
rag-chatbot
RAG (Retrieval-augmented generation) ChatBot that provides answers based on contextual information extracted from a collection of Markdown files.
Stars: 327
The RAG ChatBot project combines Lama.cpp, Chroma, and Streamlit to build a Conversation-aware Chatbot and a Retrieval-augmented generation (RAG) ChatBot. The RAG Chatbot works by taking a collection of Markdown files as input and provides answers based on the context provided by those files. It utilizes a Memory Builder component to load Markdown pages, divide them into sections, calculate embeddings, and save them in an embedding database. The chatbot retrieves relevant sections from the database, rewrites questions for optimal retrieval, and generates answers using a local language model. It also remembers previous interactions for more accurate responses. Various strategies are implemented to deal with context overflows, including creating and refining context, hierarchical summarization, and async hierarchical summarization.
README:
![]()
[!IMPORTANT] Disclaimer: The code has been tested on:
Ubuntu 22.04.2 LTSrunning on a Lenovo Legion 5 Pro with twenty12th Gen Intel® Core™ i7-12700Hand anNVIDIA GeForce RTX 3060.MacOS Sonoma 14.3.1running on a MacBook Pro M1 (2020).If you are using another Operating System or different hardware, and you can't load the models, please take a look at the official Llama Cpp Python's GitHub issue.
[!WARNING]
lama_cpp_pyhondoesn't useGPUonM1if you are running anx86version ofPython. More info here.- It's important to note that the large language model sometimes generates hallucinations or false information.
- Introduction
- Prerequisites
- Bootstrap Environment
- Using the Open-Source Models Locally
- Supported Response Synthesis strategies
- Example Data
- Build the memory index
- Run the Chatbot
- Run the RAG Chatbot
- How to debug the Streamlit app on Pycharm
- References
This project combines the power of Lama.cpp, Chroma and Streamlit to build:
- a Conversation-aware Chatbot (ChatGPT like experience).
- a RAG (Retrieval-augmented generation) ChatBot.
The RAG Chatbot works by taking a collection of Markdown files as input and, when asked a question, provides the corresponding answer based on the context provided by those files.

[!NOTE] We decided to grab and refactor the
RecursiveCharacterTextSplitterclass fromLangChainto effectively chunk Markdown files without adding LangChain as a dependency.
The Memory Builder component of the project loads Markdown pages from the docs folder.
It then divides these pages into smaller sections, calculates the embeddings (a numerical representation) of these
sections with the all-MiniLM-L6-v2
sentence-transformer, and saves them in an embedding database called Chroma
for later use.
When a user asks a question, the RAG ChatBot retrieves the most relevant sections from the Embedding database. Since the original question can't be always optimal to retrieve for the LLM, we first prompt an LLM to rewrite the question, then conduct retrieval-augmented reading. The most relevant sections are then used as context to generate the final answer using a local language model (LLM). Additionally, the chatbot is designed to remember previous interactions. It saves the chat history and considers the relevant context from previous conversations to provide more accurate answers.
To deal with context overflows, we implemented three approaches:
-
Create And Refine the Context: synthesize a responses sequentially through all retrieved contents. -
Hierarchical Summarization of Context: generate an answer for each relevant section independently, and then hierarchically combine the answers. -
Async Hierarchical Summarization of Context: parallelized version of the Hierarchical Summarization of Context which lead to big speedups in response synthesis.


- Python 3.10+
- GPU supporting CUDA 12.1+
- Poetry 1.7.0
Install Poetry with the official installer by following this link.
You must use the current adopted version of Poetry defined here.
If you have poetry already installed and is not the right version, you can downgrade (or upgrade) poetry through:
poetry self update <version>
To easily install the dependencies we created a make file.
[!IMPORTANT] Run
Setupas your init command (or afterClean).
- Check:
make check- Use it to check that
which pip3andwhich python3points to the right path.
