
swirl-search
AI Search & RAG Without Moving Your Data. Get instant answers from your company's knowledge across 100+ apps while keeping data secure. Deploy in minutes, not months.
Stars: 2718

Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.
README:

Ask question → Get answer with sources → Click through to source

Watch it on Youtube
Teams using SWIRL saves an average 7.5 hours of productive time per week.



|
|
# No need for:
$ setup-vector-db
$ migrate-data
$ configure-indexes
# Just this:
$ curl https://raw.githubusercontent.com/swirlai/swirl-search/main/docker-compose.yaml -o docker-compose.yamlReal examples of what teams build with SWIRL:
- Connect SharePoint, Confluence, & Drive
- Get instant answers with source links
- Keep sensitive data secure
- Search across support docs & tickets
- Draft responses using your content
- Maintain consistent answers
- Search GitHub, Jira, & documentation
- Find code examples & solutions
- Speed up development workflow
- Unified search across all tools
- Results respect existing permissions
- No data duplication needed

Schedule Your Free Demo of SWIRL Enterprise
Try SWIRL Enterprise for free for 30 Days. Click on the banner to contact us.

- 🔒 Your infrastructure, your control
- 🚀 Deploy in minutes, not months
- 🔌 100+ enterprise connectors
- 🤖 AI that respects your security
SWIRL doesn't just search - it understands your company's context. Instead of broad web results, you get precise answers from your private data, right where it lives.



