
empower-functions
GPT-4 level function calling models for real-world tool using use cases
Stars: 202

Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.
README:
![]()
Empower Functions is a family of LLMs(large language models) that offer GPT-4 level capabilities for real-world "tool using" use cases, with full compatibility support to be served as a drop-in replacement.
Live Demo • Huggingface Repo • Website • Discord
New Empower Functions v1.1 We have just launched new v1.1 of the Empower Functions family. The updated v1.1 family has been fine-tuned based on Llama3.1 using an enhanced curated dataset. It has achieved state-of-the-art performance on the Berkeley Function Calling leader board:
 (captured on Sep 10, 2024)
(captured on Sep 10, 2024)
"tool using" refers to the ability of LLMs to interact with external APIs by recognizing when a function needs to be called and then generating JSON containing the necessary arguments based on user inputs. This capability is essential for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases.
Real-world use cases, particularly those involving conversational agents, often introduce complex requirements for LLMs. Models must be capable of retrieving context from multiple round of conversations(multi-turn), choosing between utilizing tools or engaging in standard dialogue ('auto' mode), and asking for clarification if any parameters are missing(clarification). Furthermore, they should integrate responses with tool outputs in a streaming fashion. Additionally, when multiple tools are required to complete a task, models should efficiently execute multiple functions either in parallel (parallel calling) or sequentially with dependencies (sequential calling).
For example, below is a screenshot demonstrating how the model is used in a medical center coordinator bot. You can explore this further in our live demo.

