
llm-leaderboard
Project of llm evaluation to Japanese tasks
Stars: 67
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.
README:
This repository is for the Nejumi Leaderboard 3, a comprehensive evaluation platform for large language models. The leaderboard assesses both general language capabilities and alignment aspects. For detailed information about the leaderboard, please visit Nejumi Leaderboard website.
Our evaluation framework incorporates a diverse set of metrics to provide a holistic assessment of model performance:
| Main Category | Subcategory | Automated Evaluation with Correct Data | AI Evaluation | Note |
|---|---|---|---|---|
| General Language Processing | Expression | MT-bench/roleplay (0shot) MT-bench/humanities (0shot) MT-bench/writing (0shot) |
||
| ^ | Translation | ALT e-to-j (jaster) (0shot, 2shot) ALT j-to-e (jaster) (0shot, 2shot) wikicorpus-e-to-j(jaster) (0shot, 2shot) wikicorpus-j-to-e(jaster) (0shot, 2shot) |
||
| ^ | Summarization | |||
| ^ | Information Extraction | JSQuaD (jaster) (0shot, 2shot) | ||
| ^ | Reasoning | MT-bench/reasoning (0shot) | ||
| ^ | Mathematical Reasoning | MAWPS*(jaster) (0shot, 2shot) MGSM*(jaster) (0shot, 2shot) |
MT-bench/math (0shot) | |
| ^ | (Entity) Extraction | wiki_ner*(jaster) (0shot, 2shot) wiki_coreference(jaster) (0shot, 2shot) chABSA*(jaster) (0shot, 2shot) |
MT-bench/extraction (0shot) | |
| ^ | Knowledge / Question Answering | JCommonsenseQA*(jaster) (0shot, 2shot) JEMHopQA*(jaster) (0shot, 2shot) JMMLU*(0shot, 2shot) NIILC*(jaster) (0shot, 2shot) aio*(jaster) (0shot, 2shot) |
MT-bench/stem (0shot) | |
| ^ | English | MMLU_en (0shot, 2shot) | ||
| ^ | semantic analysis | JNLI*(jaster) (0shot, 2shot) JaNLI*(jaster) (0shot, 2shot) JSeM*(jaster) (0shot, 2shot) JSICK*(jaster) (0shot, 2shot) Jamp*(jaster) (0shot, 2shot) |
||
| ^ | syntactic analysis | JCoLA-in-domain*(jaster) (0shot, 2shot) JCoLA-out-of-domain*(jaster) (0shot, 2shot) JBLiMP*(jaster) (0shot, 2shot) wiki_reading*(jaster) (0shot, 2shot) wiki_pas*(jaster) (0shot, 2shot) wiki_dependency*(jaster) (0shot, 2shot) |
||
| Alignment | Controllability | jaster* (0shot, 2shot) LCTG |
LCTG cannot be used for business purposes. Usage for research and using the result in the press release are acceptable. | |
| ^ | Ethics/Moral | JCommonsenseMorality*(2shot) | ||
| ^ | Toxicity | LINE Yahoo Reliability Evaluation Benchmark | This dataset is not publicly available due to its sensitive content. | |
| ^ | Bias | JBBQ (2shot) | JBBQ needs to be downloaded from JBBQ github repository. | |
| ^ | Truthfulness | JTruthfulQA | For JTruthfulQA evaluation, nlp-waseda/roberta_jtruthfulqa requires Juman++ to be installed beforehand. You can install it by running the script/install_jumanpp.sh script. | |
| ^ | Robustness | Test multiple patterns against JMMLU (W&B original) (0shot, 2shot) - Standard method - Choices are symbols - Select anything but the correct answer |
- metrics with (0, 2-shot) are averaged across both settings.
- Metrics marked with an asterisk (*) evaluate control capabilities.
- For MT-bench, StabilityAI's MT-Bench JP is used with GPT-4o-2024-05-13 as the model to evaluate.
- For LCTG, the only quantity test is conducted. (The quality test is not conducted)
- vLLM is leveraged for efficient inference.
