Best AI tools for< Nlp Researcher >
Infographic
20 - AI tool Sites
FutureSmart AI
FutureSmart AI is a platform that provides custom Natural Language Processing (NLP) solutions. The platform focuses on integrating Mem0 with LangChain to enhance AI Assistants with Intelligent Memory. It offers tutorials, guides, and practical tips for building applications with large language models (LLMs) to create sophisticated and interactive systems. FutureSmart AI also features internship journeys and practical guides for mastering RAG with LangChain, catering to developers and enthusiasts in the realm of NLP and AI.
GooseAI
GooseAI is a fully managed NLP-as-a-Service delivered via API, at 30% the cost of other providers. It offers a variety of NLP models, including GPT-Neo 1.3B, Fairseq 1.3B, GPT-J 6B, Fairseq 6B, Fairseq 13B, and GPT-NeoX 20B. GooseAI is easy to use, with feature parity with industry standard APIs. It is also highly performant, with the industry's fastest generation speeds.
TUNiB
TUNiB is an AI application that specializes in creating conversational AI that people emotionally engage with. It offers services such as NLP APIs for detecting hate speech and breaches of private information, safety checks for toxicity detection, de-identification for masking personal information, and various analytics services like text, image, news, and video analytics. TUNiB aims to provide cutting-edge technologies while upholding high ethical standards.
Sentence Transformers
Sentence Transformers is a Python module that provides access to state-of-the-art embedding and reranker models. It allows users to compute embeddings, calculate similarity scores, and generate sparse embeddings for various applications such as semantic search, semantic textual similarity, and paraphrase mining. The module offers a wide selection of pre-trained models and enables users to train or finetune their own models for specific use cases.
Storia AI
Storia AI is an AI tool designed to assist software engineering teams in understanding and generating code. It provides a Perplexity-like chat experience where users can interact with an AI expert that has access to the latest versions of open-source software. The tool aims to improve code understanding and generation by providing responses backed with links to implementations, API references, GitHub issues, and more. Storia AI is developed by a team of natural language processing researchers from Google and Amazon Alexa, with a mission to build the most reliable AI pair programmer for engineering teams.
Datasaur
Datasaur is an advanced text and audio data labeling platform that offers customizable solutions for various industries such as LegalTech, Healthcare, Financial, Media, e-Commerce, and Government. It provides features like configurable annotation, quality control automation, and workforce management to enhance the efficiency of NLP and LLM projects. Datasaur prioritizes data security with military-grade practices and offers seamless integrations with AWS and other technologies. The platform aims to streamline the data labeling process, allowing engineers to focus on creating high-quality models.
Answer.AI
Answer.AI is an AI tool developed by Benjamin Clavié, focusing on NLP&IR with a special interest in developing smaller models to power LLM-based applications. The tool includes models like answerai-colbert-small-v1 and JaColBERTv2.5🇯🇵, offering efficient pooling tricks and optimizing retrieval training for lower-resource languages. Benjamin Clavié shares insights and thoughts on ML/NLP/IR ecosystem through blog posts on the website.
Explosion
Explosion is a software company specializing in developer tools and tailored solutions for AI, Machine Learning, and Natural Language Processing (NLP). They are the makers of spaCy, one of the leading open-source libraries for advanced NLP. The company offers consulting services and builds developer tools for various AI-related tasks, such as coreference resolution, dependency parsing, image classification, named entity recognition, and more.
Medallia
Medallia is a real-time text analytics software that offers comprehensive feedback capture, role-based reporting, AI and analytics capabilities, integrations, pricing flexibility, enterprise-grade security, and solutions for customer experience, employee experience, contact center, and market research. It provides omnichannel text analytics powered by AI to uncover high-impact insights and enable users to identify emerging trends and key insights at scale. Medallia's text analytics platform supports workflows, event analytics, real-time actions, natural language understanding, out-of-the-box topic models, customizable KPIs, and omnichannel analytics for various industries.
MTS AI
MTS AI is a platform offering AI-based products and solutions, leveraging artificial intelligence technologies to create voice assistants, chatbots, video analysis solutions, and more. They develop AI solutions using natural language processing, computer vision, and edge computing technologies, collaborating with leading tech companies and global experts. MTS AI aims to find the most viable AI applications for the benefit of society, providing automation for customer service systems, security control, and voice and video data analysis.
Chatbots Life
Chatbots Life is a platform dedicated to providing comprehensive resources and insights on chatbots, AI, and natural language understanding (NLU). The website offers a wide range of content, including articles, workshops, and events, to help individuals learn and stay updated on the latest trends and technologies in the field of conversational AI.
Hella Jobs
Hella Jobs is a leading platform for AI, Machine Learning, and Data Science jobs. It connects job seekers with top employers in the field of AI/ML, allowing employers to post open jobs and hire top talent. Job seekers can create profiles, submit resumes, and find new job opportunities. The platform offers features such as job filtering by keywords and location, job category selection, salary range selection, and job type filtering. Hella Jobs aims to streamline the job search process for both employers and job seekers in the AI/ML industry.

DeepRec.ai
DeepRec.ai is a specialized recruitment platform focusing on AI and ML professionals. The platform offers hiring services for various AI specialisms such as Research GenAI, Machine Learning, Computer Vision, AI Infrastructure, Quantum Computing, Robotics & Embodied AI, and AI4Science. DeepRec.ai provides hiring solutions like Embedded Hiring, Retained Search, Contingent Contract & Flexible Resource, tailored to scale with businesses and address high-volume hiring challenges. The platform boasts positive feedback from both clients and candidates, emphasizing the quality of communication, candidate selection, and support throughout the recruitment process.
Lexalytics
Lexalytics is a leading provider of text analytics and natural language processing (NLP) solutions. Our platform and services help businesses transform complex text data into valuable insights and actionable intelligence. With Lexalytics, you can: * **Analyze customer feedback** to understand what your customers are saying about your products, services, and brand. * **Identify trends and patterns** in text data to make better decisions about your business. * **Automate tasks** such as document classification, entity extraction, and sentiment analysis. * **Develop custom NLP applications** to meet your specific needs.
AI Detector
AI Detector is an online tool that uses advanced algorithms and machine learning to check if your written text is generated by AI or a human writer. It analyzes the writing style, sentence structure, and other linguistic patterns to determine the likelihood of AI authorship. The tool provides a percentage score indicating the probability of AI-generated content, helping users identify potential plagiarism or AI-assisted writing.
Needl.ai
Needl.ai is an AI-powered platform designed to provide seamless information intelligence for enterprises. It unifies information from internal and external data sources, delivering near real-time, actionable insights. Users can connect preferred apps and data sources, curate personalized feeds, and centralize interactions with data using AI Assistants. Needl.ai offers a range of products for efficient enterprise decision-making, including Needl Feed, Needl Assistants, and AskNeedl for intelligent data aggregation and interactions.

