
sqlcoder
SoTA LLM for converting natural language questions to SQL queries
Stars: 2767

Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.
README:
Defog's SQLCoder is a family of state-of-the-art LLMs for converting natural language questions to SQL queries.
Interactive Demo | 🤗 HF Repo | ♾️ Colab | 🐦 Twitter
SQLCoder is a family of large language models that outperforms gpt-4 and gpt-4-turbo for natural language to SQL generation tasks on our sql-eval framework, and significantly outperform all popular open-source models.
If running on a device with an NVIDIA GPU with more than 16GB VRAM (best performance)
pip install "sqlcoder[transformers]"
If running on Apple Silicon (less good performance, because of quantization and lack of beam search)
CMAKE_ARGS="-DLLAMA_METAL=on" pip install "sqlcoder[llama-cpp]"
If running on a non-apple silicon computer without GPU access, please run this on Linux/Intel Mac
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install "sqlcoder[llama-cpp]"
And run this on Windows
$env:CMAKE_ARGS = "-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS"
pip install "sqlcoder[llama-cpp]"SQLCoder has not been tested on other platforms yet. Contributions for testing on other platforms are very welcome!
In your terminal, run
sqlcoder launch
With this, you will be able to connect straight to your database, so you can add your metadata and query it visually.
The code in this repo (what little there is of it) is Apache-2 licensed. The model weights have a CC BY-SA 4.0 license. The TL;DR is that you can use and modify the model for any purpose – including commercial use. However, if you modify the weights (for example, by fine-tuning), you must open-source your modified weights under the same license terms.
Defog was trained on more than 20,000 human-curated questions. These questions were based on 10 different schemas. None of the schemas in the training data were included in our evaluation framework.
You can read more about our training approach and evaluation framework.
We classified each generated question into one of 6 categories. The table displays the percentage of questions answered correctly by each model, broken down by category.
| date | group_by | order_by | ratio | join | where | |
|---|---|---|---|---|---|---|
| sqlcoder-70b | 96 | 91.4 | 97.1 | 85.7 | 97.1 | 91.4 |
| sqlcoder-7b-2 | 96 | 91.4 | 94.3 | 91.4 | 94.3 | 77.1 |
| sqlcoder-34b | 80 | 94.3 | 85.7 | 77.1 | 85.7 | 80 |
| gpt-4 | 72 | 94.3 | 97.1 | 80 | 91.4 | 80 |
| gpt-4-turbo | 76 | 91.4 | 91.4 | 62.8 | 88.6 | 77.1 |
| natural-sql-7b | 56 | 88.6 | 85.7 | 60 | 88.6 | 80 |
| sqlcoder-7b | 64 | 82.9 | 74.3 | 54.3 | 74.3 | 74.3 |
| gpt-3.5 | 72 | 77.1 | 82.8 | 34.3 | 65.7 | 71.4 |
| claude-2 | 52 | 71.4 | 74.3 | 57.1 | 65.7 | 62.9 |
You can use SQLCoder via the transformers library by downloading our model weights from the Hugging Face repo. We have added sample code for inference on a sample database schema.
python inference.py -q "Question about the sample database goes here"
# Sample question:
# Do we get more revenue from customers in New York compared to customers in San Francisco? Give me the total revenue for each city, and the difference between the two.You can also use a demo on our website here
SQLCoder-34B has been tested on a 4xA10 GPU with float16 weights. You can also load an 8-bit and 4-bit quantized version of the model on consumer GPUs with 20GB or more of memory – like RTX 4090, RTX 3090, and Apple M2 Pro, M2 Max, or M2 Ultra Chips with 20GB or more of memory.
- [x] Open-source the v1 model weights
- [x] Train the model on more data, with higher data variance
- [ ] Tune the model further with Reward Modelling and RLHF
- [ ] Pretrain a model from scratch that specializes in SQL analysis
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sqlcoder
Similar Open Source Tools
sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.
PostTrainBench
PostTrainBench is a benchmark designed to measure the ability of command-line interface (CLI) agents to post-train pre-trained large language models (LLMs). The agents are tasked with improving the performance of a base LLM on a given benchmark using an evaluation script and 10 hours on an H100 GPU. The benchmark scores are computed after post-training, and the setup evaluates an agent's capability to conduct AI research and development. The repository provides a platform for collaborative contributions to expand tasks and agent scaffolds, with the potential for co-authorship on research papers.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

moatless-tools
Moatless Tools is a hobby project focused on experimenting with using Large Language Models (LLMs) to edit code in large existing codebases. The project aims to build tools that insert the right context into prompts and handle responses effectively. It utilizes an agentic loop functioning as a finite state machine to transition between states like Search, Identify, PlanToCode, ClarifyChange, and EditCode for code editing tasks.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord

AI-Toolbox
AI-Toolbox is a C++ library aimed at representing and solving common AI problems, with a focus on MDPs, POMDPs, and related algorithms. It provides an easy-to-use interface that is extensible to many problems while maintaining readable code. The toolbox includes tutorials for beginners in reinforcement learning and offers Python bindings for seamless integration. It features utilities for combinatorics, polytopes, linear programming, sampling, distributions, statistics, belief updating, data structures, logging, seeding, and more. Additionally, it supports bandit/normal games, single agent MDP/stochastic games, single agent POMDP, and factored/joint multi-agent scenarios.

cladder
CLadder is a repository containing the CLadder dataset for evaluating causal reasoning in language models. The dataset consists of yes/no questions in natural language that require statistical and causal inference to answer. It includes fields such as question_id, given_info, question, answer, reasoning, and metadata like query_type and rung. The dataset also provides prompts for evaluating language models and example questions with associated reasoning steps. Additionally, it offers dataset statistics, data variants, and code setup instructions for using the repository.