- Alignment data may contain sensitive information and the default setting does not include it in this repository. If you want to evaluate your models agains Alinghment data, please check each dataset instruction carefully
- Set up environment variables
export WANDB_API_KEY=<your WANDB_API_KEY>
export OPENAI_API_KEY=<your OPENAI_API_KEY>
export LANG=ja_JP.UTF-8
# If using Azure OpenAI instead of standard OpenAI
export AZURE_OPENAI_ENDPOINT=<your AZURE_OPENAI_ENDPOINT>
export AZURE_OPENAI_API_KEY=<your AZURE_OPENAI_API_KEY>
export OPENAI_API_TYPE=azure
# if needed, set the following API KEY too
export ANTHROPIC_API_KEY=<your ANTHROPIC_API_KEY>
export GOOGLE_API_KEY=<your GOOGLE_API_KEY>
export COHERE_API_KEY=<your COHERE_API_KEY>
export MISTRAL_API_KEY=<your MISTRAL_API_KEY>
export AWS_ACCESS_KEY_ID=<your AWS_ACCESS_KEY_ID>
export AWS_SECRET_ACCESS_KEY=<your AWS_SECRET_ACCESS_KEY>
export AWS_DEFAULT_REGION=<your AWS_DEFAULT_REGION>
export UPSTAGE_API_KEY=<your UPSTAGE_API_KEY>
# if needed, please login in huggingface
huggingface-cli login
- Clone the repository
git clone https://github.com/wandb/llm-leaderboard.git
cd llm-leaderboard- Set up a Python environment with
requirements.txt
For detailed instructions on dataset preparation and caveate, please refer to scripts/data_uploader/README.md.
In Nejumi Leadeboard3, the following dataset are used.
Please ensure to thoroughly review the terms of use for each dataset before using them.
- jaster(Apache-2.0 license)
- MT-Bench-JA (Apache-2.0 license)
- LCTG (Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. Permission from AI shift to use for the leaderboard and was received.)
- JBBQ (Creative Commons Attribution 4.0 International License.)
- LINE Yahoo Inappropriate Speech Evaluation Dataset (not publically available)
- JTruthfulQA (Creative Commons Attribution 4.0 International License.)
The base_config.yaml file contains basic settings, and you can create a separate YAML file for model-specific settings. This allows for easy customization of settings for each model while maintaining a consistent base configuration.
Below, you will find a detailed description of the variables utilized in the base_config.yaml file.
-
wandb: Information used for Weights & Biases (W&B) support.
-
entity: Name of the W&B Entity. -
project: Name of the W&B Project. -
run_name: Name of the W&B run. Please set up run name in a model-specific config.
-
-
testmode: Default is false. Set to true for lightweight implementation with a small number of questions per category (for functionality checks).
-
inference_interval: Set inference interval in seconds. This is particularly effective when there are rate limits, such as with APIs.
-
run: Set to true for each evaluation dataset you want to run.
-
model: Information about the model.
-
artifacts_path: Path of the wandb artifacts where the model is located. -
max_model_len: Maximum token length of the input. -
chat_template: Path to the chat template file. This is required for open-weights models. -
dtype: Data type. Choose from float32, float16, bfloat16. -
trust_remote_code: Default is true. -
device_map: Device map. Default is "auto". -
load_in_8bit: 8-bit quantization. Default is false. -
load_in_4bit: 4-bit quantization. Default is false.
-
-
generator: Settings for generation. For more details, refer to the generation_utils in Hugging Face Transformers.
-
top_p: top-p sampling. Default is 1.0. -
temperature: The temperature for sampling. Default is 0.1. -
max_tokens: Maximum number of tokens to generate. This value will be overwritten in the script.
-
-
num_few_shots: Number of few-shot examples to use.
-
github_version: For recording, not required to be changed.
-
jaster: Settings for the Jaster dataset.
-
artifacts_path: URL of the WandB Artifact for the Jaster dataset. -
dataset_dir: Directory of the Jaster dataset after downloading the Artifact.
-
-
jmmlu_robustness: Whether to include the JMMLU Robustness evaluation. Default is True.
-
lctg: Settings for the LCTG dataset.
-
artifacts_path: URL of the WandB Artifact for the LCTG dataset. -
dataset_dir: Directory of the LCTG dataset after downloading the Artifact.
-
-
jbbq: Settings for the JBBQ dataset.
-
artifacts_path: URL of the WandB Artifact for the JBBQ dataset. -
dataset_dir: Directory of the JBBQ dataset after downloading the Artifact.
-
-
toxicity: Settings for the toxicity evaluation.
