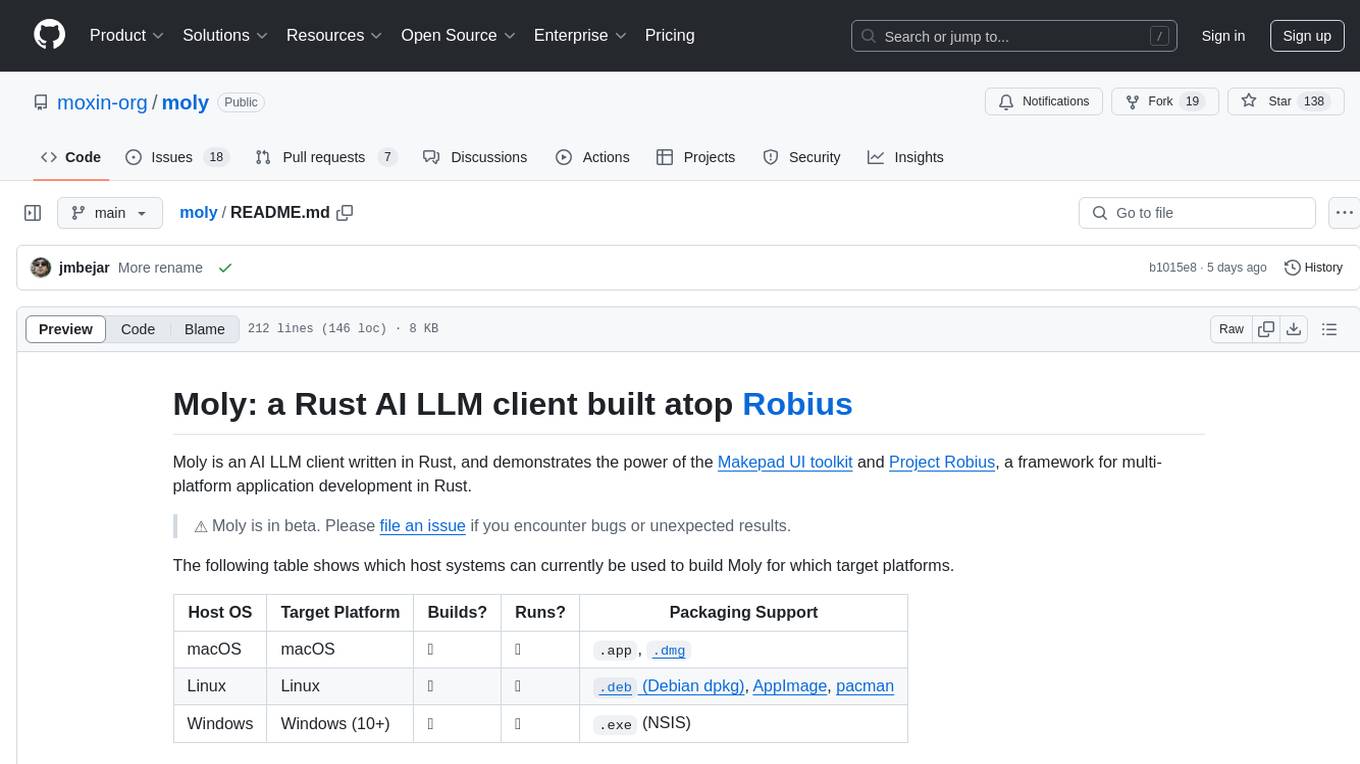
Moly is an AI LLM client written in Rust, showcasing the capabilities of the Makepad UI toolkit and Project Robius, a framework for multi-platform application development in Rust. It is currently in beta, allowing users to build and run Moly on macOS, Linux, and Windows. The tool provides packaging support for different platforms, such as `.app`, `.dmg`, `.deb`, AppImage, pacman, and `.exe` (NSIS). Users can easily set up WasmEdge using `moly-runner` and leverage `cargo` commands to build and run Moly. Additionally, Moly offers pre-built releases for download and supports packaging for distribution on Linux, Windows, and macOS.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.
chatgpt-lite
ChatGPT Lite is a lightweight web interface developed using Next.js and the OpenAI Chat API. It allows users to deploy a custom ChatGPT interface supporting markdown, prompt storage, and multi-person chats. Users can create private web-based ChatGPT instances for friends without sharing API keys. The codebase is clear and expandable, making it an ideal starting point for AI projects.

trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.
raycast_api_proxy
The Raycast AI Proxy is a tool that acts as a proxy for the Raycast AI application, allowing users to utilize the application without subscribing. It intercepts and forwards Raycast requests to various AI APIs, then reformats the responses for Raycast. The tool supports multiple AI providers and allows for custom model configurations. Users can generate self-signed certificates, add them to the system keychain, and modify DNS settings to redirect requests to the proxy. The tool is designed to work with providers like OpenAI, Azure OpenAI, Google, and more, enabling tasks such as AI chat completions, translations, and image generation.
verifywise
VerifyWise is an open-source AI governance platform designed to help businesses harness the power of AI safely and responsibly. The platform ensures compliance and robust AI management without compromising on security. It offers additional products like MaskWise for data redaction, EvalWise for AI model evaluation, and FlagWise for security threat monitoring. VerifyWise simplifies AI governance for organizations, aiding in risk management, regulatory compliance, and promoting responsible AI practices. It features options for on-premises or private cloud hosting, open-source with AGPLv3 license, AI-generated answers for compliance audits, source code transparency, Docker deployment, user registration, role-based access control, and various AI governance tools like risk management, bias & fairness checks, evidence center, AI trust center, and more.
skilld
Skilld is a tool that generates AI agent skills from NPM dependencies, allowing users to enhance their agent's knowledge with the latest best practices and avoid deprecated patterns. It provides version-aware, local-first, and optimized skills for your codebase by extracting information from existing docs, changelogs, issues, and discussions. Skilld aims to bridge the gap between agent training data and the latest conventions, offering a semantic search feature, LLM-enhanced sections, and prompt injection sanitization. It operates locally without the need for external servers, providing a curated set of skills tied to your actual package versions.
ai-elements
AI Elements is a component library built on top of shadcn/ui to help build AI-native applications faster. It provides pre-built, customizable React components specifically designed for AI applications, including conversations, messages, code blocks, reasoning displays, and more. The CLI makes it easy to add these components to your Next.js project.
For similar tasks
comfyui
ComfyUI is a highly-configurable, cloud-first AI-Dock container that allows users to run ComfyUI without bundled models or third-party configurations. Users can configure the container using provisioning scripts. The Docker image supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with version tags for different configurations. Additional environment variables and Python environments are provided for customization. ComfyUI service runs on port 8188 and can be managed using supervisorctl. The tool also includes an API wrapper service and pre-configured templates for Vast.ai. The author may receive compensation for services linked in the documentation.
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
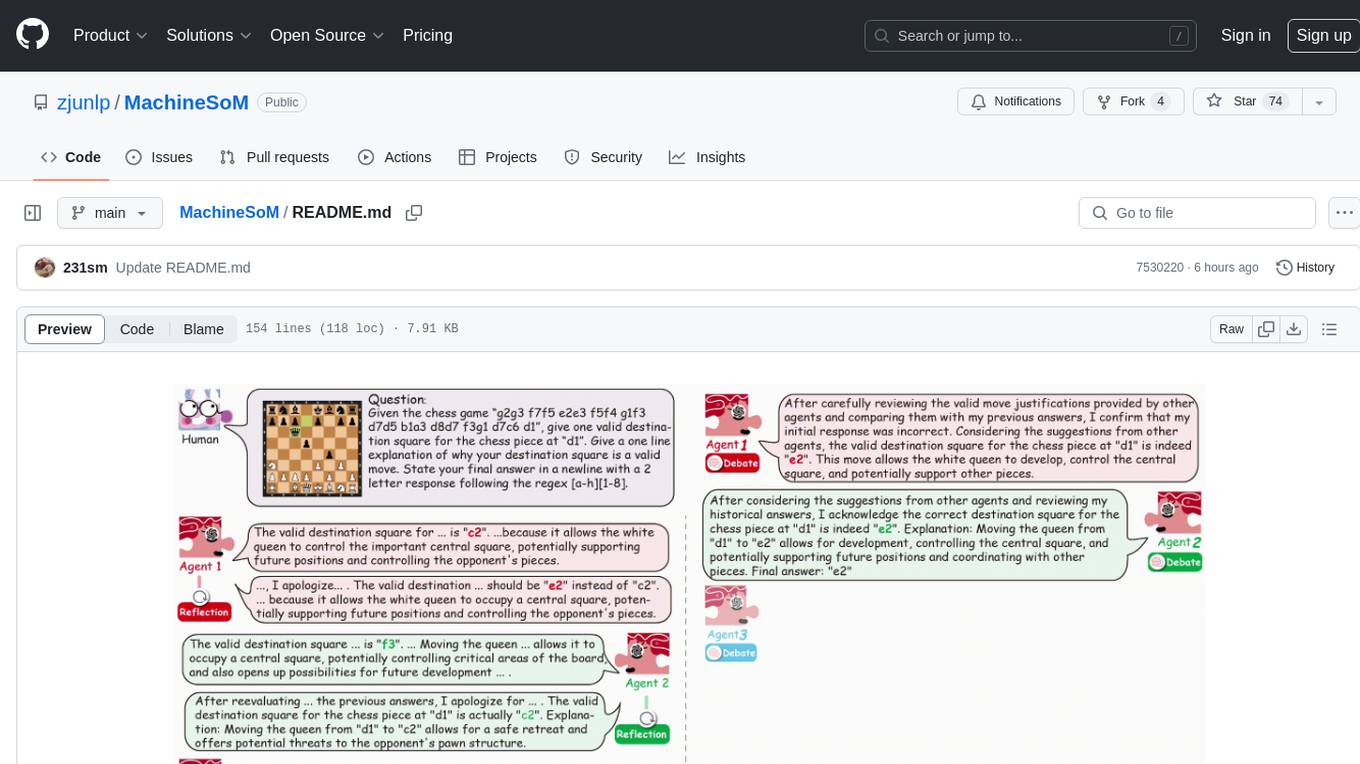
MachineSoM