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.
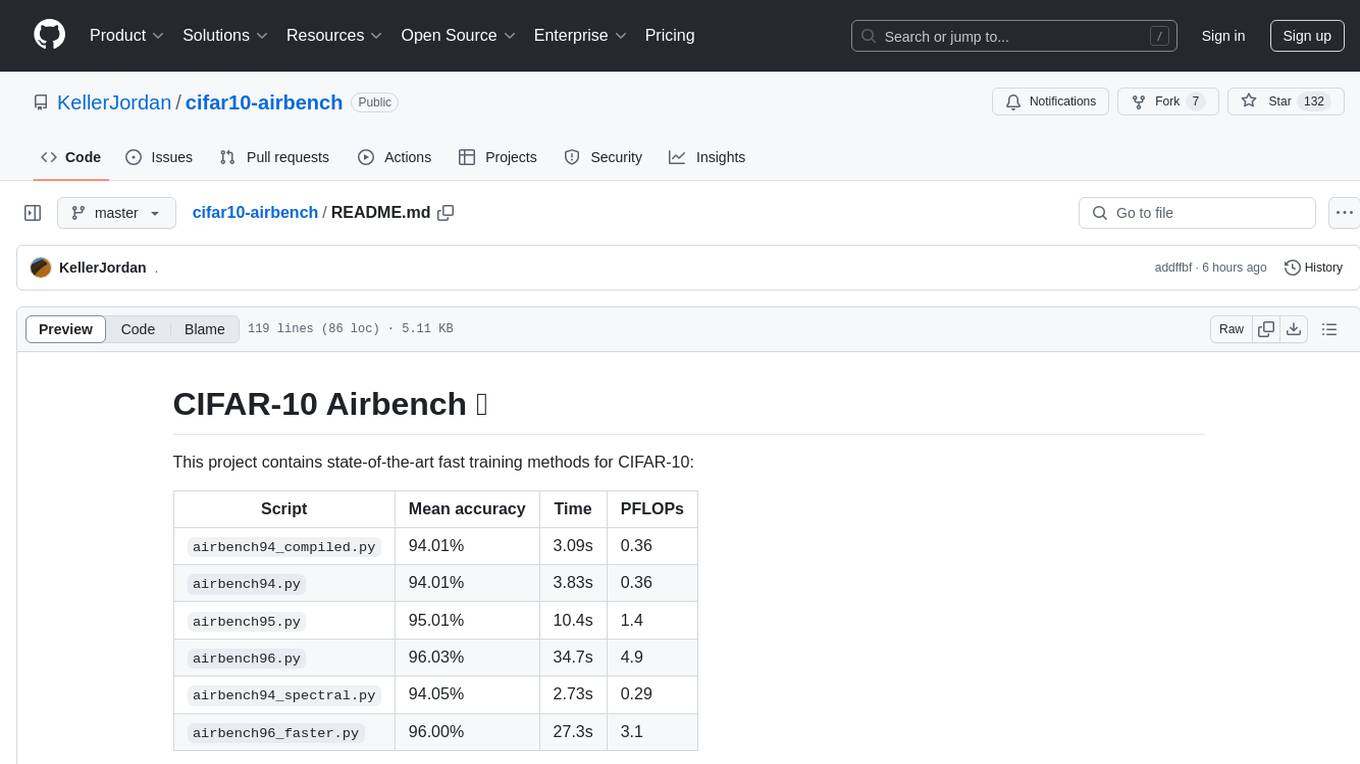
cifar10-airbench
CIFAR-10 Airbench is a project offering fast and stable training baselines for CIFAR-10 dataset, facilitating machine learning research. It provides easily runnable PyTorch scripts for training neural networks with high accuracy levels. The methods used in this project aim to accelerate research on fundamental properties of deep learning. The project includes GPU-accelerated dataloader for custom experiments and trainings, and can be used for data selection and active learning experiments. The training methods provided are faster than standard ResNet training, offering improved performance for research projects.
AgentGym
AgentGym is a framework designed to help the AI community evaluate and develop generally-capable Large Language Model-based agents. It features diverse interactive environments and tasks with real-time feedback and concurrency. The platform supports 14 environments across various domains like web navigating, text games, house-holding tasks, digital games, and more. AgentGym includes a trajectory set (AgentTraj) and a benchmark suite (AgentEval) to facilitate agent exploration and evaluation. The framework allows for agent self-evolution beyond existing data, showcasing comparable results to state-of-the-art models.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.
sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.
TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

quadratic
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.