
wanda
A simple and effective LLM pruning approach.
Stars: 560
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.
README:
Official PyTorch implementation of Wanda (Pruning by Weights and activations), as presented in our paper:
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun*, Zhuang Liu*, Anna Bair, J. Zico Kolter (* indicates equal contribution)
Carnegie Mellon University, Meta AI Research and Bosch Center for AI
Paper - Project page
@article{sun2023wanda,
title={A Simple and Effective Pruning Approach for Large Language Models},
author={Sun, Mingjie and Liu, Zhuang and Bair, Anna and Kolter, J. Zico},
year={2023},
journal={arXiv preprint arXiv:2306.11695}
}

Compared to magnitude pruning which removes weights solely based on their magnitudes, our pruning approach Wanda removes weights on a per-output basis, by the product of weight magnitudes and input activation norms.
- [x] (9.22.2023) Add support for LLaMA-2.
- [x] (9.22.2023) Add code to reproduce the ablation study on OBS weight update in the paper.
- [x] (10.6.2023) Add new support for the weight update analysis in the ablation study. Feel free to try it out!
- [x] (10.6.2023) Add support for zero-shot evaluation.
- [x] (10.20.2023) Add code for pruning OPT models.
- [x] (10.23.2023) Add code for LoRA fine-tuning.
Installation instructions can be found in INSTALL.md.
The scripts directory contains all the bash commands to replicate the main results (Table 2) in our paper.
Below is an example command for pruning LLaMA-7B with Wanda, to achieve unstructured 50% sparsity.
python main.py \
--model decapoda-research/llama-7b-hf \
--prune_method wanda \
--sparsity_ratio 0.5 \
--sparsity_type unstructured \
--save out/llama_7b/unstructured/wanda/ We provide a quick overview of the arguments:
-
--model: The identifier for the LLaMA model on the Hugging Face model hub. -
--cache_dir: Directory for loading or storing LLM weights. The default isllm_weights. -
--prune_method: We have implemented three pruning methods, namely [magnitude,wanda,sparsegpt]. -
--sparsity_ratio: Denotes the percentage of weights to be pruned. -
--sparsity_type: Specifies the type of sparsity [unstructured,2:4,4:8]. -
--use_variant: Whether to use the Wanda variant, default isFalse. -
--save: Specifies the directory where the result will be stored.
For structured N:M sparsity, set the argument --sparsity_type to "2:4" or "4:8". An illustrative command is provided below:
python main.py \
--model decapoda-research/llama-7b-hf \
--prune_method wanda \
--sparsity_ratio 0.5 \
--sparsity_type 2:4 \
--save out/llama_7b/2-4/wanda/ For LLaMA-2 models, replace --model with meta-llama/Llama-2-7b-hf (take 7b as an example):
python main.py \
--model meta-llama/Llama-2-7b-hf \
--prune_method wanda \
--sparsity_ratio 0.5 \
--sparsity_type unstructured \
--save out/llama2_7b/unstructured/wanda/LLaMA-2 results: (LLaMA-2-34b is not released as of 9.22.2023)
| sparsity | ppl | llama2-7b | llama2-13b | llama2-70b |
|---|---|---|---|---|
| - | dense | 5.12 | 4.57 | 3.12 |
| unstructured 50% | magnitude | 14.89 | 6.37 | 4.98 |
| unstructured 50% | sparsegpt | 6.51 | 5.63 | 3.98 |
| unstructured 50% | wanda | 6.42 | 5.56 | 3.98 |
| 4:8 | magnitude | 16.48 | 6.76 | 5.58 |
| 4:8 | sparsegpt | 8.12 | 6.60 | 4.59 |
| 4:8 | wanda | 7.97 | 6.55 | 4.47 |
| 2:4 | magnitude | 54.59 | 8.33 | 6.33 |
| 2:4 | sparsegpt | 10.17 | 8.32 | 5.40 |
| 2:4 | wanda | 11.02 | 8.27 | 5.16 |
To reproduce the analysis on weight update, we provide our implementation for this ablation. All commands can be found in this script.
for method in ablate_mag_seq ablate_wanda_seq ablate_mag_iter ablate_wanda_iter
do
CUDA_VISIBLE_DEVICES=0 python main.py \
--model decapoda-research/llama-7b-hf \
--sparsity_ratio 0.5 \
--sparsity_type unstructured \
--prune_method ${method} \
--save out/llama_7b_ablation/unstructured/
done Here ablate_{mag/wanda}_{seq/iter} means that we use magnitude pruning or wanda to obtain the pruned mask at each layer, then apply weight update procedure with either a sequential style or an iterative style every 128 input channels. For details, please see Section 5 of our paper.
For evaluating zero-shot tasks, we modify the EleutherAI LM Harness framework so that it could evaluate pruned LLM models. We provide the modified repo in this link. Make sure to download, extract and install this custom lm_eval package from the source code.
For reproducibility, we used commit df3da98 on the main branch. All tasks were evaluated on task version of 0 except for BoolQ, where the task version is 1.
On a high level, the functionality we provide is adding two arguments pretrained_model and tokenizer in this function. We can then call this simple_evaluate function API from our codebase to evaluate sparse pruned LLMs. To evaluate zero-shot tasks in addition to the WikiText perplexity, pass the --eval_zero_shot argument.
The pruning speed for each method is evaluated by the cumulated time spent on pruning (for each layer), without the forward passes.
For inference speedup with structured sparsity, we refer the reader to this blog post, where structured sparsity is supported by PyTorch >= 2.1. You can switch between the CUTLASS or CuSPARSELt kernel here.
Last, for pruning image classifiers, see directory image_classifiers for details.
This repository is build upon the SparseGPT repository.
This project is released under the MIT license. Please see the LICENSE file for more information.
Feel free to discuss papers/code with us through issues/emails!
mingjies at cs.cmu.edu
liuzhuangthu at gmail.com
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for wanda
Similar Open Source Tools
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
llm-leaderboard
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

