
airbyte-connectors
Airbyte connectors (sources & destinations) + Airbyte CDK for JavaScript/TypeScript
Stars: 121

This repository contains Airbyte connectors used in Faros and Faros Community Edition platforms as well as Airbyte Connector Development Kit (CDK) for JavaScript/TypeScript.
README:
![]()
![]()
![]()

This repository contains Airbyte connectors used in Faros and Faros Community Edition platforms as well as Airbyte Connector Development Kit (CDK) for JavaScript/TypeScript.
See the READMEs inside destinations/ and sources/ subfolders for more information on each connector.
| Component | Code | Installation | Version |
|---|---|---|---|
| Airbyte CDK for JavaScript/TypeScript | faros-airbyte-cdk | npm i faros-airbyte-cdk |
 |
| AgileAccelerator Source | sources/agileaccelerator-source | docker pull farosai/airbyte-agileaccelerator-source |
 |
| Asana Source | sources/asana-source | docker pull farosai/airbyte-asana-source |
 |
| AWS CloudWatch Metrics Source | sources/aws-cloudwatch-metrics-source | docker pull farosai/airbyte-aws-cloudwatch-metrics-source |
 |
| Azure Active Directory Source | sources/azureactivedirectory-source | docker pull farosai/airbyte-azureactivedirectory-source |
 |
| Azure Pipeline Source | sources/azurepipeline-source | docker pull farosai/airbyte-azurepipeline-source |
 |
| Azure Repos Source | sources/azure-repos-source | docker pull farosai/airbyte-azure-repos-source |
 |
| Azure Workitems Source | sources/azure-workitems-source | docker pull farosai/airbyte-azure-workitems-source |
 |
| Backlog Source | sources/backlog-source | docker pull farosai/airbyte-backlog-source |
 |
| BambooHR Source | sources/bamboohr-source | docker pull farosai/airbyte-bamboohr-source |
 |
| Bitbucket Source | sources/bitbucket-source | docker pull farosai/airbyte-bitbucket-source |
 |
| Bitbucket Server Source | sources/bitbucket-server-source | docker pull farosai/airbyte-bitbucket-server-source |
 |
| Buildkite Source | sources/buildkite-source | docker pull farosai/airbyte-buildkite-source |
 |
| Customer.IO Source | sources/customer-io-source | docker pull farosai/airbyte-customer-io-source |
 |
| Cursor Source | sources/cursor-source | docker pull farosai/airbyte-cursor-source |
 |
| CircleCI Source | sources/circleci-source | docker pull farosai/airbyte-circleci-source |
 |
| Claude Source | sources/claude-source | docker pull farosai/airbyte-claude-source |
 |
| ClickUp Source | sources/clickup-source | docker pull farosai/airbyte-clickup-source |
 |
| Datadog Source | sources/datadog-source | docker pull farosai/airbyte-datadog-source |
 |
| Docker Source | sources/docker-source | docker pull farosai/airbyte-docker-source |
 |
| Faros Destination | destinations/airbyte-faros-destination |
npm i airbyte-faros-destination or docker pull farosai/airbyte-faros-destination
|
 
|
| Faros GraphQL Source | sources/faros-graphql-source | docker pull farosai/airbyte-faros-graphql-source |
 |
| Faros Graph Doctor Source | sources/faros-graphdoctor-source | docker pull farosai/airbyte-faros-graphdoctor-source |
 |
| Files Source | sources/files-source | docker pull farosai/airbyte-files-source |
 |
| FireHydrant Source | sources/firehydrant-source | docker pull farosai/airbyte-firehydrant-source |
 |
| GitHub Source | sources/github-source | docker pull farosai/airbyte-github-source |
 |
| GitLab Source | sources/gitlab-source | docker pull farosai/airbyte-gitlab-source |
 |
| Google Calendar Source | sources/googlecalendar-source | docker pull farosai/airbyte-googlecalendar-source |
 |
| Google Drive Source | sources/googledrive-source | docker pull farosai/airbyte-googledrive-source |
 |
| Harness Source | sources/harness-source | docker pull farosai/airbyte-harness-source |
 |
| Jenkins Source | sources/jenkins-source | docker pull farosai/airbyte-jenkins-source |
