
DaoCloud-docs
DaoCloud Enterprise 5.0 Documentation
Stars: 200
DaoCloud Enterprise 5.0 Documentation provides detailed information on using DaoCloud, a Certified Kubernetes Service Provider. The documentation covers current and legacy versions, workflow control using GitOps, and instructions for opening a PR and previewing changes locally. It also includes naming conventions, writing tips, references, and acknowledgments to contributors. Users can find guidelines on writing, contributing, and translating pages, along with using tools like MkDocs, Docker, and Poetry for managing the documentation.
README:

![]()
中文版 | English
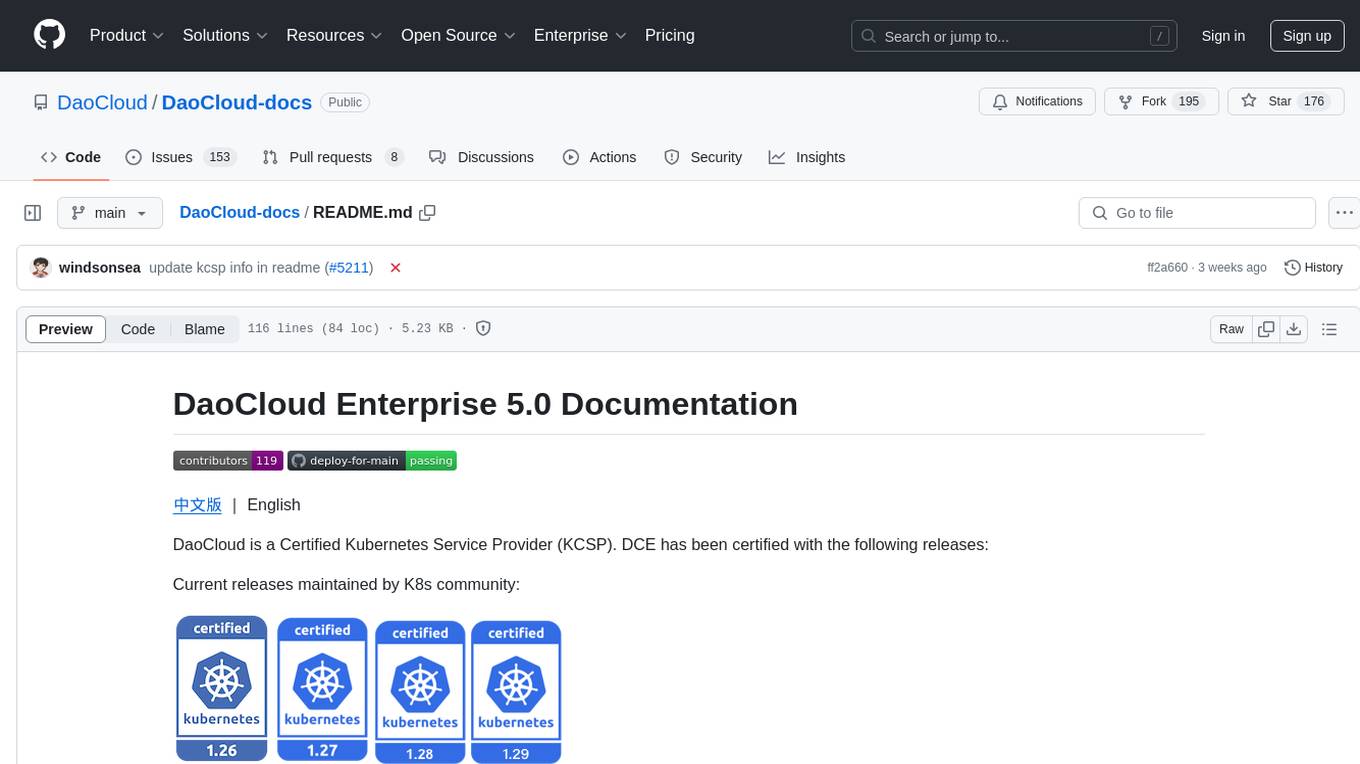
DaoCloud is a Certified Kubernetes Service Provider (KCSP). DCE has been certified with the following releases:
Current releases maintained by K8s community:




