
ABQ-LLM
An acceleration library that supports arbitrary bit-width combinatorial quantization operations
Stars: 99
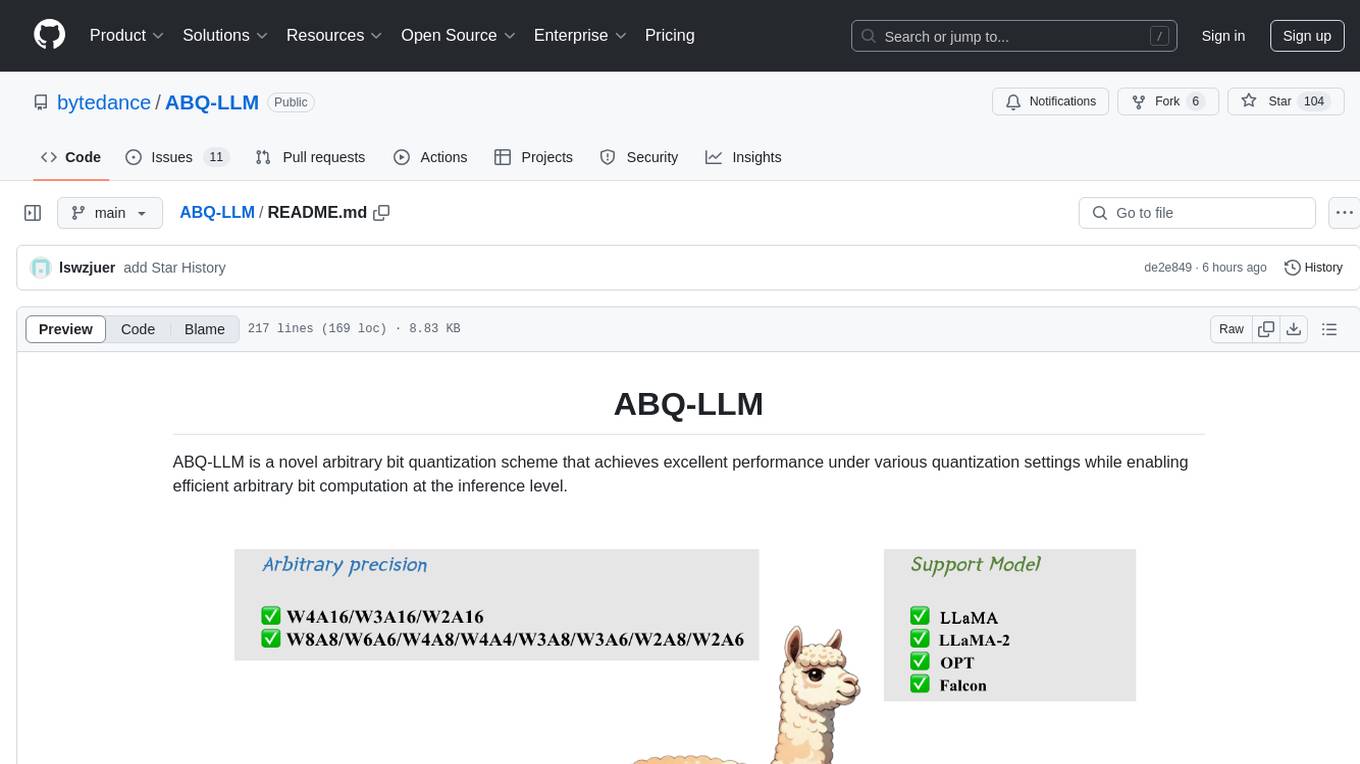
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level. The algorithm supports precise weight-only quantization and weight-activation quantization. It provides pre-trained model weights and a set of out-of-the-box quantization operators for arbitrary bit model inference in modern architectures.
README:
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level.
 The current release version supports the following features:
The current release version supports the following features:
- The ABQ-LLM algorithm is employed for precise weight-only quantization (W8A16, W4A16, W3A16, W2A16) and weight-activation quantization (W8A8, W6A6, W4A4, W3A8, W3A6, W2A8, W2A6).
- Pre-trained ABQ-LLM model weights for LLM (LLaMA and LLaMA-2 loaded to run quantized models).
- A set of out-of-the-box arbitrary bit quantization operators that support arbitrary bit model inference in Turing and above architectures.
conda create -n abq-llm python=3.10.0 -y
conda activate abq-llm
git clone https://github.com/bytedance/ABQ-LLM.git
cd ./ABQ-LLM/algorithm
pip install --upgrade pip
pip install -r requirements.txt
You can actually compile and test our quantized inference Kernel, but you need to install the basic CUDA Toolkit.
- Install CUDA Toolkit (11.8 or 12.1, linux or windows). Use the Express Installation option. Installation may require a restart (windows).
- Clone the CUTLASS. (It is only used for speed comparison)
git submodule init
git submodule update
We provide pre-trained ABQ-LLM model zoo for multiple model families, including LLaMa-1&2, OPT. The detailed support list:
| Models | Sizes | W4A16 | W3A16 | W2A16 | W2A16g128 | W2A16g64 |
|---|---|---|---|---|---|---|
| LLaMA | 7B/13B | ✅ | ✅ | ✅ | ✅ | ✅ |
| LLaMA-2 | 7B/13B | ✅ | ✅ | ✅ | ✅ | ✅ |
| Models | Sizes | W8A8 | W4A8 | W6A6 | W4A6 | W4A4 | W3A8 | W3A6 | W2A8 | W2A6 |
|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA | 7B/13B | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| LLaMA-2 | 7B/13B | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
We provide the pre-trained ABQ- LLM model weight in hugginface, you can verify the model performance by the following commands.
CUDA_VISIBLE_DEVICES=0 python run_pretrain_abq_model.py \
--model /PATH/TO/LLaMA/llama-7b-ABQ \
--wbits 4 --abits 4
We also provide full script to run ABQ-LLM in ./algorithm/scripts/. We use LLaMa-7B as an example here:
- Obtain the channel-wise scales and shifts required for initialization:
python generate_act_scale_shift.py --model /PATH/TO/LLaMA/llama-7b
- Weight-only quantization
# W3A16
CUDA_VISIBLE_DEVICES=0 python main.py \
--model /PATH/TO/LLaMA/llama-7b \
--epochs 20 --output_dir ./log/llama-7b-w3a16 \
--eval_ppl --wbits 3 --abits 16 --lwc --let
# W3A16g128
CUDA_VISIBLE_DEVICES=0 python main.py \
--model /PATH/TO/LLaMA/llama-7b \
--epochs 20 --output_dir ./log/llama-7b-w3a16g128 \
--eval_ppl --wbits 3 --abits 16 --group_size 128 --lwc --let
- weight-activation quantization
# W4A4
CUDA_VISIBLE_DEVICES=0 python main.py \
--model /PATH/TO/LLaMA/llama-7b \