| Model | Specs | Links | Notes |
|---|---|---|---|
| llama3-empower-functions-small | 128k context, based on Llama3.1 8B | model, gguf | Most cost-effective, locally runnable |
| llama3-empower-functions-large | 128k context, based on Llama3.1 70B | model | Best accuracy |
We have tested and the family of models in following setup:
- empower-functions-small: fp16 on 1xA100 40G, GGUF and 4bit GGUF on Macbook M2 Pro with 32G RAM, in minimal the 4bit GGUF version requires 7.56G RAM.
- empower-functions-large: fp16 on 4xA100 80G
Running locally is only supported by the
llama3-empower-functions-smallmodel. To use other models, please use our API.
Local running is supported through the empower_functions pip package, make sure you install it first by running pip install empower-functions.
If you encounter errors like RuntimeError: Failed to load shared library, (mach-o file, but is an incompatible architecture (have 'x86_64', need 'arm64')), please re-install the llama-cpp-python package by running
CMAKE_ARGS="-DCMAKE_OSX_ARCHITECTURES=arm64 -DCMAKE_APPLE_SILICON_PROCESSOR=arm64 -DLLAMA_METAL=on" pip install --upgrade --verbose --force-reinstall --no-cache-dir llama-cpp-python
Running a Local OpenAI Compatible Server
We leverage the llama-cpp-python project to run the model locally. To start a local OpenAI compatible server, you'll need to follow the steps below:
- Download the GGUF model from our huggingface repo
- Run the command
python -m empower_functions.server --model <path to GGUF model> --chat_format empower-functions
You should see the following output when the server is ready:
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
Then you can use the OpenAI SDK to connect to the server. See below for a basic example:
import openai
import json
client = openai.OpenAI(
base_url = "http://localhost:8000/v1",
api_key = "YOUR_API_KEY"
)
messages = [
{"role": "user", "content": "What's the weather in San Francisco?"}
]
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA"
}
},
"required": ["location"]
}
}
}
]
chat_completion = client.chat.completions.create(
model="does_not_matter",
messages=messages,
tools=tools,
temperature=0,
tool_choice="auto"
)
print(chat_completion)Running in a Python Environment
You can directly call the model in your python environment through the llama-cpp-python package with the chat handler provided in the empower_functions package. See below for a basic example. For more detailed example, please refer to the python script.
import json
from empower_functions import EmpowerFunctionsCompletionHandler
from llama_cpp.llama_tokenizer import LlamaHFTokenizer
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="empower-dev/llama3-empower-functions-small-gguf",
filename="ggml-model-Q4_K_M.gguf",
chat_format="llama-3",
chat_handler=EmpowerFunctionsCompletionHandler(),
tokenizer=LlamaHFTokenizer.from_pretrained("empower-dev/llama3-empower-functions-small-gguf"),
n_gpu_layers=0
)
# You can then use the llm object to chat with the model
messages = [
{"role": "user", "content": "What's the weather in San Francisco?"}
]
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA"
}
},
"required": ["location"]
}
}
}
]
result = llm.create_chat_completion(
messages = messages,
tools=tools,
tool_choice="auto",
max_tokens=128
)
print(json.dumps(result["choices"][0], indent=2))Running in Windows with Cuda
-
install Nvidia toolkit (I used cuda 12.1): https://developer.nvidia.com/cuda-12-1-1-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local
-
install Visual Studio with: C++ CMake tools for Windows. C++ core features
-
run this command with the empower_functions virtual environment active in the Windows command prompt (command prompt, not PowerShell):
set FORCE_CMAKE=1 && set CMAKE_ARGS=-DGGML_CUDA=on -DLLAMA_AVX=off -DLLAMA_AVX2=off -DLLAMA_FMA=off && pip install llama-cpp-python --no-cache-dir --force-reinstall --verbose
That will take awhile but will overwrite the normal llama-cpp-python module with the Cuda support one.
- then run the server with the virtual environment active with a command like this:
python -m empower_functions.server --model C:\Github\empower-functions-gpu\models\ggml-model-Q4_K_M.gguf --chat_format empower-functions --port 8001 --n_ctx 8196 --n_gpu_layers 20
replacing the path with the path where the model is saved on your computer and adjusting n_ctx to the desired context and n_gpu_layers to the amount of the layers to offload to the GPU.
The empower platform offers an API that is fully compatible with the OpenAI API, allowing you to directly use the OpenAI SDK. An example is shown below. See below for a basic example, more details can be found here.
Currently streaming and JSON model is only available in Empower API.
from openai import OpenAI
client = OpenAI(
base_url="https://app.empower.dev/api/v1",
api_key="YOU_API_KEY"
)
response = client.chat.completions.create(
model="empower-functions",
messages=[{"role": "user",
"content": "What's the weather in San Francisco and Los Angeles in Celsius?"}],
temperature=0,
tools=[{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}],
)
response_message = response.choices[0].message.tool_calls
print(response_message)The Empower functions model family has been tuned to natively produce JSON. We provide utilities in our Python package to prompt OpenAI-formatted messages. See below for a basic example, more details can be found here.
from transformers import AutoModelForCausalLM, AutoTokenizer
from prompt import prompt_messages
device = "cuda"
model_path = 'empower-dev/empower-functions-small'
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
]
messages = [
{'role': 'user', 'content': 'What\'s the weather in San Francisco and Los Angles in Celsius?'},
]
messages = prompt_messages(messages, functions)
model_inputs = tokenizer.apply_chat_template(
messages, return_tensors="pt").to(model.device)
generated_ids = model.generate(model_inputs, max_new_tokens=128)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])Empower's function models are fine-tuned based on state-of-the-art OSS models. We divided the training into two phases.
First, we perform SFT(supervised fine-tuning) using over 100k rows of hand-curated, high-quality conversations involving function calling. These conversations cover different scenarios such as single turn, multi-turn, and parallel calling. Specifically, the model is trained to use beginning tokens to determine whether it is calling functions or returning regular conversation (using and tags). It then returns function calls as JSON or conversations as usual, making streaming integration very straightforward. The SFT sets the model up with a very strong foundation covering various scenarios for general use cases.
Next, we apply DPO (Directly Preference Optimization) for trickier scenario where SFT (Supervised Fine-Tuning) is less effective. For instance, when function specifications include examples for arguments, we want to prevent the model from hallucinating argument values from these examples. We have found DPO to be very effective in correcting such misbehavior with a relatively small amount of data.
Finally, we are committed to continuously optimizing the model for better quality across a wider range of use cases and scenarios :) We can further fine-tune the model based on your specific needs. Please contact us if you have any use-case-specific requirements!
We evaluate our models against the Berkeley Function Calling benchmark and both of the 8B and 70B version have achieved the state of the art performance on its size:
(captured on Sep 10, 2024)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for empower-functions
Similar Open Source Tools
empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.
ai-dev-2024-ml-workshop
The 'ai-dev-2024-ml-workshop' repository contains materials for the Deploy and Monitor ML Pipelines workshop at the AI_dev 2024 conference in Paris, focusing on deployment designs of machine learning pipelines using open-source applications and free-tier tools. It demonstrates automating data refresh and forecasting using GitHub Actions and Docker, monitoring with MLflow and YData Profiling, and setting up a monitoring dashboard with Quarto doc on GitHub Pages.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.