Legacy versions that are no longer maintained by the K8s community but will continue to be maintained by DaoCloud's KLTS:












DCE 5.0 website is created with MkDocs. All pages are written in markdown. We use GitOps to control workflow and versions.
This website uses Pull Request (PR) to modify, translate, and manage all pages.
- Click
Forkto create a fork - Run
git cloneto clone this fork to your computer - Edit one or more pages locally and preview it
- Run git commands, such as
git add,git commit, andgit push, to submit your changes - Open a PR in this repo
- Successfully merge after reviewing, thanks.
This section describes how you can preview your changes before commit.
- Install and run Docker.
- Run
make serveand preview your changes.
See MkDocs documents to install。
- Install Poetry and Python 3.9+
- Configure Poetry:
poetry config virtualenvs.in-project true - Enable venv:
poetry env use 3.9
- Configure Poetry:
- Install dependencies:
poetry install - Run
poetry run mkdocs serve -f mkdocs.ymlin the repo folder locally - Preview with http://0.0.0.0:8000/
This section lists some conventions about a file or folder name for your reference:
-
Only contain English lower cases and hyphens (
-) -
Do not contain any of these characters like:
- Chinese chars
- spaces
- special chars like
*,?,\,/,:,#,%,~,{,}
- Connect words with a hyphen (
-) - Keep short:up to 5 English words, avoid repetition, use abbreviations
- Be descriptive: easy to understand and reflect the doc's subject
| No | Yes | Why |
|---|---|---|
| ConfigName | config-name | Use small letters and hyphens |
| create secret | create-secret | No spaces in name |
| quick-start-install-online-install | online-install | Keep short |
| c-ws | create-workspace | Be descriptive |
| update_image | update-image | Connect words with hyphens |
- Indent 4 spaces for bullets
- Provide a space between zh and en chars
- Provide a blank line before and after a para, an image, a heading, or a list
- Do not add any punctuation by the end of a heading
- Care about links to avoid any null or dead link
- Give a consistent experience to explore all pages herein
For more details refer to DaoCloud Style Guide of Writing.
- docs.daocloud.io Release v1.0
- DaoCloud Style Guide of Writing
- Contribution Guideline
- Citizen Code of Conduct
- Export Word and PDF
- Automatic Page Translation; ChatGPT is recommended to use for better translation

| Site | Status |
|---|---|
| daocloud-docs |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DaoCloud-docs
Similar Open Source Tools
DaoCloud-docs
DaoCloud Enterprise 5.0 Documentation provides detailed information on using DaoCloud, a Certified Kubernetes Service Provider. The documentation covers current and legacy versions, workflow control using GitOps, and instructions for opening a PR and previewing changes locally. It also includes naming conventions, writing tips, references, and acknowledgments to contributors. Users can find guidelines on writing, contributing, and translating pages, along with using tools like MkDocs, Docker, and Poetry for managing the documentation.

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.
MarkFlowy
MarkFlowy is a lightweight and feature-rich Markdown editor with built-in AI capabilities. It supports one-click export of conversations, translation of articles, and obtaining article abstracts. Users can leverage large AI models like DeepSeek and Chatgpt as intelligent assistants. The editor provides high availability with multiple editing modes and custom themes. Available for Linux, macOS, and Windows, MarkFlowy aims to offer an efficient, beautiful, and data-safe Markdown editing experience for users.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.
deep-chat
Deep Chat is a fully customizable AI chat component that can be injected into your website with minimal to no effort. Whether you want to create a chatbot that leverages popular APIs such as ChatGPT or connect to your own custom service, this component can do it all! Explore deepchat.dev to view all of the available features, how to use them, examples and more!