pgvecto.rs
pgvecto.rs is a Postgres extension written in Rust that provides vector similarity search functions. It offers ultra-low-latency, high-precision vector search capabilities, including sparse vector search and full-text search. With complete SQL support, async indexing, and easy data management, it simplifies data handling. The extension supports various data types like FP16/INT8, binary vectors, and Matryoshka embeddings. It ensures system performance with production-ready features, high availability, and resource efficiency. Security and permissions are managed through easy access control. The tool allows users to create tables with vector columns, insert vector data, and calculate distances between vectors using different operators. It also supports half-precision floating-point numbers for better performance and memory usage optimization.

WordLlama
WordLlama is a fast, lightweight NLP toolkit optimized for CPU hardware. It recycles components from large language models to create efficient word representations. It offers features like Matryoshka Representations, low resource requirements, binarization, and numpy-only inference. The tool is suitable for tasks like semantic matching, fuzzy deduplication, ranking, and clustering, making it a good option for NLP-lite tasks and exploratory analysis.

RTL-Coder
RTL-Coder is a tool designed to outperform GPT-3.5 in RTL code generation by providing a fully open-source dataset and a lightweight solution. It targets Verilog code generation and offers an automated flow to generate a large labeled dataset with over 27,000 diverse Verilog design problems and answers. The tool addresses the data availability challenge in IC design-related tasks and can be used for various applications beyond LLMs. The tool includes four RTL code generation models available on the HuggingFace platform, each with specific features and performance characteristics. Additionally, RTL-Coder introduces a new LLM training scheme based on code quality feedback to further enhance model performance and reduce GPU memory consumption.