 |
| Jira Source | sources/jira-source | docker pull farosai/airbyte-jira-source |
 |
| Okta Source | sources/okta-source | docker pull farosai/airbyte-okta-source |
 |
| Octopus Source | sources/octopus-source | docker pull farosai/airbyte-octopus-source |
 |
| OpsGenie Source | sources/opsgenie-source | docker pull farosai/airbyte-opsgenie-source |
 |
| PagerDuty Source | sources/pagerduty-source | docker pull farosai/airbyte-pagerduty-source |
 |
| Phabricator Source | sources/phabricator-source | docker pull farosai/airbyte-phabricator-source |
 |
| ServiceNow Source | sources/servicenow-source | docker pull farosai/airbyte-servicenow-source |
 |
| SemaphoreCI Source | sources/semaphoreci-source | docker pull farosai/airbyte-semaphoreci-source |
 |
| Shortcut Source | sources/shortcut-source | docker pull farosai/airbyte-shortcut-source |
 |
| Sheets Source | sources/sheets-source | docker pull farosai/airbyte-sheets-source |
 |
| SquadCast Source | sources/squadcast-source | docker pull farosai/airbyte-squadcast-source |
 |
| StatusPage Source | sources/statuspage-source | docker pull farosai/airbyte-statuspage-source |
 |
| TestRails Source | sources/testrails-source | docker pull farosai/airbyte-testrails-source |
 |
| Tromzo Source | sources/tromzo-source | docker pull farosai/airbyte-tromzo-source |
 |
| Trello Source | sources/trello-source | docker pull farosai/airbyte-trello-source |
 |
| Vanta Source | sources/vanta-source | docker pull farosai/airbyte-vanta-source |
 |
| VictorOps Source | sources/victorops-source | docker pull farosai/airbyte-victorops-source |
 |
| Windsurf Source | sources/windsurf-source | docker pull farosai/airbyte-windsurf-source |
 |
| Workday Source | sources/workday-source | docker pull farosai/airbyte-workday-source |
 |
| Wolken Source | sources/wolken-source | docker pull farosai/airbyte-wolken-source |
 |
| Xray Source | sources/xray-source | docker pull farosai/airbyte-xray-source |
 |
| Zephyr Source | sources/zephyr-source | docker pull farosai/airbyte-zephyr-source |
 |
- Install
nvm - Install Node.js
nvm install 22 && nvm use 22 - Install
Turborepoby runningnpm install turbo --global - Run
npm ito install dependencies for all projects (turbo cleanto clean all) - Run
turbo buildto build all projects (for a single project add scope, e.gturbo build --filter=airbyte-faros-destination) - Run
turbo testto test all projects (for a single project add scope, e.gturbo test --filter=airbyte-faros-destination) - Run
turbo lintto apply linter on all projects (for a single project add scope, e.gturbo lint --filter=airbyte-faros-destination)
👉 Follow our guide on how to develop a new source here.
Read more about Turborepo here.
To manage dependencies in this project, you can use the following commands:
-
Install Dependencies: Run
npm installto install all the necessary dependencies for the project. -
Update Dependencies: Use
npm updateto update all the dependencies to their latest versions. -
Check for Vulnerabilities: Run
npm auditto check for any vulnerabilities in the dependencies. -
Fix Vulnerabilities: Use
npm audit fixto automatically fix any vulnerabilities that can be resolved. -
Clean Dependencies: Run
npm pruneto remove any extraneous packages that are not listed inpackage.json.
In order to build a Docker image for a connector run the docker build command and set path and version arguments.
For example for Faros Destination connector run:
docker build . --build-arg path=destinations/airbyte-faros-destination --build-arg version=0.0.1 -t airbyte-faros-destinationAnd then run it:
docker run airbyte-faros-destination- If you encounter errors like
...: No such file or directorywhen running docker run commands on Windows, try to confirm all files in this repo are usingLFend of line. If not, convert them all to useLFinstead ofCRLF.
