
mlcraft
Synmetrix – open source semantic layer / Boost your LLM precision
Stars: 480

Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
README:
![]()
Website • Docs • Cube.js Models docs • Docker Hub • Slack community
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale.
- Data modeling and transformations: Flexibly define metrics and dimensions using SQL and Cube data models. Apply transformations and aggregations.
- Semantic layer: Consolidate metrics from across sources into a unified, governed data model. Eliminate metric definition differences.
- Scheduled reports and alerts: Monitor metrics and get notified of changes via configurable reports and alerts.
- Versioning: Track schema changes over time for transparency and auditability.
- Role-based access control: Manage permissions for data models and metrics access.
- Data exploration: Analyze metrics through the UI, or integrate with any BI tool via the SQL API.
- Caching: Optimize performance using pre-aggregations and caching from Cube.
- Teams: Collaborate on metrics modeling across your organization.
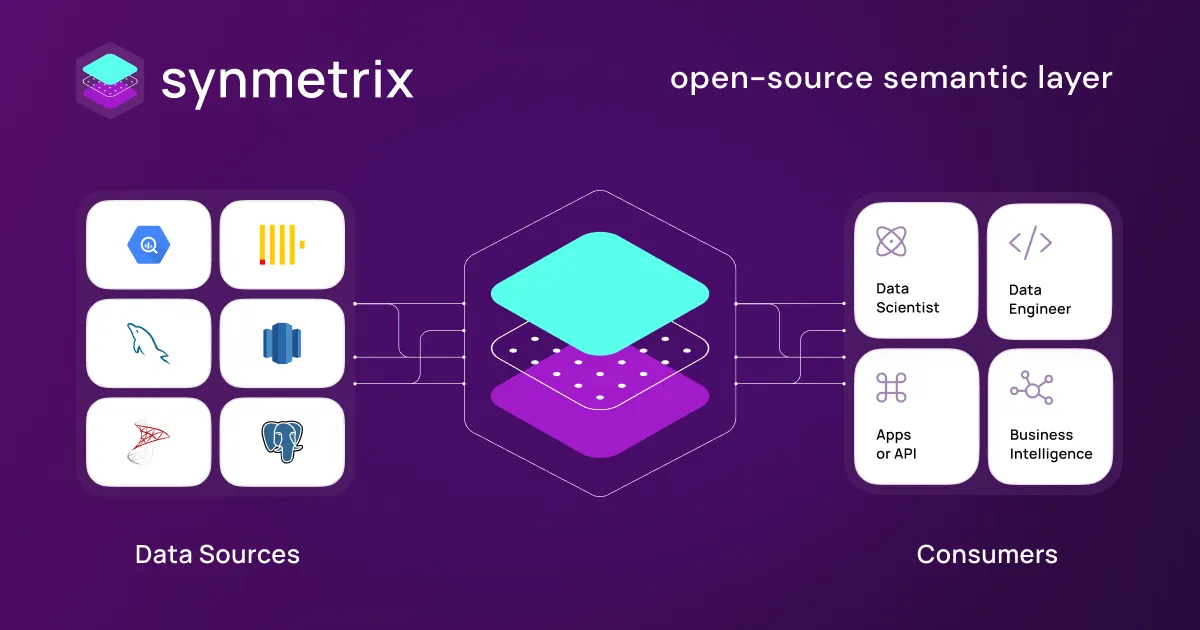
Synmetrix leverages Cube (Cube.js) to implement flexible data models that can consolidate metrics from across warehouses, databases, APIs and more. This unified semantic layer eliminates differences in definitions and calculations, providing a single source of truth.
The metrics data model can then be distributed downstream to any consumer via a SQL API, allowing integration into BI tools, reporting, dashboards, data science, and more.
By combining best practices from data engineering, like caching, orchestration, and transformation, with self-service analytics capabilities, Synmetrix speeds up data-driven workflows from metrics definition to consumption.
-
Data Democratization: Synmetrix makes data accessible to non-experts, enabling everyone in an organization to make data-driven decisions easily.
-
Business Intelligence (BI) and Reporting: Integrate Synmetrix with any BI tool for advanced reporting and analytics, enhancing data visualization and insights.
- Embedded Analytics: Use the Synmetrix API to embed analytics directly into applications, providing users with real-time data insights within their workflows.