PDEBench
PDEBench provides a diverse and comprehensive set of benchmarks for scientific machine learning, including challenging and realistic physical problems. The repository consists of code for generating datasets, uploading and downloading datasets, training and evaluating machine learning models as baselines. It features a wide range of PDEs, realistic and difficult problems, ready-to-use datasets with various conditions and parameters. PDEBench aims for extensibility and invites participation from the SciML community to improve and extend the benchmark.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.
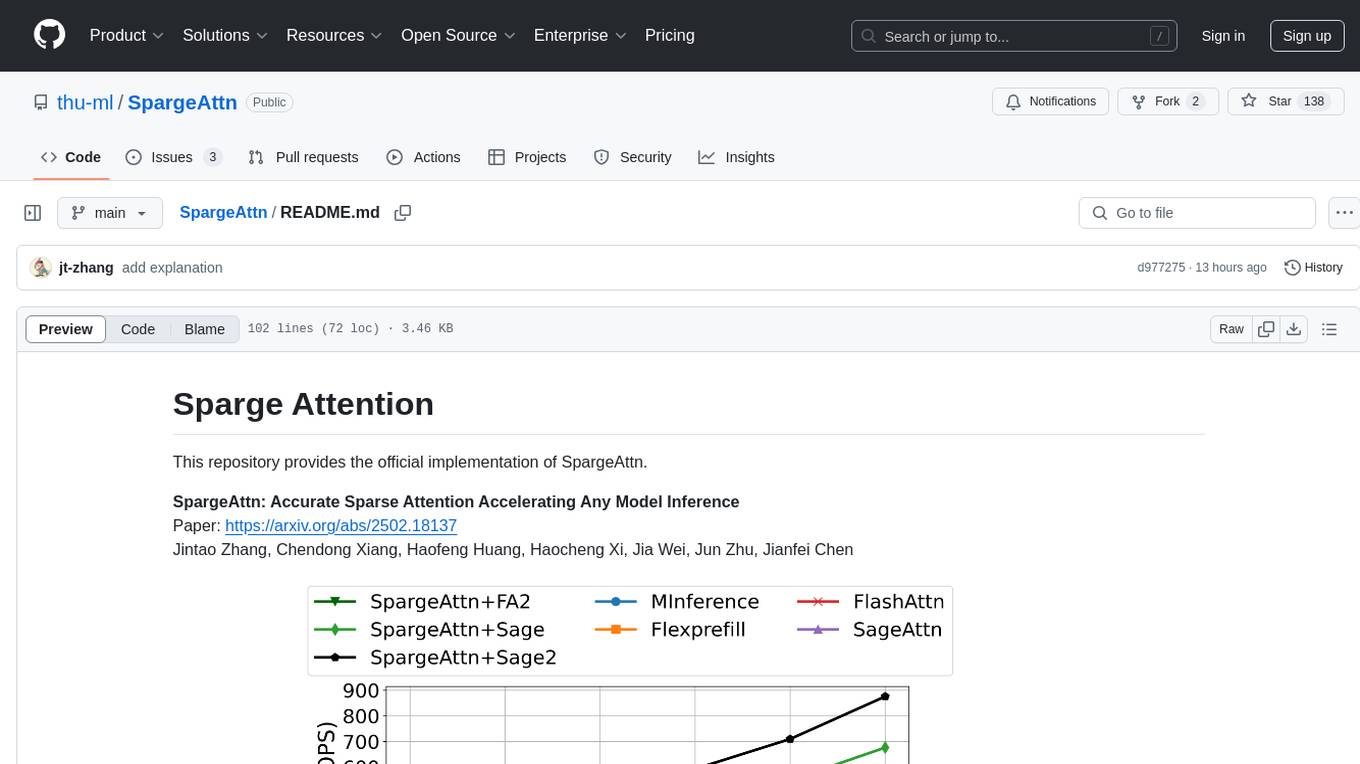
SpargeAttn
SpargeAttn is an official implementation designed for accelerating any model inference by providing accurate sparse attention. It offers a significant speedup in model performance while maintaining quality. The tool is based on SageAttention and SageAttention2, providing options for different levels of optimization. Users can easily install the package and utilize the available APIs for their specific needs. SpargeAttn is particularly useful for tasks requiring efficient attention mechanisms in deep learning models.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.
Endia
Endia is a dynamic Array library for Scientific Computing, offering automatic differentiation of arbitrary order, complex number support, dual API with PyTorch-like imperative or JAX-like functional interface, and JIT Compilation for speeding up training and inference. It can handle complex valued functions, perform both forward and reverse-mode automatic differentiation, and has a builtin JIT compiler. Endia aims to advance AI & Scientific Computing by pushing boundaries with clear algorithms, providing high-performance open-source code that remains readable and pythonic, and prioritizing clarity and educational value over exhaustive features.
For similar tasks
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.
Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.