--epochs 20 --output_dir ./log/llama-7b-w4a4 \
--eval_ppl --wbits 4 --abits 4 --lwc --let \
--tasks piqa,arc_easy,arc_challenge,boolq,hellaswag,winogrande
More detailed and optional arguments:
-
--model: the local model path or huggingface format. -
--wbits: weight quantization bits. -
--abits: activation quantization bits. -
--group_size: group size of weight quantization. If no set, use per-channel quantization for weight as default. -
--lwc: activate the Learnable Weight Clipping (LWC). -
--let: activate the Learnable Equivalent Transformation (LET). -
--lwc_lr: learning rate of LWC parameters, 1e-2 as default. -
--let_lr: learning rate of LET parameters, 5e-3 as default. -
--epochs: training epochs. You can set it as 0 to evaluate pre-trained ABQ-LLM checkpoints. -
--nsamples: number of calibration samples, 128 as default. -
--eval_ppl: evaluating the perplexity of quantized models. -
--tasks: evaluating zero-shot tasks. -
--multigpu: to inference larger network on multiple GPUs -
--real_quant: real quantization, which can see memory reduce. Note that due to the limitations of AutoGPTQ kernels, the real quantization of weight-only quantization can only lead memory reduction, but with slower inference speed. -
--save_dir: saving the quantization model for further exploration.
- Compile Kernels.
By default, w2a2, w3a3, w4a4, w5a5, w6a6, w7a7, w8a8 are compiled, and the kernel of w2a4, w2a6, w2a8, and w4a8 quantization combination is compiled. Each quantization scheme corresponds to dozens of kernel implementation schemes to build its search space.
# linux
cd engine
bash build.sh
# windows
cd engine
build.bat
- Comprehensive benchmark.
For the typical GEMM operation of the llama model, different quantization combinations (w2a2, w3a3, w4a4,w5a5, w6a6, w7a7, w8a8, w2a4, w2a6, w2a8, w4a8) are tested to obtain the optimal performance in the search space of each quantization combination.
# linux
bash test.sh
# windows
test.bat
- Add new quantization combinations(Optional).
We reconstructed the quantized matrix multiplication operation in a clever way, decomposing it into a series of binary matrix multiplications, and performed a high degree of template and computational model abstraction.
Based on the above optimizations, you can quickly expand our code to support new quantization combinations, such as wpaq. You only need to add wpaq instantiation definition and declaration files in engine/mma_any/aq_wmma_impl and then recompile.
The performance upper limit depends on how the search space is defined (the instantiated function configuration). For related experience, please refer to the paper or the existing implementation in this directory.
- Compile the fastertransformer
cd fastertransformer
bash build.sh
- Config llama (Change precision in examples/cpp/llama/llama_config.ini)
fp16: int8_mode=0
w8a16: int8_mode=1
w8a8: int8_mode=2
w4a16: int8_mode=4
w2a8: int8_mode=5
- Run llama on single GPU
cd build_release
./bin/llama_example
- (Optional) Run in multi GPU. Change tensor_para_size=2 in examples/cpp/llama/llama_config.ini
cd build_release
mpirun -n 2 ./bin/llama_example
- ABQ-LLM achieve SoTA performance in weight-only quantization