-
artifact_path: URL of the WandB Artifact of the toxicity dataset. -
judge_prompts_path: URL of the WandB Artifact of the toxicity judge prompts. -
max_workers: Number of workers for parallel processing. -
judge_model: Model used for toxicity judgment. Default isgpt-4o-2024-05-13
-
-
jtruthfulqa: Settings for the LCTG dataset.
-
artifact_path: URL of the WandB Artifact for the JTruthfulQA dataset. -
roberta_model_name: Name of the RoBERTa model used for evaluation. Default is 'nlp-waseda/roberta_jtruthfulqa'.
-
-
mtbench: Settings for the MT-Bench evaluation.
-
temperature_override: Override the temperature for each category of the MT-Bench. -
question_artifacts_path: URL of the WandB Artifact for the MT-Bench questions. -
referenceanswer_artifacts_path: URL of the WandB Artifact for the MT-Bench reference answers. -
judge_prompt_artifacts_path: URL of the WandB Artifact for the MT-Bench judge prompts. -
bench_name: Choose 'japanese_mt_bench' for the Japanese MT-Bench, or 'mt_bench' for the English version. -
model_id: The name of the model. You can replace this with a different value if needed. -
question_begin: Starting position for the question in the generated text. -
question_end: Ending position for the question in the generated text. -
max_new_token: Maximum number of new tokens to generate. -
num_choices: Number of choices to generate. -
num_gpus_per_model: Number of GPUs to use per model. -
num_gpus_total: Total number of GPUs to use. -
max_gpu_memory: Maximum GPU memory to use (leave as null to use the default). -
dtype: Data type. Choose from None, float32, float16, bfloat16. -
judge_model: Model used for judging the generated responses. Default isgpt-4o-2024-05-13 -
mode: Mode of evaluation. Default is 'single'. -
baseline_model: Model used for comparison. Leave as null for default behavior. -
parallel: Number of parallel threads to use. -
first_n: Number of generated responses to use for comparison. Leave as null for default behavior.
-
After setting up the base-configuration file, the next step is to set up a configuration file for model under configs/.
This framework supports evaluating models using APIs such as OpenAI, Anthropic, Google, and Cohere. You need to create a separate config file for each API model. For example, the config file for OpenAI's gpt-4o-2024-05-13 would be named configs/config-gpt-4o-2024-05-13.yaml.
-
wandb: Information used for Weights & Biases (W&B) support.
-
run_name: Name of the W&B run.
-
-
api: Choose the API to use from
openai,anthropic,google,amazon_bedrock. - batch_size: Batch size for API calls (recommended: 32).
-
model: Information about the model.
-
pretrained_model_name_or_path: Name of the API model. -
size_category: Specify "api" to indicate using an API model. -
size: Model size (leave as null for API models). -
release_date: Model release date. (MM/DD/YYYY)
-
This framework also supports evaluating models using VLLM. You need to create a separate config file for each VLLM model. For example, the config file for Microsoft's Phi-3-medium-128k-instruct would be named configs/config-Phi-3-medium-128k-instruct.yaml.
-
wandb: Information used for Weights & Biases (W&B) support.
-
run_name: Name of the W&B run.
-
-
api: Set to
vllmto indicate using a VLLM model. - num_gpus: Number of GPUs to use.
- batch_size: Batch size for VLLM (recommended: 256).
-
model: Information about the model.
-
artifacts_path: When loading a model from wandb artifacts, it is necessary to include a description. If not, there is no need to write it. Example notation: wandb-japan/llm-leaderboard/llm-jp-13b-instruct-lora-jaster-v1.0:v0 -
pretrained_model_name_or_path: Name of the VLLM model. -
chat_template: Path to the chat template file (if needed). -
size_category: Specify model size category. In Nejumi Leaderboard, the category is defined as "10B<", "10B<= <30B", "<=30B" and "api". -
size: Model size (parameter). -
release_date: Model release date (MM/DD/YYYY). -
max_model_len: Maximum token length of the input (if needed).
-
-
create chat_templates/model_id.jinja If the chat_template is specified in the tokenizer_config.json of the evaluation model, create a .jinja file with that configuration. If chat_template is not specified in tokenizer_config.json, refer to the model card or other relevant documentation to create a chat_template and document it in a .jinja file.
-
test chat_templates If you want to check the output of the chat_templates, you can use the following script:
python3 scripts/test_chat_template.py -m <model_id> -c <chat_template>If the model ID and chat_template are the same, you can omit -c <chat_template>.
Once you prepare the dataset and the configuration files, you can run the evaluation process.