- Integrating Synmetrix with Observable: A Quick Guide (Video)
- Guide to Connecting Synmetrix with DBeaver Using SQL API (Video)
- Semantic Layer for LLM: Enhance LLM's accuracy in data handling and queries with Synmetrix's semantic layer, improving data interaction and precision.
Ensure the following software is installed before proceeding:
The repository mlcraft-io/mlcraft/install-manifests houses all the necessary installation manifests for deploying Synmetrix anywhere. You can download the docker compose file from this repository:
Execute this in a new directory
wget https://raw.githubusercontent.com/mlcraft-io/mlcraft/main/install-manifests/docker-compose/docker-compose.yml
Alternatively, you can use curl
curl https://raw.githubusercontent.com/mlcraft-io/mlcraft/main/install-manifests/docker-compose/docker-compose.yml -o docker-compose.yml
NOTE: Ensure to review the environment variables in the docker-compose.yml file. Modify them as necessary.
Execute the following command to start Synmetrix along with a Postgres database for data storage.
docker-compose pull stack && docker-compose up -d
Verify if the containers are operational:
docker ps
Output:
CONTAINER ID IMAGE ... CREATED STATUS PORTS ...
c8f342d086f3 synmetrix/stack ... 1m ago Up 1m 80->8888/tcp ...
30ea14ddaa5e postgres:12 ... 1m ago Up 1m 5432/tcp
The installation of all dependencies will take approximately 5-7 minutes. Wait until you see the Synmetrix Stack is ready message. You can view the logs using docker-compose logs -f to confirm if the process has completed.
First, it's recommended to install Rosetta 2 on your Mac. This will allow Docker to run ARM64v8 containers. Since Docker version 4.25 it allows to run ARM64v8 containers natively, but some users still encounter issues without Rosetta installed.
For ARM64v8, Cubestore requires a specific version. Update the Cubestore version in the docker-compose file to include the -arm64v8 suffix. For instance, use v0.35.33-arm64v8 (refer to the Cubestore tags on Docker Hub for the latest version).
To run the docker-compose file for ARM64v8, use the following command:
docker-compose pull stack && CUBESTORE_VERSION=v0.35.33-arm64v8 docker-compose up -d
Video guide (MacOS, M3 Max processor):
- You can access Synmetrix at http://localhost/
- The GraphQL endpoint is located at http://localhost/v1/graphql
- The Admin Console (Hasura Console) can be found at http://localhost/console
- The Cube Swagger API can be found at http://localhost:4000/docs
-
Admin Console Access: Ensure to check
HASURA_GRAPHQL_ADMIN_SECRETin the docker-compose file. This is mandatory for accessing the Admin Console. The default value isadminsecret. Remember to modify this in a production environment. -
Environment Variables: Set up all necessary environment variables. Synmetrix will function with the default values, but certain features might not perform as anticipated.
-
Preloaded Seed Data: The project is equipped with preloaded seed data. Use the credentials below to sign in:
- Email:
[email protected] - Password:
demodemo
This account is pre-configured with two demo datasources and their respective SQL API access. For SQL operations, you can use the following credentials with any PostgreSQL client tool such as DBeaver or TablePlus:
Host Port Database User Password localhost 15432 db demo_pg_user demo_pg_pass localhost 15432 db demo_clickhouse_user demo_clickhouse_pass - Email:
Demo: app.synmetrix.org
- Login:
[email protected] - Password:
demodemo
| Database type | Host | Port | Database | User | Password | SSL |
|---|---|---|---|---|---|---|
| ClickHouse | gh-api.clickhouse.tech | 443 | default | play | no password | true |
| PostgreSQL | demo-db-examples.cube.dev | 5432 | ecom | cube | 12345 | false |
Synmetrix leverages Cube for flexible data modeling and transformations.
Cube implements a multi-stage SQL data modeling architecture:
- Raw data sits in a source database such as Postgres, MySQL, etc.
- The raw data is modeled into reusable data marts using Cube Data Models files. These models files allow defining metrics, dimensions, granularities and relationships.
- The models act as an abstraction layer between the raw data and application code.
- Cube then generates optimized analytical SQL queries against the raw data based on the model.
- The Cube Store distributed cache optimizes query performance by caching query results.
This modeling architecture makes it simple to create fast and complex analytical queries with Cube that are optimized to run against large datasets.
The unified data model can consolidate metrics from across different databases and systems, providing a consistent semantic layer for end users.
For production workloads, Synmetrix uses Cube Store as the caching and query execution layer.