- Use it to check that
- Setup:
- Setup with NVIDIA CUDA acceleration:
make setup_cuda- Creates an environment and installs all dependencies with NVIDIA CUDA acceleration.
- Setup with Metal GPU acceleration:
make setup_metal- Creates an environment and installs all dependencies with Metal GPU acceleration for macOS system only.
- Setup with NVIDIA CUDA acceleration:
- Update:
make update- Update an environment and installs all updated dependencies.
- Tidy up the code:
make tidy- Run Ruff check and format.
- Clean:
make clean- Removes the environment and all cached files.
- Test:
make test- Runs all tests.
- Using pytest
We utilize the open-source library llama-cpp-python, a binding
for llama-cpp,
allowing us to utilize it within a Python environment.
llama-cpp serves as a C++ backend designed to work efficiently with transformer-based models.
Running the LLMs architecture on a local PC is impossible due to the large (~7 billion) number of parameters.
This library enable us to run them either on a CPU or GPU.
Additionally, we use the Quantization and 4-bit precision to reduce number of bits required to represent the numbers.
The quantized models are stored in GGML/GGUF
format.
| 🤖 Model | Supported | Model Size | Max Context Window | Notes and link to the model card |
|---|---|---|---|---|
llama-3.2 Meta Llama 3.2 Instruct |
✅ | 1B | 128k | Optimized to run locally on a mobile or edge device - Card |
llama-3.2 Meta Llama 3.2 Instruct |
✅ | 3B | 128k | Optimized to run locally on a mobile or edge device - Card |
llama-3.1 Meta Llama 3.1 Instruct |
✅ | 8B | 128k | Recommended model Card |
qwen-2.5:3b - Qwen2.5 Instruct |
✅ | 3B | 128k | Card |
qwen-2.5:3b-math-reasoning - Qwen2.5 Instruct Math Reasoning |
✅ | 3B | 128k | Card |
deep-seek-r1:7b - DeepSeek R1 Distill Qwen 7B |
✅ | 7B | 128k | Experimental Card |
openchat-3.6 - OpenChat 3.6 |
✅ | 8B | 8192 | Card |
openchat-3.5 - OpenChat 3.5 |
✅ | 7B | 8192 | Card |
starling Starling Beta |
✅ | 7B | 8192 | Is trained from Openchat-3.5-0106. It's recommended if you prefer more verbosity over OpenChat - Card
|
phi-3.5 Phi-3.5 Mini Instruct |
✅ | 3.8B | 128k | Card |
stablelm-zephyr StableLM Zephyr OpenOrca |
✅ | 3B | 4096 | Card |
| ✨ Response Synthesis strategy | Supported | Notes |
|---|---|---|
create-and-refine Create and Refine |
✅ | |
tree-summarization Tree Summarization |
✅ | |
async-tree-summarization - Recommended - Async Tree Summarization |
✅ |
You could download some Markdown pages from
the Blendle Employee Handbook
and put them under docs.
Run:
python chatbot/memory_builder.py --chunk-size 1000 --chunk-overlap 50To interact with a GUI type:
streamlit run chatbot/chatbot_app.py -- --model llama-3.1 --max-new-tokens 1024
To interact with a GUI type:
streamlit run chatbot/rag_chatbot_app.py -- --model llama-3.1 --k 2 --synthesis-strategy async-tree-summarization

- Large Language Models (LLMs):
- LLM Frameworks:
- llama.cpp:
- Ollama:
- Ollama
- Ollama Python Library
- On the architecture of ollama
- Analysis of Ollama Architecture and Conversation Processing Flow for AI LLM Tool
- How to Customize Ollama’s Storage Directory
- Use CodeGPT to access self-hosted models from Ollama for a code assistant in PyCharm. More info here.
- Deepval - A framework for evaluating LLMs:
- Structured Outputs
- LLM Datasets:
- Agents:
- Agent Frameworks:
- PydanticAI
- Atomic Agents
- agno - a lightweight, high-performance library for building Agents.