- ABQ-LLM achieve SoTA performance in weight-activation quantization

- ABQ-LLM achieve SoTA performance in zero-shot task

- On kernel inference acceleration, ABQ- LLM achieves performance gains that far exceed those of CUTLASS and CUBLAS.

- We integrated our ABQKernel into FastTransformer and compared it with the FP16 version of FastTransformer and the INT8 version of SmoothQuant. Our approach achieved a 2.8x speedup and 4.8x memory compression over FP16, using only 10GB of memory on LLaMA-30B, less than what FP16 requires for LLaMA-7B. Additionally, it outperformed SmoothQuant with a 1.6x speedup and 2.7x memory compression.

SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
GPTQ: Accurate Post-training Compression for Generative Pretrained Transformers
RPTQ: Reorder-Based Post-Training Quantization for Large Language Models
OmniQuant is a simple and powerful quantization technique for LLMs
If you use our ABQ-LLM approach in your research, please cite our paper:
@article{zeng2024abq,
title={ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models},
author={Zeng, Chao and Liu, Songwei and Xie, Yusheng and Liu, Hong and Wang, Xiaojian and Wei, Miao and Yang, Shu and Chen, Fangmin and Mei, Xing},
journal={arXiv preprint arXiv:2408.08554},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ABQ-LLM
Similar Open Source Tools
ABQ-LLM
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level. The algorithm supports precise weight-only quantization and weight-activation quantization. It provides pre-trained model weights and a set of out-of-the-box quantization operators for arbitrary bit model inference in modern architectures.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
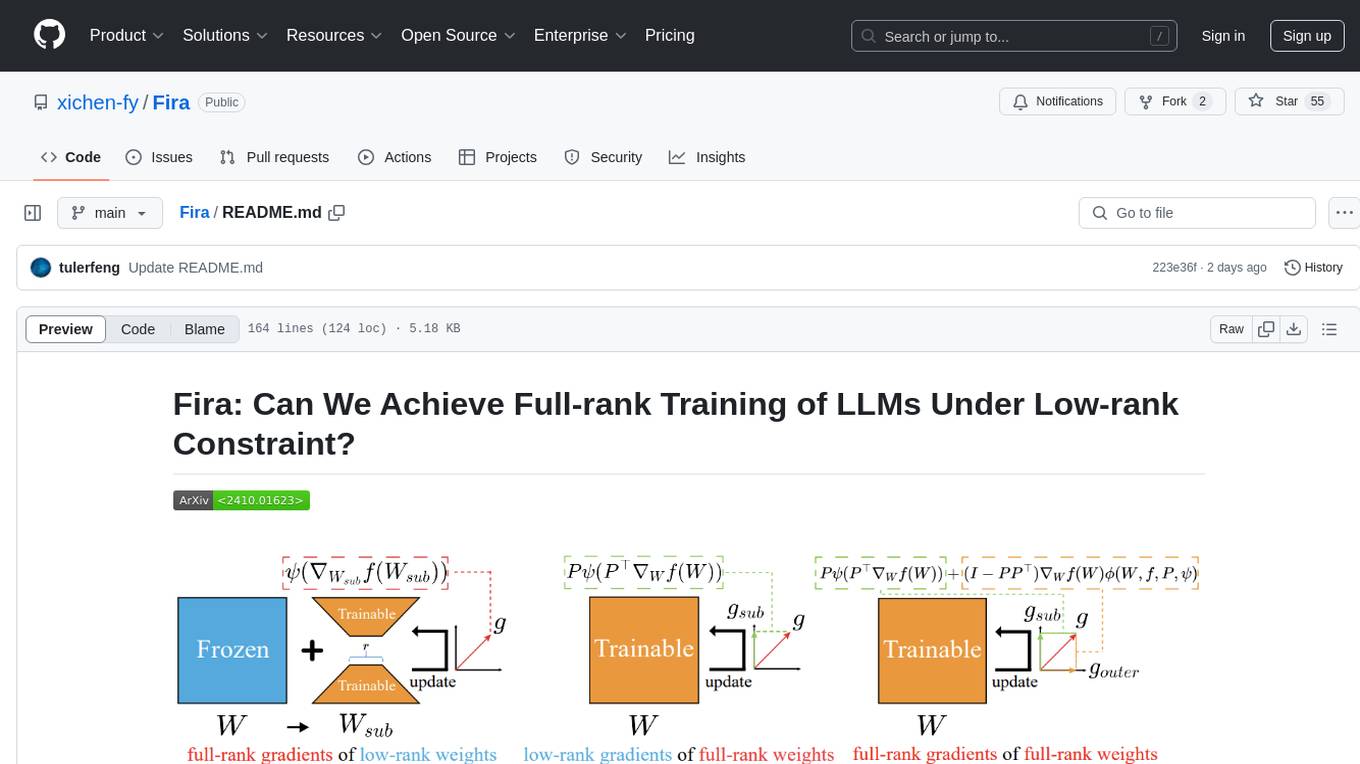
Fira