Full list of connectors is available here
For Support on Connectors Contact the Swirl Team at: [email protected]
-
To run Swirl in Docker, you must have the latest Docker app for MacOS, Linux, or Windows installed and running locally. You can also watch the video tutorial to get started.
-
Windows users must also install and configure either the WSL 2 or the Hyper-V backend, as outlined in the System Requirements for installing Docker Desktop on Windows.
Warning Make sure the Docker app is running before proceeding!
- Download the YAML file: https://raw.githubusercontent.com/swirlai/swirl-search/main/docker-compose.yaml
curl https://raw.githubusercontent.com/swirlai/swirl-search/main/docker-compose.yaml -o docker-compose.yaml- Optional: To enable Swirl's Real-Time Retrieval Augmented Generation (RAG) in Docker, run the following commands from the Console using a valid OpenAI API key:
export MSAL_CB_PORT=8000
export MSAL_HOST=localhost
export OPENAI_API_KEY=‘<your-OpenAI-API-key>’🔑 Check out OpenAI's YouTube video if you don't have an OpenAI API Key.
- In MacOS or Linux, run the following command from the Console:
docker-compose pull && docker-compose up- In Windows, run the following command from PowerShell:
docker compose upAfter a few minutes the following or similar should appear:
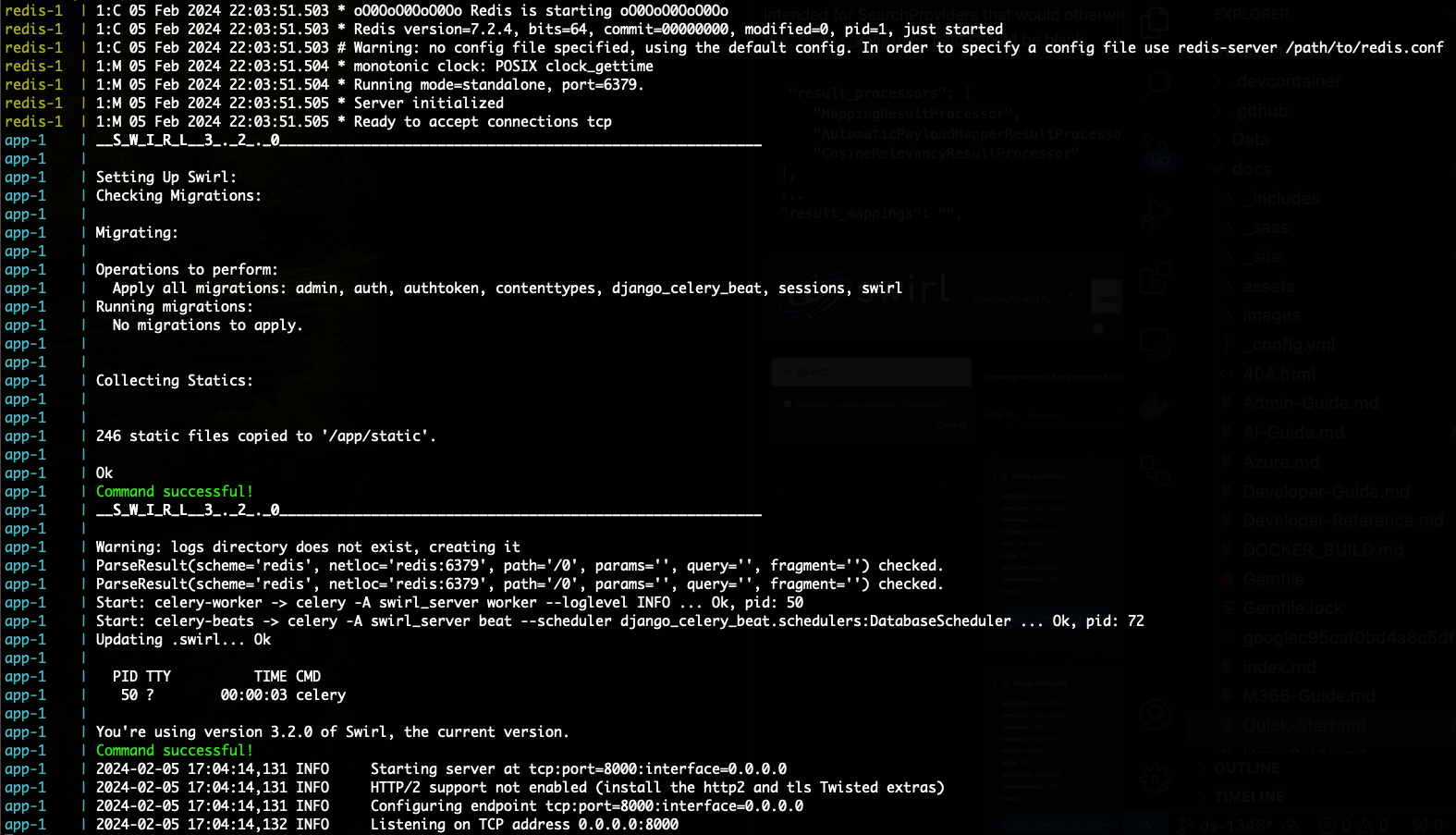
-
Open this URL with a browser: http://localhost:8000 (or http://localhost:8000/galaxy)
-
If the search page appears, click
Log Outat the top, right. The Swirl login page will appear. -
Enter the username
adminand passwordpassword, then clickLogin. -
Enter a search in the search box and press the
Searchbutton. Ranked results appear in just a few seconds:

- To view the raw JSON, open http://localhost:8000/swirl/search/
The most recent Search object will be displayed at the top. Click on the result_url link to view the full JSON Response.
Warning The Docker version of Swirl does not retain any data or configuration when shut down!
🔑 Swirl comes configured to search Arxiv, European PMC and Google News right out of the box.
🔑 Using Swirl with Microsoft 365 requires installation and approval by an authorized company Administrator. For more information, please review the M365 Guide or contact us.
-
Check out the details of our latest release!
-
Head over to the Quick Start Guide and install Swirl locally!
Guide to Run SWIRL in Docker in 60 seconds.

