
structured-logprobs
OpenAI's Structured Outputs with Logprobs
Stars: 155
This Python library enhances OpenAI chat completion responses by providing detailed information about token log probabilities. It works with OpenAI Structured Outputs to ensure model-generated responses adhere to a JSON Schema. Developers can analyze and incorporate token-level log probabilities to understand the reliability of structured data extracted from OpenAI models.
README:


![]()
![]()
![]()
This Python library is designed to enhance OpenAI chat completion responses by adding detailed information about token log probabilities. This library works with OpenAI Structured Outputs, which is a feature that ensures the model will always generate responses that adhere to your supplied JSON Schema, so you don't need to worry about the model omitting a required key, or hallucinating an invalid enum value. It provides utilities to analyze and incorporate token-level log probabilities into structured outputs, helping developers understand the reliability of structured data extracted from OpenAI models.

The primary goal of structured-logprobs is to provide insights into the reliability of extracted data. By analyzing token-level log probabilities, the library helps assess how likely each value generated from an LLM's structured outputs is.
The module contains a function for mapping characters to token indices (map_characters_to_token_indices) and two methods for incorporating log probabilities:
- Adding log probabilities as a separate field in the response (
add_logprobs). - Embedding log probabilities inline within the message content (
add_logprobs_inline).
To use this library, first create a chat completion response with the OpenAI Python SDK, then enhance the response with log probabilities. Here is an example of how to do that:
from openai import OpenAI
from openai.types import ResponseFormatJSONSchema
from structured_logprobs import add_logprobs, add_logprobs_inline
# Initialize the OpenAI client
client = OpenAI(api_key="your-api-key")
schema_path = "path-to-your-json-schema"
with open(schema_path) as f:
schema_content = json.load(f)
# Validate the schema content
response_schema = ResponseFormatJSONSchema.model_validate(schema_content)
# Create a chat completion request
completion = client.chat.completions.create(
model="gpt-4o-2024-08-06",
messages = [
{
"role": "system",
"content": (
"I have three questions. The first question is: What is the capital of France? "
"The second question is: Which are the two nicest colors? "
"The third question is: Can you roll a die and tell me which number comes up?"
),
}
],
logprobs=True,
response_format=response_schema.model_dump(by_alias=True),
)
chat_completion = add_logprobs(completion)
chat_completion_inline = add_logprobs_inline(completion)
print(chat_completion.log_probs[0])
{'capital_of_France': -5.5122365e-07, 'the_two_nicest_colors': [-0.0033997903, -0.011364183612649998], 'die_shows': -0.48048785}
print(chat_completion_inline.choices[0].message.content)
{"capital_of_France": "Paris", "capital_of_France_logprob": -6.704273e-07, "the_two_nicest_colors": ["blue", "green"], "die_shows": 5.0, "die_shows_logprob": -2.3782086}The response_format in the request body is an object specifying the format that the model must output. Setting to { "type": "json_schema", "json_schema": {...} } ensures the model will match your supplied JSON schema.
Below is the example of the JSON file that defines the schema used for validating the responses.
{
"type": "json_schema",
"json_schema": {
"name": "answears",
"description": "Response to questions in JSON format",
"schema": {
"type": "object",
"properties": {
"capital_of_France": { "type": "string" },
"the_two_nicest_colors": {
"type": "array",
"items": {
"type": "string",
"enum": ["red", "blue", "green", "yellow", "purple"]
}
},
"die_shows": { "type": "number" }
},
"required": ["capital_of_France", "the_two_nicest_colors", "die_shows"],
"additionalProperties": false
},
"strict": true
}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for structured-logprobs
Similar Open Source Tools
structured-logprobs
This Python library enhances OpenAI chat completion responses by providing detailed information about token log probabilities. It works with OpenAI Structured Outputs to ensure model-generated responses adhere to a JSON Schema. Developers can analyze and incorporate token-level log probabilities to understand the reliability of structured data extracted from OpenAI models.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.
trex
Trex is a tool that transforms unstructured data into structured data by specifying a regex or context-free grammar. It intelligently restructures data to conform to the defined schema. It offers a Python client for installation and requires an API key obtained by signing up at automorphic.ai. The tool supports generating structured JSON objects based on user-defined schemas and prompts. Trex aims to provide significant speed improvements, structured custom CFG and regex generation, and generation from JSON schema. Future plans include auto-prompt generation for unstructured ETL and more intelligent models.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.
VectorETL
VectorETL is a lightweight ETL framework designed to assist Data & AI engineers in processing data for AI applications quickly. It streamlines the conversion of diverse data sources into vector embeddings and storage in various vector databases. The framework supports multiple data sources, embedding models, and vector database targets, simplifying the creation and management of vector search systems for semantic search, recommendation systems, and other vector-based operations.
pipelex
Pipelex is an open-source devtool designed to transform how users build repeatable AI workflows. It acts as a Docker or SQL for AI operations, allowing users to create modular 'pipes' using different LLMs for structured outputs. These pipes can be connected sequentially, in parallel, or conditionally to build complex knowledge transformations from reusable components. With Pipelex, users can share and scale proven methods instantly, saving time and effort in AI workflow development.