Fira is a memory-efficient training framework for Large Language Models (LLMs) that enables full-rank training under low-rank constraint. It introduces a method for training with full-rank gradients of full-rank weights, achieved with just two lines of equations. The framework includes pre-training and fine-tuning functionalities, packaged as a Python library for easy use. Fira utilizes Adam optimizer by default and provides options for weight decay. It supports pre-training LLaMA models on the C4 dataset and fine-tuning LLaMA-7B models on commonsense reasoning tasks.

cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
open-unlearning
OpenUnlearning is an easily extensible framework that unifies LLM unlearning evaluation benchmarks. It provides efficient implementations of TOFU and MUSE unlearning benchmarks, supporting 5 unlearning methods, 3+ datasets, 6+ evaluation metrics, and 7+ LLMs. Users can easily extend the framework to incorporate more variants, collaborate by adding new benchmarks, unlearning methods, datasets, and evaluation metrics, and drive progress in the field.

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.

AI-Toolbox
AI-Toolbox is a C++ library aimed at representing and solving common AI problems, with a focus on MDPs, POMDPs, and related algorithms. It provides an easy-to-use interface that is extensible to many problems while maintaining readable code. The toolbox includes tutorials for beginners in reinforcement learning and offers Python bindings for seamless integration. It features utilities for combinatorics, polytopes, linear programming, sampling, distributions, statistics, belief updating, data structures, logging, seeding, and more. Additionally, it supports bandit/normal games, single agent MDP/stochastic games, single agent POMDP, and factored/joint multi-agent scenarios.