Ai Kit Finder
Ai Kit Finder is a website that provides a directory of AI tools and applications. The website includes a search bar that allows users to search for AI tools by category, feature, or keyword. Ai Kit Finder also provides detailed descriptions of each AI tool, including its features, advantages, and disadvantages. Additionally, the website includes a blog that provides articles on the latest AI trends and developments.
Next AI Jobs
Next AI Jobs is an AI-powered platform that specializes in connecting professionals with job opportunities in the fields of Artificial Intelligence (AI), Machine Learning (ML), Natural Language Processing (NLP), and Data Science. The platform utilizes advanced algorithms to match candidates with relevant job listings, streamlining the recruitment process for both employers and job seekers. Next AI Jobs provides a user-friendly interface where users can create profiles, upload resumes, and apply for jobs with ease. With a focus on the rapidly growing AI industry, Next AI Jobs aims to bridge the gap between talented individuals and top-tier companies seeking AI expertise.
Innovatiana
Innovatiana is a data labeling outsourcing platform that offers high-quality datasets for artificial intelligence models. They specialize in image, audio/video, and text data labeling tasks, providing ethical outsourcing with a focus on impact and transparency. Innovatiana recruits and trains their own team in Madagascar, ensuring fair pay and good working conditions. They offer competitive rates, secure data handling, and high-quality labeled data to feed AI models. The platform supports various AI tasks such as Computer Vision, Data Collection, Data Moderation, Documents Processing, and Natural Language Processing.
Inspect
Inspect is an open-source framework for large language model evaluations created by the UK AI Safety Institute. It provides built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Users can explore various solvers, tools, scorers, datasets, and models to create advanced evaluations. Inspect supports extensions for new elicitation and scoring techniques through Python packages.
57 - Open Source Tools

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

mindnlp
MindNLP is an open-source NLP library based on MindSpore. It provides a platform for solving natural language processing tasks, containing many common approaches in NLP. It can help researchers and developers to construct and train models more conveniently and rapidly. Key features of MindNLP include: * Comprehensive data processing: Several classical NLP datasets are packaged into a friendly module for easy use, such as Multi30k, SQuAD, CoNLL, etc. * Friendly NLP model toolset: MindNLP provides various configurable components. It is friendly to customize models using MindNLP. * Easy-to-use engine: MindNLP simplified complicated training process in MindSpore. It supports Trainer and Evaluator interfaces to train and evaluate models easily. MindNLP supports a wide range of NLP tasks, including: * Language modeling * Machine translation * Question answering * Sentiment analysis * Sequence labeling * Summarization MindNLP also supports industry-leading Large Language Models (LLMs), including Llama, GLM, RWKV, etc. For support related to large language models, including pre-training, fine-tuning, and inference demo examples, you can find them in the "llm" directory. To install MindNLP, you can either install it from Pypi, download the daily build wheel, or install it from source. The installation instructions are provided in the documentation. MindNLP is released under the Apache 2.0 license. If you find this project useful in your research, please consider citing the following paper: @misc{mindnlp2022, title={{MindNLP}: a MindSpore NLP library}, author={MindNLP Contributors}, howpublished = {\url{https://github.com/mindlab-ai/mindnlp}}, year={2022} }
awesome-langchain-zh
The awesome-langchain-zh repository is a collection of resources related to LangChain, a framework for building AI applications using large language models (LLMs). The repository includes sections on the LangChain framework itself, other language ports of LangChain, tools for low-code development, services, agents, templates, platforms, open-source projects related to knowledge management and chatbots, as well as learning resources such as notebooks, videos, and articles. It also covers other LLM frameworks and provides additional resources for exploring and working with LLMs. The repository serves as a comprehensive guide for developers and AI enthusiasts interested in leveraging LangChain and LLMs for various applications.
glm-free-api
GLM AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, intelligent agent dialogue support, AI drawing support, online search support, long document interpretation support, image parsing support. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository also includes six other free APIs for various services like Moonshot AI, StepChat, Qwen, Metaso, Spark, and Emohaa. The tool supports tasks such as chat completions, AI drawing, document interpretation, image parsing, and refresh token survival check.

Awesome-LLM-RAG-Application
Awesome-LLM-RAG-Application is a repository that provides resources and information about applications based on Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) pattern. It includes a survey paper, GitHub repo, and guides on advanced RAG techniques. The repository covers various aspects of RAG, including academic papers, evaluation benchmarks, downstream tasks, tools, and technologies. It also explores different frameworks, preprocessing tools, routing mechanisms, evaluation frameworks, embeddings, security guardrails, prompting tools, SQL enhancements, LLM deployment, observability tools, and more. The repository aims to offer comprehensive knowledge on RAG for readers interested in exploring and implementing LLM-based systems and products.

serverless-rag-demo
The serverless-rag-demo repository showcases a solution for building a Retrieval Augmented Generation (RAG) system using Amazon Opensearch Serverless Vector DB, Amazon Bedrock, Llama2 LLM, and Falcon LLM. The solution leverages generative AI powered by large language models to generate domain-specific text outputs by incorporating external data sources. Users can augment prompts with relevant context from documents within a knowledge library, enabling the creation of AI applications without managing vector database infrastructure. The repository provides detailed instructions on deploying the RAG-based solution, including prerequisites, architecture, and step-by-step deployment process using AWS Cloudshell.

step-free-api
The StepChat Free service provides high-speed streaming output, multi-turn dialogue support, online search support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. Additionally, it provides seven other free APIs for various services. The repository includes a disclaimer about using reverse APIs and encourages users to avoid commercial use to prevent service pressure on the official platform. It offers online testing links, showcases different demos, and provides deployment guides for Docker, Docker-compose, Render, Vercel, and native deployments. The repository also includes information on using multiple accounts, optimizing Nginx reverse proxy, and checking the liveliness of refresh tokens.
qlora-pipe
qlora-pipe is a pipeline parallel training script designed for efficiently training large language models that cannot fit on one GPU. It supports QLoRA, LoRA, and full fine-tuning, with efficient model loading and the ability to load any dataset that Axolotl can handle. The script allows for raw text training, resuming training from a checkpoint, logging metrics to Tensorboard, specifying a separate evaluation dataset, training on multiple datasets simultaneously, and supports various models like Llama, Mistral, Mixtral, Qwen-1.5, and Cohere (Command R). It handles pipeline- and data-parallelism using Deepspeed, enabling users to set the number of GPUs, pipeline stages, and gradient accumulation steps for optimal utilization.