llm-structured-output
This repository contains a library for constraining LLM generation to structured output, enforcing a JSON schema for precise data types and property names. It includes an acceptor/state machine framework, JSON acceptor, and JSON schema acceptor for guiding decoding in LLMs. The library provides reference implementations using Apple's MLX library and examples for function calling tasks. The tool aims to improve LLM output quality by ensuring adherence to a schema, reducing unnecessary output, and enhancing performance through pre-emptive decoding. Evaluations show performance benchmarks and comparisons with and without schema constraints.
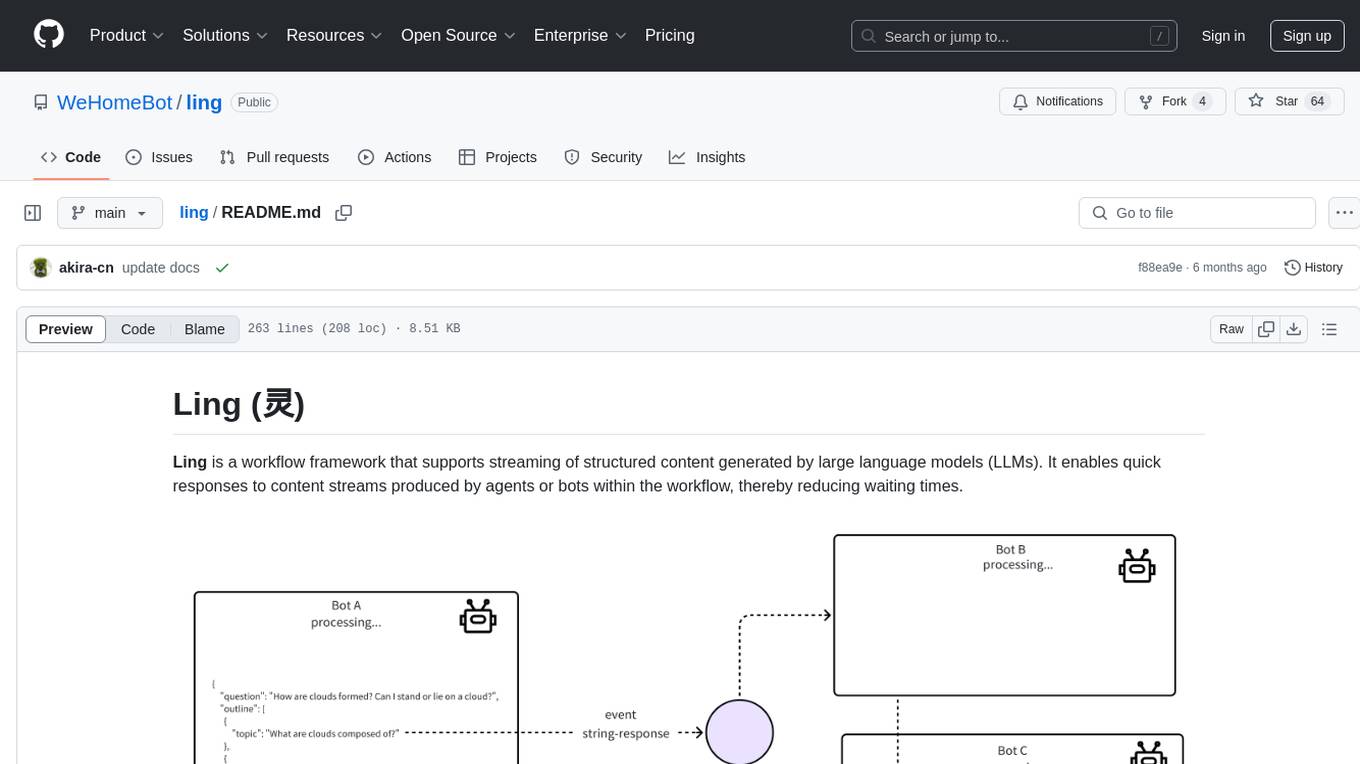
ling
Ling is a workflow framework supporting streaming of structured content from large language models. It enables quick responses to content streams, reducing waiting times. Ling parses JSON data streams character by character in real-time, outputting content in jsonuri format. It facilitates immediate front-end processing by converting content during streaming input. The framework supports data stream output via JSONL protocol, correction of token errors in JSON output, complex asynchronous workflows, status messages during streaming output, and Server-Sent Events.