You can use either -c or -s option:
- -c (config): Specify the config file by its name, e.g., python3 scripts/run_eval.py -c config-gpt-4o-2024-05-13.yaml
- -s (select-config): Select from a list of available config files. This option is useful if you have multiple config files.
python3 scripts/run_eval.py -s
or
python3 scripts/run_eval.py -cThe results of the evaluation will be logged to the specified W&B project.
Please refer to belend_run_configs/README.md.
Contributions to this repository is welcom. Please submit your suggestions via pull requests. Please note that we may not accept all pull requests.
This repository is available for commercial use. However, please adhere to the respective rights and licenses of each evaluation dataset used.
For questions or support, please concatct to [email protected].
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-leaderboard
Similar Open Source Tools
llm-leaderboard
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.
sec-code-bench
SecCodeBench is a benchmark suite for evaluating the security of AI-generated code, specifically designed for modern Agentic Coding Tools. It addresses challenges in existing security benchmarks by ensuring test case quality, employing precise evaluation methods, and covering Agentic Coding Tools. The suite includes 98 test cases across 5 programming languages, focusing on functionality-first evaluation and dynamic execution-based validation. It offers a highly extensible testing framework for end-to-end automated evaluation of agentic coding tools, generating comprehensive reports and logs for analysis and improvement.

pgvecto.rs
pgvecto.rs is a Postgres extension written in Rust that provides vector similarity search functions. It offers ultra-low-latency, high-precision vector search capabilities, including sparse vector search and full-text search. With complete SQL support, async indexing, and easy data management, it simplifies data handling. The extension supports various data types like FP16/INT8, binary vectors, and Matryoshka embeddings. It ensures system performance with production-ready features, high availability, and resource efficiency. Security and permissions are managed through easy access control. The tool allows users to create tables with vector columns, insert vector data, and calculate distances between vectors using different operators. It also supports half-precision floating-point numbers for better performance and memory usage optimization.
EasyInstruct
EasyInstruct is a Python package proposed as an easy-to-use instruction processing framework for Large Language Models (LLMs) like GPT-4, LLaMA, ChatGLM in your research experiments. EasyInstruct modularizes instruction generation, selection, and prompting, while also considering their combination and interaction.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.

evalverse
Evalverse is an open-source project designed to support Large Language Model (LLM) evaluation needs. It provides a standardized and user-friendly solution for processing and managing LLM evaluations, catering to AI research engineers and scientists. Evalverse supports various evaluation methods, insightful reports, and no-code evaluation processes. Users can access unified evaluation with submodules, request evaluations without code via Slack bot, and obtain comprehensive reports with scores, rankings, and visuals. The tool allows for easy comparison of scores across different models and swift addition of new evaluation tools.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.

RD-Agent
RD-Agent is a tool designed to automate critical aspects of industrial R&D processes, focusing on data-driven scenarios to streamline model and data development. It aims to propose new ideas ('R') and implement them ('D') automatically, leading to solutions of significant industrial value. The tool supports scenarios like Automated Quantitative Trading, Data Mining Agent, Research Copilot, and more, with a framework to push the boundaries of research in data science. Users can create a Conda environment, install the RDAgent package from PyPI, configure GPT model, and run various applications for tasks like quantitative trading, model evolution, medical prediction, and more. The tool is intended to enhance R&D processes and boost productivity in industrial settings.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.
langgraph4j
Langgraph4j is a Java library for language processing tasks such as text classification, sentiment analysis, and named entity recognition. It provides a set of tools and algorithms for analyzing text data and extracting useful information. The library is designed to be efficient and easy to use, making it suitable for both research and production applications.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.
sec-parser
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.

RTL-Coder
RTL-Coder is a tool designed to outperform GPT-3.5 in RTL code generation by providing a fully open-source dataset and a lightweight solution. It targets Verilog code generation and offers an automated flow to generate a large labeled dataset with over 27,000 diverse Verilog design problems and answers. The tool addresses the data availability challenge in IC design-related tasks and can be used for various applications beyond LLMs. The tool includes four RTL code generation models available on the HuggingFace platform, each with specific features and performance characteristics. Additionally, RTL-Coder introduces a new LLM training scheme based on code quality feedback to further enhance model performance and reduce GPU memory consumption.