llm-structured-output
This repository contains a library for constraining LLM generation to structured output, enforcing a JSON schema for precise data types and property names. It includes an acceptor/state machine framework, JSON acceptor, and JSON schema acceptor for guiding decoding in LLMs. The library provides reference implementations using Apple's MLX library and examples for function calling tasks. The tool aims to improve LLM output quality by ensuring adherence to a schema, reducing unnecessary output, and enhancing performance through pre-emptive decoding. Evaluations show performance benchmarks and comparisons with and without schema constraints.
CoPilot
TigerGraph CoPilot is an AI assistant that combines graph databases and generative AI to enhance productivity across various business functions. It includes three core component services: InquiryAI for natural language assistance, SupportAI for knowledge Q&A, and QueryAI for GSQL code generation. Users can interact with CoPilot through a chat interface on TigerGraph Cloud and APIs. CoPilot requires LLM services for beta but will support TigerGraph's LLM in future releases. It aims to improve contextual relevance and accuracy of answers to natural-language questions by building knowledge graphs and using RAG. CoPilot is extensible and can be configured with different LLM providers, graph schemas, and LangChain tools.

otto-m8
otto-m8 is a flowchart based automation platform designed to run deep learning workloads with minimal to no code. It provides a user-friendly interface to spin up a wide range of AI models, including traditional deep learning models and large language models. The tool deploys Docker containers of workflows as APIs for integration with existing workflows, building AI chatbots, or standalone applications. Otto-m8 operates on an Input, Process, Output paradigm, simplifying the process of running AI models into a flowchart-like UI.
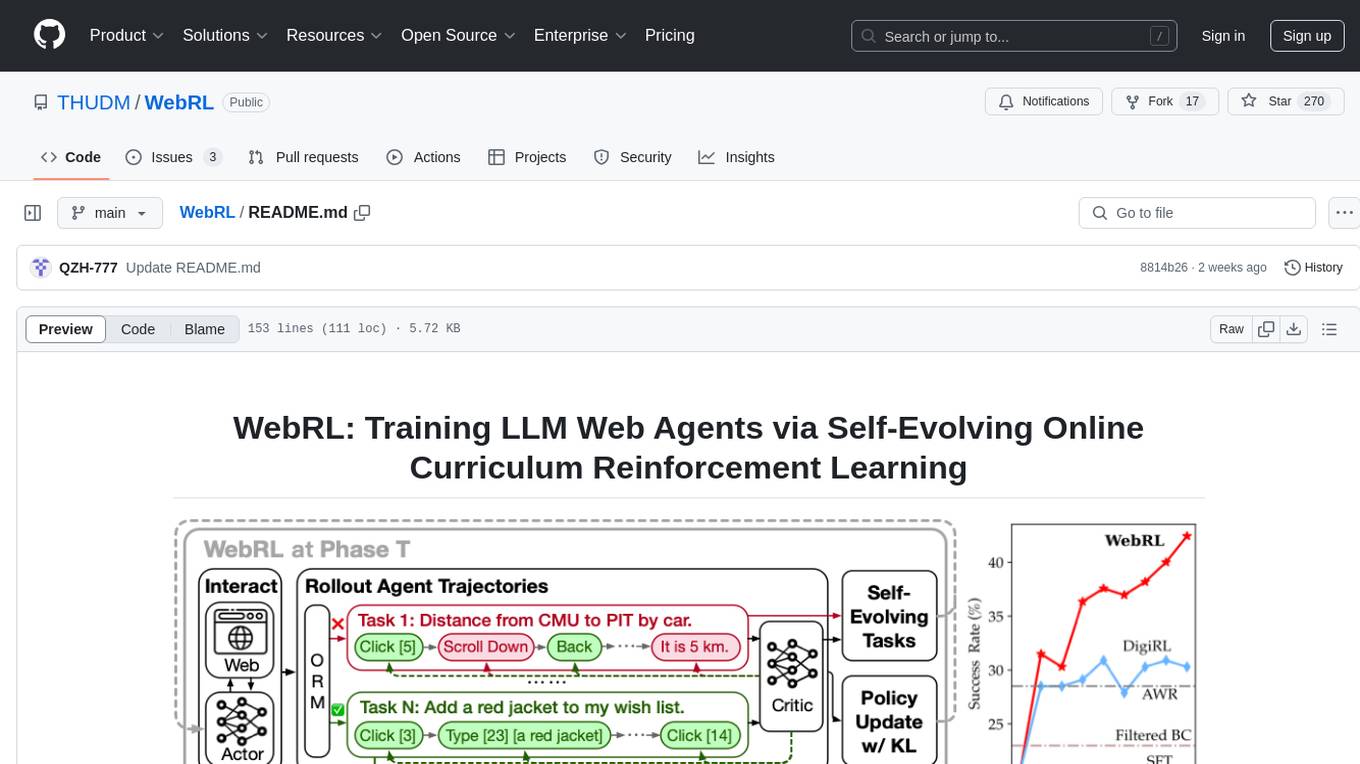
WebRL
WebRL is a self-evolving online curriculum learning framework designed for training web agents in the WebArena environment. It provides model checkpoints, training instructions, and evaluation processes for training the actor and critic models. The tool enables users to generate new instructions and interact with WebArena to configure tasks for training and evaluation.