Create a new GitHub Release. The release workflow will automatically publish the packages to NPM and push Docker images to Docker Hub.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for airbyte-connectors
Similar Open Source Tools
airbyte-connectors
This repository contains Airbyte connectors used in Faros and Faros Community Edition platforms as well as Airbyte Connector Development Kit (CDK) for JavaScript/TypeScript.

phoenix
Phoenix is a tool that provides MLOps and LLMOps insights at lightning speed with zero-config observability. It offers a notebook-first experience for monitoring models and LLM Applications by providing LLM Traces, LLM Evals, Embedding Analysis, RAG Analysis, and Structured Data Analysis. Users can trace through the execution of LLM Applications, evaluate generative models, explore embedding point-clouds, visualize generative application's search and retrieval process, and statistically analyze structured data. Phoenix is designed to help users troubleshoot problems related to retrieval, tool execution, relevance, toxicity, drift, and performance degradation.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.
petercat
Peter Cat is an intelligent Q&A chatbot solution designed for community maintainers and developers. It provides a conversational Q&A agent configuration system, self-hosting deployment solutions, and a convenient integrated application SDK. Users can easily create intelligent Q&A chatbots for their GitHub repositories and quickly integrate them into various official websites or projects to provide more efficient technical support for the community.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
agentkit-samples
AgentKit Samples is a repository containing a series of examples and tutorials to help users understand, implement, and integrate various functionalities of AgentKit into their applications. The platform offers a complete solution for building, deploying, and maintaining AI agents, significantly reducing the complexity of developing intelligent applications. The repository provides different levels of examples and tutorials, including basic tutorials for understanding AgentKit's concepts and use cases, as well as more complex examples for experienced developers.