LLMstudio
LLMstudio by TensorOps is a platform that offers prompt engineering tools for accessing models from providers like OpenAI, VertexAI, and Bedrock. It provides features such as Python Client Gateway, Prompt Editing UI, History Management, and Context Limit Adaptability. Users can track past runs, log costs and latency, and export history to CSV. The tool also supports automatic switching to larger-context models when needed. Coming soon features include side-by-side comparison of LLMs, automated testing, API key administration, project organization, and resilience against rate limits. LLMstudio aims to streamline prompt engineering, provide execution history tracking, and enable effortless data export, offering an evolving environment for teams to experiment with advanced language models.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.
intro-llm-rag
This repository serves as a comprehensive guide for technical teams interested in developing conversational AI solutions using Retrieval-Augmented Generation (RAG) techniques. It covers theoretical knowledge and practical code implementations, making it suitable for individuals with a basic technical background. The content includes information on large language models (LLMs), transformers, prompt engineering, embeddings, vector stores, and various other key concepts related to conversational AI. The repository also provides hands-on examples for two different use cases, along with implementation details and performance analysis.

scikit-llm
Scikit-LLM is a tool that seamlessly integrates powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks. It allows users to leverage large language models for various text analysis applications within the familiar scikit-learn framework. The tool simplifies the process of incorporating advanced language processing capabilities into machine learning pipelines, enabling users to benefit from the latest advancements in natural language processing.
Awesome-LLMs-in-Graph-tasks
This repository is a collection of papers on leveraging Large Language Models (LLMs) in Graph Tasks. It provides a comprehensive overview of how LLMs can enhance graph-related tasks by combining them with traditional Graph Neural Networks (GNNs). The integration of LLMs with GNNs allows for capturing both structural and contextual aspects of nodes in graph data, leading to more powerful graph learning. The repository includes summaries of various models that leverage LLMs to assist in graph-related tasks, along with links to papers and code repositories for further exploration.
Magic_Words
Magic_Words is a repository containing code for the paper 'What's the Magic Word? A Control Theory of LLM Prompting'. It implements greedy back generation and greedy coordinate gradient (GCG) to find optimal control prompts (magic words). Users can set up a virtual environment, install the package and dependencies, and run example scripts for pointwise control and optimizing prompts for datasets. The repository provides scripts for finding optimal control prompts for question-answer pairs and dataset optimization using the GCG algorithm.
chinese-llm-benchmark
The Chinese LLM Benchmark is a continuous evaluation list of large models in CLiB, covering a wide range of commercial and open-source models from various companies and research institutions. It supports multidimensional evaluation of capabilities including classification, information extraction, reading comprehension, data analysis, Chinese encoding efficiency, and Chinese instruction compliance. The benchmark not only provides capability score rankings but also offers the original output results of all models for interested individuals to score and rank themselves.
Online-RLHF
This repository, Online RLHF, focuses on aligning large language models (LLMs) through online iterative Reinforcement Learning from Human Feedback (RLHF). It aims to bridge the gap in existing open-source RLHF projects by providing a detailed recipe for online iterative RLHF. The workflow presented here has shown to outperform offline counterparts in recent LLM literature, achieving comparable or better results than LLaMA3-8B-instruct using only open-source data. The repository includes model releases for SFT, Reward model, and RLHF model, along with installation instructions for both inference and training environments. Users can follow step-by-step guidance for supervised fine-tuning, reward modeling, data generation, data annotation, and training, ultimately enabling iterative training to run automatically.
HippoRAG
HippoRAG is a novel retrieval augmented generation (RAG) framework inspired by the neurobiology of human long-term memory that enables Large Language Models (LLMs) to continuously integrate knowledge across external documents. It provides RAG systems with capabilities that usually require a costly and high-latency iterative LLM pipeline for only a fraction of the computational cost. The tool facilitates setting up retrieval corpus, indexing, and retrieval processes for LLMs, offering flexibility in choosing different online LLM APIs or offline LLM deployments through LangChain integration. Users can run retrieval on pre-defined queries or integrate directly with the HippoRAG API. The tool also supports reproducibility of experiments and provides data, baselines, and hyperparameter tuning scripts for research purposes.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).