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
project-blog
Welcome to the Blog Script Project, a collaborative platform for developers and writers to create, manage, and share content. With features like Markdown support, submodule integration, customizable templates, project contribution workflow, global visibility, community discussions, SEO optimization, and role-based dashboard, Blog Script enhances collaboration and visibility for your work. You can contribute by adding new projects, improving existing projects, updating documentation, fixing bugs, optimizing, and ensuring code readability. Follow the contribution guidelines to star the repository, find tasks, fork the repository, make changes, add screenshots, submit a pull request, and contribute to the open-source community. Additionally, you can add your project as a submodule by following the provided guidelines. Join us, contribute, and grow together!
intense-rp-next
IntenseRP Next v2 is a local OpenAI-compatible API + desktop app that bridges an OpenAI-style client (like SillyTavern) with provider web apps (DeepSeek, GLM Chat, Moonshot) by starting a local FastAPI server, launching a real Chromium session, intercepting streaming network responses, and re-emitting them as OpenAI-style SSE deltas for the client. It provides free-ish access to provider web models via the official web apps, a clicky desktop app experience, and occasional wait times due to web app changes. The tool is designed for local or LAN use and comes with built-in logging, update flows, and support for DeepSeek, GLM Chat, and Moonshot provider apps.

evalverse
Evalverse is an open-source project designed to support Large Language Model (LLM) evaluation needs. It provides a standardized and user-friendly solution for processing and managing LLM evaluations, catering to AI research engineers and scientists. Evalverse supports various evaluation methods, insightful reports, and no-code evaluation processes. Users can access unified evaluation with submodules, request evaluations without code via Slack bot, and obtain comprehensive reports with scores, rankings, and visuals. The tool allows for easy comparison of scores across different models and swift addition of new evaluation tools.
vim-airline
Vim-airline is a lean and mean status/tabline plugin for Vim that provides a nice statusline at the bottom of each Vim window. It consists of several sections displaying information such as mode, environment status, filename, filetype, file encoding, and current position in the file. The plugin is highly customizable and integrates with various plugins, providing a tiny core with extensibility in mind. It is optimized for speed, supports multiple themes, and integrates seamlessly with other plugins. Vim-airline is written in 100% Vimscript, eliminating the need for Python. The plugin aims to be stable and includes a unit testing suite for reliability.

nyxtext
Nyxtext is a text editor built using Python, featuring Custom Tkinter with the Catppuccin color scheme and glassmorphic design. It follows a modular approach with each element organized into separate files for clarity and maintainability. NyxText is not just a text editor but also an AI-powered desktop application for creatives, developers, and students.

coreply
Coreply is an open-source Android app that provides texting suggestions while typing, enhancing the typing experience with intelligent, context-aware suggestions. It supports various texting apps and offers real-time AI suggestions, customizable LLM settings, and ensures no data collection. Users can install the app, configure it with an API key, and start receiving suggestions while typing in messaging apps. The tool supports different AI models from providers like OpenAI, Google AI Studio, Openrouter, Groq, and Codestral for chat completion and fill-in-the-middle tasks.

