
Dot
RAG and Local AI made super-easy
Stars: 726

Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.
README:



Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box.
https://github.com/alexpinel/Dot/assets/93524949/242ef635-b9f5-4263-8f9e-07bc040e3113
Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT.
Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.
To use Dot:
- Visit the Dot website to download the application for Apple Silicon or Windows.
For developers:
- Clone the repository
$ https://github.com/alexpinel/Dot.git - Install Node js and then run
npm installinside the project repository, you can runnpm install --forceif you face any issues at this stage
Now, it is time to add a full python bundle to the app. The purpose of this is to create a distributable environment with all necessary libraries, if you only plan on using Dot from the console you might not need to follow this particular step but then make sure to replace the python path locations specified in src/index.js. Creating the python bundle is covered in detail here: https://til.simonwillison.net/electron/python-inside-electron , the bundles can also be installed from here: https://github.com/indygreg/python-build-standalone/releases/tag/20240224
Having created the bundle, please rename it to 'python' and place it inside the llm directory. It is now time to get all necessary libraries, keep in mind that running a simple pip install will not work without specifying the actual path of the bundle so use this instead: path/to/python/.bin/or/.exe -m pip install
Required python libraries:
- pytorch link (CPU version recommended as it is lighter than GPU)
- langchain link
- FAISS link
- HuggingFace link
- llama.cpp link (Use CUDA implementation if you have an Nvidia GPU!)
- pypdf link
- docx2txt link
- Unstructured link (Use
pip install "unstructured[pptx, md, xlsx]for the file formats)
Now python should be setup and running! However, there is still a few more steps left, now is the time to add the final magic to Dot! First, create a folder inside the llm directory and name it mpnet, there you will need to install sentence-transformers to use for the document embeddings, fetch all the files from the following link and place them inside the new folder: sentence-transformers/all-mpnet-base-v2
Finally, download the Mistral 7B LLM from the following link and place it inside the llm/scripts directory alongside the python scripts used by Dot: TheBloke/Mistral-7B-Instruct-v0.2-GGUF
That's it! If you follow these steps you should be able to get it all running, please let me know if you are facing any issues :)
- Linux support
- Choice of LLM
- Image file support
- Enhanced document awareness beyond content
- Simplified file loading (select individual files, not just folders)
- Increased security measures for using local LLMs
- Support for additional document types
- Efficient file database management for quicker access to groups of files
Contributions are highly encouraged! As a student managing this project on the side, any help is greatly appreciated. Whether it's coding, documentation, or feature suggestions, please feel free to get involved!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Dot
Similar Open Source Tools
Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
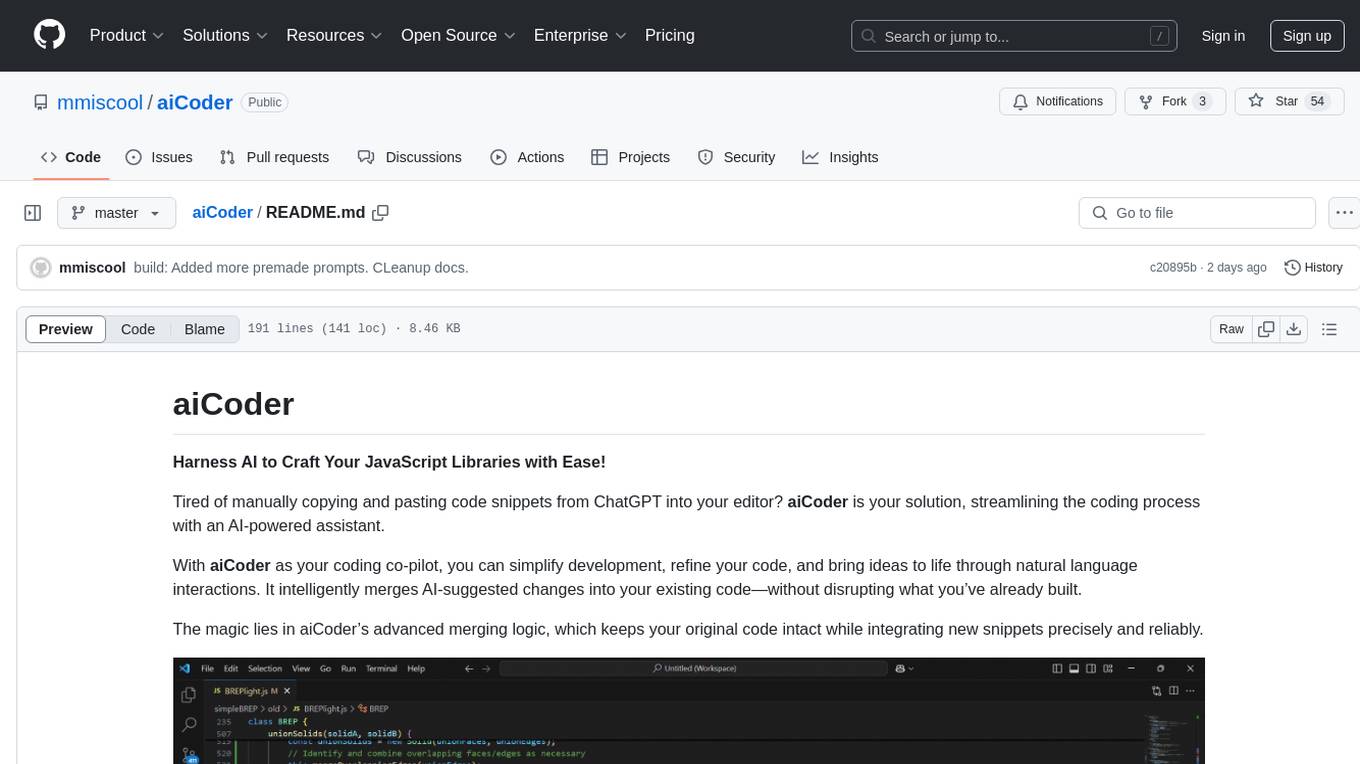