LiveBench
LiveBench is a benchmark tool designed for Language Model Models (LLMs) with a focus on limiting contamination through monthly new questions based on recent datasets, arXiv papers, news articles, and IMDb movie synopses. It provides verifiable, objective ground-truth answers for accurate scoring without an LLM judge. The tool offers 18 diverse tasks across 6 categories and promises to release more challenging tasks over time. LiveBench is built on FastChat's llm_judge module and incorporates code from LiveCodeBench and IFEval.
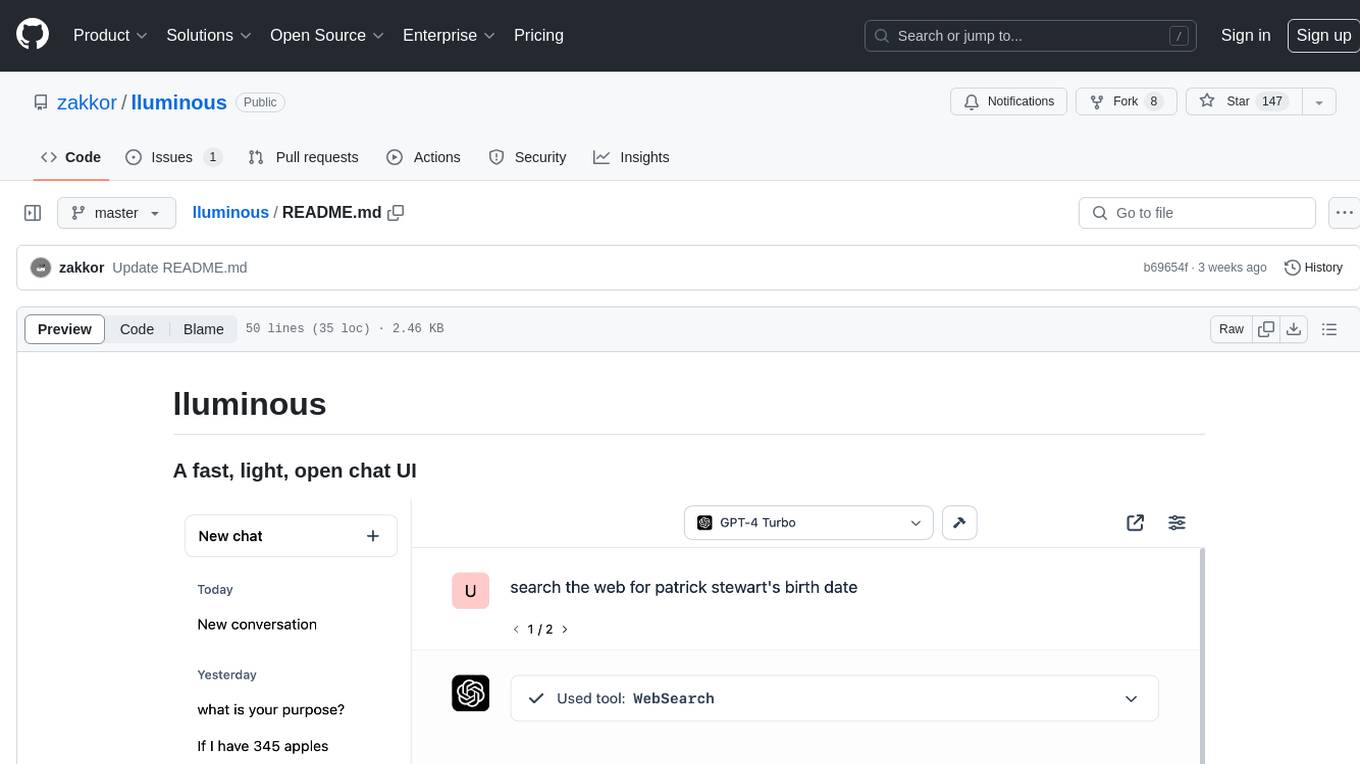
lluminous
lluminous is a fast and light open chat UI that supports multiple providers such as OpenAI, Anthropic, and Groq models. Users can easily plug in their API keys locally to access various models for tasks like multimodal input, image generation, multi-shot prompting, pre-filled responses, and more. The tool ensures privacy by storing all conversation history and keys locally on the user's device. Coming soon features include memory tool, file ingestion/embedding, embeddings-based web search, and prompt templates.
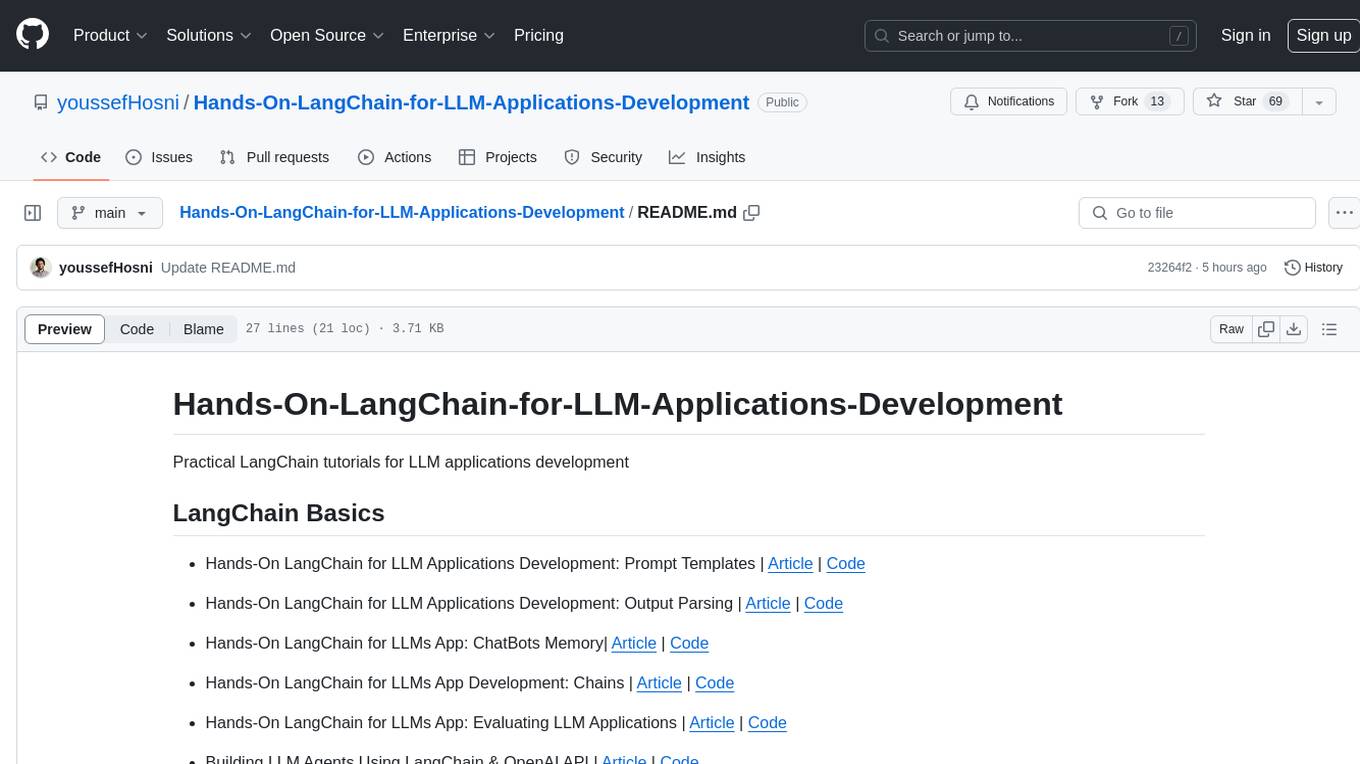
Hands-On-LangChain-for-LLM-Applications-Development
Practical LangChain tutorials for developing LLM applications, including prompt templates, output parsing, chatbots memory, chains, evaluating applications, building agents using LangChain & OpenAI API, retrieval augmented generation with LangChain, documents loading, splitting, vector database & text embeddings, information retrieval, answering questions from documents, chat with files, and introduction to Open AI function calling.
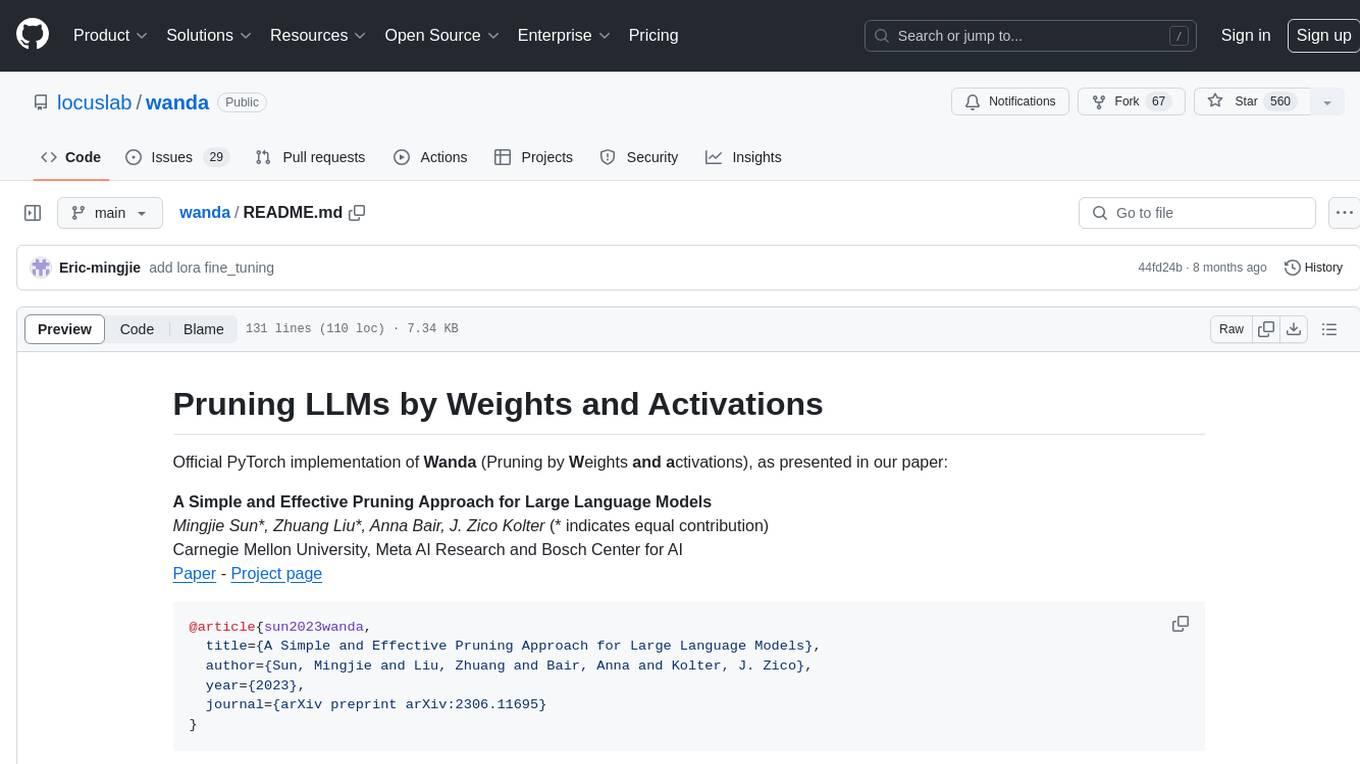
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.