Toolio
Toolio is an OpenAI-like HTTP server API implementation that supports structured LLM response generation, making it conform to a JSON schema. It is useful for reliable tool calling and agentic workflows based on schema-driven output. Toolio is based on the MLX framework for Apple Silicon, specifically M1/M2/M3/M4 Macs. It allows users to host MLX-format LLMs for structured output queries and provides a command line client for easier usage of tools. The tool also supports multiple tool calls and the creation of custom tools for specific tasks.

awadb
AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.
chatmemory
ChatMemory is a simple yet powerful long-term memory manager that facilitates communication between AI and users. It organizes conversation data into history, summary, and knowledge entities, enabling quick retrieval of context and generation of clear, concise answers. The tool leverages vector search on summaries/knowledge and detailed history to provide accurate responses. It balances speed and accuracy by using lightweight retrieval and fallback detailed search mechanisms, ensuring efficient memory management and response generation beyond mere data retrieval.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.
pipelex
Pipelex is an open-source devtool designed to transform how users build repeatable AI workflows. It acts as a Docker or SQL for AI operations, allowing users to create modular 'pipes' using different LLMs for structured outputs. These pipes can be connected sequentially, in parallel, or conditionally to build complex knowledge transformations from reusable components. With Pipelex, users can share and scale proven methods instantly, saving time and effort in AI workflow development.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

LightAgent
LightAgent is a lightweight, open-source Agentic AI development framework with memory, tools, and a tree of thought. It supports multi-agent collaboration, autonomous learning, tool integration, complex task handling, and multi-model support. It also features a streaming API, tool generator, agent self-learning, adaptive tool mechanism, and more. LightAgent is designed for intelligent customer service, data analysis, automated tools, and educational assistance.
llm-strategy
The 'llm-strategy' repository implements the Strategy Pattern using Large Language Models (LLMs) like OpenAI’s GPT-3. It provides a decorator 'llm_strategy' that connects to an LLM to implement abstract methods in interface classes. The package uses doc strings, type annotations, and method/function names as prompts for the LLM and can convert the responses back to Python data. It aims to automate the parsing of structured data by using LLMs, potentially reducing the need for manual Python code in the future.
For similar tasks
empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