baml
BAML is a config file format for declaring LLM functions that you can then use in TypeScript or Python. With BAML you can Classify or Extract any structured data using Anthropic, OpenAI or local models (using Ollama) ## Resources  [Discord Community](https://discord.gg/boundaryml)  [Follow us on Twitter](https://twitter.com/boundaryml) * Discord Office Hours - Come ask us anything! We hold office hours most days (9am - 12pm PST). * Documentation - Learn BAML * Documentation - BAML Syntax Reference * Documentation - Prompt engineering tips * Boundary Studio - Observability and more #### Starter projects * BAML + NextJS 14 * BAML + FastAPI + Streaming ## Motivation Calling LLMs in your code is frustrating: * your code uses types everywhere: classes, enums, and arrays * but LLMs speak English, not types BAML makes calling LLMs easy by taking a type-first approach that lives fully in your codebase: 1. Define what your LLM output type is in a .baml file, with rich syntax to describe any field (even enum values) 2. Declare your prompt in the .baml config using those types 3. Add additional LLM config like retries or redundancy 4. Transpile the .baml files to a callable Python or TS function with a type-safe interface. (VSCode extension does this for you automatically). We were inspired by similar patterns for type safety: protobuf and OpenAPI for RPCs, Prisma and SQLAlchemy for databases. BAML guarantees type safety for LLMs and comes with tools to give you a great developer experience:  Jump to BAML code or how Flexible Parsing works without additional LLM calls. | BAML Tooling | Capabilities | | ----------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | BAML Compiler install | Transpiles BAML code to a native Python / Typescript library (you only need it for development, never for releases) Works on Mac, Windows, Linux  | | VSCode Extension install | Syntax highlighting for BAML files Real-time prompt preview Testing UI | | Boundary Studio open (not open source) | Type-safe observability Labeling |
generative-ai
This repository contains codes related to Generative AI as per YouTube video. It includes various notebooks and files for different days covering topics like map reduce, text to SQL, LLM parameters, tagging, and Kaggle competition. The repository also includes resources like PDF files and databases for different projects related to Generative AI.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.
For similar tasks
DaoCloud-docs
DaoCloud Enterprise 5.0 Documentation provides detailed information on using DaoCloud, a Certified Kubernetes Service Provider. The documentation covers current and legacy versions, workflow control using GitOps, and instructions for opening a PR and previewing changes locally. It also includes naming conventions, writing tips, references, and acknowledgments to contributors. Users can find guidelines on writing, contributing, and translating pages, along with using tools like MkDocs, Docker, and Poetry for managing the documentation.
gpt-home
GPT Home is a project that allows users to build their own home assistant using Raspberry Pi and OpenAI API. It serves as a guide for setting up a smart home assistant similar to Google Nest Hub or Amazon Alexa. The project integrates various components like OpenAI, Spotify, Philips Hue, and OpenWeatherMap to provide a personalized home assistant experience. Users can follow the detailed instructions provided to build their own version of the home assistant on Raspberry Pi, with optional components for customization. The project also includes system configurations, dependencies installation, and setup scripts for easy deployment. Overall, GPT Home offers a DIY solution for creating a smart home assistant using Raspberry Pi and OpenAI technology.
comfy-cli
comfy-cli is a command line tool designed to simplify the installation and management of ComfyUI, an open-source machine learning framework. It allows users to easily set up ComfyUI, install packages, manage custom nodes, download checkpoints, and ensure cross-platform compatibility. The tool provides comprehensive documentation and examples to aid users in utilizing ComfyUI efficiently.
crewAI-tools
The crewAI Tools repository provides a guide for setting up tools for crewAI agents, enabling the creation of custom tools to enhance AI solutions. Tools play a crucial role in improving agent functionality. The guide explains how to equip agents with a range of tools and how to create new tools. Tools are designed to return strings for generating responses. There are two main methods for creating tools: subclassing BaseTool and using the tool decorator. Contributions to the toolset are encouraged, and the development setup includes steps for installing dependencies, activating the virtual environment, setting up pre-commit hooks, running tests, static type checking, packaging, and local installation. Enhance AI agent capabilities with advanced tooling.
aipan-netdisk-search
Aipan-Netdisk-Search is a free and open-source web project for searching netdisk resources. It utilizes third-party APIs with IP access restrictions, suggesting self-deployment. The project can be easily deployed on Vercel and provides instructions for manual deployment. Users can clone the project, install dependencies, run it in the browser, and access it at localhost:3001. The project also includes documentation for deploying on personal servers using NUXT.JS. Additionally, there are options for donations and communication via WeChat.