enterprise-h2ogpte
Enterprise h2oGPTe - GenAI RAG is a repository containing code examples, notebooks, and benchmarks for the enterprise version of h2oGPTe, a powerful AI tool for generating text based on the RAG (Retrieval-Augmented Generation) architecture. The repository provides resources for leveraging h2oGPTe in enterprise settings, including implementation guides, performance evaluations, and best practices. Users can explore various applications of h2oGPTe in natural language processing tasks, such as text generation, content creation, and conversational AI.
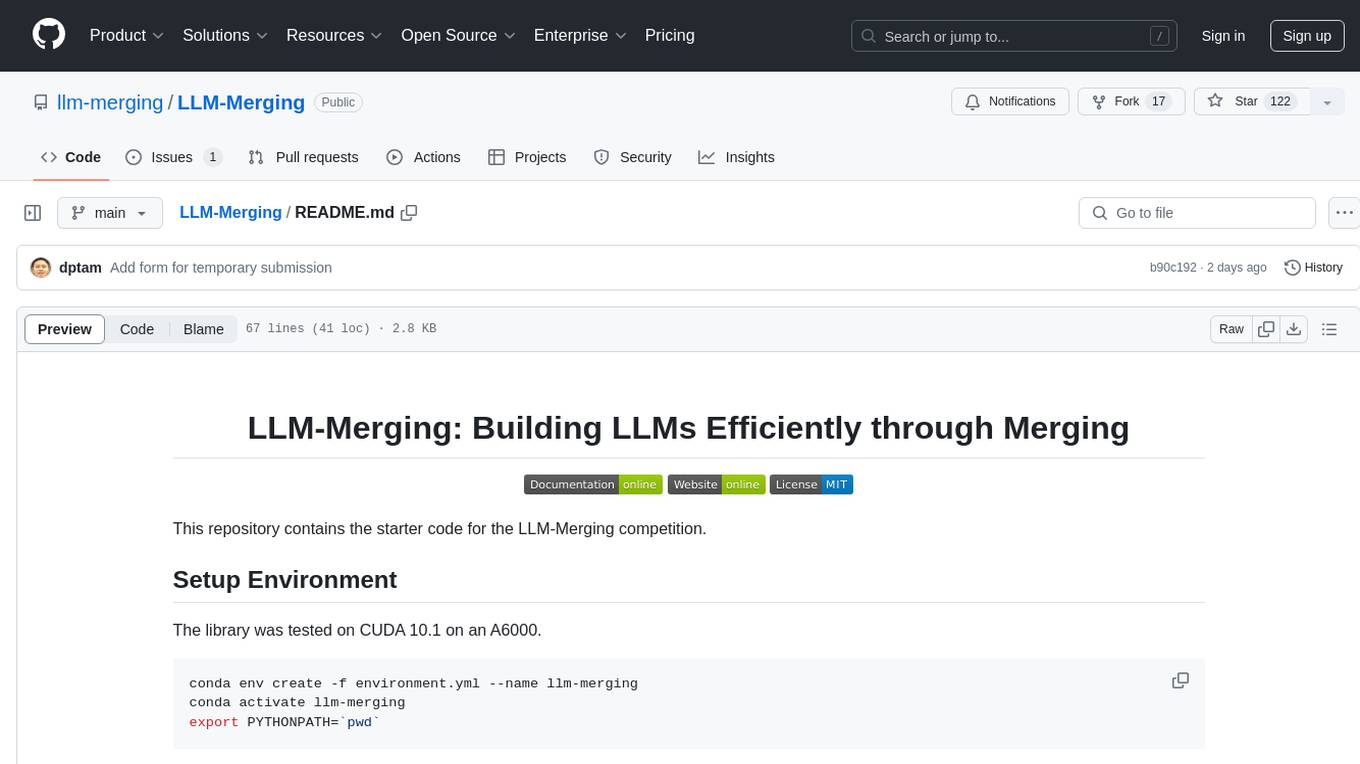
LLM-Merging
LLM-Merging is a repository containing starter code for the LLM-Merging competition. It provides a platform for efficiently building LLMs through merging methods. Users can develop new merging methods by creating new files in the specified directory and extending existing classes. The repository includes instructions for setting up the environment, developing new merging methods, testing the methods on specific datasets, and submitting solutions for evaluation. It aims to facilitate the development and evaluation of merging methods for LLMs.