agentica
Agentica is a human-centric framework for building large language model agents. It provides functionalities for planning, memory management, tool usage, and supports features like reflection, planning and execution, RAG, multi-agent, multi-role, and workflow. The tool allows users to quickly code and orchestrate agents, customize prompts, and make API calls to various services. It supports API calls to OpenAI, Azure, Deepseek, Moonshot, Claude, Ollama, and Together. Agentica aims to simplify the process of building AI agents by providing a user-friendly interface and a range of functionalities for agent development.
web-builder
Web Builder is a low-code front-end framework based on Material for Angular, offering a rich component library for excellent digital innovation experience. It allows rapid construction of modern responsive UI, multi-theme, multi-language web pages through drag-and-drop visual configuration. The framework includes a beautiful admin theme, complete front-end solutions, and AI integration in the Pro version for optimizing copy, creating components, and generating pages with a single sentence.
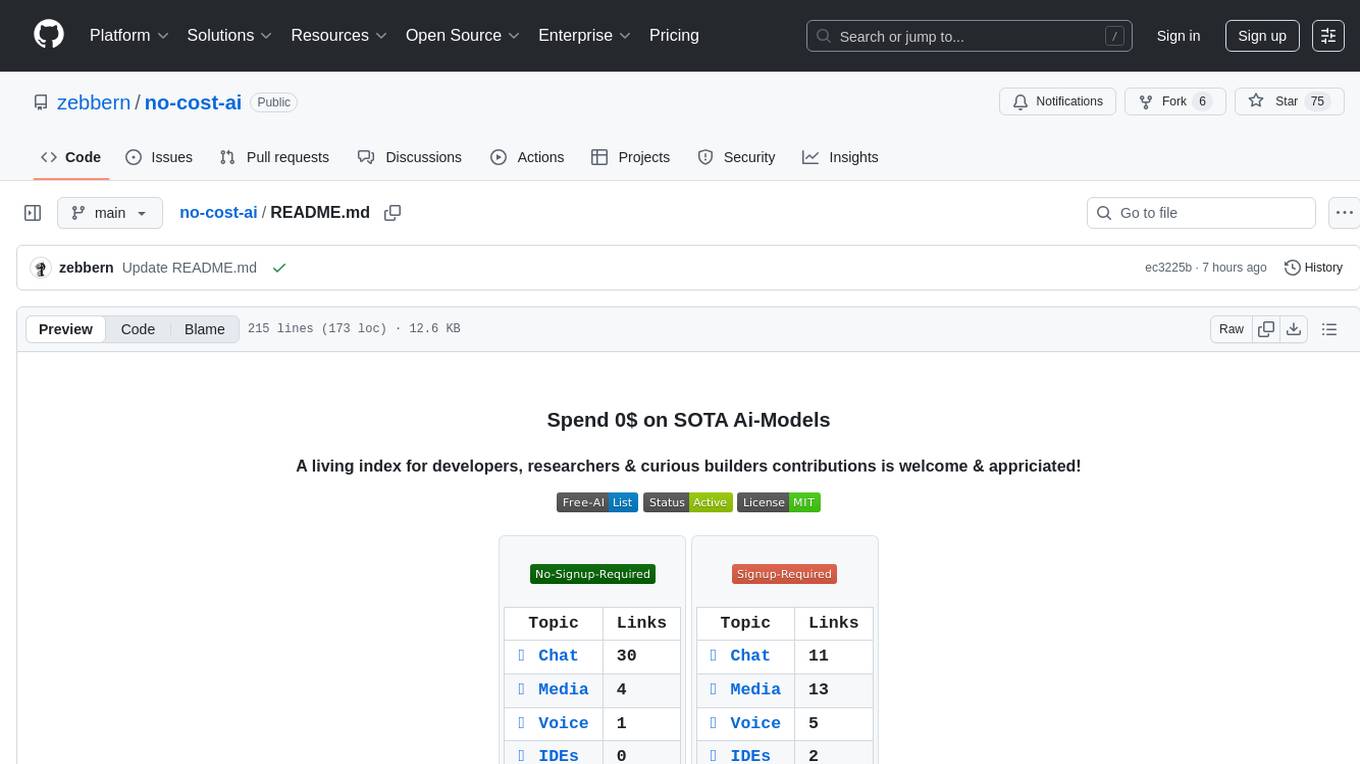
no-cost-ai
No-cost-ai is a repository dedicated to providing a comprehensive list of free AI models and tools for developers, researchers, and curious builders. It serves as a living index for accessing state-of-the-art AI models without any cost. The repository includes information on various AI applications such as chat interfaces, media generation, voice and music tools, AI IDEs, and developer APIs and platforms. Users can find links to free models, their limits, and usage instructions. Contributions to the repository are welcome, and users are advised to use the listed services at their own risk due to potential changes in models, limitations, and reliability of free services.

jiwu-mall-chat-tauri
Jiwu Chat Tauri APP is a desktop chat application based on Nuxt3 + Tauri + Element Plus framework. It provides a beautiful user interface with integrated chat and social functions. It also supports AI shopping chat and global dark mode. Users can engage in real-time chat, share updates, and interact with AI customer service through this application.