Agently-Daily-News-Collector
Agently Daily News Collector is an open-source project showcasing a workflow powered by the Agent ly AI application development framework. It allows users to generate news collections on various topics by inputting the field topic. The AI agents automatically perform the necessary tasks to generate a high-quality news collection saved in a markdown file. Users can edit settings in the YAML file, install Python and required packages, input their topic idea, and wait for the news collection to be generated. The process involves tasks like outlining, searching, summarizing, and preparing column data. The project dependencies include Agently AI Development Framework, duckduckgo-search, BeautifulSoup4, and PyYAM.
comfy-cli
Comfy-cli is a command line tool designed to facilitate the installation and management of ComfyUI, an open-source machine learning framework. Users can easily set up ComfyUI, install packages, and manage custom nodes directly from the terminal. The tool offers features such as easy installation, seamless package management, custom node management, checkpoint downloads, cross-platform compatibility, and comprehensive documentation. Comfy-cli simplifies the process of working with ComfyUI, making it convenient for users to handle various tasks related to the framework.
BentoDiffusion
BentoDiffusion is a BentoML example project that demonstrates how to serve and deploy diffusion models in the Stable Diffusion (SD) family. These models are specialized in generating and manipulating images based on text prompts. The project provides a guide on using SDXL Turbo as an example, along with instructions on prerequisites, installing dependencies, running the BentoML service, and deploying to BentoCloud. Users can interact with the deployed service using Swagger UI or other methods. Additionally, the project offers the option to choose from various diffusion models available in the repository for deployment.
For similar jobs
flux-aio
Flux All-In-One is a lightweight distribution optimized for running the GitOps Toolkit controllers as a single deployable unit on Kubernetes clusters. It is designed for bare clusters, edge clusters, clusters with restricted communication, clusters with egress via proxies, and serverless clusters. The distribution follows semver versioning and provides documentation for specifications, installation, upgrade, OCI sync configuration, Git sync configuration, and multi-tenancy configuration. Users can deploy Flux using Timoni CLI and a Timoni Bundle file, fine-tune installation options, sync from public Git repositories, bootstrap repositories, and uninstall Flux without affecting reconciled workloads.
paddler
Paddler is an open-source load balancer and reverse proxy designed specifically for optimizing servers running llama.cpp. It overcomes typical load balancing challenges by maintaining a stateful load balancer that is aware of each server's available slots, ensuring efficient request distribution. Paddler also supports dynamic addition or removal of servers, enabling integration with autoscaling tools.
DaoCloud-docs
DaoCloud Enterprise 5.0 Documentation provides detailed information on using DaoCloud, a Certified Kubernetes Service Provider. The documentation covers current and legacy versions, workflow control using GitOps, and instructions for opening a PR and previewing changes locally. It also includes naming conventions, writing tips, references, and acknowledgments to contributors. Users can find guidelines on writing, contributing, and translating pages, along with using tools like MkDocs, Docker, and Poetry for managing the documentation.
ztncui-aio
This repository contains a Docker image with ZeroTier One and ztncui to set up a standalone ZeroTier network controller with a web user interface. It provides features like Golang auto-mkworld for generating a planet file, supports local persistent storage configuration, and includes a public file server. Users can build the Docker image, set up the container with specific environment variables, and manage the ZeroTier network controller through the web interface.
devops-gpt
DevOpsGPT is a revolutionary tool designed to streamline your workflow and empower you to build systems and automate tasks with ease. Tired of spending hours on repetitive DevOps tasks? DevOpsGPT is here to help! Whether you're setting up infrastructure, speeding up deployments, or tackling any other DevOps challenge, our app can make your life easier and more productive. With DevOpsGPT, you can expect faster task completion, simplified workflows, and increased efficiency. Ready to experience the DevOpsGPT difference? Visit our website, sign in or create an account, start exploring the features, and share your feedback to help us improve. DevOpsGPT will become an essential tool in your DevOps toolkit.
ChatOpsLLM
ChatOpsLLM is a project designed to empower chatbots with effortless DevOps capabilities. It provides an intuitive interface and streamlined workflows for managing and scaling language models. The project incorporates robust MLOps practices, including CI/CD pipelines with Jenkins and Ansible, monitoring with Prometheus and Grafana, and centralized logging with the ELK stack. Developers can find detailed documentation and instructions on the project's website.
aiops-modules
AIOps Modules is a collection of reusable Infrastructure as Code (IAC) modules that work with SeedFarmer CLI. The modules are decoupled and can be aggregated using GitOps principles to achieve desired use cases, removing heavy lifting for end users. They must be generic for reuse in Machine Learning and Foundation Model Operations domain, adhering to SeedFarmer Guide structure. The repository includes deployment steps, project manifests, and various modules for SageMaker, Mlflow, FMOps/LLMOps, MWAA, Step Functions, EKS, and example use cases. It also supports Industry Data Framework (IDF) and Autonomous Driving Data Framework (ADDF) Modules.
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.