langtest
LangTest is a comprehensive evaluation library for custom LLM and NLP models. It aims to deliver safe and effective language models by providing tools to test model quality, augment training data, and support popular NLP frameworks. LangTest comes with benchmark datasets to challenge and enhance language models, ensuring peak performance in various linguistic tasks. The tool offers more than 60 distinct types of tests with just one line of code, covering aspects like robustness, bias, representation, fairness, and accuracy. It supports testing LLMS for question answering, toxicity, clinical tests, legal support, factuality, sycophancy, and summarization.
unify
The Unify Python Package provides access to the Unify REST API, allowing users to query Large Language Models (LLMs) from any Python 3.7.1+ application. It includes Synchronous and Asynchronous clients with Streaming responses support. Users can easily use any endpoint with a single key, route to the best endpoint for optimal throughput, cost, or latency, and customize prompts to interact with the models. The package also supports dynamic routing to automatically direct requests to the top-performing provider. Additionally, users can enable streaming responses and interact with the models asynchronously for handling multiple user requests simultaneously.
gpt_server
The GPT Server project leverages the basic capabilities of FastChat to provide the capabilities of an openai server. It perfectly adapts more models, optimizes models with poor compatibility in FastChat, and supports loading vllm, LMDeploy, and hf in various ways. It also supports all sentence_transformers compatible semantic vector models, including Chat templates with function roles, Function Calling (Tools) capability, and multi-modal large models. The project aims to reduce the difficulty of model adaptation and project usage, making it easier to deploy the latest models with minimal code changes.
llm-book
The 'llm-book' repository is dedicated to the introduction of large-scale language models, focusing on natural language processing tasks. The code is designed to run on Google Colaboratory and utilizes datasets and models available on the Hugging Face Hub. Note that as of July 28, 2023, there are issues with the MARC-ja dataset links, but an alternative notebook using the WRIME Japanese sentiment analysis dataset has been added. The repository covers various chapters on topics such as Transformers, fine-tuning language models, entity recognition, summarization, document embedding, question answering, and more.
awesome-llms-fine-tuning
This repository is a curated collection of resources for fine-tuning Large Language Models (LLMs) like GPT, BERT, RoBERTa, and their variants. It includes tutorials, papers, tools, frameworks, and best practices to aid researchers, data scientists, and machine learning practitioners in adapting pre-trained models to specific tasks and domains. The resources cover a wide range of topics related to fine-tuning LLMs, providing valuable insights and guidelines to streamline the process and enhance model performance.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.

awesome-llm-attributions
This repository focuses on unraveling the sources that large language models tap into for attribution or citation. It delves into the origins of facts, their utilization by the models, the efficacy of attribution methodologies, and challenges tied to ambiguous knowledge reservoirs, biases, and pitfalls of excessive attribution.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.