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.
llm-python
A set of instructional materials, code samples and Python scripts featuring LLMs (GPT etc) through interfaces like llamaindex, langchain, Chroma (Chromadb), Pinecone etc. Mainly used to store reference code for my LangChain tutorials on YouTube.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.
llama-recipes
The llama-recipes repository provides a scalable library for fine-tuning Llama 2, along with example scripts and notebooks to quickly get started with using the Llama 2 models in a variety of use-cases, including fine-tuning for domain adaptation and building LLM-based applications with Llama 2 and other tools in the LLM ecosystem. The examples here showcase how to run Llama 2 locally, in the cloud, and on-prem.
llama-zip
llama-zip is a command-line utility for lossless text compression and decompression. It leverages a user-provided large language model (LLM) as the probabilistic model for an arithmetic coder, achieving high compression ratios for structured or natural language text. The tool is not limited by the LLM's maximum context length and can handle arbitrarily long input text. However, the speed of compression and decompression is limited by the LLM's inference speed.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.
For similar tasks
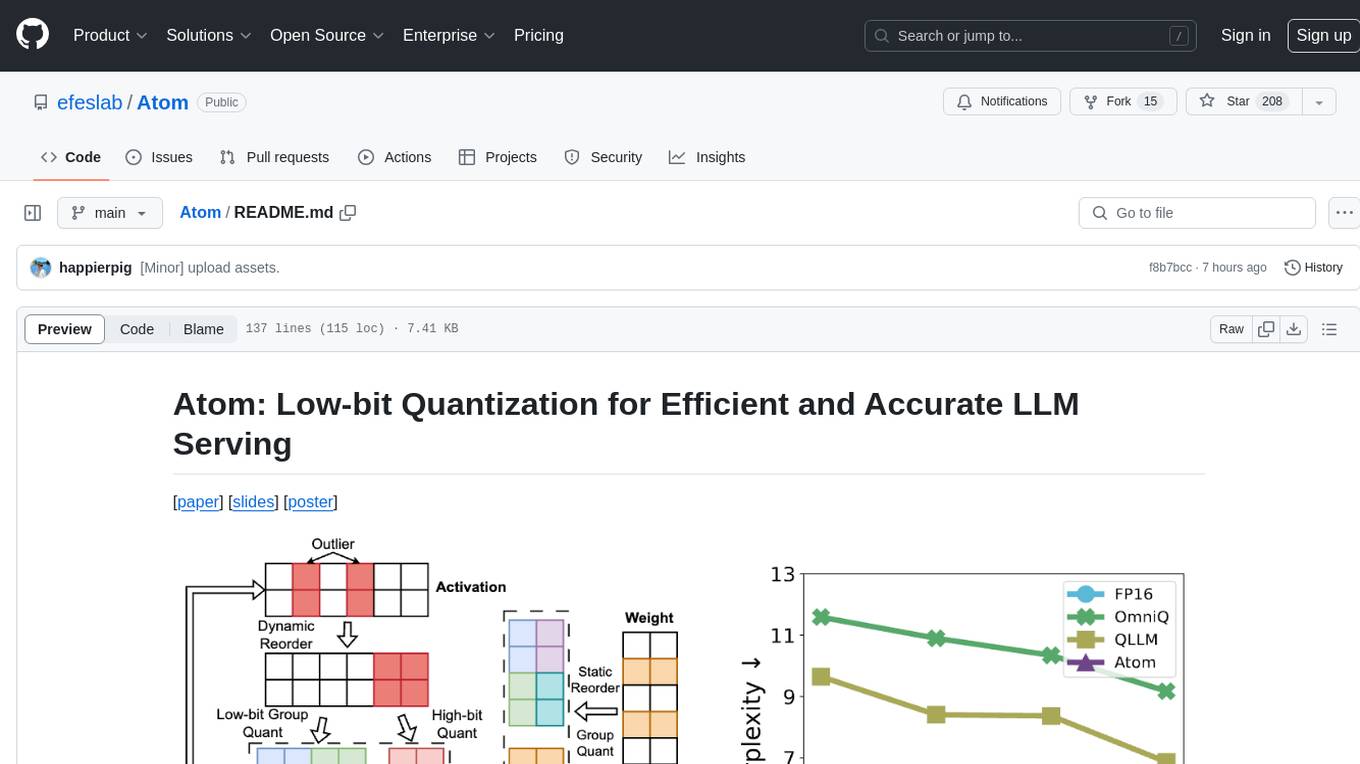
Atom
Atom is an accurate low-bit weight-activation quantization algorithm that combines mixed-precision, fine-grained group quantization, dynamic activation quantization, KV-cache quantization, and efficient CUDA kernels co-design. It introduces a low-bit quantization method, Atom, to maximize Large Language Models (LLMs) serving throughput with negligible accuracy loss. The codebase includes evaluation of perplexity and zero-shot accuracy, kernel benchmarking, and end-to-end evaluation. Atom significantly boosts serving throughput by using low-bit operators and reduces memory consumption via low-bit quantization.
ABQ-LLM
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level. The algorithm supports precise weight-only quantization and weight-activation quantization. It provides pre-trained model weights and a set of out-of-the-box quantization operators for arbitrary bit model inference in modern architectures.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.