Cube Store is a purpose-built database for operational analytics, optimized for fast aggregations and time series data. It provides:
- Distributed querying for scalability
- Advanced caching for fast queries
- columnar storage for analytics performance
- Integration with Cube for modeling
By leveraging Cube Store and Cube together, Synmetrix benefits from excellent analytics performance and flexibility in modeling metrics.
| Repository | Description |
|---|---|
| mlcraft-io/mlcraft | Synmetrix Monorepo |
| mlcraft-io/client-v2 | Synmetrix Client |
| mlcraft-io/docs | Synmetrix Docs |
| mlcraft-io/examples | Synmetrix Examples |
For general help using Synmetrix, please refer to the official Synmetrix documentation. For additional help, you can use one of these channels to ask a question:
- Slack / For live discussion with the Community and Synmetrix team
- GitHub / Bug reports, Contributions
- Twitter / Updates and news
- Youtube / Video tutorials and demos
Check out our roadmap to get informed on what we are currently working on, and what we have in mind for the next weeks, months and years.
The core Synmetrix is available under the Apache License 2.0 (Apache-2.0).
All other contents are available under the MIT License.
| Component | Requirement |
|---|---|
| Processor (CPU) | 3.2 GHz or higher, modern processor with multi-threading and virtualization support. |
| RAM | 8 GB or more to handle computational tasks and data processing. |
| Disk Space | At least 30 GB of free space for software installation and storing working data. |
| Network | Internet connectivity is required for cloud services and software updates. |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mlcraft
Similar Open Source Tools
mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

OmAgent
OmAgent is an open-source agent framework designed to streamline the development of on-device multimodal agents. It enables agents to empower various hardware devices, integrates speed-optimized SOTA multimodal models, provides SOTA multimodal agent algorithms, and focuses on optimizing the end-to-end computing pipeline for real-time user interaction experience. Key features include easy connection to diverse devices, scalability, flexibility, and workflow orchestration. The architecture emphasizes graph-based workflow orchestration, native multimodality, and device-centricity, allowing developers to create bespoke intelligent agent programs.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
kubesphere
KubeSphere is a distributed operating system for cloud-native application management, using Kubernetes as its kernel. It provides a plug-and-play architecture, allowing third-party applications to be seamlessly integrated into its ecosystem. KubeSphere is also a multi-tenant container platform with full-stack automated IT operation and streamlined DevOps workflows. It provides developer-friendly wizard web UI, helping enterprises to build out a more robust and feature-rich platform, which includes most common functionalities needed for enterprise Kubernetes strategy.
OpenContracts
OpenContracts is an Apache-2 licensed enterprise document analytics tool that supports multiple formats, including PDF and txt-based formats. It features multiple document ingestion pipelines with a pluggable architecture for easy format and ingestion engine support. Users can create custom document analytics tools with beautiful result displays, support mass document data extraction with a LlamaIndex wrapper, and manage document collections, layout parsing, automatic vector embeddings, and human annotation. The tool also offers pluggable parsing pipelines, human annotation interface, LlamaIndex integration, data extraction capabilities, and custom data extract pipelines for bulk document querying.
gpt-rag-ingestion
The GPT-RAG Data Ingestion service automates processing of diverse document types for indexing in Azure AI Search. It uses intelligent chunking strategies tailored to each format, generates text and image embeddings, and enables rich, multimodal retrieval experiences for agent-based RAG applications. Supported data sources include Blob Storage, NL2SQL Metadata, and SharePoint. The service selects chunkers based on file extension, such as DocAnalysisChunker for PDF files, OCR for image files, LangChainChunker for text-based files, TranscriptionChunker for video transcripts, and SpreadsheetChunker for spreadsheets. Deployment requires provisioning infrastructure and assigning specific roles to the user or service principal.
arthur-engine
The Arthur Engine is a comprehensive tool for monitoring and governing AI/ML workloads. It provides evaluation and benchmarking of machine learning models, guardrails enforcement, and extensibility for fitting into various application architectures. With support for a wide range of evaluation metrics and customizable features, the tool aims to improve model understanding, optimize generative AI outputs, and prevent data-security and compliance risks. Key features include real-time guardrails, model performance monitoring, feature importance visualization, error breakdowns, and support for custom metrics and models integration.