aiCoder
aiCoder is an AI-powered tool designed to streamline the coding process by automating repetitive tasks, providing intelligent code suggestions, and facilitating the integration of new features into existing codebases. It offers a chat interface for natural language interactions, methods and stubs lists for code modification, and settings customization for project-specific prompts. Users can leverage aiCoder to enhance code quality, focus on higher-level design, and save time during development.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.
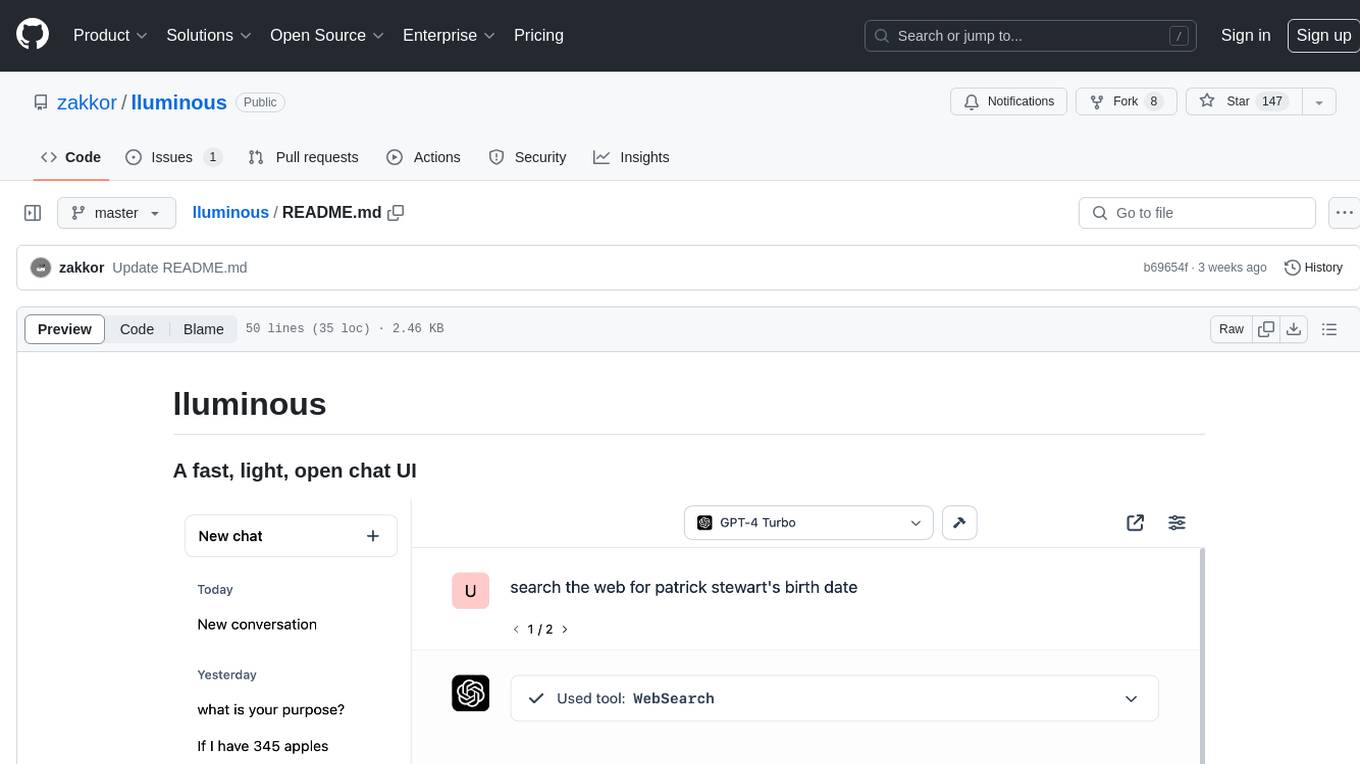
lluminous
lluminous is a fast and light open chat UI that supports multiple providers such as OpenAI, Anthropic, and Groq models. Users can easily plug in their API keys locally to access various models for tasks like multimodal input, image generation, multi-shot prompting, pre-filled responses, and more. The tool ensures privacy by storing all conversation history and keys locally on the user's device. Coming soon features include memory tool, file ingestion/embedding, embeddings-based web search, and prompt templates.
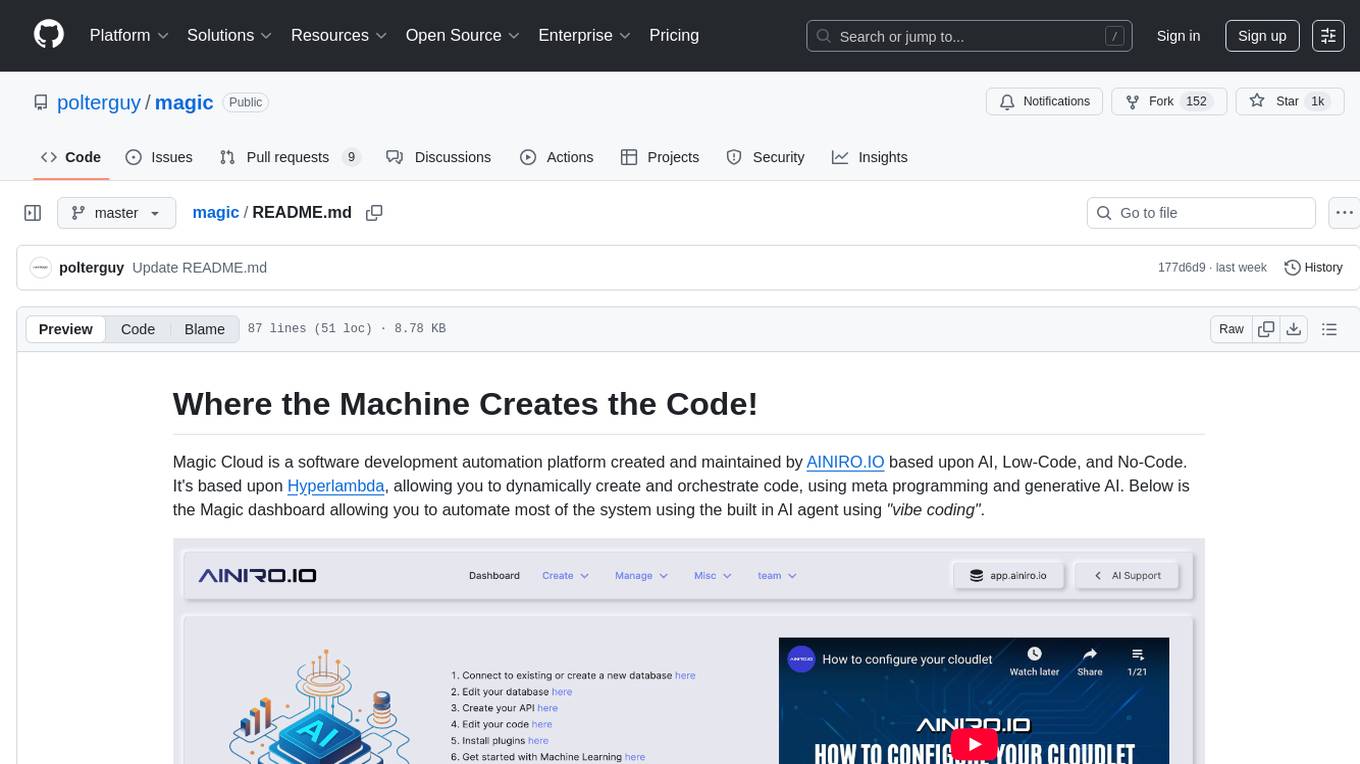
magic
Magic Cloud is a software development automation platform based on AI, Low-Code, and No-Code. It allows dynamic code creation and orchestration using Hyperlambda, generative AI, and meta programming. The platform includes features like CRUD generation, No-Code AI, Hyperlambda programming language, AI agents creation, and various components for software development. Magic is suitable for backend development, AI-related tasks, and creating AI chatbots. It offers high-level programming capabilities, productivity gains, and reduced technical debt.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.

raggenie
RAGGENIE is a low-code RAG builder tool designed to simplify the creation of conversational AI applications. It offers out-of-the-box plugins for connecting to various data sources and building conversational AI on top of them, including integration with pre-built agents for actions. The tool is open-source under the MIT license, with a current focus on making it easy to build RAG applications and future plans for maintenance, monitoring, and transitioning applications from pilots to production.
DistiLlama
DistiLlama is a Chrome extension that leverages a locally running Large Language Model (LLM) to perform various tasks, including text summarization, chat, and document analysis. It utilizes Ollama as the locally running LLM instance and LangChain for text summarization. DistiLlama provides a user-friendly interface for interacting with the LLM, allowing users to summarize web pages, chat with documents (including PDFs), and engage in text-based conversations. The extension is easy to install and use, requiring only the installation of Ollama and a few simple steps to set up the environment. DistiLlama offers a range of customization options, including the choice of LLM model and the ability to configure the summarization chain. It also supports multimodal capabilities, allowing users to interact with the LLM through text, voice, and images. DistiLlama is a valuable tool for researchers, students, and professionals who seek to leverage the power of LLMs for various tasks without compromising data privacy.