- Embeddings:
- To find the list of best embeddings models for the retrieval task in your language go to the Massive Text Embedding Benchmark (MTEB) Leaderboard
-
all-MiniLM-L6-v2
- This is a
sentence-transformersmodel: It maps sentences & paragraphs to a 384 dimensional dense vector space (Max Tokens 512) and can be used for tasks like classification or semantic search.
- This is a
- Vector Databases:
- Indexing algorithms:
- There are many algorithms for building indexes to optimize vector search. Most vector databases
implement
Hierarchical Navigable Small World (HNSW)and/orInverted File Index (IVF). Here are some great articles explaining them, and the trade-off betweenspeed,memoryandquality:- Nearest Neighbor Indexes for Similarity Search
- Hierarchical Navigable Small World (HNSW)
- From NVIDIA - Accelerating Vector Search: Using GPU-Powered Indexes with RAPIDS RAFT
- From NVIDIA - Accelerating Vector Search: Fine-Tuning GPU Index Algorithms
-
PS: Flat indexes (i.e. no optimisation) can be used to maintain 100% recall and precision, at the expense of speed.
- There are many algorithms for building indexes to optimize vector search. Most vector databases
implement
- Chroma
- Qdrant:
- Indexing algorithms:
- Retrieval Augmented Generation (RAG):
- Building A Generative AI Platform
-
Rewrite-Retrieve-Read
-
Because the original query can not be always optimal to retrieve for the LLM, especially in the real world, we first prompt an LLM to rewrite the queries, then conduct retrieval-augmented reading.
-
- Rerank
- Building Response Synthesis from Scratch
- Conversational awareness
- RAG is Dead, Again?
- Chatbot UI:
- Text Processing and Cleaning:
- Inspirational Open Source Repositories:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rag-chatbot
Similar Open Source Tools
rag-chatbot
The RAG ChatBot project combines Lama.cpp, Chroma, and Streamlit to build a Conversation-aware Chatbot and a Retrieval-augmented generation (RAG) ChatBot. The RAG Chatbot works by taking a collection of Markdown files as input and provides answers based on the context provided by those files. It utilizes a Memory Builder component to load Markdown pages, divide them into sections, calculate embeddings, and save them in an embedding database. The chatbot retrieves relevant sections from the database, rewrites questions for optimal retrieval, and generates answers using a local language model. It also remembers previous interactions for more accurate responses. Various strategies are implemented to deal with context overflows, including creating and refining context, hierarchical summarization, and async hierarchical summarization.
keras-llm-robot
The Keras-llm-robot Web UI project is an open-source tool designed for offline deployment and testing of various open-source models from the Hugging Face website. It allows users to combine multiple models through configuration to achieve functionalities like multimodal, RAG, Agent, and more. The project consists of three main interfaces: chat interface for language models, configuration interface for loading models, and tools & agent interface for auxiliary models. Users can interact with the language model through text, voice, and image inputs, and the tool supports features like model loading, quantization, fine-tuning, role-playing, code interpretation, speech recognition, image recognition, network search engine, and function calling.
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
llm2sh
llm2sh is a command-line utility that leverages Large Language Models (LLMs) to translate plain-language requests into shell commands. It provides a convenient way to interact with your system using natural language. The tool supports multiple LLMs for command generation, offers a customizable configuration file, YOLO mode for running commands without confirmation, and is easily extensible with new LLMs and system prompts. Users can set up API keys for OpenAI, Claude, Groq, and Cerebras to use the tool effectively. llm2sh does not store user data or command history, and it does not record or send telemetry by itself, but the LLM APIs may collect and store requests and responses for their purposes.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
EasyInstruct
EasyInstruct is a Python package proposed as an easy-to-use instruction processing framework for Large Language Models (LLMs) like GPT-4, LLaMA, ChatGLM in your research experiments. EasyInstruct modularizes instruction generation, selection, and prompting, while also considering their combination and interaction.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
all-rag-techniques
This repository provides a hands-on approach to Retrieval-Augmented Generation (RAG) techniques, simplifying advanced concepts into understandable implementations using Python libraries like openai, numpy, and matplotlib. It offers a collection of Jupyter Notebooks with concise explanations, step-by-step implementations, code examples, evaluations, and visualizations for various RAG techniques. The goal is to make RAG more accessible and demystify its workings for educational purposes.