agentica
Agentica is a human-centric framework for building large language model agents. It provides functionalities for planning, memory management, tool usage, and supports features like reflection, planning and execution, RAG, multi-agent, multi-role, and workflow. The tool allows users to quickly code and orchestrate agents, customize prompts, and make API calls to various services. It supports API calls to OpenAI, Azure, Deepseek, Moonshot, Claude, Ollama, and Together. Agentica aims to simplify the process of building AI agents by providing a user-friendly interface and a range of functionalities for agent development.
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.
intelligence-layer-sdk
The Aleph Alpha Intelligence Layer️ offers a comprehensive suite of development tools for crafting solutions that harness the capabilities of large language models (LLMs). With a unified framework for LLM-based workflows, it facilitates seamless AI product development, from prototyping and prompt experimentation to result evaluation and deployment. The Intelligence Layer SDK provides features such as Composability, Evaluability, and Traceability, along with examples to get started. It supports local installation using poetry, integration with Docker, and access to LLM endpoints for tutorials and tasks like Summarization, Question Answering, Classification, Evaluation, and Parameter Optimization. The tool also offers pre-configured tasks for tasks like Classify, QA, Search, and Summarize, serving as a foundation for custom development.
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.
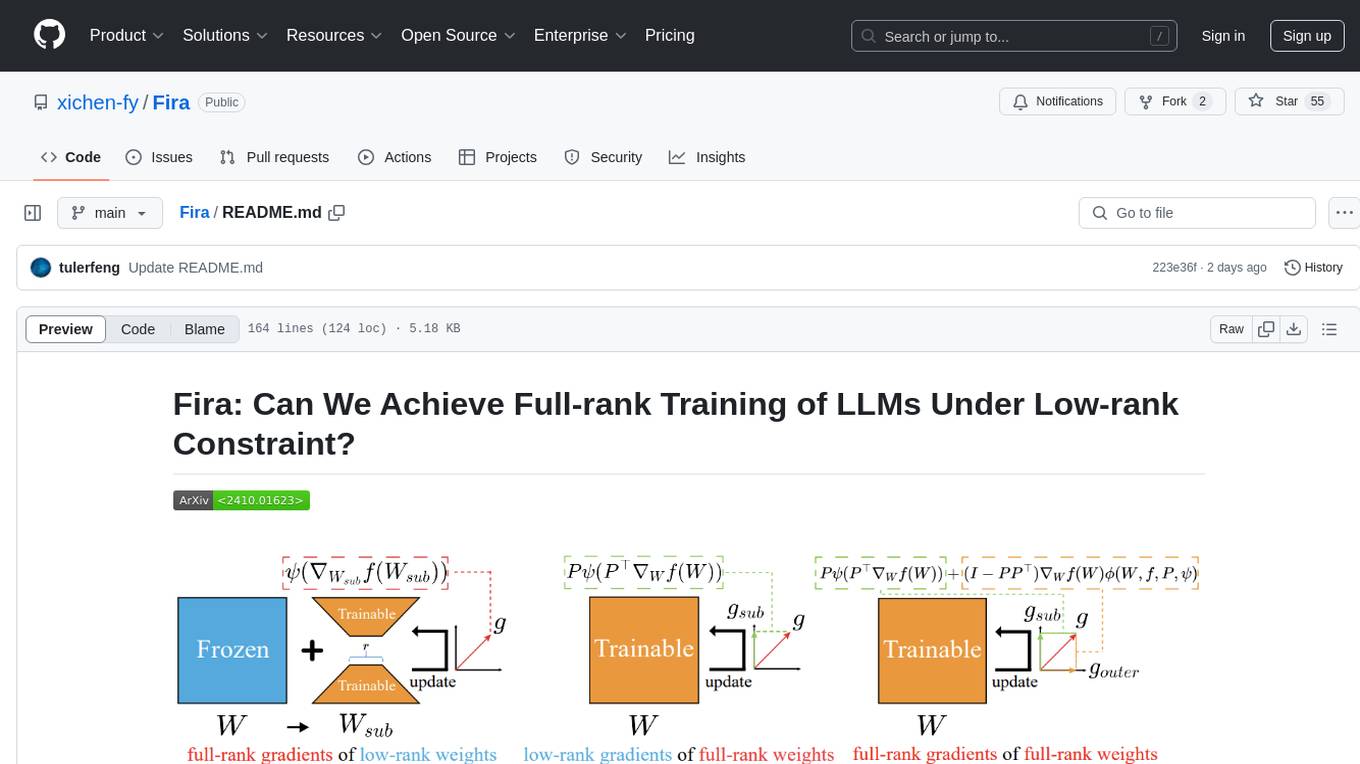
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.
vnc-lm
vnc-lm is a Discord bot designed for messaging with language models. Users can configure model parameters, branch conversations, and edit prompts to enhance responses. The bot supports various providers like OpenAI, Huggingface, and Cloudflare Workers AI. It integrates with ollama and LiteLLM, allowing users to access a wide range of language model APIs through a single interface. Users can manage models, switch between models, split long messages, and create conversation branches. LiteLLM integration enables support for OpenAI-compatible APIs and local LLM services. The bot requires Docker for installation and can be configured through environment variables. Troubleshooting tips are provided for common issues like context window problems, Discord API errors, and LiteLLM issues.
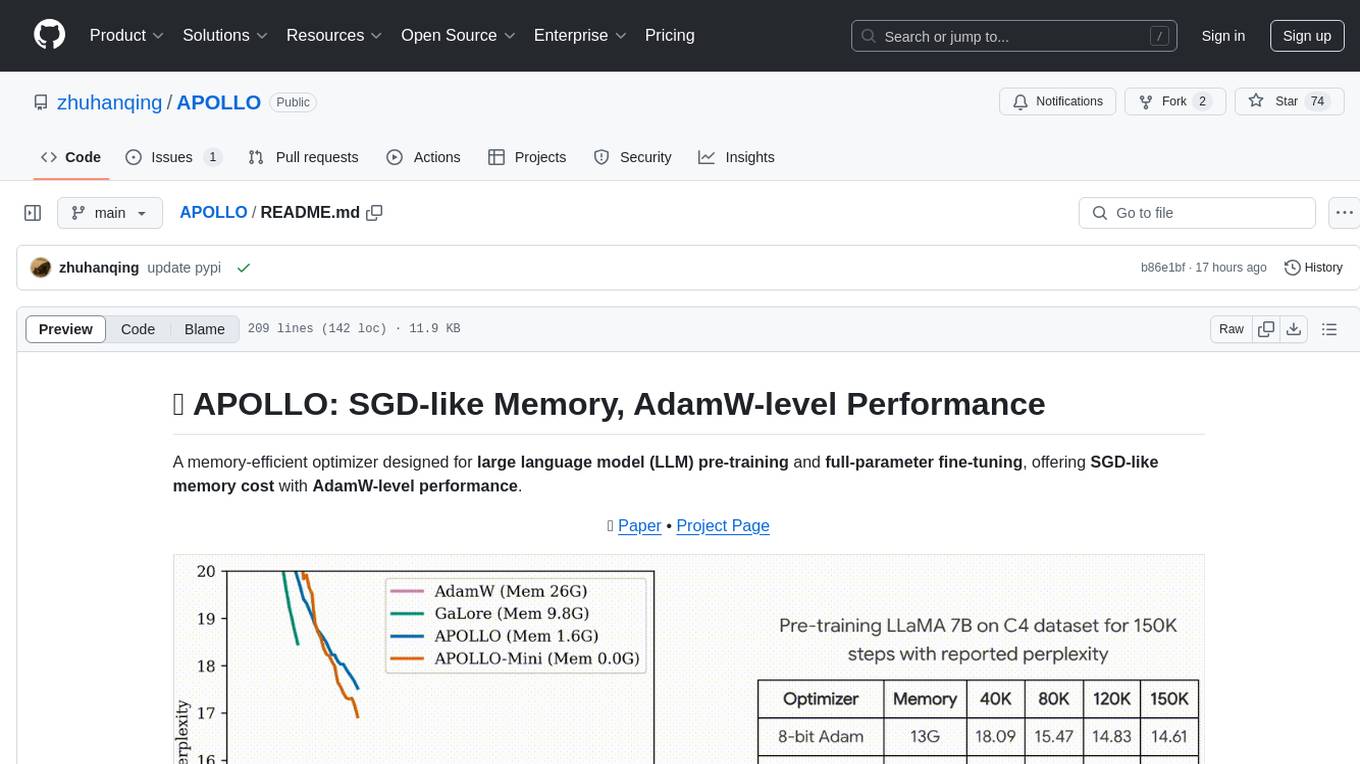
APOLLO
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.
text2text
Text2Text is a comprehensive language modeling toolkit that offers a wide range of functionalities for text processing and generation. It provides tools for tokenization, embedding, TF-IDF calculations, BM25 scoring, indexing, translation, data augmentation, distance measurement, training/finetuning models, language identification, and serving models via a web server. The toolkit is designed to be user-friendly and efficient, offering a variety of features for natural language processing tasks.

Hands-On-Large-Language-Models-CN
Hands-On Large Language Models CN(ZH) is a Chinese version of the book 'Hands-On Large Language Models' by Jay Alammar and Maarten Grootendorst. It provides detailed code annotations and additional insights, offers Notebook versions suitable for Chinese network environments, utilizes openbayes for free GPU access, allows convenient environment setup with vscode, and includes accompanying Chinese language videos on platforms like Bilibili and YouTube. The book covers various chapters on topics like Tokens and Embeddings, Transformer LLMs, Text Classification, Text Clustering, Prompt Engineering, Text Generation, Semantic Search, Multimodal LLMs, Text Embedding Models, Fine-tuning Models, and more.
Prompt_Engineering
Prompt Engineering Techniques is a comprehensive repository for learning, building, and sharing prompt engineering techniques, from basic concepts to advanced strategies for leveraging large language models. It provides step-by-step tutorials, practical implementations, and a platform for showcasing innovative prompt engineering techniques. The repository covers fundamental concepts, core techniques, advanced strategies, optimization and refinement, specialized applications, and advanced applications in prompt engineering.
RagaAI-Catalyst
RagaAI Catalyst is a comprehensive platform designed to enhance the management and optimization of LLM projects. It offers features such as project management, dataset management, evaluation management, trace management, prompt management, synthetic data generation, and guardrail management. These functionalities enable efficient evaluation and safeguarding of LLM applications.
structured-logprobs
This Python library enhances OpenAI chat completion responses by providing detailed information about token log probabilities. It works with OpenAI Structured Outputs to ensure model-generated responses adhere to a JSON Schema. Developers can analyze and incorporate token-level log probabilities to understand the reliability of structured data extracted from OpenAI models.
LLM-Finetune
LLM-Finetune is a repository for fine-tuning language models for various NLP tasks such as text classification and named entity recognition. It provides instructions and scripts for training and inference using models like Qwen2-VL and GLM4. The repository also includes datasets for tasks like text classification, named entity recognition, and multimodal tasks. Users can easily prepare the environment, download datasets, train models, and perform inference using the provided scripts and notebooks. Additionally, the repository references SwanLab, an AI training record, analysis, and visualization tool.
backtrack_sampler
Backtrack Sampler is a framework for experimenting with custom sampling algorithms that can backtrack the latest generated tokens. It provides a simple and easy-to-understand codebase for creating new sampling strategies. Users can implement their own strategies by creating new files in the `/strategy` directory. The repo includes examples for usage with llama.cpp and transformers, showcasing different strategies like Creative Writing, Anti-slop, Debug, Human Guidance, Adaptive Temperature, and Replace. The goal is to encourage experimentation and customization of backtracking algorithms for language models.
open-unlearning
OpenUnlearning is an easily extensible framework that unifies LLM unlearning evaluation benchmarks. It provides efficient implementations of TOFU and MUSE unlearning benchmarks, supporting 5 unlearning methods, 3+ datasets, 6+ evaluation metrics, and 7+ LLMs. Users can easily extend the framework to incorporate more variants, collaborate by adding new benchmarks, unlearning methods, datasets, and evaluation metrics, and drive progress in the field.
100x-LLM
This repository contains code snippets and examples from the 100x Applied AI cohort lectures. It includes implementations of LLM Workflows, RAG (Retrieval Augmented Generation), Agentic Patterns, Chat Completions with various providers, Function Calling, and more. The repository structure consists of core components like LLM Workflows, RAG Implementations, Agentic Patterns, Chat Completions, Function Calling, Hugging Face Integration, and additional components for various agent implementations, presentation generation, Notion API integration, FastAPI-based endpoints, authentication implementations, and LangChain usage examples.