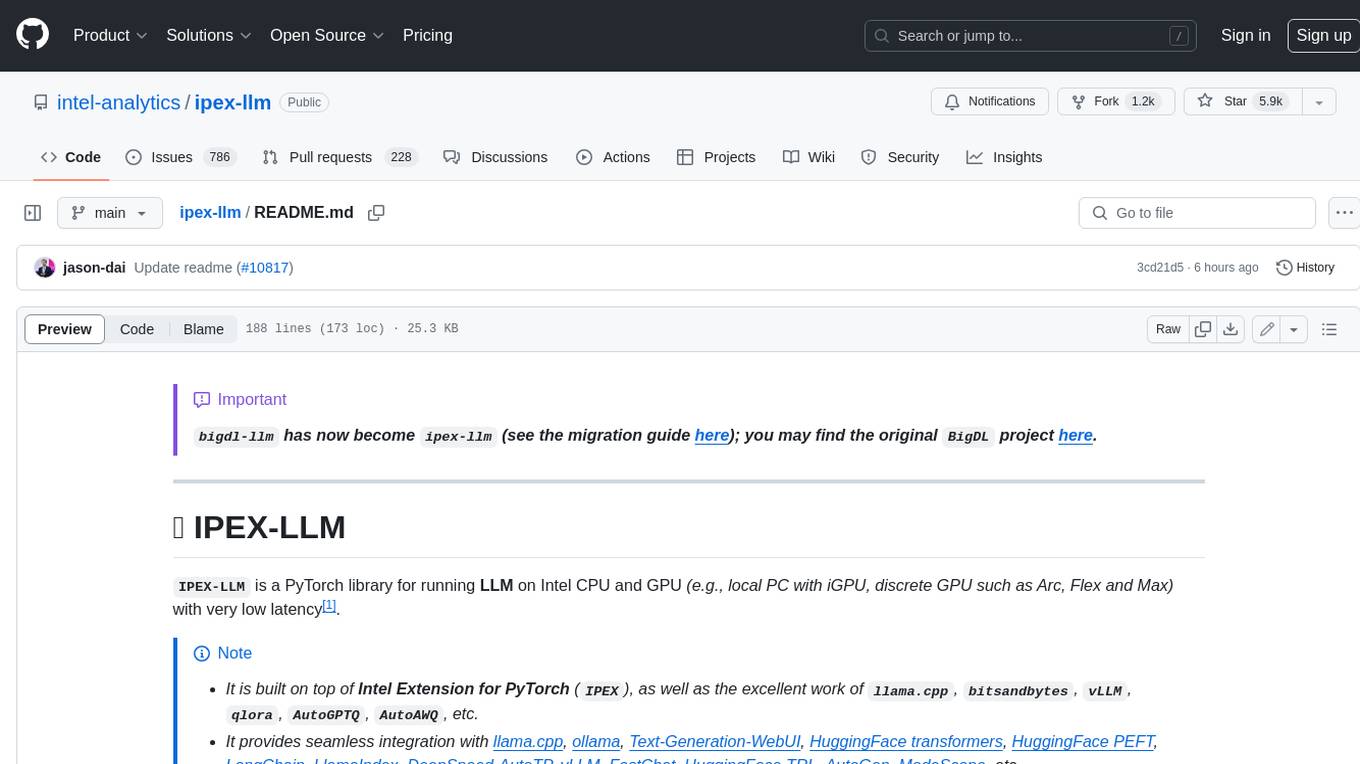
ipex-llm
IPEX-LLM is a PyTorch library for running Large Language Models (LLMs) on Intel CPUs and GPUs with very low latency. It provides seamless integration with various LLM frameworks and tools, including llama.cpp, ollama, Text-Generation-WebUI, HuggingFace transformers, and more. IPEX-LLM has been optimized and verified on over 50 LLM models, including LLaMA, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, and RWKV. It supports a range of low-bit inference formats, including INT4, FP8, FP4, INT8, INT2, FP16, and BF16, as well as finetuning capabilities for LoRA, QLoRA, DPO, QA-LoRA, and ReLoRA. IPEX-LLM is actively maintained and updated with new features and optimizations, making it a valuable tool for researchers, developers, and anyone interested in exploring and utilizing LLMs.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.