thinc
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.
run-gemini-cli
run-gemini-cli is a GitHub Action that integrates Gemini into your development workflow via the Gemini CLI. It acts as an autonomous agent for routine coding tasks and an on-demand collaborator. Use it for GitHub pull request reviews, triaging issues, code analysis, and more. It provides automation, on-demand collaboration, extensibility with tools, and customization options.
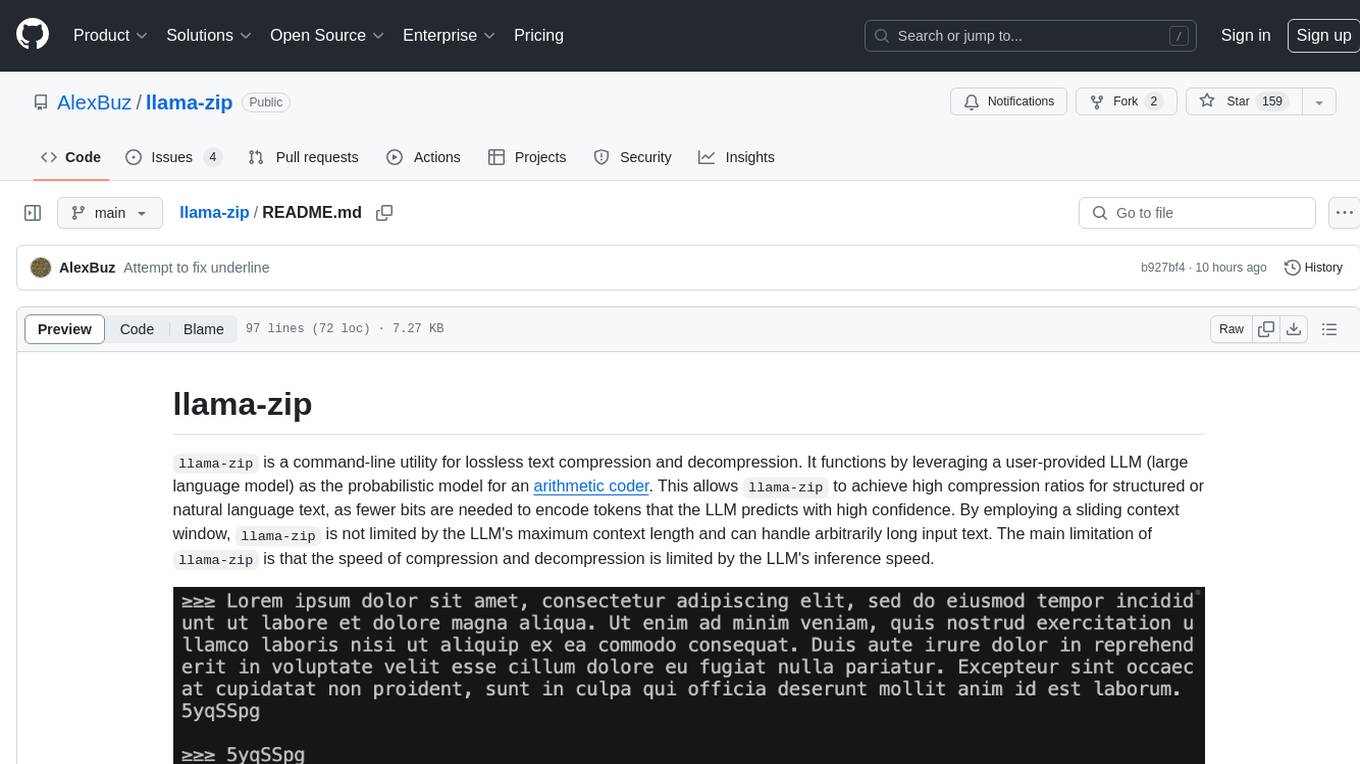
llama-zip
llama-zip is a command-line utility for lossless text compression and decompression. It leverages a user-provided large language model (LLM) as the probabilistic model for an arithmetic coder, achieving high compression ratios for structured or natural language text. The tool is not limited by the LLM's maximum context length and can handle arbitrarily long input text. However, the speed of compression and decompression is limited by the LLM's inference speed.