airbyte-connectors
This repository contains Airbyte connectors used in Faros and Faros Community Edition platforms as well as Airbyte Connector Development Kit (CDK) for JavaScript/TypeScript.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

unstract
Unstract is a no-code platform that enables users to launch APIs and ETL pipelines to structure unstructured documents. With Unstract, users can go beyond co-pilots by enabling machine-to-machine automation. Unstract's Prompt Studio provides a simple, no-code approach to creating prompts for LLMs, vector databases, embedding models, and text extractors. Users can then configure Prompt Studio projects as API deployments or ETL pipelines to automate critical business processes that involve complex documents. Unstract supports a wide range of LLM providers, vector databases, embeddings, text extractors, ETL sources, and ETL destinations, providing users with the flexibility to choose the best tools for their needs.

Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation
For similar jobs
EDDI
E.D.D.I (Enhanced Dialog Driven Interface) is an enterprise-certified chatbot middleware that offers advanced prompt and conversation management for Conversational AI APIs. Developed in Java using Quarkus, it is lean, RESTful, scalable, and cloud-native. E.D.D.I is highly scalable and designed to efficiently manage conversations in AI-driven applications, with seamless API integration capabilities. Notable features include configurable NLP and Behavior rules, support for multiple chatbots running concurrently, and integration with MongoDB, OAuth 2.0, and HTML/CSS/JavaScript for UI. The project requires Java 21, Maven 3.8.4, and MongoDB >= 5.0 to run. It can be built as a Docker image and deployed using Docker or Kubernetes, with additional support for integration testing and monitoring through Prometheus and Kubernetes endpoints.
empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.
aiotdlib
aiotdlib is a Python asyncio Telegram client based on TDLib. It provides automatic generation of types and functions from tl schema, validation, good IDE type hinting, and high-level API methods for simpler work with tdlib. The package includes prebuilt TDLib binaries for macOS (arm64) and Debian Bullseye (amd64). Users can use their own binary by passing `library_path` argument to `Client` class constructor. Compatibility with other versions of the library is not guaranteed. The tool requires Python 3.9+ and users need to get their `api_id` and `api_hash` from Telegram docs for installation and usage.
amadeus-java
Amadeus Java SDK provides a rich set of APIs for the travel industry, allowing developers to access various functionalities such as flight search, booking, airport information, and more. The SDK simplifies interaction with the Amadeus API by providing self-contained code examples and detailed documentation. Developers can easily make API calls, handle responses, and utilize features like pagination and logging. The SDK supports various endpoints for tasks like flight search, booking management, airport information retrieval, and travel analytics. It also offers functionalities for hotel search, booking, and sentiment analysis. Overall, the Amadeus Java SDK is a comprehensive tool for integrating Amadeus APIs into Java applications.
llms
LLMs is a universal LLM API transformation server designed to standardize requests and responses between different LLM providers such as Anthropic, Gemini, and Deepseek. It uses a modular transformer system to handle provider-specific API formats, supporting real-time streaming responses and converting data into standardized formats. The server transforms requests and responses to and from unified formats, enabling seamless communication between various LLM providers.
java-genai
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.

ProxyPilot
ProxyPilot is a powerful local API proxy tool built in Go that eliminates the need for separate API keys when using Claude Code, Codex, Gemini, Kiro, and Qwen subscriptions with any AI coding tool. It handles OAuth authentication, token management, and API translation automatically, providing a single server to route requests. The tool supports multiple authentication providers, universal API translation, tool calling repair, extended thinking models, OAuth integration, multi-account support, quota auto-switching, usage statistics tracking, context compression, agentic harness for coding agents, session memory, system tray app, auto-updates, rollback support, and over 60 management APIs. ProxyPilot also includes caching layers for response and prompt caching to reduce latency and token usage.

wenda
Wenda is a platform for large-scale language model invocation designed to efficiently generate content for specific environments, considering the limitations of personal and small business computing resources, as well as knowledge security and privacy issues. The platform integrates capabilities such as knowledge base integration, multiple large language models for offline deployment, auto scripts for additional functionality, and other practical capabilities like conversation history management and multi-user simultaneous usage.