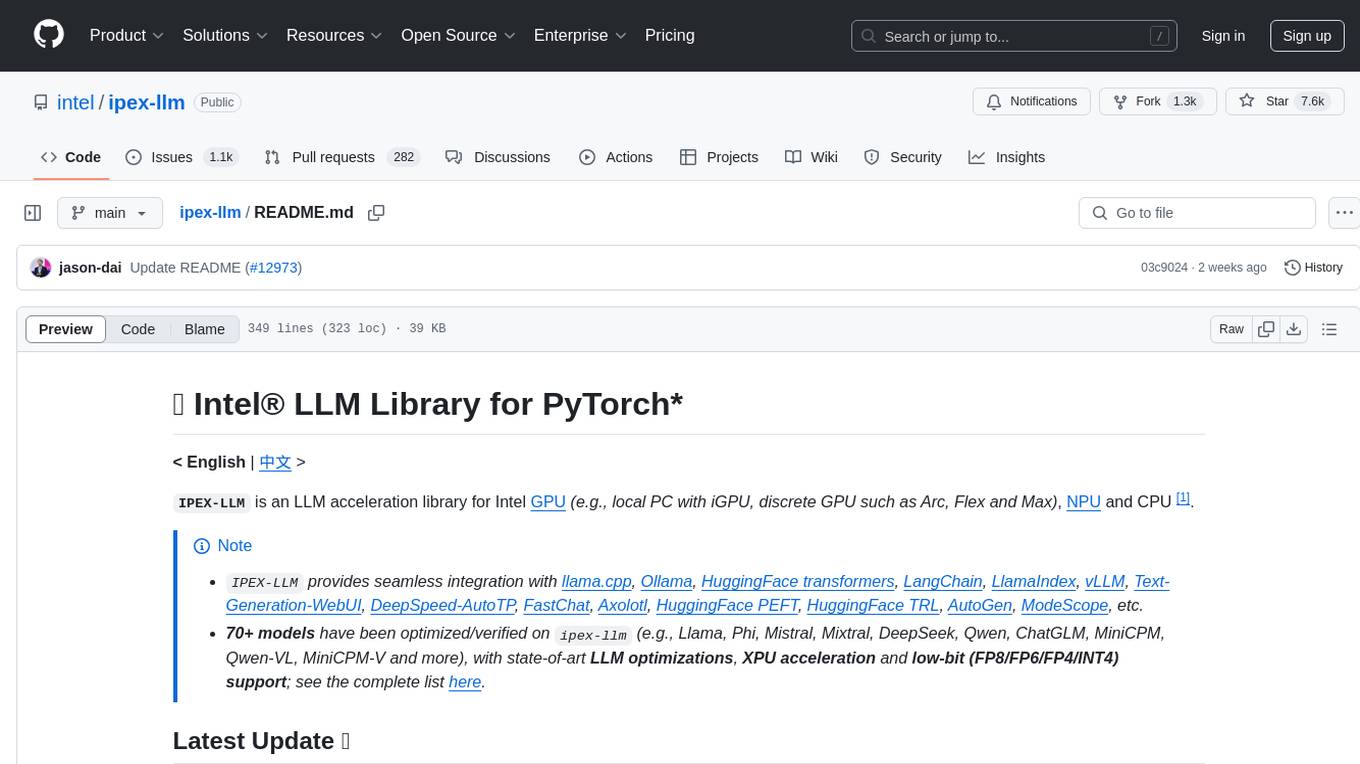
ipex-llm
The `ipex-llm` repository is an LLM acceleration library designed for Intel GPU, NPU, and CPU. It provides seamless integration with various models and tools like llama.cpp, Ollama, HuggingFace transformers, LangChain, LlamaIndex, vLLM, Text-Generation-WebUI, DeepSpeed-AutoTP, FastChat, Axolotl, and more. The library offers optimizations for over 70 models, XPU acceleration, and support for low-bit (FP8/FP6/FP4/INT4) operations. Users can run different models on Intel GPUs, NPU, and CPUs with support for various features like finetuning, inference, serving, and benchmarking.