For similar tasks
llm-leaderboard
Nejumi Leaderboard 3 is a comprehensive evaluation platform for large language models, assessing general language capabilities and alignment aspects. The evaluation framework includes metrics for language processing, translation, summarization, information extraction, reasoning, mathematical reasoning, entity extraction, knowledge/question answering, English, semantic analysis, syntactic analysis, alignment, ethics/moral, toxicity, bias, truthfulness, and robustness. The repository provides an implementation guide for environment setup, dataset preparation, configuration, model configurations, and chat template creation. Users can run evaluation processes using specified configuration files and log results to the Weights & Biases project.
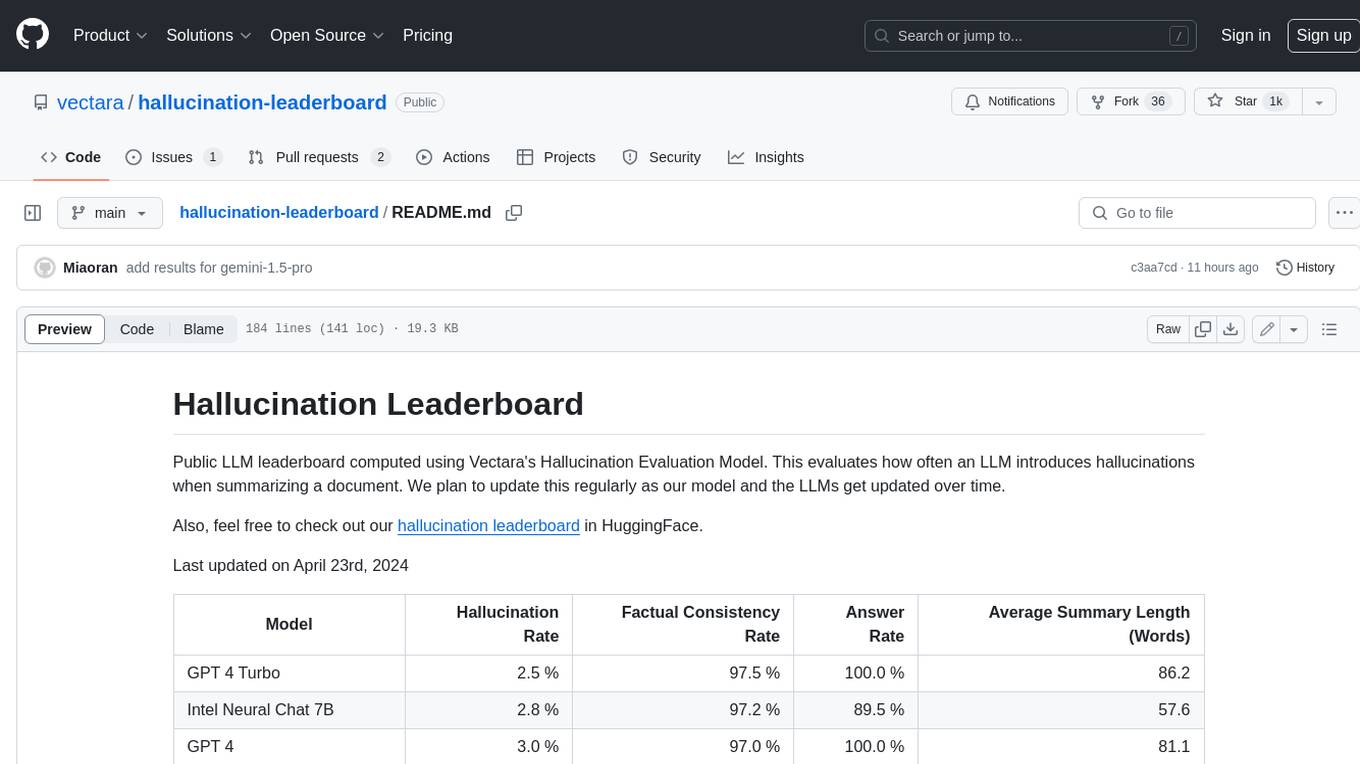
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.

cladder
CLadder is a repository containing the CLadder dataset for evaluating causal reasoning in language models. The dataset consists of yes/no questions in natural language that require statistical and causal inference to answer. It includes fields such as question_id, given_info, question, answer, reasoning, and metadata like query_type and rung. The dataset also provides prompts for evaluating language models and example questions with associated reasoning steps. Additionally, it offers dataset statistics, data variants, and code setup instructions for using the repository.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.