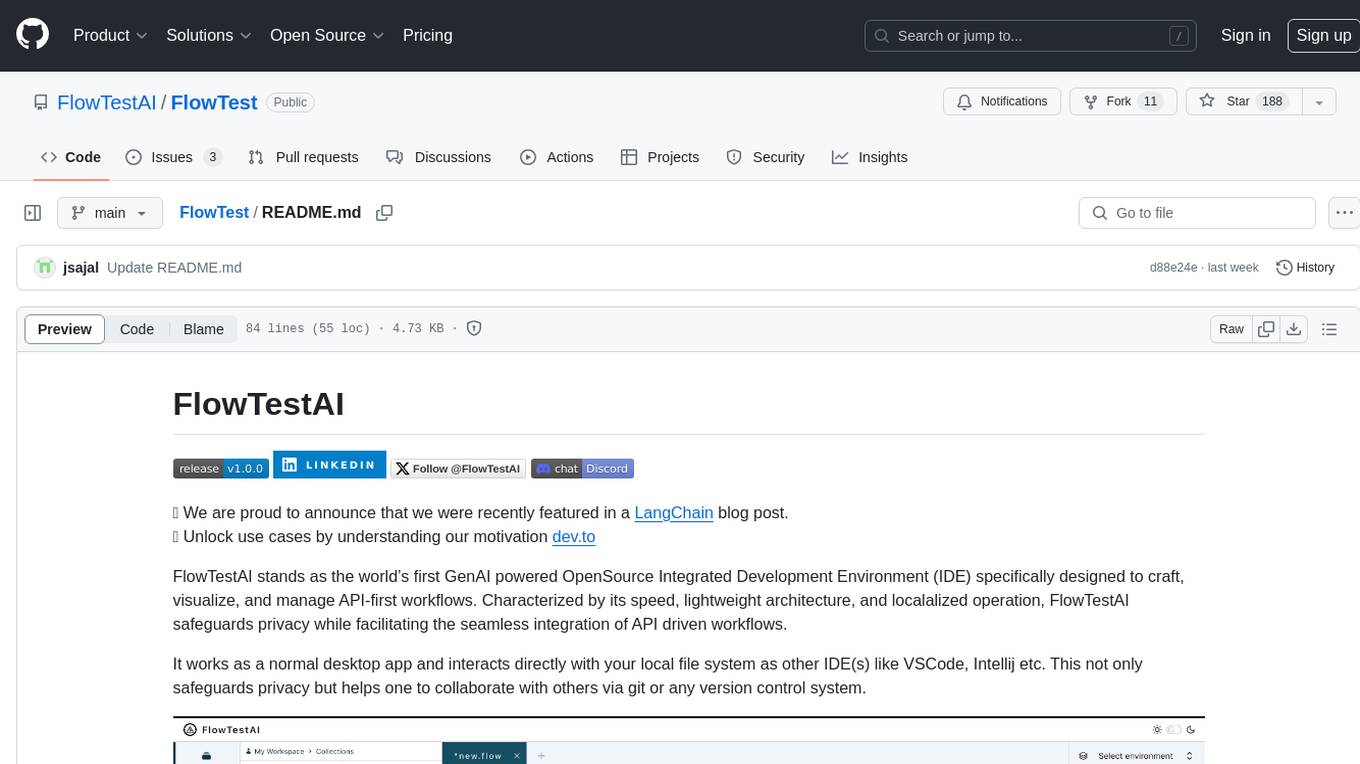
FlowTest
FlowTestAI is the world’s first GenAI powered OpenSource Integrated Development Environment (IDE) designed for crafting, visualizing, and managing API-first workflows. It operates as a desktop app, interacting with the local file system, ensuring privacy and enabling collaboration via version control systems. The platform offers platform-specific binaries for macOS, with versions for Windows and Linux in development. It also features a CLI for running API workflows from the command line interface, facilitating automation and CI/CD processes.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.