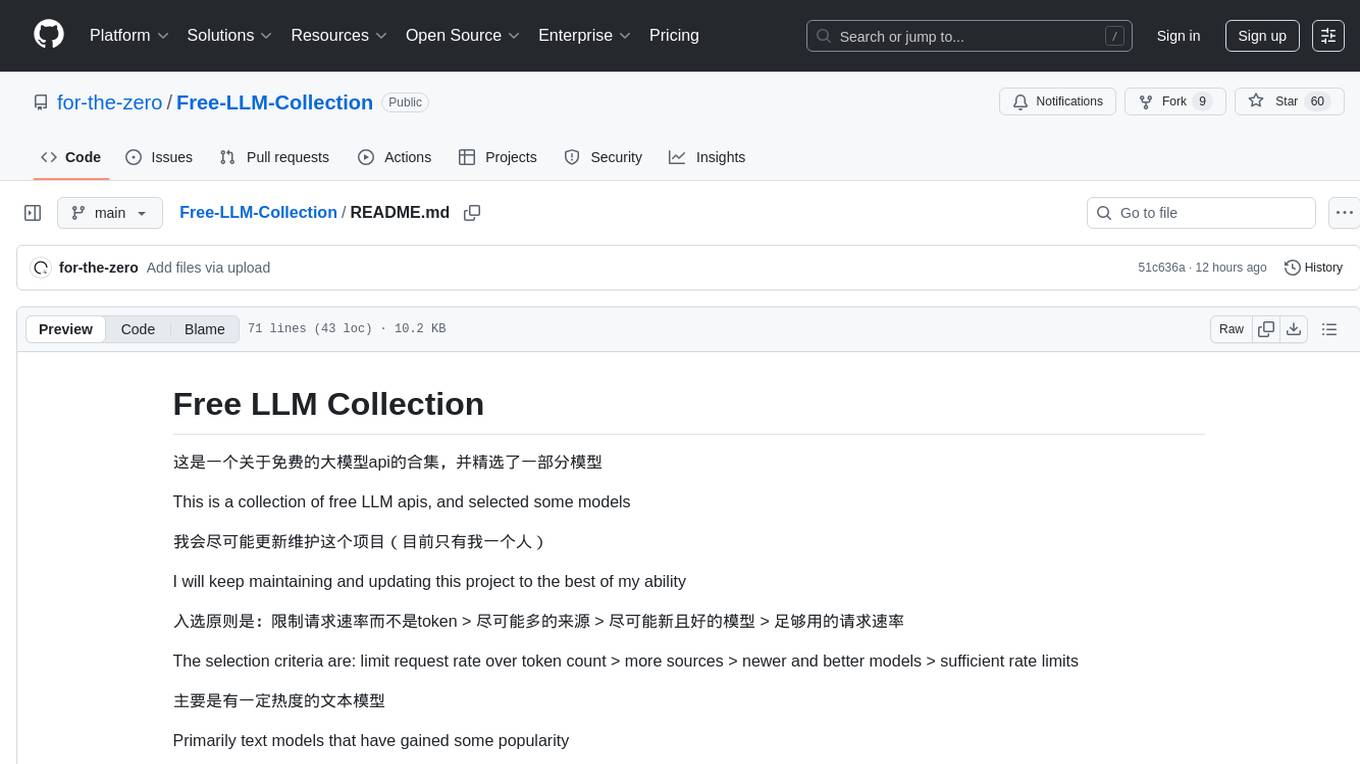
Free-LLM-Collection
Free-LLM-Collection is a curated list of free resources for mastering the Legal Language Model (LLM) technology. It includes datasets, research papers, tutorials, and tools to help individuals learn and work with LLM models. The repository aims to provide a comprehensive collection of materials to support researchers, developers, and enthusiasts interested in exploring and leveraging LLM technology for various applications in the legal domain.
TigerBot
TigerBot is a cutting-edge foundation for your very own LLM, providing a world-class large model for innovative Chinese-style contributions. It offers various upgrades and features, such as search mode enhancements, support for large context lengths, and the ability to play text-based games. TigerBot is suitable for prompt-based game engine development, interactive game design, and real-time feedback for playable games.
For similar tasks

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern
airbyte-connectors
This repository contains Airbyte connectors used in Faros and Faros Community Edition platforms as well as Airbyte Connector Development Kit (CDK) for JavaScript/TypeScript.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

unstract
Unstract is a no-code platform that enables users to launch APIs and ETL pipelines to structure unstructured documents. With Unstract, users can go beyond co-pilots by enabling machine-to-machine automation. Unstract's Prompt Studio provides a simple, no-code approach to creating prompts for LLMs, vector databases, embedding models, and text extractors. Users can then configure Prompt Studio projects as API deployments or ETL pipelines to automate critical business processes that involve complex documents. Unstract supports a wide range of LLM providers, vector databases, embeddings, text extractors, ETL sources, and ETL destinations, providing users with the flexibility to choose the best tools for their needs.

Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.