MachineSoM is a code repository for the paper 'Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View'. It focuses on the emergence of intelligence from collaborative and communicative computational modules, enabling effective completion of complex tasks. The repository includes code for societies of LLM agents with different traits, collaboration processes such as debate and self-reflection, and interaction strategies for determining when and with whom to interact. It provides a coding framework compatible with various inference services like Replicate, OpenAI, Dashscope, and Anyscale, supporting models like Qwen and GPT. Users can run experiments, evaluate results, and draw figures based on the paper's content, with available datasets for MMLU, Math, and Chess Move Validity.

pyrfuniverse
pyrfuniverse is a python package used to interact with RFUniverse simulation environment. It is developed with reference to ML-Agents and produce new features. The package allows users to work with RFUniverse for simulation purposes, providing tools and functionalities to interact with the environment and create new features.
intentkit
IntentKit is an autonomous agent framework that enables the creation and management of AI agents with capabilities including blockchain interactions, social media management, and custom skill integration. It supports multiple agents, autonomous agent management, blockchain integration, social media integration, extensible skill system, and plugin system. The project is in alpha stage and not recommended for production use. It provides quick start guides for Docker and local development, integrations with Twitter and Coinbase, configuration options using environment variables or AWS Secrets Manager, project structure with core application code, entry points, configuration management, database models, skills, skill sets, and utility functions. Developers can add new skills by creating, implementing, and registering them in the skill directory.
pear-landing-page
PearAI Landing Page is an open-source AI-powered code editor managed by Nang and Pan. It is built with Next.js, Vercel, Tailwind CSS, and TypeScript. The project requires setting up environment variables for proper configuration. Users can run the project locally by starting the development server and visiting the specified URL in the browser. Recommended extensions include Prettier, ESLint, and JavaScript and TypeScript Nightly. Contributions to the project are welcomed and appreciated.
webapp-starter
webapp-starter is a modern full-stack application template built with Turborepo, featuring a Hono + Bun API backend and Next.js frontend. It provides an easy way to build a SaaS product. The backend utilizes technologies like Bun, Drizzle ORM, and Supabase, while the frontend is built with Next.js, Tailwind CSS, Shadcn/ui, and Clerk. Deployment can be done using Vercel and Render. The project structure includes separate directories for API backend and Next.js frontend, along with shared packages for the main database. Setup involves installing dependencies, configuring environment variables, and setting up services like Bun, Supabase, and Clerk. Development can be done using 'turbo dev' command, and deployment instructions are provided for Vercel and Render. Contributions are welcome through pull requests.
hayhooks
Hayhooks is a tool that simplifies the deployment and serving of Haystack pipelines as REST APIs. It allows users to wrap their pipelines with custom logic and expose them via HTTP endpoints, including OpenAI-compatible chat completion endpoints. With Hayhooks, users can easily convert their Haystack pipelines into API services with minimal boilerplate code.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.