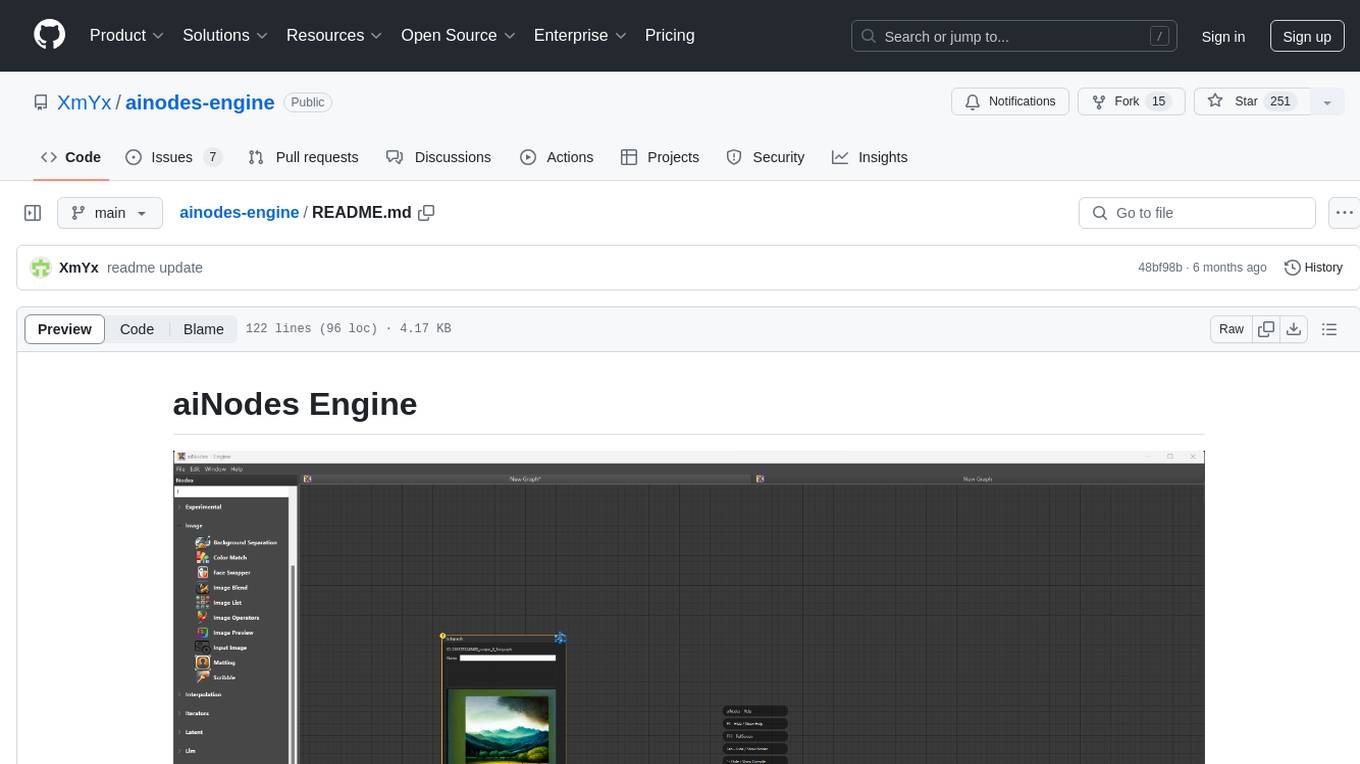
ainodes-engine
aiNodes Engine is a Python-based AI image/motion picture generator node engine with a live execution chain, python code editor node, and plug-in support. It offers full modularity, colored background drop, and easy node creation with IDE annotations. The project is officially supported by Deforum and incorporates various open-source projects like ComfyUI. It is designed to be flexible, with an Unreal-like execution chain, supporting features such as Deforum, Stable Diffusion, Upscalers, Kandinsky, ControlNet, and more. The engine allows for background separation, human matting/masking, compositing, drag and drop, subgraphs, and graph saving/loading from image metadata. It aims to provide a unique, controllable manner of working with a strict user-declared execution chain.