MM-RLHF
MM-RLHF is a comprehensive project for aligning Multimodal Large Language Models (MLLMs) with human preferences. It includes a high-quality MLLM alignment dataset, a Critique-Based MLLM reward model, a novel alignment algorithm MM-DPO, and benchmarks for reward models and multimodal safety. The dataset covers image understanding, video understanding, and safety-related tasks with model-generated responses and human-annotated scores. The reward model generates critiques of candidate texts before assigning scores for enhanced interpretability. MM-DPO is an alignment algorithm that achieves performance gains with simple adjustments to the DPO framework. The project enables consistent performance improvements across 10 dimensions and 27 benchmarks for open-source MLLMs.

LLMVoX
LLMVoX is a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming Text-to-Speech (TTS) system designed to convert text outputs from Large Language Models into high-fidelity streaming speech with low latency. It achieves significantly lower Word Error Rate compared to speech-enabled LLMs while operating at comparable latency and speech quality. Key features include being lightweight & fast with only 30M parameters, LLM-agnostic for easy integration with existing models, multi-queue streaming for continuous speech generation, and multilingual support for easy adaptation to new languages.
LLM-eval-survey
LLM-eval-survey is a collection of papers and resources related to evaluations on large language models. It includes a survey on the evaluation of large language models, covering various aspects such as natural language processing, robustness, ethics, biases, trustworthiness, social science, natural science, engineering, medical applications, agent applications, and other applications. The repository provides a comprehensive overview of different evaluation tasks and benchmarks for large language models.
llm
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), DeepSeek, Ollama, and LlamaCpp. The toolkit provides full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema). It offers a single unified interface for multiple providers, zero dependencies outside Ruby's standard library, smart API design, and optional per-provider process-wide connection pool. Features include chat, agents, media support (text-to-speech, transcription, translation, image generation, editing), embeddings, model management, and more.
LLM_book
LLM_book is a learning record and roadmap for programmers with a certain AI foundation to learn Large Language Models (LLM). It covers topics such as PyTorch basics, Transformer architecture, langchain basics, foundational concepts of large models, fine-tuning methods, RAG (Retrieval-Augmented Generation), and building intelligent agents using LLM. The repository provides learning materials, code implementations, and documentation to help users progress in understanding and implementing LLM technologies.
haiku.rag
Haiku RAG is a Retrieval-Augmented Generation (RAG) library that utilizes LanceDB as a local vector database. It supports semantic and full-text search, hybrid search with Reciprocal Rank Fusion, multiple embedding and QA providers, default search result reranking, question answering, file monitoring, and various file formats. It can be used via CLI or Python API, and can serve as tools for AI assistants like Claude Desktop. The library offers features for document management and search, with detailed documentation available.
sparql-llm
This project provides tools to enhance the capabilities of Large Language Models (LLMs) in generating SPARQL queries for specific endpoints. It includes reusable components, a chat web service, and an experimental MCP server. The system integrates Retrieval-Augmented Generation (RAG) and SPARQL query validation through endpoint schemas to ensure accurate query generation on large-scale knowledge graphs. Components can work independently or as part of a chat-based system requiring endpoint metadata. Features include metadata extraction, SPARQL query validation, deployable chat system, and live example chat system at chat.expasy.org.
MaiBot
MaiBot is an interactive intelligent agent based on a large language model. It aims to be an 'entity' active in QQ group chats, focusing on human-like interactions. It features personification in language style, behavior planning, expression learning, plugin system for unlimited extensions, and emotion expression. The project's design philosophy emphasizes creating a 'life form' in group chats that feels real rather than perfect, with the goal of providing companionship through an AI that makes mistakes and has its own perceptions and thoughts. The code is open-source, but the runtime data of MaiBot is intended to remain closed to maintain its autonomy and conversational nature.
base-llm
Base LLM is a comprehensive learning tutorial from traditional Natural Language Processing (NLP) to Large Language Models (LLM), covering core technologies such as word embeddings, RNN, Transformer architecture, BERT, GPT, and Llama series models. The project aims to help developers build a solid technical foundation by providing a clear path from theory to practical engineering. It covers NLP theory, Transformer architecture, pre-trained language models, advanced model implementation, and deployment processes.
20 - OpenAI Gpts
ReDev You v00400
Specialist in belief transformation using advanced NLP and visualization, now more powerful with a two-component structure.
💹 AI Trading Sentiment Surge
AI Trading Sentiment Surge - Dive into market trends with AI-powered sentiment analysis and NLP to guide investment strategies. 🌐📊🤖


Hero's GPT
Your AI ally for insightful guidance, emotional support, and personalized decision-making assistance.
GPT Insight Analyzer
Enhance GPT interactions with precise, insightful analysis. Uncover nuanced conversation depths with GPT Insight Analyzer. V.0.41 Start the dialogue—just say 'Hi'.

William Shakespeare
An AI that embodies the persona of William Shakespeare, offering first-person insights into his life and works, and generating creative content inspired by his literary contributions. It provides historical context, analysis, and can engage in Shakespearean-style dialogue.