openmacro
Openmacro is a multimodal personal agent that allows users to run code locally. It acts as a personal agent capable of completing and automating tasks autonomously via self-prompting. The tool provides a CLI natural-language interface for completing and automating tasks, analyzing and plotting data, browsing the web, and manipulating files. Currently, it supports API keys for models powered by SambaNova, with plans to add support for other hosts like OpenAI and Anthropic in future versions.
AICentral
AI Central is a powerful tool designed to take control of your AI services with minimal overhead. It is built on Asp.Net Core and dotnet 8, offering fast web-server performance. The tool enables advanced Azure APIm scenarios, PII stripping logging to Cosmos DB, token metrics through Open Telemetry, and intelligent routing features. AI Central supports various endpoint selection strategies, proxying asynchronous requests, custom OAuth2 authorization, circuit breakers, rate limiting, and extensibility through plugins. It provides an extensibility model for easy plugin development and offers enriched telemetry and logging capabilities for monitoring and insights.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.

ollama-ex
Ollama is a powerful tool for running large language models locally or on your own infrastructure. It provides a full implementation of the Ollama API, support for streaming requests, and tool use capability. Users can interact with Ollama in Elixir to generate completions, chat messages, and perform streaming requests. The tool also supports function calling on compatible models, allowing users to define tools with clear descriptions and arguments. Ollama is designed to facilitate natural language processing tasks and enhance user interactions with language models.
parea-sdk-py
Parea AI provides a SDK to evaluate & monitor AI applications. It allows users to test, evaluate, and monitor their AI models by defining and running experiments. The SDK also enables logging and observability for AI applications, as well as deploying prompts to facilitate collaboration between engineers and subject-matter experts. Users can automatically log calls to OpenAI and Anthropic, create hierarchical traces of their applications, and deploy prompts for integration into their applications.
For similar tasks
structured-logprobs
This Python library enhances OpenAI chat completion responses by providing detailed information about token log probabilities. It works with OpenAI Structured Outputs to ensure model-generated responses adhere to a JSON Schema. Developers can analyze and incorporate token-level log probabilities to understand the reliability of structured data extracted from OpenAI models.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.