Robyn
Robyn is an experimental, semi-automated and open-sourced Marketing Mix Modeling (MMM) package from Meta Marketing Science. It uses various machine learning techniques to define media channel efficiency and effectivity, explore adstock rates and saturation curves. Built for granular datasets with many independent variables, especially suitable for digital and direct response advertisers with rich data sources. Aiming to democratize MMM, make it accessible for advertisers of all sizes, and contribute to the measurement landscape.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
PyAirbyte
PyAirbyte brings the power of Airbyte to every Python developer by providing a set of utilities to use Airbyte connectors in Python. It enables users to easily manage secrets, work with various connectors like GitHub, Shopify, and Postgres, and contribute to the project. PyAirbyte is not a replacement for Airbyte but complements it, supporting data orchestration frameworks like Airflow and Snowpark. Users can develop ETL pipelines and import connectors from local directories. The tool simplifies data integration tasks for Python developers.
documentation
Vespa documentation is served using GitHub Project pages with Jekyll. To edit documentation, check out and work off the master branch in this repository. Documentation is written in HTML or Markdown. Use a single Jekyll template _layouts/default.html to add header, footer and layout. Install bundler, then $ bundle install $ bundle exec jekyll serve --incremental --drafts --trace to set up a local server at localhost:4000 to see the pages as they will look when served. If you get strange errors on bundle install try $ export PATH=“/usr/local/opt/[email protected]/bin:$PATH” $ export LDFLAGS=“-L/usr/local/opt/[email protected]/lib” $ export CPPFLAGS=“-I/usr/local/opt/[email protected]/include” $ export PKG_CONFIG_PATH=“/usr/local/opt/[email protected]/lib/pkgconfig” The output will highlight rendering/other problems when starting serving. Alternatively, use the docker image `jekyll/jekyll` to run the local server on Mac $ docker run -ti --rm --name doc \ --publish 4000:4000 -e JEKYLL_UID=$UID -v $(pwd):/srv/jekyll \ jekyll/jekyll jekyll serve or RHEL 8 $ podman run -it --rm --name doc -p 4000:4000 -e JEKYLL_ROOTLESS=true \ -v "$PWD":/srv/jekyll:Z docker.io/jekyll/jekyll jekyll serve The layout is written in denali.design, see _layouts/default.html for usage. Please do not add custom style sheets, as it is harder to maintain.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

vectara-answer
Vectara Answer is a sample app for Vectara-powered Summarized Semantic Search (or question-answering) with advanced configuration options. For examples of what you can build with Vectara Answer, check out Ask News, LegalAid, or any of the other demo applications.

smartcat
Smartcat is a CLI interface that brings language models into the Unix ecosystem, allowing power users to leverage the capabilities of LLMs in their daily workflows. It features a minimalist design, seamless integration with terminal and editor workflows, and customizable prompts for specific tasks. Smartcat currently supports OpenAI, Mistral AI, and Anthropic APIs, providing access to a range of language models. With its ability to manipulate file and text streams, integrate with editors, and offer configurable settings, Smartcat empowers users to automate tasks, enhance code quality, and explore creative possibilities.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.
Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.
emerging-trajectories
Emerging Trajectories is an open source library for tracking and saving forecasts of political, economic, and social events. It provides a way to organize and store forecasts, as well as track their accuracy over time. This can be useful for researchers, analysts, and anyone else who wants to keep track of their predictions.
reor
Reor is an AI-powered desktop note-taking app that automatically links related notes, answers questions on your notes, and provides semantic search. Everything is stored locally and you can edit your notes with an Obsidian-like markdown editor. The hypothesis of the project is that AI tools for thought should run models locally by default. Reor stands on the shoulders of the giants Ollama, Transformers.js & LanceDB to enable both LLMs and embedding models to run locally. Connecting to OpenAI or OpenAI-compatible APIs like Oobabooga is also supported.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.
obsidian-Smart2Brain
Your Smart Second Brain is a free and open-source Obsidian plugin that serves as your personal assistant, powered by large language models like ChatGPT or Llama2. It can directly access and process your notes, eliminating the need for manual prompt editing, and it can operate completely offline, ensuring your data remains private and secure.