finetrainers
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.
For similar tasks
Flowise
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.

nlux
nlux is an open-source Javascript and React JS library that makes it super simple to integrate powerful large language models (LLMs) like ChatGPT into your web app or website. With just a few lines of code, you can add conversational AI capabilities and interact with your favourite LLM.
generative-ai-go
The Google AI Go SDK enables developers to use Google's state-of-the-art generative AI models (like Gemini) to build AI-powered features and applications. It supports use cases like generating text from text-only input, generating text from text-and-images input (multimodal), building multi-turn conversations (chat), and embedding.
awesome-langchain-zh
The awesome-langchain-zh repository is a collection of resources related to LangChain, a framework for building AI applications using large language models (LLMs). The repository includes sections on the LangChain framework itself, other language ports of LangChain, tools for low-code development, services, agents, templates, platforms, open-source projects related to knowledge management and chatbots, as well as learning resources such as notebooks, videos, and articles. It also covers other LLM frameworks and provides additional resources for exploring and working with LLMs. The repository serves as a comprehensive guide for developers and AI enthusiasts interested in leveraging LangChain and LLMs for various applications.

Large-Language-Model-Notebooks-Course
This practical free hands-on course focuses on Large Language models and their applications, providing a hands-on experience using models from OpenAI and the Hugging Face library. The course is divided into three major sections: Techniques and Libraries, Projects, and Enterprise Solutions. It covers topics such as Chatbots, Code Generation, Vector databases, LangChain, Fine Tuning, PEFT Fine Tuning, Soft Prompt tuning, LoRA, QLoRA, Evaluate Models, Knowledge Distillation, and more. Each section contains chapters with lessons supported by notebooks and articles. The course aims to help users build projects and explore enterprise solutions using Large Language Models.
ai-chatbot
Next.js AI Chatbot is an open-source app template for building AI chatbots using Next.js, Vercel AI SDK, OpenAI, and Vercel KV. It includes features like Next.js App Router, React Server Components, Vercel AI SDK for streaming chat UI, support for various AI models, Tailwind CSS styling, Radix UI for headless components, chat history management, rate limiting, session storage with Vercel KV, and authentication with NextAuth.js. The template allows easy deployment to Vercel and customization of AI model providers.
awesome-local-llms
The 'awesome-local-llms' repository is a curated list of open-source tools for local Large Language Model (LLM) inference, covering both proprietary and open weights LLMs. The repository categorizes these tools into LLM inference backend engines, LLM front end UIs, and all-in-one desktop applications. It collects GitHub repository metrics as proxies for popularity and active maintenance. Contributions are encouraged, and users can suggest additional open-source repositories through the Issues section or by running a provided script to update the README and make a pull request. The repository aims to provide a comprehensive resource for exploring and utilizing local LLM tools.
Awesome-AI-Data-Guided-Projects
A curated list of data science & AI guided projects to start building your portfolio. The repository contains guided projects covering various topics such as large language models, time series analysis, computer vision, natural language processing (NLP), and data science. Each project provides detailed instructions on how to implement specific tasks using different tools and technologies.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.