| ✦ | Feature |
|---|---|
| 📌 | Microsoft 365 integration and OAUTH2 support |
| 🔍 | SearchProvider configurations for all included Connectors. They can be organized with the active, default and tags properties. |
| ✏️ |
Adaptation of the query for each provider such as rewriting NOT term to -term, removing NOTted terms from providers that don't support NOT, and passing down the AND, + and OR operators. |
| ⏳ | Synchronous or asynchronous search federation via APIs |
| 🛎️ | Optional subscribe feature to continuously monitor any search for new results |
| 🛠️ | Pipelining of Processor stages for real-time adaptation and transformation of queries, responses and results |
| 🗄️ | Results stored in SQLite3 or PostgreSQL for post-processing, consumption and/or analytics |
| ➡️ | Built-in Query Transformation support, including re-writing and replacement |
| 📖 | Matching on word stems and handling of stopwords via NLTK |
| 🚫 | Duplicate detection on field or by configurable Cosine Similarity threshold |
| 🔄 | Re-ranking of unified results using Cosine Vector Similarity based on spaCy's large language model and NLTK |
| 🎚️ | Result mixers order results by relevancy, date or round-robin (stack) format, with optional filtering of just new items in subscribe mode |
| 📄 | Page through all results requested, re-run, re-score and update searches using URLs provided with each result set |
| 📁 | Sample data sets for use with SQLite3 and PostgreSQL |
| ✒️ | Optional spell correction using TextBlob |
| ⌛ | Optional search/result expiration service to limit storage use |
| 🔌 | Easily extensible Connector and Mixer objects |
Do you have a brilliant idea or improvement for SWIRL? We're all ears, and thrilled you're here to help!
🔗 Get Started in 3 Easy Steps:
- Connect with Fellow Enthusiasts - Jump into the Swirl Slack Community and share your ideas. You'll find a welcoming group of Swirl enthusiasts and team members eager to assist and collaborate.
-
Branch It Out - Always branch off from the
developbranch with a descriptive name that encapsulates your idea or fix. -
Start Your Contribution - Ready to get your hands dirty? Make sure all contributions come through a GitHub pull request. We roughly follow the Gitflow branching model, so all changes destined for the next release should be made to the
developbranch.
📚 First time contributing on GitHub? No worries, the GitHub documentation has you covered with a great guide on contributing to projects.
💡 Every contribution, big or small, makes a difference. Join us in shaping the future of Swirl!
For information about Swirl as a managed service, please contact us!
At Swirl, every user matters to us. Whether you're a beginner finding your way or an expert with feedback, we're here to support, listen, and help. Don't hesitate to reach out to us.
-
Join the SWIRL Community Slack: Dive into our SWIRL Community on Slack - to discuss anything related to SWIRL.
-
Direct Support: For any questions, suggestions, or even a simple hello, drop us an email at [email protected]. We cherish every message and promise to get back to you promptly!
-
Request A Connector (Enterprise Support) Want to see a new connector quickly and fast. Contact the Swirl Team at: [email protected]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for swirl-search
Similar Open Source Tools
swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.
SurfSense
SurfSense is a tool designed to help users save and organize content from the internet into a personal Knowledge Graph. It allows users to capture web browsing sessions and webpage content using a Chrome extension, enabling easy retrieval and recall of saved information. SurfSense offers features like powerful search capabilities, natural language interaction with saved content, self-hosting options, and integration with GraphRAG for meaningful content relations. The tool eliminates the need for web scraping by directly reading data from the DOM, making it a convenient solution for managing online information.
ocular
Ocular is a set of modules and tools that allow you to build rich, reliable, and performant Generative AI-Powered Search Platforms without the need to reinvent Search Architecture. We help you build you spin up customized internal search in days not months.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
OpenHands
OpenDevin is a platform for autonomous software engineers powered by AI and LLMs. It allows human developers to collaborate with agents to write code, fix bugs, and ship features. The tool operates in a secured docker sandbox and provides access to different LLM providers for advanced configuration options. Users can contribute to the project through code contributions, research and evaluation of LLMs in software engineering, and providing feedback and testing. OpenDevin is community-driven and welcomes contributions from developers, researchers, and enthusiasts looking to advance software engineering with AI.
TaxHacker
TaxHacker is a self-hosted accountant app designed for freelancers and small businesses to automate expense and income tracking using the power of GenAI. It can analyze uploaded photos, receipts, or PDFs to extract important data like name, total amount, date, merchant, and VAT, saving them as structured transactions. The tool supports automatic currency conversion, filters, multiple projects, import-export functionalities, custom categories, and allows users to create custom fields for extraction. TaxHacker simplifies reporting and tax filing by organizing and storing data efficiently.
ha-llmvision
LLM Vision is a Home Assistant integration that allows users to analyze images, videos, and camera feeds using multimodal LLMs. It supports providers such as OpenAI, Anthropic, Google Gemini, LocalAI, and Ollama. Users can input images and videos from camera entities or local files, with the option to downscale images for faster processing. The tool provides detailed instructions on setting up LLM Vision and each supported provider, along with usage examples and service call parameters.
UFO
UFO is a UI-focused dual-agent framework to fulfill user requests on Windows OS by seamlessly navigating and operating within individual or spanning multiple applications.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.