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

ludwig
Ludwig is a declarative deep learning framework designed for scale and efficiency. It is a low-code framework that allows users to build custom AI models like LLMs and other deep neural networks with ease. Ludwig offers features such as optimized scale and efficiency, expert level control, modularity, and extensibility. It is engineered for production with prebuilt Docker containers, support for running with Ray on Kubernetes, and the ability to export models to Torchscript and Triton. Ludwig is hosted by the Linux Foundation AI & Data.
lm.rs
lm.rs is a tool that allows users to run inference on Language Models locally on the CPU using Rust. It supports LLama3.2 1B and 3B models, with a WebUI also available. The tool provides benchmarks and download links for models and tokenizers, with recommendations for quantization options. Users can convert models from Google/Meta on huggingface using provided scripts. The tool can be compiled with cargo and run with various arguments for model weights, tokenizer, temperature, and more. Additionally, a backend for the WebUI can be compiled and run to connect via the web interface.
rag-time
RAG Time is a 5-week AI learning series focusing on Retrieval-Augmented Generation (RAG) concepts. The repository contains code samples, step-by-step guides, and resources to help users master RAG. It aims to teach foundational and advanced RAG concepts, demonstrate real-world applications, and provide hands-on samples for practical implementation.
ToolJet
ToolJet is an open-source platform for building and deploying internal tools, workflows, and AI agents. It offers a visual builder with drag-and-drop UI, integrations with databases, APIs, SaaS apps, and object storage. The community edition includes features like a visual app builder, ToolJet database, multi-page apps, collaboration tools, extensibility with plugins, code execution, and security measures. ToolJet AI, the enterprise version, adds AI capabilities for app generation, query building, debugging, agent creation, security compliance, user management, environment management, GitSync, branding, access control, embedded apps, and enterprise support.
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.
all-rag-techniques
This repository provides a hands-on approach to Retrieval-Augmented Generation (RAG) techniques, simplifying advanced concepts into understandable implementations using Python libraries like openai, numpy, and matplotlib. It offers a collection of Jupyter Notebooks with concise explanations, step-by-step implementations, code examples, evaluations, and visualizations for various RAG techniques. The goal is to make RAG more accessible and demystify its workings for educational purposes.
For similar tasks
langtrace
Langtrace is an open source observability software that lets you capture, debug, and analyze traces and metrics from all your applications that leverage LLM APIs, Vector Databases, and LLM-based Frameworks. It supports Open Telemetry Standards (OTEL), and the traces generated adhere to these standards. Langtrace offers both a managed SaaS version (Langtrace Cloud) and a self-hosted option. The SDKs for both Typescript/Javascript and Python are available, making it easy to integrate Langtrace into your applications. Langtrace automatically captures traces from various vendors, including OpenAI, Anthropic, Azure OpenAI, Langchain, LlamaIndex, Pinecone, and ChromaDB.
mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

rtdl-num-embeddings
This repository provides the official implementation of the paper 'On Embeddings for Numerical Features in Tabular Deep Learning'. It focuses on transforming scalar continuous features into vectors before integrating them into the main backbone of tabular neural networks, showcasing improved performance. The embeddings for continuous features are shown to enhance the performance of tabular DL models and are applicable to various conventional backbones, offering efficiency comparable to Transformer-based models. The repository includes Python packages for practical usage, exploration of metrics and hyperparameters, and reproducing reported results for different algorithms and datasets.
VulBench
This repository contains materials for the paper 'How Far Have We Gone in Vulnerability Detection Using Large Language Model'. It provides a tool for evaluating vulnerability detection models using datasets such as d2a, ctf, magma, big-vul, and devign. Users can query the model 'Llama-2-7b-chat-hf' and store results in a SQLite database for analysis. The tool supports binary and multiple classification tasks with concurrency settings. Additionally, users can evaluate the results and generate a CSV file with metrics for each dataset and prompt type.

agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.
hyperfy
Hyperfy is a powerful tool for automating social media marketing tasks. It provides a user-friendly interface to schedule posts, analyze performance metrics, and engage with followers across multiple platforms. With Hyperfy, users can save time and effort by streamlining their social media management processes in one centralized platform.
rill
Rill delivers rapid, self-service dashboards for data engineers and analysts directly on raw data lakes, ensuring reliable, fast-loading dashboards with accurate, real-time metrics. It comes with an embedded in-memory database for lightning-fast performance and supports bringing your own OLAP engine. Rill implements BI-as-code through SQL-based definitions, YAML configuration, Git integration, and CLI tools. Its metrics layer provides a unified way to define, compute, and serve business metrics, while AI agents can access fresh metrics instantly for precise decision-making and intelligent automation.
For similar jobs
mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.