Follow
Follow is a content organization tool that creates a noise-free timeline for users, allowing them to share lists, explore collections, and browse distraction-free. It offers features like subscribing to feeds, AI-powered browsing, dynamic content support, an ownership economy with $POWER tipping, and a community-driven experience. Follow is under active development and welcomes feedback from users and developers. It can be accessed via web app or desktop client and offers installation methods for different operating systems. The tool aims to provide a customized information hub, AI-powered browsing experience, and support for various types of content, while fostering a community-driven and open-source environment.
wppconnect
WPPConnect is an open source project developed by the JavaScript community with the aim of exporting functions from WhatsApp Web to the node, which can be used to support the creation of any interaction, such as customer service, media sending, intelligence recognition based on phrases artificial and many other things.
discord-llm-chatbot
llmcord.py enables collaborative LLM prompting in your Discord server. It works with practically any LLM, remote or locally hosted. ### Features ### Reply-based chat system Just @ the bot to start a conversation and reply to continue. Build conversations with reply chains! You can do things like: - Build conversations together with your friends - "Rewind" a conversation simply by replying to an older message - @ the bot while replying to any message in your server to ask a question about it Additionally: - Back-to-back messages from the same user are automatically chained together. Just reply to the latest one and the bot will see all of them. - You can seamlessly move any conversation into a thread. Just create a thread from any message and @ the bot inside to continue. ### Choose any LLM Supports remote models from OpenAI API, Mistral API, Anthropic API and many more thanks to LiteLLM. Or run a local model with ollama, oobabooga, Jan, LM Studio or any other OpenAI compatible API server. ### And more: - Supports image attachments when using a vision model - Customizable system prompt - DM for private access (no @ required) - User identity aware (OpenAI API only) - Streamed responses (turns green when complete, automatically splits into separate messages when too long, throttled to prevent Discord ratelimiting) - Displays helpful user warnings when appropriate (like "Only using last 20 messages", "Max 5 images per message", etc.) - Caches message data in a size-managed (no memory leaks) and per-message mutex-protected (no race conditions) global dictionary to maximize efficiency and minimize Discord API calls - Fully asynchronous - 1 Python file, ~200 lines of code
extensionOS
Extension | OS is an open-source browser extension that brings AI directly to users' web browsers, allowing them to access powerful models like LLMs seamlessly. Users can create prompts, fix grammar, and access intelligent assistance without switching tabs. The extension aims to revolutionize online information interaction by integrating AI into everyday browsing experiences. It offers features like Prompt Factory for tailored prompts, seamless LLM model access, secure API key storage, and a Mixture of Agents feature. The extension was developed to empower users to unleash their creativity with custom prompts and enhance their browsing experience with intelligent assistance.
For similar tasks

vectara-answer
Vectara Answer is a sample app for Vectara-powered Summarized Semantic Search (or question-answering) with advanced configuration options. For examples of what you can build with Vectara Answer, check out Ask News, LegalAid, or any of the other demo applications.
LLocalSearch
LLocalSearch is a completely locally running search aggregator using LLM Agents. The user can ask a question and the system will use a chain of LLMs to find the answer. The user can see the progress of the agents and the final answer. No OpenAI or Google API keys are needed.
llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.

DocsGPT
DocsGPT is an open-source documentation assistant powered by GPT models. It simplifies the process of searching for information in project documentation by allowing developers to ask questions and receive accurate answers. With DocsGPT, users can say goodbye to manual searches and quickly find the information they need. The tool aims to revolutionize project documentation experiences and offers features like live previews, Discord community, guides, and contribution opportunities. It consists of a Flask app, Chrome extension, similarity search index creation script, and a frontend built with Vite and React. Users can quickly get started with DocsGPT by following the provided setup instructions and can contribute to its development by following the guidelines in the CONTRIBUTING.md file. The project follows a Code of Conduct to ensure a harassment-free community environment for all participants. DocsGPT is licensed under MIT and is built with LangChain.
udm14
udm14 is a basic website designed to facilitate easy searches on Google with the &udm=14 parameter, ensuring AI-free results without knowledge panels. The tool simplifies access to these specific search results buried within Google's interface, providing a straightforward solution for users seeking this functionality.
openrecall
OpenRecall is a fully open-source, privacy-first tool that captures your digital history through snapshots, making it searchable for quick access to specific information. It offers transparency, cross-platform support, privacy focus, and hardware compatibility. Features include time travel, local-first AI, semantic search, and full control over storage. The roadmap includes visual search capabilities and audio transcription. Users can easily install and run OpenRecall to enhance memory and productivity without compromising privacy.
Fyin
Fyin is an open-source tool that serves as an alternative to Perplexity AI, allowing users to run it locally for faster answers. It features the ability to run locally using ollama or OpenAI API, a local VectorDB for fast search, quick searching, scraping & answering due to parallelism, configurable number of search results to parse, and local scraping of websites. The tool aims to provide a more efficient and customizable solution for obtaining answers through search and scraping functionalities.
For similar jobs
vectara-answer
Vectara Answer is a sample app for Vectara-powered Summarized Semantic Search (or question-answering) with advanced configuration options. For examples of what you can build with Vectara Answer, check out Ask News, LegalAid, or any of the other demo applications.

smartcat
Smartcat is a CLI interface that brings language models into the Unix ecosystem, allowing power users to leverage the capabilities of LLMs in their daily workflows. It features a minimalist design, seamless integration with terminal and editor workflows, and customizable prompts for specific tasks. Smartcat currently supports OpenAI, Mistral AI, and Anthropic APIs, providing access to a range of language models. With its ability to manipulate file and text streams, integrate with editors, and offer configurable settings, Smartcat empowers users to automate tasks, enhance code quality, and explore creative possibilities.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.

Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.
emerging-trajectories
Emerging Trajectories is an open source library for tracking and saving forecasts of political, economic, and social events. It provides a way to organize and store forecasts, as well as track their accuracy over time. This can be useful for researchers, analysts, and anyone else who wants to keep track of their predictions.
reor
Reor is an AI-powered desktop note-taking app that automatically links related notes, answers questions on your notes, and provides semantic search. Everything is stored locally and you can edit your notes with an Obsidian-like markdown editor. The hypothesis of the project is that AI tools for thought should run models locally by default. Reor stands on the shoulders of the giants Ollama, Transformers.js & LanceDB to enable both LLMs and embedding models to run locally. Connecting to OpenAI or OpenAI-compatible APIs like Oobabooga is also supported.
swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.
obsidian-Smart2Brain
Your Smart Second Brain is a free and open-source Obsidian plugin that serves as your personal assistant, powered by large language models like ChatGPT or Llama2. It can directly access and process your notes, eliminating the need for manual prompt editing, and it can operate completely offline, ensuring your data remains private and secure.